
搜索引擎如何工作並使您的生活更輕鬆?
已發表: 2015-11-06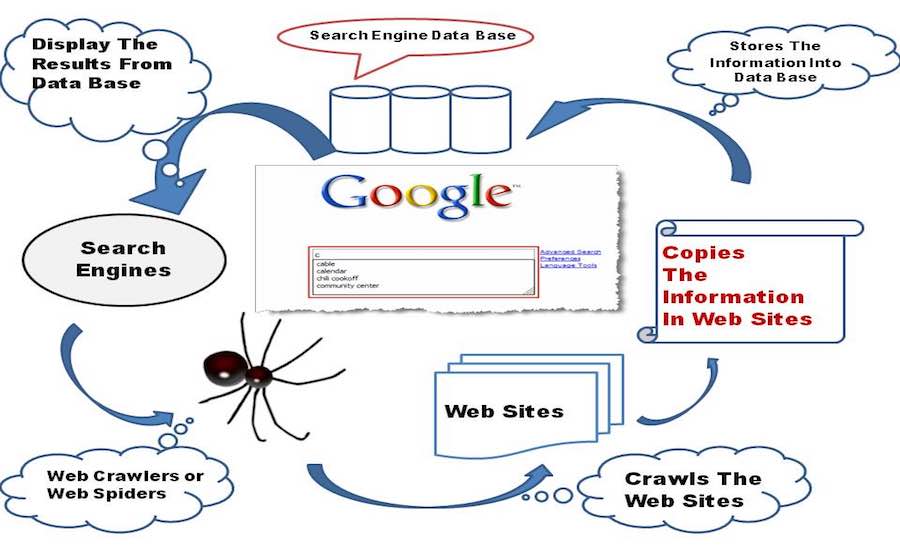 Short Bytes:搜索引擎是一種軟件,它允許根據輸入的搜索查詢,通過使用網絡爬蟲和網絡索引、一些胖公式和智能算法來顯示相關的網頁結果,以收集適當的數據。
Short Bytes:搜索引擎是一種軟件,它允許根據輸入的搜索查詢,通過使用網絡爬蟲和網絡索引、一些胖公式和智能算法來顯示相關的網頁結果,以收集適當的數據。
Google 如何在一瞬間為您提供最佳結果? 實際上,在谷歌、必應出現之前,這並不重要。 如果沒有谷歌、必應或雅虎,情況就會大不相同。 讓我們深入搜索引擎的世界,看看搜索引擎是如何工作的。
窺視歷史
搜索引擎的童話故事始於 1990 年代,當時 Tim Berners-Lee 曾經將每一個新的網絡服務器加入到由 CERN 網絡服務器維護的列表中。 直到 93 年 9 月,互聯網上還沒有搜索引擎,只有少數能夠維護文件名數據庫的工具。 Archie、Veronica、Jughead 是這一類別的第一批參賽者。
日內瓦大學的 Oscar Nierstrasz 獲得了第一個名為 W3Catalog 的搜索引擎的認可。 他編寫了一些嚴肅的 Perl 腳本,最終在 1993 年 9 月 3 日推出了世界上第一個搜索引擎。此外,1993 年出現了許多其他搜索引擎。 JumpStation 由 Jonathon Fletcher、AliWeb、WWW Worm 等 Yahoo! 1995 年作為網絡目錄推出,但從 2000 年開始使用 Inktomi 的引擎搜索,然後在 2009 年轉移到微軟的 Bing。
現在,談論作為搜索引擎術語的主要同義詞的名稱,谷歌搜索,是兩名斯坦福大學畢業生拉里佩奇和塞爾吉布林的研究項目,在 1995 年 3 月有最初的足跡。谷歌的工作最初是受到啟發的Page的反向鏈接方法是根據一個網頁有多少反向鏈接進行計算,以衡量該頁面在萬維網中的重要性。 “我得到的最好的建議”,佩奇回憶說,他的主管特里·維諾格拉德是如何支持他的想法的。 從那時起,谷歌就再也沒有回頭。
一切從爬行開始
一個處於初期階段的嬰兒搜索引擎開始探索萬維網,它用它的小手和膝蓋探索它在網頁上找到的所有其他鏈接並將它們存儲在它的數據庫中。
現在,讓我們關註一些幕後的技術思想,搜索引擎包含一個網絡爬蟲軟件,它基本上是一個互聯網機器人,其任務是打開網頁上的所有超鏈接,並從所有鏈接中創建一個文本和元數據數據庫. 它從一組初始訪問鏈接開始,稱為種子。 一旦它繼續訪問這些鏈接,就會在要訪問的現有 URL 列表中添加新鏈接,稱為 Crawl Frontier。
