
如何在 Bash 中解析 CSV 数据
已发表: 2022-09-16
逗号分隔值 (CSV) 文件是导出数据的最常见格式之一。 在 Linux 上,我们可以使用 Bash 命令读取 CSV 文件。 但它会变得非常复杂,非常快。 我们会伸出援手。
什么是 CSV 文件?
逗号分隔值文件是包含表格数据的文本文件。 CSV 是一种分隔数据。 顾名思义,逗号“ , ”用于将每个数据字段(或值)与其相邻字段分开。
CSV 无处不在。 如果应用程序具有导入和导出功能,它几乎总是支持 CSV。 CSV 文件是人类可读的。 您可以用 less 查看它们,在任何文本编辑器中打开它们,并将它们从一个程序移动到另一个程序。 例如,您可以从 SQLite 数据库中导出数据并在 LibreOffice Calc 中打开它。
然而,即使是 CSV 也会变得复杂。 想要在数据字段中使用逗号? 该字段需要用引号“ "括起来。要在字段中包含引号,每个引号需要输入两次。
当然,如果您使用由您编写的程序或脚本生成的 CSV,则 CSV 格式可能简单明了。 如果您被迫使用更复杂的 CSV 格式,而 Linux 就是 Linux,那么我们也可以使用一些解决方案。
一些样本数据
您可以使用 Online Data Generator 等网站轻松生成一些示例 CSV 数据。 您可以定义所需的字段并选择所需的数据行数。 您的数据使用真实的虚拟值生成并下载到您的计算机。
我们创建了一个包含 50 行虚拟员工信息的文件:
- id :一个简单的唯一整数值。
- firstname :人的名字。
- lastname :此人的姓氏。
- job-title :此人的职位。
- email-address :此人的电子邮件地址。
- 分公司:他们工作的公司分公司。
- state :分支所在的州。
某些 CSV 文件具有列出字段名称的标题行。 我们的示例文件有一个。 这是我们文件的顶部:
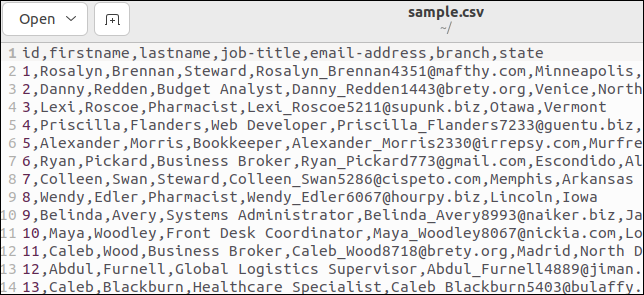
第一行将字段名称保存为逗号分隔值。
从 CSV 文件中解析数据
让我们编写一个脚本来读取 CSV 文件并从每条记录中提取字段。 将此脚本复制到编辑器中,并将其保存到名为“field.sh”的文件中。
#! /bin/bash 而 IFS="," 读取 -r id firstname lastname jobtitle email 分支状态 做 echo "记录 ID:$id" 回声“名字:$名” 回声“姓氏:$姓氏” echo "职位名称:$jobtitle" echo "邮箱地址:$email" 回声“分支:$分支” 回声“状态:$状态” 回声“” 完成 < <(tail -n +2 sample.csv)
我们的小脚本中有很多内容。 让我们分解一下。

我们正在使用一个while循环。 只要while循环条件解析为 true,就会执行while循环的主体。 循环的主体非常简单。 一组echo显语句用于将某些变量的值打印到终端窗口。
while循环条件比循环体更有趣。 我们使用IFS=","语句指定应使用逗号作为内部字段分隔符。 IFS 是一个环境变量。 read命令在解析文本序列时引用它的值。
我们使用read命令的-r (保留反斜杠)选项来忽略数据中可能存在的任何反斜杠。 它们将被视为常规字符。
read命令解析的文本存储在一组以 CSV 字段命名的变量中。 它们可以很容易地被命名为field1, field2, ... field7 ,但是有意义的名字让生活更轻松。
数据是作为tail命令的输出获得的。 我们使用tail是因为它为我们提供了一种跳过 CSV 文件标题行的简单方法。 -n +2 (行号)选项告诉tail从第二行开始读取。
<(...)构造称为进程替换。 它使 Bash 接受进程的输出,就好像它来自文件描述符一样。 然后将其重定向到while循环中,提供read命令将解析的文本。
使用chmod命令使脚本可执行。 每次从本文复制脚本时都需要这样做。 在每种情况下替换相应脚本的名称。
chmod +x field.sh

