
如何使用 grep 排除模式、文件和目錄
已發表: 2022-06-29
自 1974 年以來,Linux grep命令一直在幫助人們在文件中查找字符串。 但有時grep太徹底了。 這裡有幾種方法可以告訴grep忽略不同的事情。
grep 命令
grep命令搜索文本文件以查找與您在命令行中提供的搜索模式相匹配的字符串。 grep的強大之處在於它使用正則表達式。 這些可以讓您描述您要查找的內容,而不必明確定義它。
grep的誕生早於 Linux。 它是在 1970 年代早期在 Unix 上開發的。 它的名字來源於ed行編輯器中的 g/re/p 鍵序列(順便說一下,發音為“ee-dee”)。 這代表全局、常規快速搜索、打印匹配行。
grep是出了名的——也許是臭名昭著的——徹底而專一。 有時它會搜索您不希望它浪費時間的文件或目錄,因為結果可能會讓您無法只見樹木不見森林。

當然,有一些方法可以控制 grep。您可以告訴它忽略模式、文件和目錄,以便 grep 更快地完成搜索,並且您不會被無意義的誤報所淹沒。
排除模式
要使用grep進行搜索,您可以通過管道從其他進程(例如cat )向其輸入輸入,或者您可以提供文件名作為最後一個命令行參數。
我們正在使用一個短文件,其中包含 Lewis Carroll 的詩歌Jabberwocky的文本。 在這兩個示例中,我們正在搜索與搜索詞“Jabberwock”匹配的行。
貓jabberwocky.txt | grep "Jabberwock"
grep "Jabberwock" jabberwocky.text
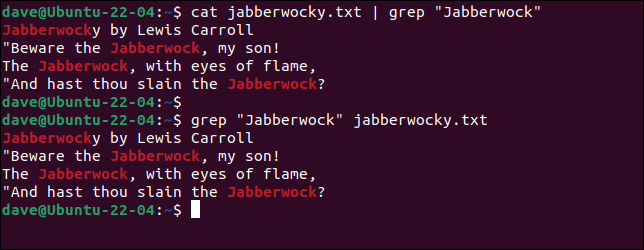
為我們列出了包含與搜索線索匹配的行,每行中的匹配元素以紅色突出顯示。 這是簡單的搜索。 但是,如果我們想排除包含“Jabberwock”這個詞的行並打印其餘的行怎麼辦?
我們可以使用-v (反轉匹配)選項來實現這一點。 這列出了與搜索詞不匹配的行。
grep -v "Jabberwock" jabberwocky.text

不包含“Jabberwock”的行會在終端窗口中列出。
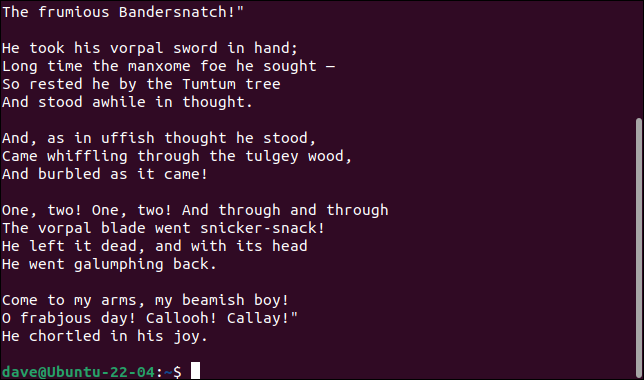
我們可以根據需要排除盡可能多的術語。 讓我們過濾掉任何包含“Jabberwock”的行和任何包含“and”的行。 為此,我們將使用-e (表達式)選項。 我們需要將它用於我們正在使用的每個搜索模式。
grep -v -e "Jabberwock" -e "and" jabberwocky.txt

輸出中的行數相應減少。
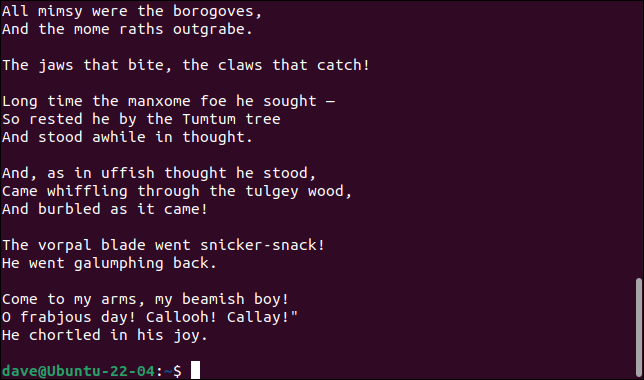
如果我們使用-E (擴展正則表達式)選項,我們可以將搜索模式與“ | “,在這種情況下並不表示管道,它是邏輯OR運算符。
grep -Ev "Jabberwock|and" jabberwocky.txt