當爬蟲遍歷鏈接時,它會從這些網頁下載信息,以便稍後以快照的形式查看,因為下載整個網頁需要大量數據,而且它的成本很低,至少在印度等國家。 我敢打賭,如果谷歌在印度成立,他們所有的錢都將用於支付互聯網賬單。 希望這不是現在關注的話題。
網絡爬蟲基於一些策略探索網頁:
選擇策略:爬蟲決定它應該下載哪些頁面和不應該下載哪些頁面。 選擇策略側重於下載網頁最相關的內容,而不是一些不重要的數據。
重新訪問政策:由於互聯網的動態特性,Crawler 會安排重新打開網頁並編輯其數據庫中的更改的時間,這使得 Crawler 很難保持與最新版本的更新。網頁。
並行化策略:爬蟲一次使用多個進程來探索稱為分佈式爬蟲的鏈接,但有時不同進程可能會下載相同的網頁,因此爬蟲保持所有進程之間的協調以消除任何可能表裡不一。
禮貌政策:當爬蟲遍歷一個網站時,它會同時從中下載網頁,從而增加了託管該網站的網絡服務器的負載。 因此,實現了一個術語“Crawl-Delay”,其中爬蟲在從網絡服務器下載一些數據後必須等待幾秒鐘,並受禮貌策略的約束。
另請閱讀:如何在 Python 中構建基本的 Web 爬蟲
標準網絡爬蟲的高級架構:
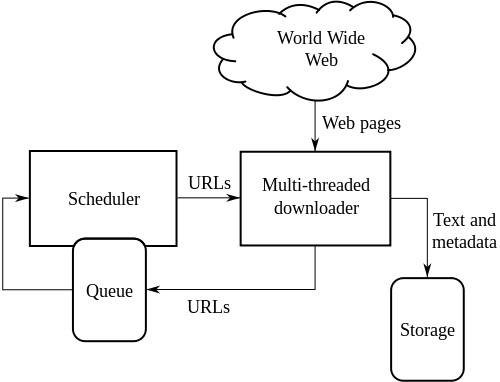
上圖描述了網絡爬蟲的工作原理。 它打開初始鏈接列表,然後打開這些鏈接中的鏈接,依此類推。
維基百科寫道,計算機科學研究人員 Vladislav Shkapenyuk 和 Torsten Suel 指出:
雖然構建一個在短時間內每秒下載幾頁的慢速爬蟲相當容易,但構建一個可以在數週內下載數億頁的高性能係統在系統設計中提出了許多挑戰, I/O 和網絡效率,以及穩健性和可管理性。
索引爬蟲
在嬰兒搜索引擎在整個互聯網上爬行後,它會為它找到的所有網頁創建一個索引。 擁有索引比浪費時間從大量大型文檔中查找搜索查詢要好得多,它將節省時間和資源。
有許多因素有助於為搜索引擎創建有效的索引系統。 索引器使用的存儲技術、索引的大小、快速找到包含搜索關鍵字的文檔的能力等是影響索引效率和可靠性的因素。
成功製作網絡索引的主要障礙之一是兩個進程之間的衝突。 假設一個進程想要搜索一個文檔,同時另一個進程想要在索引中添加一個文檔,這會在兩個進程之間產生衝突。 搜索引擎為了處理更多數據而實施分佈式計算,使問題更加嚴重。
索引類型
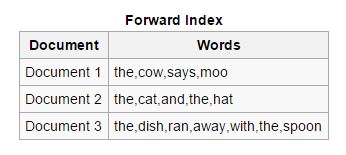
轉發:在這些類型的索引中,文檔中存在的所有關鍵字都存儲在列表中。 前向索引在索引的開始階段很容易創建,因為它使異步索引器能夠相互協作。

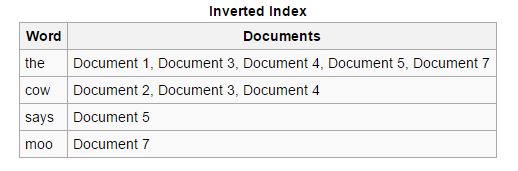
反向:將正向索引排序並轉換為反向索引,其中包含特定關鍵字的每個文檔與包含該關鍵字的其他文檔放在一起。 反向索引簡化了為給定搜索查詢查找相關文檔的過程,而正向索引並非如此。
另請閱讀:什麼是 DNS(域名系統)及其工作原理?