当我们运行脚本时,记录被正确地拆分为它们的组成字段,每个字段存储在不同的变量中。
./field.sh
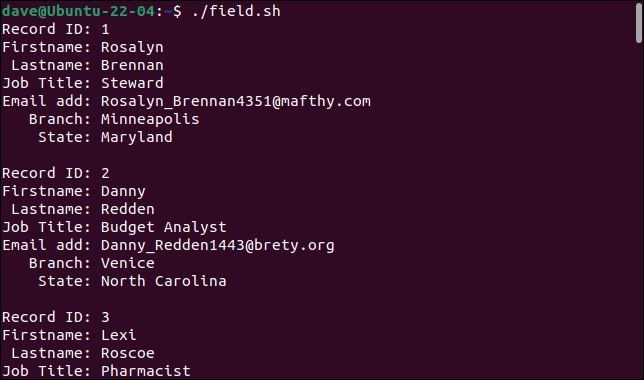
每条记录都打印为一组字段。
选择字段
也许我们不想或不需要检索每个字段。 我们可以通过合并cut命令来获得选择的字段。
该脚本称为“select.sh”。
#!/bin/bash while IFS="," 读取 -r id jobtitle 分支状态 做 echo "记录 ID:$id" echo "职位名称:$jobtitle" 回声“分支:$分支” 回声“状态:$状态” 回声“” 完成 < <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
我们已将cut命令添加到进程替换子句中。 我们使用-d (分隔符)选项告诉cut使用逗号“ , ”作为分隔符。 -f (字段)选项告诉cut我们需要字段一、四、六和七。 这四个字段被读入四个变量,这些变量被打印在while循环的主体中。
这是我们运行脚本时得到的。
./select.sh
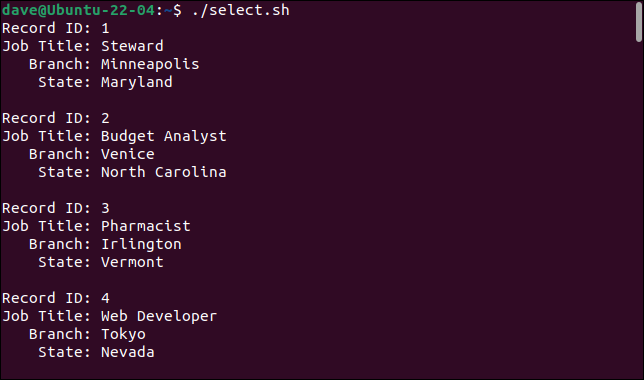
通过添加cut命令,我们可以选择我们想要的字段并忽略我们不想要的字段。
到目前为止,一切都很好。 但…
如果您处理的 CSV 不复杂,字段数据中没有逗号或引号,那么我们所介绍的内容可能会满足您的 CSV 解析需求。 为了显示我们可能遇到的问题,我们修改了一小部分数据,使其看起来像这样。
ID、名字、姓氏、职位、电子邮件地址、分支机构、州 1,Rosalyn,Brennan,“高级管家”,[email protected],马里兰州明尼阿波利斯 2,丹尼,雷登,“分析师”“预算”“”,[email protected],威尼斯,北卡罗来纳 3,Lexi,Roscoe,药剂师,,Irlington,Vermont
- 记录一在
job-title字段中有逗号,因此该字段需要用引号引起来。 - 记录二在
jobs-title字段中有一个用两组引号括起来的单词。 - 记录三在
email-address字段中没有数据。
此数据保存为“sample2.csv”。 修改“field.sh”脚本以调用“sample2.csv”,并将其保存为“field2.sh”。
#! /bin/bash 而 IFS="," 读取 -r id firstname lastname jobtitle email 分支状态 做 echo "记录 ID:$id" 回声“名字:$名” 回声“姓氏:$姓氏” echo "职位名称:$jobtitle" echo "邮箱地址:$email" 回声“分支:$分支” 回声“状态:$状态” 回声“” 完成 < <(tail -n +2 sample2.csv)
当我们运行这个脚本时,我们可以看到我们简单的 CSV 解析器中出现了裂缝。

