
NVIDIA 的 RTX 3000 系列 GPU:这是新功能
已发表: 2022-01-29
2020 年 9 月 1 日,NVIDIA 发布了其新的游戏 GPU 系列:基于其 Ampere 架构的 RTX 3000 系列。 我们将讨论什么是新的,它附带的人工智能软件,以及让这一代人非常棒的所有细节。
认识 RTX 3000 系列 GPU

NVIDIA 的主要公告是其闪亮的新 GPU,全部基于定制的 8 nm 制造工艺,并且都在光栅化和光线追踪性能方面带来了重大的加速。
在阵容的低端,有 RTX 3070,售价 499 美元。 对于 NVIDIA 在最初宣布时推出的最便宜的显卡来说,它有点贵,但一旦你得知它击败了现有的 RTX 2080 Ti(通常零售价超过 1400 美元的顶级线卡),这绝对是一种偷窃。 然而,在 NVIDIA 宣布后,第三方销售价格下降,大量在 eBay 上以低于 600 美元的价格被抢购。
截至公告发布时还没有可靠的基准,因此尚不清楚该卡是否真的在客观上比 2080 Ti “更好”,或者 NVIDIA 是否有点扭曲营销。 正在运行的基准测试是 4K 并且可能开启了 RTX,这可能会使差距看起来比在纯粹的光栅化游戏中更大,因为基于 Ampere 的 3000 系列在光线追踪方面的表现将是 Turing 的两倍多。 但是,由于光线追踪现在不会对性能造成太大影响,并且在最新一代游戏机中得到支持,因此以几乎三分之一的价格运行它与上一代旗舰产品一样快是一个主要卖点。
目前还不清楚价格是否会保持这种状态。 第三方设计通常会在价格标签上增加至少 50 美元,而且由于需求可能会有多高,到 2020 年 10 月看到它以 600 美元的价格出售也就不足为奇了。
略高于此的是 RTX 3080,售价 699 美元,应该是 RTX 2080 的两倍,比 3080 快 25-30%。
然后,在高端,新的旗舰是 RTX 3090,它非常巨大。 NVIDIA 很清楚,并将其称为“BFGPU”,该公司称其代表“Big Ferocious GPU”。

NVIDIA 没有展示任何直接的性能指标,但该公司展示了它以 60 FPS 的速度运行 8K 游戏,这令人印象深刻。 诚然,NVIDIA 几乎肯定会使用 DLSS 来达到这一目标,但 8K 游戏就是 8K 游戏。
当然,最终会有 3060 和其他更注重预算的卡的变体,但这些通常会在以后出现。
为了真正冷却这些东西,NVIDIA 需要改进的冷却器设计。 3080 的额定功率为 320 瓦,相当高,因此 NVIDIA 选择了双风扇设计,但不是将两个风扇 vwinf 放在底部,而是将风扇放在背板通常所在的顶端。 风扇将空气向上引导至 CPU 冷却器和机箱顶部。

从机箱中不良气流对性能的影响程度来看,这是完全合理的。 但是,电路板因此非常狭窄,这可能会影响第三方销售价格。
DLSS:软件优势
光线追踪并不是这些新卡的唯一好处。 真的,这有点像 hack——与老一代显卡相比,RTX 2000 系列和 3000 系列在进行实际光线追踪方面并没有那么好。 在像 Blender 这样的 3D 软件中,光线追踪一个完整的场景通常每帧需要几秒钟甚至几分钟的时间,因此在 10 毫秒内强制它是不可能的。
当然,有用于运行光线计算的专用硬件,称为 RT 内核,但在很大程度上,NVIDIA 选择了不同的方法。 NVIDIA 改进了去噪算法,允许 GPU 渲染一个非常便宜但看起来很糟糕的单通道,并且不知何故——通过人工智能魔法——将它变成了游戏玩家想要看到的东西。 当与传统的基于光栅化的技术相结合时,它可以通过光线追踪效果增强令人愉悦的体验。

然而,为了快速做到这一点,NVIDIA 添加了称为 Tensor 核心的 AI 特定处理核心。 这些处理运行机器学习模型所需的所有数学运算,并且速度非常快。 它们是云服务器领域人工智能的彻底改变者,因为人工智能被许多公司广泛使用。
除了去噪,Tensor 核心对游戏玩家的主要用途称为 DLSS,或深度学习超级采样。 它采用低质量的帧并将其升级为完全原生质量。 这实质上意味着您可以在观看 4K 图片的同时以 1080p 级别的帧速率进行游戏。

