
NVIDIA 的 RTX 3000 系列 GPU:這是新功能
已發表: 2022-01-29
2020 年 9 月 1 日,NVIDIA 發布了其新的遊戲 GPU 系列:基於其 Ampere 架構的 RTX 3000 系列。 我們將討論什麼是新的,它附帶的人工智能軟件,以及讓這一代人非常棒的所有細節。
認識 RTX 3000 系列 GPU

NVIDIA 的主要公告是其閃亮的新 GPU,全部基於定制的 8 nm 製造工藝,並且都在光柵化和光線追踪性能方面帶來了重大的加速。
在陣容的低端,有 RTX 3070,售價 499 美元。 對於 NVIDIA 在最初宣佈時推出的最便宜的顯卡來說,它有點貴,但一旦你得知它擊敗了現有的 RTX 2080 Ti(通常零售價超過 1400 美元的頂級線卡),這絕對是一種偷竊。 然而,在 NVIDIA 宣布後,第三方銷售價格下降,大量在 eBay 上以低於 600 美元的價格被搶購。
截至公告發佈時還沒有可靠的基準,因此尚不清楚該卡是否真的在客觀上比 2080 Ti “更好”,或者 NVIDIA 是否有點扭曲營銷。 正在運行的基準測試為 4K,並且可能開啟了 RTX,這可能會使差距看起來比在純粹的光柵化遊戲中更大,因為基於 Ampere 的 3000 系列在光線追踪方面的表現將是 Turing 的兩倍多。 但是,由於光線追踪現在不會對性能造成太大影響,並且在最新一代遊戲機中得到支持,因此以幾乎三分之一的價格運行它與上一代旗艦產品一樣快是一個主要賣點。
目前還不清楚價格是否會保持這種狀態。 第三方設計通常會在價格標籤上增加至少 50 美元,而且由於需求可能會有多高,到 2020 年 10 月看到它以 600 美元的價格出售也就不足為奇了。
略高於此的是 RTX 3080,售價 699 美元,應該是 RTX 2080 的兩倍,比 3080 快 25-30%。
然後,在高端,新的旗艦是 RTX 3090,它非常巨大。 NVIDIA 很清楚,並將其稱為“BFGPU”,該公司稱其代表“Big Ferocious GPU”。

NVIDIA 沒有展示任何直接的性能指標,但該公司展示了它以 60 FPS 的速度運行 8K 遊戲,這令人印象深刻。 誠然,NVIDIA 幾乎肯定會使用 DLSS 來達到這一目標,但 8K 遊戲就是 8K 遊戲。
當然,最終會有 3060 和其他更注重預算的卡的變體,但這些通常會在以後出現。
為了真正冷卻這些東西,NVIDIA 需要改進的冷卻器設計。 3080 的額定功率為 320 瓦,相當高,因此 NVIDIA 選擇了雙風扇設計,但不是將兩個風扇 vwinf 放在底部,而是將風扇放在背板通常所在的頂端。 風扇將空氣向上引導至 CPU 冷卻器和機箱頂部。

從機箱中不良氣流對性能的影響程度來看,這是完全合理的。 但是,電路板因此非常狹窄,這可能會影響第三方銷售價格。
DLSS:軟件優勢
光線追踪並不是這些新卡的唯一好處。 真的,這有點像 hack——與老一代顯卡相比,RTX 2000 系列和 3000 系列在進行實際光線追踪方面並沒有那麼好。 在像 Blender 這樣的 3D 軟件中,光線追踪一個完整的場景通常每幀需要幾秒鐘甚至幾分鐘的時間,因此在 10 毫秒內強制它是不可能的。
當然,有用於運行光線計算的專用硬件,稱為 RT 內核,但在很大程度上,NVIDIA 選擇了不同的方法。 NVIDIA 改進了去噪算法,允許 GPU 渲染一個非常便宜但看起來很糟糕的單通道,並且不知何故——通過人工智能魔法——將它變成了遊戲玩家想要看到的東西。 當與傳統的基於光柵化的技術相結合時,它可以通過光線追踪效果增強令人愉悅的體驗。