./field2.sh

第一条记录将职位字段拆分为两个字段,将第二部分视为电子邮件地址。 在此之后的每个字段都向右移动一个位置。 最后一个字段包含branch和state值。
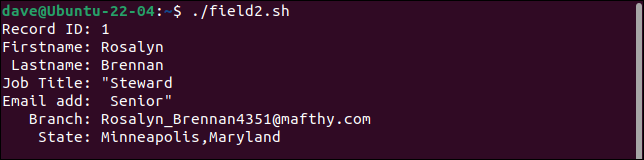
第二条记录保留所有引号。 它应该只在“预算”一词周围有一对引号。
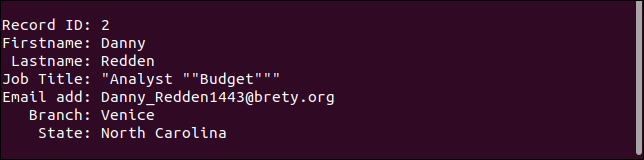
第三条记录实际上处理了它应该处理的缺失字段。 电子邮件地址丢失,但其他一切都应如此。

与直觉相反,对于简单的数据格式,编写一个健壮的通用 CSV 解析器是非常困难的。 像awk这样的工具会让你接近,但总会有边缘情况和例外情况发生。

尝试编写一个可靠的 CSV 解析器可能不是最好的方法。 另一种方法——特别是如果你在某种截止日期前工作——采用两种不同的策略。
一种是使用专门设计的工具来操作和提取数据。 第二个是清理您的数据并替换嵌入逗号和引号等问题场景。 然后,您的简单 Bash 解析器可以处理对 Bash 友好的 CSV。
csvkit 工具包
CSV 工具包csvkit是一组专门用于帮助处理 CSV 文件的实用程序。 您需要将其安装在您的计算机上。
要在 Ubuntu 上安装它,请使用以下命令:
sudo apt install csvkit

要在 Fedora 上安装它,您需要输入:
须藤 dnf 安装 python3-csvkit

在 Manjaro 上,命令是:
sudo pacman -S csvkit

如果我们将 CSV 文件的名称传递给它, csvlook实用程序会显示一个表格,其中显示每个字段的内容。 显示字段内容以显示字段内容所代表的内容,而不是存储在 CSV 文件中的内容。
让我们用我们有问题的“sample2.csv”文件尝试csvlook 。
csvlook sample2.csv
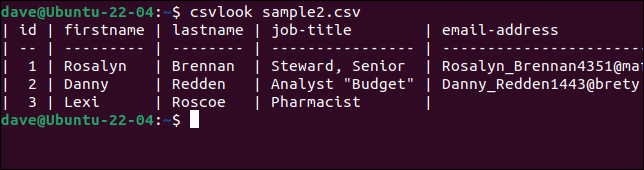
所有字段均正确显示。 这证明问题不在于 CSV。 问题是我们的脚本过于简单,无法正确解释 CSV。
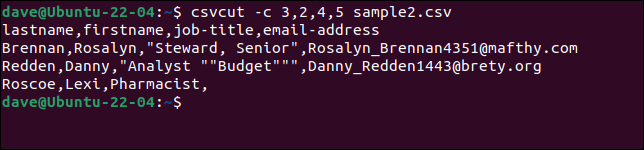
要选择特定列,请使用csvcut命令。 -c (列)选项可以与字段名或列号一起使用,或两者结合使用。
假设我们需要从每条记录中提取名字和姓氏、职位和电子邮件地址,但我们希望名称顺序为“姓氏,名字”。 我们需要做的就是按照我们想要的顺序放置字段名称或数字。
这三个命令都是等价的。
csvcut -c 姓氏、名字、职位、电子邮件地址 sample2.csv
csvcut -c lastname,firstname,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
我们可以添加csvsort命令来按字段对输出进行排序。 我们使用-c (列)选项指定要排序的列,并使用-r (反向)选项按降序排序。
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
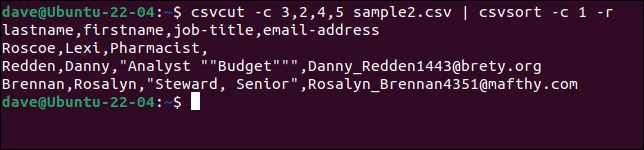
为了使输出更漂亮,我们可以通过csvlook提供它。
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
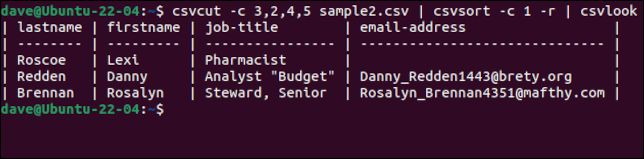
一个巧妙的做法是,即使记录已排序,带有字段名称的标题行仍保留为第一行。 一旦我们满意,我们就可以按照我们想要的方式获得数据,我们可以从命令链中删除csvlook ,并通过将输出重定向到一个文件来创建一个新的 CSV 文件。
我们向“sample2.file”添加了更多数据,删除了csvsort命令,并创建了一个名为“sample3.csv”的新文件。
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

