
如何保護您的圖像免受 AI 藝術生成器的侵害
已發表: 2023-03-24
- 使用 HaveIBeenTrained.com 等工具選擇退出訓練數據集。
- 使用“robots.txt”文件來抵禦網絡爬蟲,其中許多首先用於創建數據集。
- 為您的作品版權並在法庭上挑戰這些工具的開發者(或加入現有的集體訴訟)。
- 僅上傳帶有強烈水印的圖像。
- 首先要避免將您的藝術作品放到互聯網上。
AI 藝術生成器可能無法模仿人類的創造力,但它們肯定會敲詐你。 這對藝術家和那些害怕 AI 接管的人來說都是一個擔憂,但可能不會失去一切。
如何保護受版權保護的藝術免受 AI 侵害
如果沒有訓練它們的數據集,人工智能藝術生成器就什麼都不是。 這涉及從現有藝術品中提取大量樣本,並以一種允許人類使用自然語言提示來創作類似藝術品的方式對其進行語境化。 您可以使用 OpenAI 的 DALL-E 2 或 Midjourney 等生成藝術應用程序親自嘗試。
我們要求 DALL-E 2 製作“一張來自芝麻街的 Elmo 的 Pablo Picasso 風格的照片”,這就是我們得到的(是的,這是最好的):

能夠以已故藝術家的風格創作藝術品可能不會引起太多警鐘,尤其是在一種如此知名的風格中。 但對於通過 ArtStation、DeviantArt、Behance、個人網站和社交媒體頁面(如 Instagram 或 Facebook)分享他們的創作的現代藝術家來說,這更令人擔憂。
那麼你能做些什麼來保護你自己的創作不被用來訓練一個可以比你更快地吐出創作的人工智能呢?
選擇退出訓練數據集
您可以使用 HaveIBeenTrained.com 選擇退出互聯網上最大的兩個開放圖像訓練數據集 LAION-400M 和 LAION-5B。 這些數據集被網絡上一些最大的圖像生成器使用,包括 Stable Diffusion 和 Google Imagen。 因為它們是真正開放的,所以許多其他生成式 AI 工具也使用它們。
不幸的是,這樣做的過程緩慢而乏味。 您需要先註冊一個帳戶,然後搜索或上傳圖像以在數據集中查找匹配項。 然後,您可以在桌面網絡瀏覽器中右鍵單擊該圖像,然後選擇“添加到我的退出”選項。 或者,您可以通過單擊“添加到我的選擇加入”來授予數據集使用圖像的明確權限。
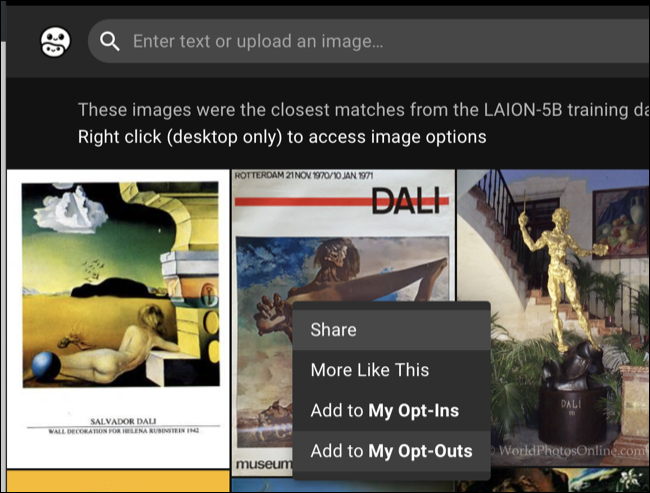
您需要為找到的每張圖像執行此操作,因此如果您是一位擁有大量作品的藝術家,這可能是一個艱苦的過程。 實際上需要多長時間最終取決於過濾掉你的作品的難易程度,如果你的作品與一個獨特的名稱或項目相關聯,有大量的在線追隨者等等,這可能會更容易。
儘管這兩個龐大的數據集是一個很好的起點,但它們遠非唯一使用的數據集。 個人可以創建自己的數據集,有些人可以復制特定的藝術家或藝術風格。 像 OpenAI 這樣的一些公司根本不透露他們的工具使用了哪些數據集,所以沒有辦法對抗這些。
使用 Robots.txt 抵禦爬蟲
robots.txt 文件是放置在網站根目錄中的一個小文本文檔,用於告訴網絡爬蟲允許或不允許它們去哪裡。 儘管 Google 明確聲明“這不是一種讓網頁遠離 Google 的機制”,但如果您將作品託管在自己的網站上,您可能仍想嘗試使用它來讓網絡爬蟲遠離您的作品。
顧名思義,網絡爬蟲在網絡上爬行以搜索索引內容。 搜索引擎遠非唯一的爬蟲,爬蟲還用於創建數據集,很像上面提到的 LAION-400M 和 LAION-5B 數據集。 robots.txt 的主要問題是它依賴於網絡爬蟲尊重您的請求。
Common Crawl 是最大的數據集之一,其數據已用於構建 LAION 的數據集。 抓取網絡的過程是一個持續的過程,LAION 表示其當前(在撰寫本文時)LAION-400M 數據集是“從 2014 年至 2021 年期間抓取的隨機網頁”創建的。
Common Crawl 聲明它在阻止內容和延遲抓取(以節省帶寬)方面尊重 robots.txt 和機器人排除協議。 您可以通過在 Robots.txt 文件中為“CCBot”用戶代理創建規則來做到這一點。 當然,如果您不是自行託管您的作品,那麼這些都無濟於事。
