
如何在 Linux 中使用 wc 命令
已发表: 2022-07-23
计算文件中的行数、字数和字节数很有用,但 Linux wc命令的真正灵活性来自与其他命令的配合。 让我们来看看。
wc 命令是什么?
wc命令是一个小型应用程序。 它是核心 Linux 实用程序之一,因此无需安装。 它已经在您的 Linux 计算机上。
你可以用几句话来描述它的作用。 它计算文件或文件选择中的行数、字数和字节数,并在终端窗口中打印结果。 它还可以从 STDIN 流中获取输入,这意味着您希望它处理的文本可以通过管道传输到其中。 这是wc真正开始增加价值的地方。

这是 Linux 口号“做一件事,做好”的一个很好的例子。 因为它接受管道输入,所以它可以用于多命令咒语。 正如我们将看到的,这个小的独立实用程序实际上是一个伟大的团队合作者。
我使用wc的一种方法是在我正在准备的复杂命令或别名中作为占位符。 如果完成的命令具有破坏性和删除文件的潜力,我经常使用wc作为真正危险命令的替代。
这样,在命令的开发过程中,我会得到视觉反馈,表明每个文件都在按预期进行处理。 当我与语法搏斗时,不可能发生任何不好的事情。
尽管wc很简单,但您仍然需要了解一些小怪癖。
开始使用 wc
使用wc的最简单方法是在命令行上传递文本文件的名称。
wc lorem.txt

这会导致wc扫描文件并计算行数、字数和字节数,并将它们写出到终端窗口。
单词被认为是任何以空格为界的东西。 它们是否是来自真实语言的单词是无关紧要的。 如果一个文件只包含“frd g lkj”,它仍然算作三个单词。
行是由回车符或文件结尾终止的字符序列。 该行是否在您的编辑器或终端窗口中环绕并不重要,直到wc遇到回车或文件末尾,它仍然是同一行。
我们的第一个示例在整个文件中找到了一行。 这是“lorem.txt”文件的内容。
猫 lorem.txt
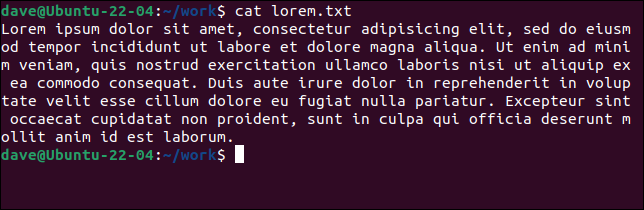
所有这些都算作一行,因为没有回车。 将此与另一个文件“lorem2.txt”进行比较,以及wc如何解释它。
wc lorem2.txt
猫lorem2.txt
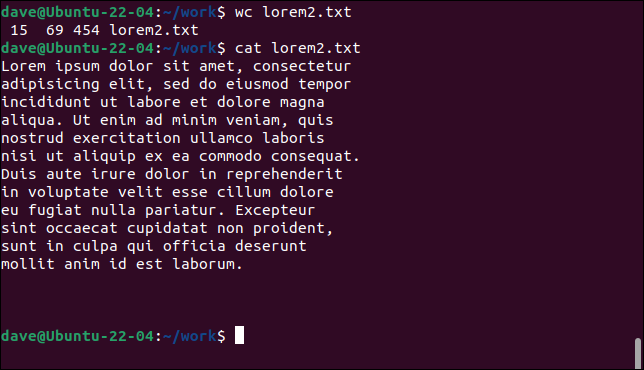
这一次, wc计数 15 行,因为已在文本中插入回车以在特定点开始新行。 但是,如果您计算其中包含文本的行数,您会发现只有 12 行。
其他三行是文件末尾的空白行。 这些仅包含回车符。 尽管这些行中没有文本,但已经开始了一个新行,因此wc将它们视为此类。
我们可以将任意数量的文件传递给wc 。
wc lorem.txt lorem2.txt
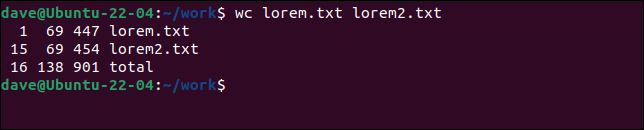
我们得到每个文件的统计数据和所有文件的总数。
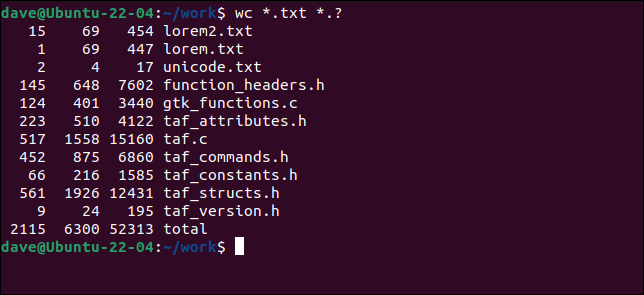
我们还可以使用通配符,以便我们可以选择匹配的文件而不是显式命名的文件。
wc *.txt *.?
命令行选项
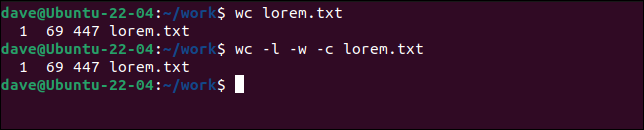
默认情况下, wc将显示每个文件中的行、单词和字节。 这与使用-l (行) -w (字)和-c (字节)选项相同。
wc lorem.txt
wc -l -w -c lorem.txt
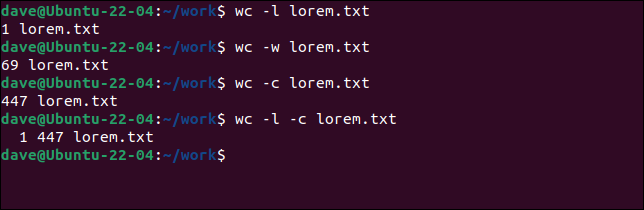
我们可以指定我们希望看到的图形组合。
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
应特别注意最后一个数字,由-c (字节)选项生成。 许多人将其误认为是数字符。 它实际上计算字节数。 字符数和字节数可能相同。 但不总是。
让我们看一下名为“unicode.txt”的文件的内容。
猫 unicode.txt