清理 CSV 数据的安全方法
如果您在 LibreOffice Calc 中打开 CSV 文件,每个字段都将放置在一个单元格中。 您可以使用查找和替换功能来搜索逗号。 您可以将它们替换为“nothing”,以便它们消失,或者使用不会影响 CSV 解析的字符,如分号“ ; “ 例如。
您不会看到引用字段周围的引号。 您将看到的唯一引号是字段数据中嵌入的引号。 这些显示为单引号。 查找并用单个撇号“ ' ”替换它们将替换 CSV 文件中的双引号。
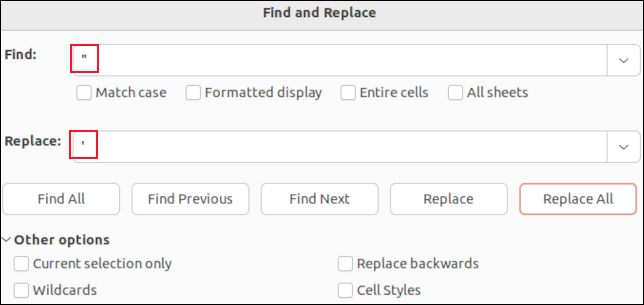
在像 LibreOffice Calc 这样的应用程序中进行查找和替换意味着您不会意外删除任何字段分隔符逗号,也不会删除引用字段周围的引号。 您只会更改字段的数据值。
我们用分号更改了字段中的所有逗号,用撇号更改了所有嵌入的引号,并保存了我们的更改。
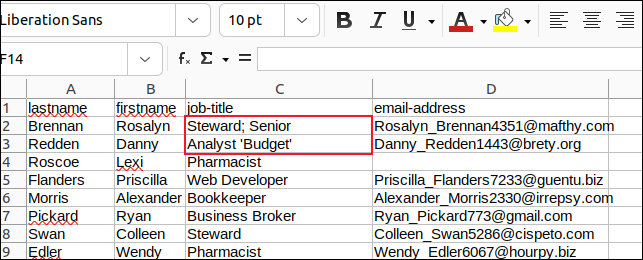
然后我们创建了一个名为“field3.sh”的脚本来解析“sample3.csv”。
#! /bin/bash 而 IFS="," 读取 -r lastname firstname jobtitle email 做 回声“姓氏:$姓氏” 回声“名字:$名” echo "职位名称:$jobtitle" echo "邮箱地址:$email" 回声“” 完成 < <(tail -n +2 sample3.csv)
让我们看看我们在运行它时会得到什么。
./field3.sh
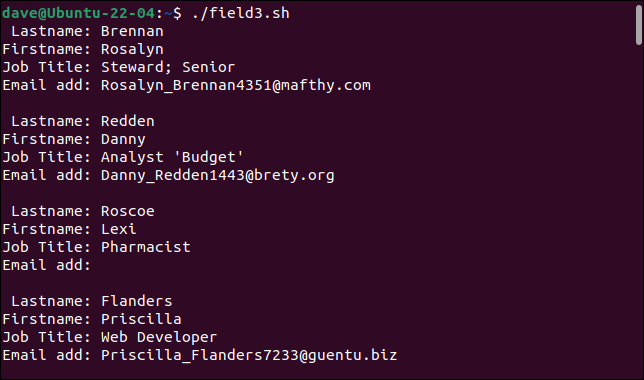
我们的简单解析器现在可以处理我们以前有问题的记录。
你会看到很多 CSV
CSV 可以说是最接近应用程序数据通用语言的东西。 大多数处理某种形式的数据的应用程序都支持导入和导出 CSV。 了解如何以现实和实用的方式处理 CSV 将对您有利。
相关: 9 个 Bash 脚本示例让您开始使用 Linux