文件解析
也稱為標記化,是指對文檔的組件進行分解,例如關鍵字(稱為標記)、圖像和其他媒體,以便以後可以將它們插入索引中。 該方法主要側重於理解母語並預測用戶可能搜索的關鍵字,這是創建有效網絡索引系統的基礎。
主要挑戰包括找到要提取的關鍵字的單詞邊界,因為我們可以看到像中文和日文這樣的語言通常在其語言腳本中沒有空格。 理解一種語言所具有的歧義性也是一個值得關注的問題,因為一些語言會隨著地理變化而略有不同,甚至有很大差異。 此外,一些網頁效率低下沒有明確提及所使用的語言也是一個值得關注的問題,並增加了索引器的工作量。
搜索引擎能夠識別各種文件格式並成功地從中提取數據,在這些情況下必須格外小心。
元標記在快速創建索引方面也非常有用,它們減少了網絡索引器的工作量並簡化了完全解析整個文檔的需要。 您會在本文底部找到附加的元標記。
搜索索引
現在,寶寶搜索引擎已經不是寶寶了,他學會瞭如何爬行,如何快速高效地抓取東西,如何系統地整理自己的東西。 假設他的朋友讓他從他的安排中找到一些東西,他會怎麼做? 有四種類型的搜索查詢在使用中,雖然它們不是正式派生的,但它們隨著時間的推移而發展,並且已被發現在用戶提出的現實生活查詢方面是有效的。
導航:該術語用於用戶想要訪問 Internet 上存在的特定網頁或網站的查詢。 例如,當您在 Google 上搜索fossBytes時,您正在啟動導航查詢。
信息性:這種類型的查詢有數千個結果,涵蓋了增強用戶知識的一般主題。 例如,當您搜索史蒂夫喬布斯時,您將看到與史蒂夫喬布斯相關的所有鏈接。
事務性:關注用戶執行特定操作的意圖的查詢可能涉及一組預定義的指令。 例如,如何找到丟失/被盜的筆記本電腦?
連接性:這些類型的查詢不經常使用,它們關注從網站創建的索引的連接程度。 例如,如果您搜索,維基百科上有多少頁?
Google 和 Bing 創建了一些嚴謹的算法,足以確定與您的查詢最相關的結果。 Google 聲稱會根據 200 多個因素計算您的搜索結果,例如內容質量、新舊、網頁安全等等。 他們的搜索實驗室任命了世界上最偉大的頭腦,他們進行艱苦的計算並處理令人興奮的公式,只是為了讓搜索對您來說更加簡單和快捷。
其他顯著特點*
圖片搜索:您會驚訝地發現 Google 的著名圖片搜索工具背後的靈感。 J.Lo,是的,你沒聽錯,J.Lo 和她在 2000 年格萊美頒獎典禮上的綠色范思哲 (ver-sah-chay) 禮服是谷歌推出圖片搜索的真正原因,因為人們正忙著谷歌搜索她。
埃里克施密特在其 2015 年 1 月 19 日發表的題為“修補匠的學徒”的文章中說。
語音搜索:谷歌經過一番努力,率先在其搜索引擎上引入了語音搜索,隨後其他搜索引擎也紛紛實現了這一功能。
垃圾郵件打擊:搜索引擎部署了一些嚴格的算法,以便他們可以保護您免受垃圾郵件攻擊。 垃圾郵件基本上是散佈在整個互聯網上的消息或文件,可能用於廣告或傳播病毒。 同樣在這件事上,谷歌人員手動通知他們發現負責在互聯網上傳播垃圾郵件的網站。
位置優化:搜索引擎現在能夠根據用戶的位置顯示結果。 如果搜索,班加羅爾的天氣怎麼樣,那麼天氣統計數據將參考班加羅爾。
更好地了解您:現代搜索引擎能夠理解用戶查詢的含義,而不是查找用戶輸入的關鍵字。
自動完成:在您鍵入時根據您之前的搜索和其他用戶進行的搜索來預測您的搜索查詢的能力。
知識圖:此功能由 Google 搜索提供,展示了其根據現實生活中的人物、地點和事件提供搜索結果的能力。
家長控制:搜索引擎允許小型家長控制他們的孩子在互聯網上的活動。
* 很難涵蓋這些強大的搜索引擎提供的大量功能。
清盤
搜索引擎為使我們的生活更簡單做出了貢獻,他們為利用互聯網上的所有信息所做的辛勤工作是無價的。 但這種探索導致了我們個人空間在公共平台上的展示,我必須說,是時候為我們走過的路感到慌張了,除非我們回顧自己的行為為時已晚而我們的生活只是尷尬的雙年展。 我們不能否認搜索引擎現在是我們數字人格分裂的重要組成部分。 我們只需要利用我們已經獲得的技術,而不是讓它將我們奴役在我們自己的惡行的鎖鏈中。
好了,不多說感情線了,欣賞一下那個現在已經十幾歲的寶貝搜索引擎的可愛和才華,對你的理解更深了。 谷歌一直在那里為我們搜索一切,它是我們許多人的互聯網,我們必須珍惜我們在使用谷歌搜索時獲得的良好體驗。 哦! 我忘了提到必應,你也很棒。 保持警惕,保持安全並使用 Google 搜索。
觀看此視頻並了解有關搜索引擎的更多信息:
您是否曾經點擊過 Google 搜索上的“手氣不錯”按鈕。 打開它並在下面的評論部分告訴我們你最喜歡哪個塗鴉。