Google 搜索中心有一個創建 robots.txt 文件的便捷指南,或者您可以使用像 Ryte 的 Robots.txt 生成器這樣的網站為您創建一個。 您可以允許或禁用來自特定目錄的特定用戶代理,或者簡單地使用通配符 (*) 阻止所有內容。 例如,一個 robots.txt 文件會阻止 Common Crawl 訪問您 /images/ 目錄中的所有文件,同時仍允許其他爬蟲為您的網站編制索引:
用戶代理:CCbot 不允許:/圖片/ 用戶代理: * 允許: / 站點地圖:https://www.example.com/sitemap.xml
這不會打敗已經訪問過您網站的爬蟲,但它應該可以防止 Common Crawl 將來索引您的 /images/ 文件夾(以及自上次爬網以來的任何新上傳)。
版權您的作品
儘管版權隱含在您創作的作品中,但不遺餘力地為您的作品爭取版權也可能是值得的。 在美國,您可以通過在 Copyright.gov 上註冊您的作品來做到這一點。 您可以在一個申請中提交最多 10 件未發表的作品,但請注意,處理您的作品可能需要一段時間(目前大約一年)。
為您的作品註冊版權可以讓您在涉及法院的事務中更有立足之地。 這就是針對 Stability AI(Stable Diffusion 和 DreamStudio 的開發者,LAION 的資助者)、DeviantArt(藝術家平台和 DreamUp 的開發者)和代表受影響藝術家的生成藝術應用程序 Midjourney 提起集體訴訟背後的想法.

你可以在 StableDiffusionLitigation.com 上閱讀所有關於訴訟的信息,如果你認為你的工作已被用來訓練這些生成器,那麼你可能有理由通過聯繫法律團隊來加入集體訴訟。 如果您想走這條路,那麼向美國版權局申請註冊您的藝術作品是重要的第一步。
與過去吸引律師的其他做法(盜版、越獄、文件共享)一樣,訴訟不太可能完全阻止這種做法。 辯方可能會爭辯說,這些工具是根據從面向公眾的網站收集的“合理使用”材料進行培訓的。 我們將不得不拭目以待,看看此類訴訟會產生什麼影響(如果有的話)。
激進水印
如果您只上傳帶有一些激進或邊緣自毀水印的藝術作品,則數據集中包含的藝術作品將反映這一點。 最終,這在很大程度上取決於首先上傳您的作品的原因。 如果您非商業地創作藝術品是為了享受互聯網的樂趣,這似乎最終會弄巧成拙。

但是,如果您要銷售真實世界的畫作並希望在銷售前在線展示它們,這可能會有所幫助。 它肯定會減損完成的藝術品,所以這是你必須自己考慮的事情。
不要在互聯網上上傳您的作品
這聽起來可能很荒謬(確實如此),但如果你的作品一開始就沒有上傳到互聯網,它就不可能被抓到網上並用於訓練人工智能。 當然,如果不使用互聯網分享您的作品而以藝術家的身份謀生可能幾乎是不可能的(尤其是如果您使用數字媒體工作)。
對於從事音樂工作的藝術家來說,這是不可能的。 即使您使用油畫或水彩等傳統材料,也無法判斷是否有人會為完成的作品拍照並自行上傳。
人工智能藝術能獲得版權嗎?
生成式 AI 的輸出是否可以受版權保護是一個複雜的問題。 普遍接受的一件事是,用於生成藝術的人工智能工具很少對輸出有任何權利。
這在大多數工具的服務條款中都有明確說明,包括 Stable Diffusion:
除此處規定外,許可方對您使用模型生成的輸出不主張任何權利。 您對您生成的輸出及其後續使用負責。 任何輸出的使用都不能違反許可證中規定的任何條款。
該許可證繼續禁止任何“違反任何適用的國家、聯邦、州、地方或國際法律或法規”的使用,其中包括版權法。
中途:
在現行法律允許的範圍內,您擁有您使用服務創建的所有資產。 這不包括放大其他人的圖像,這些圖像仍歸原始資產創建者所有。
和 OpenAI(DALL-E 2):
在雙方之間,在適用法律允許的範圍內,您擁有所有輸入,並且在您遵守這些條款的前提下,OpenAI 特此向您轉讓其對輸出的所有權利、所有權和權益。
關於使用此類工具創作的任何作品的版權,美國版權局已聲明版權僅適用於人類創作的藝術(以及其他要求,如原創性):
在聲稱非人類作者身份的情況下,上訴法院發現版權不保護所謂的創作。
法律在不斷發展,所以這在未來可能會被成功挑戰。 還值得注意的是,即使其他元素(如藝術品或音樂)不是 AI 生成器的產品(如情節或對話),最終產品的元素仍然可以獲得版權。
人工智能藝術生成器可以使用我受版權保護的藝術嗎?