我們得到的輸出與之前的冗長命令完全相同。
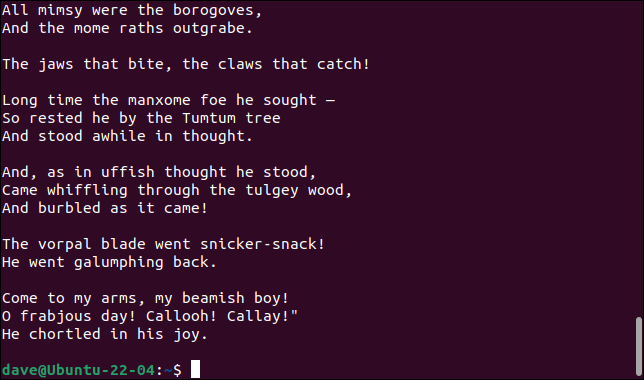
如果您想使用正則表達式模式而不是顯式搜索線索,則命令的格式是相同的。 此命令將排除以“ACHT”集中任何字母開頭的所有行。
grep -Ev "^ACHT" jabberwocky.txt
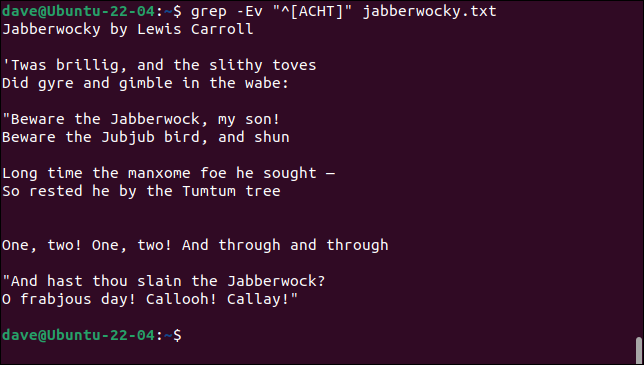
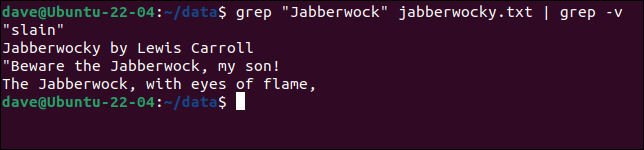
要查看包含一個模式但也不包含另一個模式的行,我們可以將grep給grep 。 我們將搜索所有包含單詞“Jabberwock”的行,然後過濾掉所有包含單詞“ slain ”的行。
grep "Jabberwock" jabberwocky.txt | grep -v "被殺"

排除文件
我們可以讓grep在文件集合中查找字符串或模式。 您可以在命令行上列出每個文件,但是對於許多文件,這種方法無法擴展。
grep "vorpal" verse-1.txt verse-2.txt verse-3.txt verse-4.txt verse-5.txt verse-6.txt
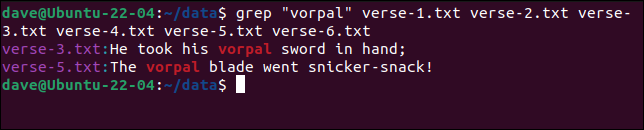
請注意,包含匹配行的文件的名稱顯示在每行輸出的開頭。
為了減少打字,我們可以使用通配符。 但這可能違反直覺。 這似乎有效。
grep "vorpal" *.txt

但是,在這個目錄下還有其他的TXT文件,與詩歌無關。 如果我們用相同的命令結構搜索“劍”這個詞,我們會得到很多誤報。
grep "劍" *.txt

我們想要的結果被來自其他具有 TXT 擴展名的文件的大量錯誤結果所掩蓋。
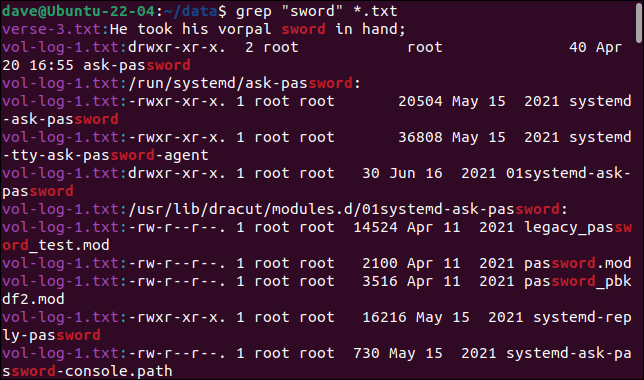
“vorpal”這個詞不匹配任何東西,但是“sword”包含在“password”這個詞中,因此在一些偽日誌文件中多次找到它。
我們需要排除這些文件。 為此,我們將使用--exclude選項。 要排除名為“vol-log-1.txt”的單個文件,我們將使用以下命令:
grep --exclude=vol-log-1.txt "劍" *.txt
在這種情況下,我們要排除多個名稱以“vol”開頭的日誌文件。 我們需要的語法是:
grep --exclude=vol*.txt "劍" *.txt

