
如何在 Linux 上比較二進製文件
已發表: 2022-08-20
如何檢查兩個 Linux 二進製文件是否相同? 如果它們是可執行文件,則任何差異都可能意味著不需要的或惡意的行為。 這是檢查它們是否不同的最簡單方法。
比較二進製文件
Linux 有豐富的方法來比較和分析文本文件。 diff命令將為您比較兩個文件,並突出顯示差異。 它甚至可以在更改的兩側提供幾行,以圍繞更改的行提供一些上下文。 colordiff命令添加顏色,使視覺上的差異解析更加容易。
開發人員和作者使用diff來突出顯示不同版本的程序源代碼文件或草稿文本之間的差異。 它快速簡單,您不需要任何技術技能即可查看文本字符串之間的差異。
在二進製文件的世界裡,事情並不是那麼簡單。 二進製文件不是由純文本組成的。 它們由許多包含數值的字節組成。 如果它是壓縮文件,例如 TAR 存檔或 ZIP 文件,則這些值表示存儲在存檔文件中的壓縮文件,以及解壓縮和提取文件所需的符號表。

如果二進製文件是可執行文件,則文件字節的數值被解釋為 CPU 的機器代碼指令、元數據、標籤或編碼數據。 當二進製文件執行或被另一個應用程序使用時,對二進製文件或庫文件的更改可能會導致行為差異。
欺騙文件的創建或修改日期和時間很容易。 這意味著可能有兩個版本的文件具有相同的名稱、文件大小(如果更改逐字節替換現有內容)和日期戳。 然而,其中一個文件可能已被更改。
安全哈希算法
安全哈希算法是一種基於數學的算法。 它通過掃描文件中的所有字節並對它們應用數學變換以生成哈希值來創建一個 64 位值。 在任何一天,同一個文件總是會產生相同的哈希值。 即使是一個字節的差異也會導致完全不同的哈希值。
您經常會在其下載頁面上看到文件的哈希值。 下載文件後,您應該為該文件生成一個哈希值。 如果它與網頁上顯示的哈希值不同,則表明該文件已被盜用。 它要么被篡改並替換了真實文件(以使人們下載受污染的文件),要么在傳輸過程中被損壞。
在我們的測試計算機上,我們有同一個文件的兩個副本,一個共享庫。 這些文件已被重命名,以便它們可以位於同一目錄中。 理論上,這些文件應該是相同的。 畢竟,它們應該是共享庫的相同版本。
ls -l *.so

這些文件具有相同的大小、相同的日期戳和相同的時間戳。 對於不經意的觀察者來說,它們看起來是一樣的。 讓我們使用sha256sum命令並為每個文件生成一個哈希。
sha256sum binary_file1.so
sha256sum binary_file2.so
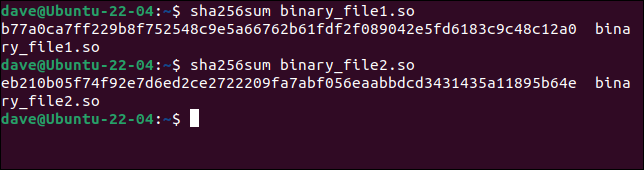
哈希完全不同,清楚地表明兩個文件之間存在差異。 如果網站顯示正版文件的哈希,您可以丟棄不匹配的文件。
尋找差異
如果您想查看更改,也有辦法做到這一點。 你不需要能夠反編譯文件,也不需要理解彙編或機器代碼就可以看到修改。 理解這些變化意味著什麼,以及它們的目的是什麼,當然需要更深入的技術知識。 但只要知道這些變化有多大就可以表明文件發生了什麼。
如果我們在這兩個二進製文件上使用diff ,我們會得到一個有點平淡無奇的響應。
diff binary_file1.so binary_file2.so