問題不一定是 AI 生成器“可以”使用您的受版權保護的藝術作品,而是他們已經“可以”使用您的受版權保護的藝術作品。 正如許多藝術家發現的那樣,這個問題的答案是肯定的。 上面我們討論了一些選擇退出數據集和防止爬蟲將您的內容編入索引的方法,但這些技術最終取決於掌舵人是否尊重您的偏好。
您可以使用 HaveIBeenTrained.com 查看您的藝術作品是否包含在最大的公共圖像數據集中。 上傳您較為知名的藝術作品之一,或搜索您的姓名、作品名稱、網絡漫畫或其他創作並查看。 如果您看到自己的作品出現在網站上,則表明您的作品包含在 Stable Diffusion 和其他公司使用的數據集中。
更不用說其他不公開正在使用哪些數據集的生成藝術應用程序(如 OpenAI 的 DALL-E)。 您可以隨時嘗試提示“您的名字風格的藝術品”,看看是否有任何熟悉的東西出現。
即將推出的工具可能有助於擊敗 AI 藝術生成器
藝術家可能會有一些希望以工具的形式出現,這些工具可以使生成人工智能更難根據數據集中的圖像複製藝術品。 不幸的是,這些解決方案還沒有出現(在撰寫本文時),而且從長遠來看它們的效果如何也不得而知。 人工智能工具發展迅速,因此它們有可能發展以規避此類保護措施。
第一個是 Glaze,這是芝加哥大學的一個項目,在上傳之前對藝術品“添加非常小的變化”。 開發人員將這些變化稱為“風格斗篷”,並指出藝術作品在人眼看來與原作幾乎相同,同時導致 AI 將風格誤解為另一種風格。
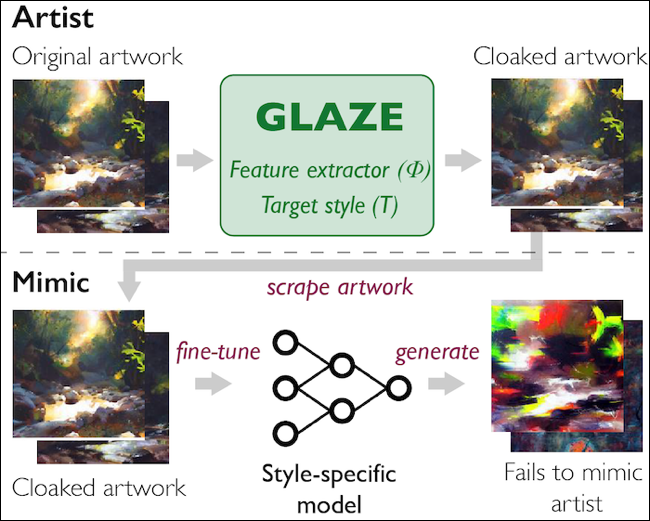
Glaze 將作為適用於 Mac 和 Windows 的應用程序發布,因此無需離開藝術家的計算機即可“隱藏”藝術品。 開發人員表示他們不會將該工具商業化,因此任何人都可以免費使用。 Glaze 項目將該工具視為“邁向以藝術家為中心的保護工具以抵制 AI 模仿的必要的第一步。”
墨爾本大學 Pursuit 博客中概述的另一種技術描述了噪聲的微妙使用,這種噪聲“改變圖像中足夠多的像素以混淆 AI,並將其轉變為‘無法學習’的圖像。” 該機構聲稱已經提出了一種利用模型弱點的技術,甚至將 Stable Diffusion 等工具描述為“懶惰的學習者”。
這種技術具有廣泛的潛在用途,包括視覺藝術作品以及可以識別您個人身份的音頻和照片。 重要的是要認識到這些技術在開發方面仍處於早期階段,因此我們必須拭目以待,看看它們的真正能力。
機器人的崛起
生成藝術應用程序可以立即創作藝術品,但它們並不像人類那樣真正具有創造力。 ChatGPT 或許能夠撰寫您的簡歷,但您需要仔細校對它,因為聊天機器人通常會自信地犯錯。
最重要的是,當前的人工智能解決方案可能有用,但也很薄弱。