然而,為了快速做到這一點,NVIDIA 添加了稱為 Tensor 核心的 AI 特定處理核心。 這些處理運行機器學習模型所需的所有數學運算,並且速度非常快。 它們是雲服務器領域人工智能的徹底改變者,因為人工智能被許多公司廣泛使用。
除了去噪,Tensor 核心對遊戲玩家的主要用途稱為 DLSS,或深度學習超級採樣。 它採用低質量的幀並將其升級為完全原生質量。 這實質上意味著您可以在觀看 4K 圖片的同時以 1080p 級別的幀速率進行遊戲。

這也有助於提高光線追踪性能——來自 PCMag 的基準測試顯示 RTX 2080 Super 以超高品質運行控制,所有光線追踪設置都已調到最大。 在 4K 下,它只有 19 FPS,但在 DLSS 上,它獲得了更好的 54 FPS。 DLSS 是 NVIDIA 的免費性能,由 Turing 和 Ampere 上的 Tensor 內核實現。 任何支持它並且受 GPU 限制的遊戲都可以僅從軟件中看到嚴重的加速。
DLSS 並不是什麼新鮮事物,兩年前推出 RTX 2000 系列時,它就被宣佈為一項功能。 當時,很少有遊戲支持它,因為它需要 NVIDIA 為每個單獨的遊戲訓練和調整機器學習模型。
然而,在那個時候,NVIDIA已經對其進行了徹底的改寫,稱之為新版本DLSS 2.0。 它是一個通用 API,這意味著任何開發人員都可以實現它,並且它已經被大多數主要版本所採用。 它不是處理一幀,而是從前一幀中獲取運動矢量數據,類似於 TAA。 結果比 DLSS 1.0 清晰得多,在某些情況下,實際上看起來甚至比原始分辨率更好、更清晰,因此沒有太多理由不打開它。
有一個問題——當完全切換場景時,比如在過場動畫中,DLSS 2.0 必須在等待運動矢量數據的同時以 50% 的質量渲染第一幀。 這可能會導致幾毫秒的質量輕微下降。 但是,你看到的 99% 的東西都會被正確渲染,而大多數人在實踐中並沒有註意到這一點。
相關:什麼是 NVIDIA DLSS,它將如何使光線追踪更快?
安培架構:為人工智能而生
安培速度很快。 速度非常快,尤其是在 AI 計算方面。 RT 核心比 Turing 快 1.7 倍,新的 Tensor 核心比 Turing 快 2.7 倍。 兩者的結合是光線追踪性能真正的代際飛躍。