我們已經知道這些文件是不同的。 讓我們試試cmp 。
cmp binary_file1.so binary_file2.so

這告訴我們更多一點。 兩個文件不同的第一個字節是字節數13451。即從二進製文件的開頭算起,兩個二進製文件的字節13451不同。 所以 13451 是第一個差異的偏移量,從文件的開頭開始。
偶然地,在整個文件中,會有包含十六進制值 0x10 的字節。 這是 Linux 在文本文件中用作行尾字符的值。 cmp命令在二進製文件的開頭和第一個差異的位置之間遇到了 131 個字節和這個值。 所以它認為它在第 132 行。在這種情況下,它真的沒有任何意義。
如果我們添加-l (詳細)選項,我們將開始獲得有用的信息。
cmp -l binary_file1.so binary_file2.so
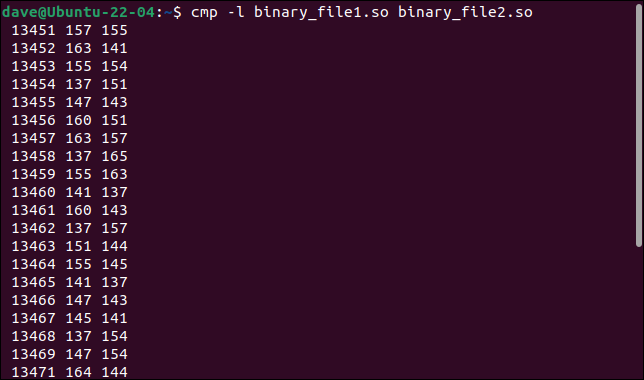
列出了所有不同的字節。 顯示字節數或偏移量、第一個文件的值和第二個文件的值,每行輸出一個字節。
字節值以八進制顯示,而不是二進製文件使用的通常十六進制格式。 儘管如此,我們還是學到了一些別的東西。 所有改變的字節都在一個連續的序列中。 它們的偏移量每字節增加一。
hexdump工具會將二進製文件轉儲到終端窗口。 如果我們使用-C (規範)選項,輸出將在每一行列出偏移量、該偏移量處 16 個字節的值,以及(如果有的話)字節值的 ASCII 表示。

hexdump -C binary_file1.so
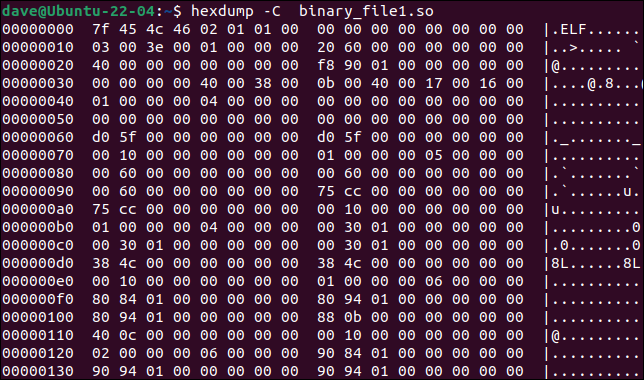
我們可以使用hexdump的輸出作為diff的輸入,讓diff像讀取兩個文本文件一樣工作。
差異<(hexdump binary_file1.so)<(hexdump binary_file2.so)
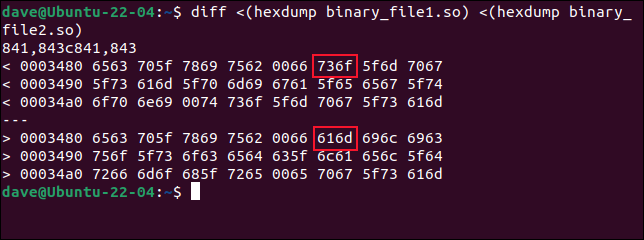
diff查找不同的行,並將第一個文件中的十六進製字節值顯示在第二個文件中的值之上。 第一行的偏移量是 0x3480,即十進制的 13440。 早些時候, cmp告訴我們第一個變化發生在字節 13451,即 0x348B。 這實際上與我們在這裡看到的相符。
diff的輸出是兩個字節的塊。 第一對字節是偏移量 0x3480 的字節 0 和 1,第二個塊保存偏移量的字節 2 和 3。 塊 6 將保存字節 0xA 和 0xB,或十進制的 10 和 11。 這些是字節 13450 和 13451。我們可以看到它們是第一個不同的字節。 兩個文件中的前五對字節相同。
但是,因為diff從零開始計數,所以cmp調用的 13451 將是字節 13540 到diff 。 更令人困惑的是,每個兩字節塊中的字節順序由diff顛倒。 字節實際上是按以下順序列出的:1 和 0、3 和 2、5 和 4、7 和 6,依此類推。
該命令在計算上也很昂貴——一次兩個 hexdump 和一個hexdumps尤其是在被diff的文件很大的情況下。
但是如果hexdump -C可以將二進製文件的 ASCII 版本發送到終端窗口,我們為什麼不將輸出重定向到文本文件,然後將這兩個文本文件與diff進行比較?
hexdump -C binary_file1.so > binary1.txt
hexdump -C binary_file2.so > binary2.txt
diff binary1.txt binary2.txt
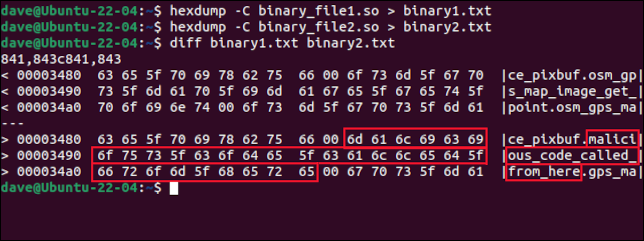
兩個文件之間的差異顯示在兩個簡短的摘錄中。 它們旁邊有一個 ASCII 表示。 文件之間的每個差異都會有一對提取。 在這個例子中,只有一個區別。
這一切都很好,但如果有什麼東西可以為你做這一切,那不是很好嗎?
VBinDiff
VBinDiff 程序可以從所有主要發行版的常用存儲庫中安裝。 要在 Ubuntu 上安裝它,請使用以下命令:
sudo apt install vbindiff

