
如何使用 Tesseract 從 Linux 命令行執行 OCR
已發表: 2022-01-29
您可以使用 Tesseract OCR 引擎在 Linux 命令行上從圖像中提取文本。 它快速、準確,支持大約 100 種語言。 以下是如何使用它。
光學字符識別
光學字符識別 (OCR) 是一種查看和查找圖像中的單詞,然後將它們提取為可編輯文本的能力。 對於人類來說,這個簡單的任務對於計算機來說是非常困難的。 至少可以說,早期的努力很笨拙。 如果字體或大小不符合 OCR 軟件的喜好,計算機通常會感到困惑。
儘管如此,這一領域的先驅者仍然受到高度尊重。 如果您丟失了文檔的電子副本,但仍有打印版本,OCR 可以重新創建可編輯的電子版本。 即使結果不是 100% 準確,這仍然可以節省大量時間。
通過一些手動整理,您將獲得您的文檔。 人們原諒了它所犯的錯誤,因為他們了解 OCR 包所面臨的任務的複雜性。 另外,這比重新輸入整個文檔要好。
從那以後,情況有了顯著改善。 由 Hewlett Packard 編寫的 Tesseract OCR 應用程序於 1980 年代作為商業應用程序開始。 它於 2005 年開源,現在得到 Google 的支持。 它具有多語言功能,被認為是可用的最準確的 OCR 系統之一,您可以免費使用它。
安裝 Tesseract OCR
要在 Ubuntu 上安裝 Tesseract OCR,請使用以下命令:
sudo apt-get install tesseract-ocr

在 Fedora 上,命令是:
須藤 dnf 安裝 tesseract

在 Manjaro 上,您需要輸入:
sudo pacman -Syu tesseract

使用 Tesseract OCR
我們將對 Tesseract OCR 提出一系列挑戰。 我們的第一個包含文本的圖像是從《通用數據保護條例》的第 63 條獨奏會中摘錄的。 讓我們看看 OCR 是否可以讀取(並保持清醒)。

這是一個棘手的圖像,因為每個句子都以微弱的上標數字開頭,這在立法文件中很常見。
我們需要給tesseract命令一些信息,包括:
- 我們希望它處理的圖像文件的名稱。
- 它將創建以保存提取的文本的文本文件的名稱。 我們不必提供文件擴展名(它始終是 .txt)。 如果同名文件已經存在,它將被覆蓋。
- 我們可以使用
--dpi選項告訴tesseract圖像的每英寸點數 (dpi) 分辨率是多少。 如果我們不提供 dpi 值,tesseract會嘗試找出它。
我們的圖像文件名為“recital-63.png”,其分辨率為 150 dpi。 我們將從它創建一個名為“recital.txt”的文本文件。
我們的命令如下所示:
tesseract 獨奏會-63.png 獨奏會--dpi 150

結果非常好。 唯一的問題是上標——它們太暗而無法正確閱讀。 高質量的圖像對於獲得良好的效果至關重要。

tesseract已將上標數字解釋為引號 (") 和度數符號 (°),但實際文本已被完美提取(必須修剪圖像的右側以適合此處)。
最後一個字符是一個字節,十六進制值為0x0C,即回車。
下面是另一張不同大小的文字圖片,包括粗體和斜體。

該文件的名稱是“bold-italic.png”。 我們要創建一個名為“bold.txt”的文本文件,所以我們的命令是:
tesseract粗體斜體.png粗體--dpi 150

這篇沒有任何問題,文本被完美地提取出來。

使用不同的語言
Tesseract OCR 支持大約 100 種語言。 要使用一種語言,您必須先安裝它。 當您在列表中找到要使用的語言時,請記下其縮寫。 我們將安裝對威爾士語的支持。 它的縮寫是“cym”,是“Cymru”的縮寫,意思是威爾士語。
安裝包名為“tesseract-ocr-”,末尾標註語言縮寫。 要在 Ubuntu 中安裝威爾士語言文件,我們將使用:
sudo apt-get install tesseract-ocr-cym