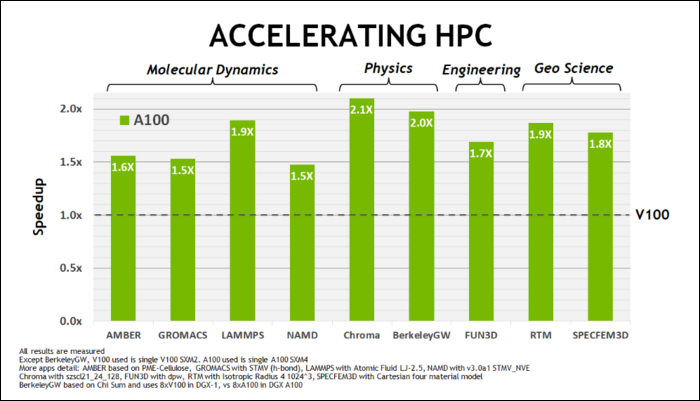
今年 5 月初,NVIDIA 發布了 Ampere A100 GPU,這是一款專為運行 AI 而設計的數據中心 GPU。 有了它,他們詳細說明了很多使 Ampere 速度如此之快的原因。 對於數據中心和高性能計算工作負載,Ampere 通常比 Turing 快 1.7 倍左右。 對於 AI 訓練,它的速度最高可達 6 倍。
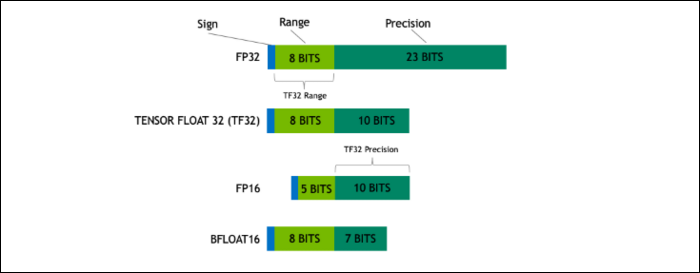
借助 Ampere,NVIDIA 正在使用一種新的數字格式,旨在在某些工作負載中取代行業標準的“浮點 32”或 FP32。 在後台,您的計算機處理的每個數字都會佔用內存中預定義的位數,無論是 8 位、16 位、32 位、64 位還是更大。 更大的數字更難處理,所以如果你可以使用更小的數字,你就會減少處理。
FP32 存儲一個 32 位的十進制數,它使用 8 位來表示數字的範圍(可以有多大或多小),使用 23 位來表示精度。 NVIDIA 聲稱,這 23 個精度位對於許多 AI 工作負載來說並不是完全必要的,您可以從其中的 10 個中獲得類似的結果和更好的性能。 將大小減少到僅 19 位,而不是 32 位,在許多計算中都有很大的不同。
這種新格式稱為 Tensor Float 32,A100 中的 Tensor Cores 經過優化以處理奇怪大小的格式。 這就是,除了芯片縮小和核心數量增加之外,他們如何在 AI 訓練中獲得 6 倍的巨大加速。
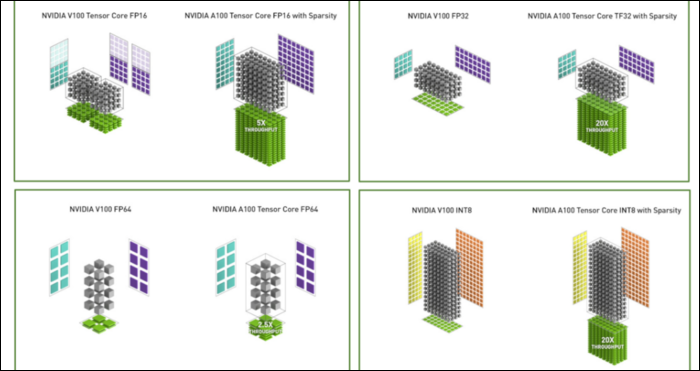
除了新的數字格式之外,Ampere 在特定計算(如 FP32 和 FP64)中看到了主要的性能加速。 對於外行來說,這些並不會直接轉化為更高的 FPS,但它們是使其在 Tensor 操作中整體速度快近三倍的部分原因。
然後,為了進一步加快計算速度,他們引入了細粒度結構化稀疏的概念,對於一個非常簡單的概念來說,這是一個非常花哨的詞。 神經網絡使用大量的數字列表,稱為權重,它們會影響最終輸出。 要處理的數字越多,它就會越慢。
然而,並非所有這些數字都是真正有用的。 其中一些實際上只是零,並且基本上可以被丟棄,當您可以同時處理更多數字時,這會導致巨大的加速。 稀疏性本質上壓縮了數字,從而減少了計算工作量。 新的“稀疏張量核心”旨在對壓縮數據進行操作。
儘管發生了這些變化,NVIDIA 表示這根本不會顯著影響訓練模型的準確性。
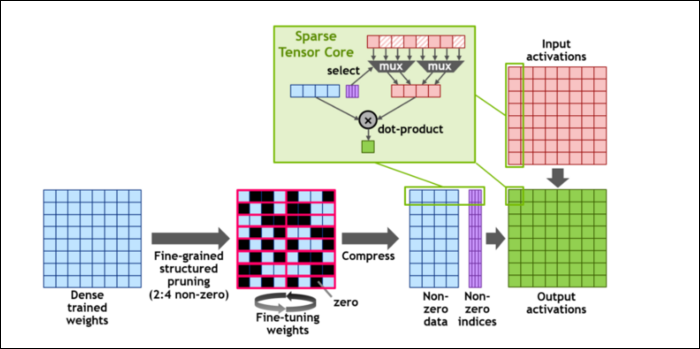
對於最小數字格式之一的稀疏 INT8 計算,單個 A100 GPU 的峰值性能超過 1.25 PetaFLOPs,這是一個驚人的高數字。 當然,這只是在處理一種特定的數字時,但它仍然令人印象深刻。