它包含三个单词和一个非拉丁字母字符。 我们将让wc使用其默认设置bytes处理文件,我们将再次执行此操作,但使用-m (字符)选项请求字符。
wc unicode.txt
wc -l -w -m unicode.txt
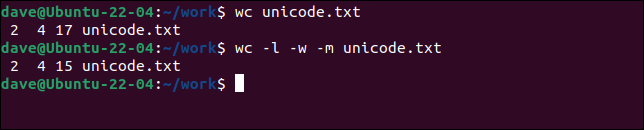
字节数多于字符数。
让我们看一下文件的十六进制转储,看看发生了什么。 hexdump命令的-C (canonical) 选项以 16 行显示文件中的字节,在行尾显示它们的纯 ASCII 等价物(如果有的话)。 如果没有对应的 ASCII 字符,一个句点“ . ”改为显示。

hexdump -C unicode.txt
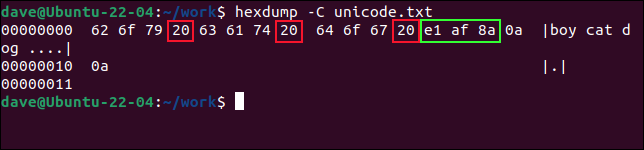
在 ASCII 中,十六进制值0x20表示一个空格字符。 如果我们从左边数三个值,我们会看到下一个值是一个空格字符。 所以前三个值0x62 、 0x6f和0x79代表“男孩”中的字母。
跳过0x20 ,我们看到另一组三个十六进制值: 0x63 、 0x61和0x74 。 这些拼出“猫”。 跳过下一个空格字符,我们看到“dog”中字母的另外三个值。 它们是0x64 、 0x5f和0x67 。
在“dog”这个词的后面,我们可以看到一个空格字符0x20和另外五个十六进制值。 最后两个是回车符0x0a 。
其他三个字节代表非拉丁字符,我们用绿色圈起来。 它是一个 Unicode 字符,编码它需要三个字节。 它们是0xe1 、 0xaf和0x8a 。
因此,请确保您知道您在计算什么,并且字节和字符不必相同。 通常,计数字节更有用,因为它可以告诉您文件中的实际内容。 按字符计数可以为您提供文件内容所代表的事物的数量。
相关:什么是 ANSI 和 Unicode 等字符编码,它们有何不同?
从文件中获取文件名
还有另一种方法可以为wc提供文件名。 您可以将文件名放在一个文件中,然后将该文件的名称传递给wc 。 它打开文件,提取文件名,并像在命令行上传递它们一样处理它们。 这允许您存储任意文件名集合以供重复使用。
但是有一个问题,而且是一个很大的问题。 文件名必须以null结尾,而不是回车终止。 也就是说,在每个文件名之后必须有一个空字节0x00而不是通常的回车字节0x0a 。
您无法打开编辑器并创建具有此格式的文件。 通常,像这样的文件是由其他程序生成的。 但是,如果您有这样的文件,这就是您将如何使用它。
这是我们包含文件名的文件。 在less中打开它会显示less用来指示空字节的奇怪“ ^@ ”字符。
更少的源文件-list.txt