帶有文字的圖像如下。 這是威爾士國歌的第一節。

讓我們看看 Tesseract OCR 是否能夠應對挑戰。 我們將使用-l (語言)選項讓tesseract知道我們想要使用的語言:
tesseract hen-wlad-fy-nhadau.png 國歌 -l cym --dpi 150

tesseract完美應對,如下面的摘錄文本所示。 Da iawn ,正方體 OCR。

如果您的文檔包含兩種或多種語言(例如威爾士語到英語詞典),您可以使用加號 ( + ) 告訴tesseract添加另一種語言,如下所示:
tesseract image.png 文本文件 -l eng+cym+fra
將 Tesseract OCR 與 PDF 結合使用
tesseract命令旨在處理圖像文件,但它無法讀取 PDF。 但是,如果您需要從 PDF 中提取文本,您可以先使用另一個實用程序來生成一組圖像。 單個圖像將代表 PDF 的單個頁面。
您需要的pdftppm實用程序應該已經安裝在您的 Linux 計算機上。 我們將用於示例的 PDF 是 Alan Turing 關於人工智能的開創性論文“計算機與智能”的副本。

我們使用-png選項來指定我們要創建 PNG 文件。 我們的 PDF 文件名為“turing.pdf”。 我們將圖像文件命名為“turing-01.png”、“turing-02.png”等:
pdftoppm -png 圖靈.pdf 圖靈

要使用單個命令對每個圖像文件運行tesseract ,我們需要使用 for 循環。 對於我們的每個“turing- nn.png ”文件,我們運行tesseract ,並創建一個名為“text-”的文本文件,加上“turing- nn ”作為圖像文件名的一部分:
對於我在圖靈-??.png; 做 tesseract "$i" "text-$i" -l eng; 完畢;

要將所有文本文件合併為一個,我們可以使用cat :
cat text-turing* > complete.txt

那麼,它是怎麼做的呢? 很好,如下所示。 不過,第一頁看起來很有挑戰性。 它具有不同的文本樣式和大小以及裝飾。 頁面右邊緣還有一個垂直的“水印”。
但是,輸出接近原始。 顯然,格式丟失了,但文本是正確的。
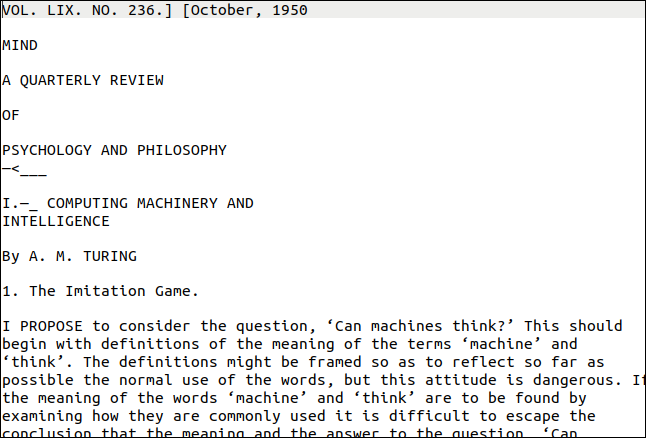
垂直水印被轉錄為頁面底部的一行亂碼。 文本太小,無法被tesseract準確讀取,但很容易找到並刪除它。 最糟糕的結果將是每行末尾的雜散字符。
奇怪的是,第二頁問題和答案列表開頭的單個字母被忽略了。 PDF 中的部分如下所示。

正如您在下面看到的,問題仍然存在,但每行開頭的“Q”和“A”都丟失了。

圖表也不會被正確轉錄。 讓我們看看當我們嘗試從圖靈 PDF 中提取如下所示的內容時會發生什麼。

正如您在下面的結果中看到的那樣,字符被讀取,但圖表的格式丟失了。

再次, tesseract與小尺寸的下標作鬥爭,並且它們被錯誤地渲染。
不過,平心而論,這仍然是一個不錯的結果。 我們無法提取簡單的文本,但後來故意選擇了這個示例,因為它提出了挑戰。
需要時的好解決方案
OCR 不是您每天都需要使用的東西。 但是,當確實需要時,很高興知道您擁有最好的 OCR 引擎之一。