當我們使用-R (dereference-recursive) 選項時, grep將為我們搜索整個目錄樹。 默認情況下,它將搜索這些位置的所有文件。 我們可能希望排除多種類型的文件。
在這台測試機器上的當前目錄下,有嵌套的目錄,其中包含日誌文件、CSV 文件和 MD 文件。 這些是我們要排除的所有類型的文本文件。 我們可以為每種文件類型使用--exclude選項,但是我們可以通過對文件類型進行分組來更有效地實現我們想要的。
此命令排除所有具有 CSV 或 MD 擴展名的文件,以及所有名稱以“vol”或“log”開頭的 TXT 文件。
grep -R --exclude=*.{csv,md} --exclude={vol*,log*}.txt "sword" /home/dave/data/ 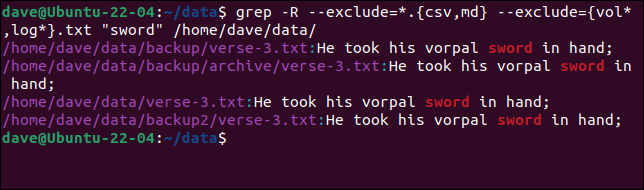
排除目錄
如果我們要忽略的文件包含在目錄中,並且這些目錄中沒有我們想要搜索的文件,我們可以排除這些整個目錄。
這個概念與排除文件的概念非常相似,只是我們使用--exclude-dir選項並命名要忽略的目錄。
grep -R --exclude-dir=backup "vorpal" /home/dave/data
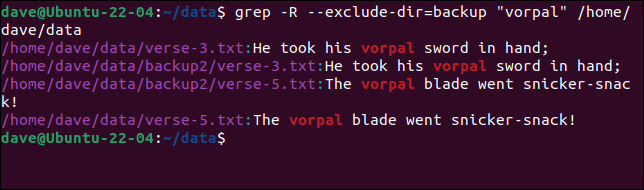
我們已經排除了“backup”目錄,但我們仍在搜索另一個名為“backup2”的目錄。
我們可以在一個命令中多次使用--exclude-dir選項也就不足為奇了。 請注意,排除目錄的路徑應相對於搜索開始的目錄給出。不要使用文件系統根目錄的絕對路徑。
grep -R --exclude-dir=backup --exclude-dir=backup2 "vorpal" /home/dave/data
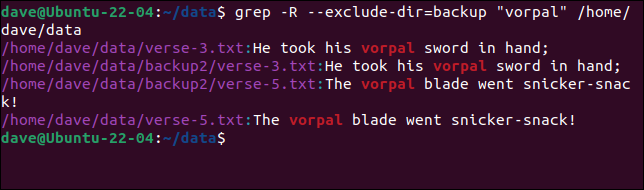
我們也可以使用分組。 我們可以通過以下方式更簡潔地實現相同的目標:
grep -R --exclude-dir={backup,backup2} "vorpal" /home/dave/data 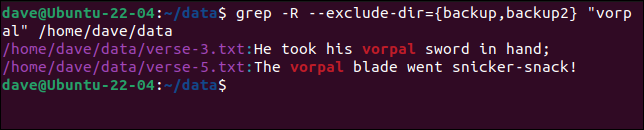
您可以在同一命令中組合文件和目錄排除項。 如果要從目錄中排除所有文件並從搜索的目錄中排除某些文件類型,請使用以下語法:
grep -R --exclude=*.{csv,md} --exclude-dir=backup/archive "frumious" /home/dave/data 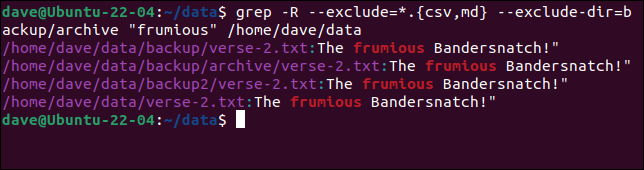
有時這是你遺漏的
有時使用grep感覺就像是在大海撈針。 移除乾草堆有很大的不同。
相關:如何在 Linux 上使用正則表達式(regexes)