要将文件与wc一起使用,我们需要使用--files0-from (读取输入)选项并传入包含文件名的文件名。
wc ---files0-from=source-files-list.txt
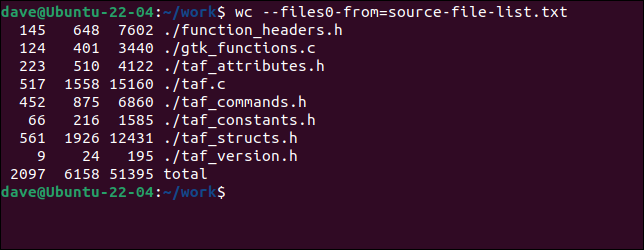
这些文件的处理方式与在命令行中提供的方式完全相同。
管道输入到 wc
将输入发送到wc的一种更常见、更灵活、更高效的方法是将其他命令的输出通过管道传输到wc中。 我们可以用echo命令来证明这一点。
echo "帮我算一算" | 厕所
echo -e "给我数这个\n" | 厕所
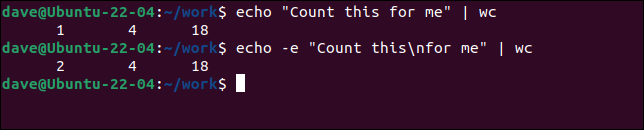
第二个echo命令使用-e (转义字符)选项来允许转义序列,如“ \n ”换行格式代码。 这会注入一个新行,导致wc将输入视为两行。
这是一系列命令,将它们的输入从一个输入到另一个。
查找 ./* -type f | 转 | 切-d'。 -f1 | 转 | 排序 | 独特的
- find从当前目录开始递归查找文件(
type -f)。rev反转文件名。 - cut通过将字段分隔符定义为句点来提取第一个字段 (
-f1).” 并从反向文件名的“前面”读取到它找到的第一个句点。 我们现在已经提取了文件扩展名。 - rev反转提取的第一个字段。
- sort按字母升序对它们进行排序。
- uniq列出终端窗口的唯一条目。
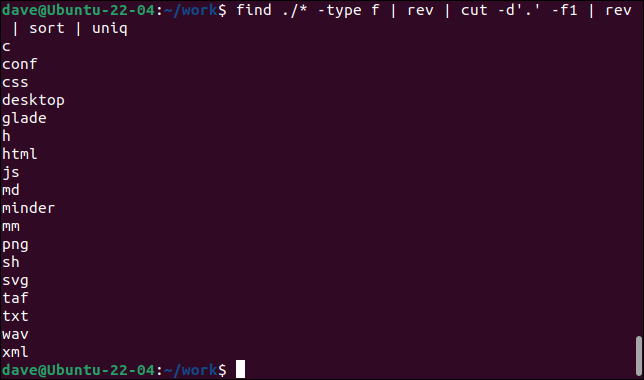
此命令列出当前目录和任何子目录中的所有唯一文件扩展名。
如果我们在uniq命令中添加-c (count) 选项,它将计算每种扩展类型的出现次数。 但是,如果我们想知道有多少不同的、唯一的文件扩展名,我们可以将wc作为该行的最后一个命令,并使用-l (行)选项。
查找 ./* -type f | 转 | 切-d'。 -f1 | 转 | 排序 | 独特 | wc -l

相关:如何使用 Linux cut 命令
最后
这是wc可以为您做的最后一招。 它会告诉你文件中最长行的长度。 可悲的是,它没有告诉你它是哪条线。 它只是给你长度。
wc -L taf.c

但请注意,制表符被计为八个空格。 在我的编辑器中查看,该行的开头有三个两空格制表符。 它的实际长度是 124 个字符。 所以报告的数字是人为扩大的。
我会用一大撮盐来处理这个功能。 我的意思是不要使用它。 它的输出具有误导性。
尽管wc有其怪癖,但当您需要计算各种值(而不仅仅是文件中的单词)时,它是一个很好的工具,可以放入管道命令。
相关:你应该知道的 37 个重要的 Linux 命令