在 Fedora 上,您需要輸入:
須藤 dnf 安裝 vbindiff

Manjaro 用戶需要使用pacman 。
sudo pacman -Sy vbindiff

要使用該程序,請在命令行上傳遞兩個二進製文件的名稱。
vbindiff binary_file1.so binary_file2.so

基於終端的應用程序打開,在滾動視圖中顯示這兩個文件。
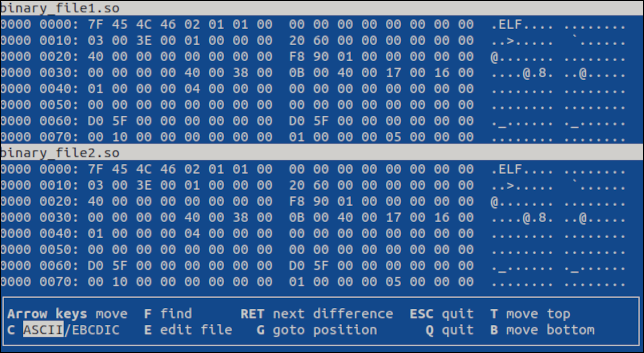
您可以使用鼠標滾輪或“UpArrow”、“DownArrow”、“Home”、“End”、“PageUp”和“PageDown”鍵來瀏覽文件。 兩個文件都會滾動。
點擊“Enter”鍵跳轉到第一個差異。 兩個文件中都突出顯示了差異。
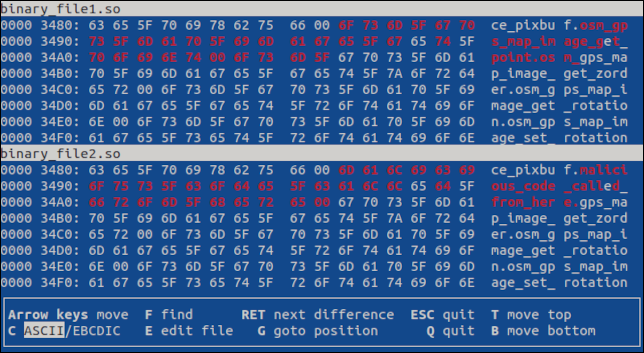
如果有更多差異,點擊“Enter”將顯示下一個差異。 按“q”或“Esc”將退出程序。
有什麼不同?
如果您正在使用屬於其他人的計算機並且不允許安裝任何軟件包,則可以使用cmp 、 diff和hexdump 。 如果您需要捕獲輸出以進行進一步處理,這些工具也是可以使用的。
但是,如果您被允許安裝包,VBinDiff 會使您的工作流程更輕鬆、更快捷。 事實上,將 VBinDiff 與單個二進製文件一起使用是瀏覽二進製文件的一種簡單方便的方法,這是一個不錯的好處。
相關:如何從 Linux 命令行查看二進製文件