
什麼是自然語言處理,它是如何工作的?
已發表: 2022-01-29
自然語言處理使計算機能夠將我們所說的內容處理成它可以執行的命令。 了解它是如何工作的基礎知識,以及它是如何被用來改善我們的生活的。
什麼是自然語言處理?
無論是 Alexa、Siri、Google Assistant、Bixby 還是 Cortana,如今每個擁有智能手機或智能揚聲器的人都有聲控助手。 每年,這些語音助手似乎都能更好地識別和執行我們告訴他們要做的事情。 但是你有沒有想過這些助手是如何處理我們所說的事情的? 由於自然語言處理或 NLP,他們設法做到了這一點。
從歷史上看,大多數軟件只能響應一組固定的特定命令。 由於您單擊了打開,文件將打開,或者電子表格將根據某些符號和公式名稱計算公式。 一個程序使用它被編碼的編程語言進行通信,因此當它得到它識別的輸入時會產生一個輸出。 在這種情況下,單詞就像一組不同的機械槓桿,總是提供所需的輸出。
這與人類語言形成鮮明對比,人類語言是複雜的、非結構化的,並且基於句子結構、語氣、口音、時間、標點符號和上下文具有多種含義。 自然語言處理是人工智能的一個分支,它試圖彌合機器識別為輸入的內容與人類語言之間的差距。 這樣當我們自然地說話或打字時,機器就會產生與我們所說的內容一致的輸出。
這是通過在實際單詞的含義之上獲取大量數據點來從人類語言的各種元素中獲取含義來完成的。 這個過程與機器學習的概念密切相關,機器學習使計算機能夠在獲得更多數據點時學習更多。 這就是為什麼我們經常與之交互的大多數自然語言處理機器似乎隨著時間的推移而變得更好的原因。
為了更好地闡明這個概念,讓我們看一下 NLP 中用於處理語言和信息的兩種最頂級的技術。
相關:人工智能的問題:機器正在學習,但無法理解它們
代幣化


標記化意味著將語音分成單詞或句子。 每段文本都是一個標記,這些標記是處理您的語音時顯示的內容。 這聽起來很簡單,但在實踐中,這是一個棘手的過程。
假設您正在使用文本轉語音軟件(例如 Google 鍵盤)向朋友發送消息。 你想發信息,“在公園見我。” 當您的手機記錄並通過 Google 的文本轉語音算法對其進行處理時,Google 必須將您剛才所說的內容拆分為令牌。 這些標記將是“meet”、“me”、“at”、“the”和“park”。
人們在單詞之間有不同長度的停頓,而其他語言在單詞之間的可聽停頓可能不會很少。 語言和方言之間的標記化過程差異很大。
詞乾和詞形還原
詞幹提取和詞形還原都涉及刪除機器可以識別的詞根的添加或變體的過程。 這樣做是為了使不同單詞的語音解釋保持一致,這些單詞基本上都意味著相同的東西,這使得 NLP 處理更快。
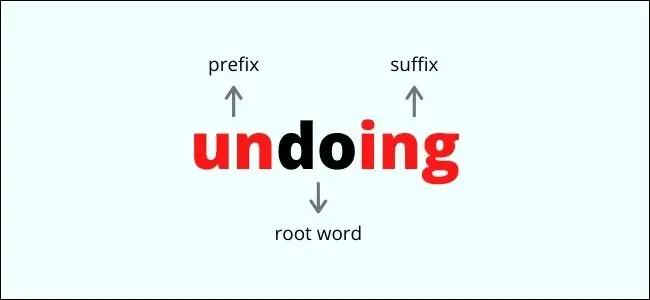
詞幹提取是一個粗略的快速過程,涉及從詞根中刪除詞綴,這些詞綴是附加到詞根之前或之後的詞的附加詞。 這通過簡單地刪除字母將單詞變成最簡單的基本形式。 例如:
- “走”變成“走”
- “快”變“快”
- “嚴重”變成“嚴重”
如您所見,詞幹提取可能會產生完全改變單詞含義的不利影響。 “Severity”和“sever”不是同一個意思,只是在詞幹提取的過程中去掉了後綴“ity”。
另一方面,詞形還原是一個更複雜的過程,涉及將一個詞簡化為它們的基礎,稱為引理。 這考慮了單詞的上下文以及它在句子中的使用方式。 它還涉及在單詞數據庫及其各自的引理中查找術語。 例如:
- “是”變成“是”
- “操作”變成“操作”
- “嚴重”變成“嚴重”
在這個例子中,詞形還原成功地將術語“嚴重性”變成了“嚴重”,這是它的詞形和詞根。
NLP 用例和未來
前面的例子只是開始觸及自然語言處理的表面。 它涵蓋了廣泛的實踐和使用場景,其中許多是我們在日常生活中使用的。 以下是當前使用 NLP 的一些示例:
- 預測文本:當您在智能手機上鍵入消息時,它會自動向您推薦適合句子或您以前使用過的單詞。
- 機器翻譯:廣泛使用的消費者翻譯服務,例如穀歌翻譯,將高級形式的 NLP 合併到處理語言並翻譯它。
- 聊天機器人: NLP 是智能聊天機器人的基礎,尤其是在客戶服務領域,它們可以在客戶面對真人之前協助客戶並處理他們的請求。
還有更多。 NLP 用途目前正在新聞媒體、醫療技術、工作場所管理和金融等領域開發和部署。 未來我們有可能與機器人進行全面而復雜的對話。
如果您有興趣了解有關 NLP 的更多信息,可以查看 Towards Data Science 博客或 Standford National Language Processing Group 上的許多出色資源。