这也有助于提高光线追踪性能——来自 PCMag 的基准测试显示 RTX 2080 Super 以超高品质运行控制,所有光线追踪设置都已调到最大。 在 4K 下,它只有 19 FPS,但在 DLSS 上,它获得了更好的 54 FPS。 DLSS 是 NVIDIA 的免费性能,由 Turing 和 Ampere 上的 Tensor 内核实现。 任何支持它并且受 GPU 限制的游戏都可以仅从软件中看到严重的加速。
DLSS 并不是什么新鲜事物,两年前推出 RTX 2000 系列时,它就被宣布为一项功能。 当时,很少有游戏支持它,因为它需要 NVIDIA 为每个单独的游戏训练和调整机器学习模型。
然而,在那个时候,NVIDIA已经对其进行了彻底的改写,称之为新版本DLSS 2.0。 它是一个通用 API,这意味着任何开发人员都可以实现它,并且它已经被大多数主要版本所采用。 它不是处理一帧,而是从前一帧中获取运动矢量数据,类似于 TAA。 结果比 DLSS 1.0 清晰得多,在某些情况下,实际上看起来甚至比原始分辨率更好、更清晰,因此没有太多理由不打开它。
有一个问题——当完全切换场景时,比如在过场动画中,DLSS 2.0 必须在等待运动矢量数据的同时以 50% 的质量渲染第一帧。 这可能会导致几毫秒的质量轻微下降。 但是,你看到的 99% 的东西都会被正确渲染,而大多数人在实践中并没有注意到这一点。
相关:什么是 NVIDIA DLSS,它将如何使光线追踪更快?
安培架构:为人工智能而生
安培速度很快。 速度非常快,尤其是在 AI 计算方面。 RT 核心比 Turing 快 1.7 倍,新的 Tensor 核心比 Turing 快 2.7 倍。 两者的结合是光线追踪性能真正的代际飞跃。

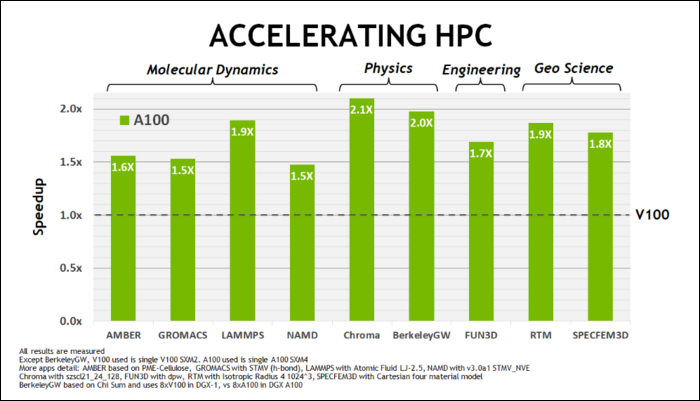
今年 5 月初,NVIDIA 发布了 Ampere A100 GPU,这是一款专为运行 AI 而设计的数据中心 GPU。 有了它,他们详细说明了很多使 Ampere 速度如此之快的原因。 对于数据中心和高性能计算工作负载,Ampere 通常比 Turing 快 1.7 倍左右。 对于 AI 训练,它的速度最高可达 6 倍。
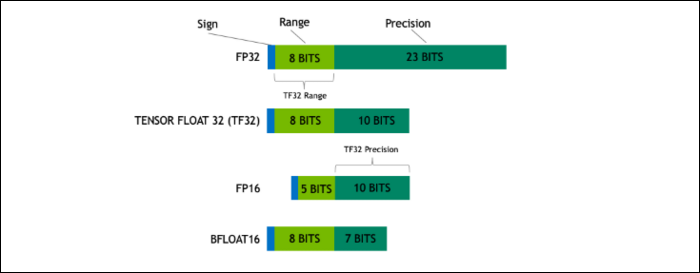
借助 Ampere,NVIDIA 正在使用一种新的数字格式,旨在在某些工作负载中取代行业标准的“浮点 32”或 FP32。 在后台,您的计算机处理的每个数字都会占用内存中预定义的位数,无论是 8 位、16 位、32 位、64 位还是更大。 更大的数字更难处理,所以如果你可以使用更小的数字,你就会减少处理。
FP32 存储一个 32 位的十进制数,它使用 8 位来表示数字的范围(可以有多大或多小),使用 23 位来表示精度。 NVIDIA 声称,这 23 个精度位对于许多 AI 工作负载来说并不是完全必要的,您可以从其中的 10 个中获得类似的结果和更好的性能。 将大小减少到仅 19 位,而不是 32 位,在许多计算中都有很大的不同。
这种新格式称为 Tensor Float 32,A100 中的 Tensor Cores 经过优化以处理奇怪大小的格式。 这就是,除了芯片缩小和核心数量增加之外,他们如何在 AI 训练中获得 6 倍的巨大加速。
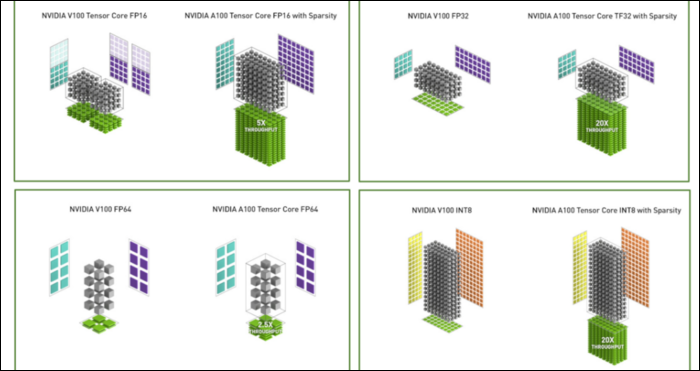
除了新的数字格式之外,Ampere 在特定计算(如 FP32 和 FP64)中看到了主要的性能加速。 对于外行来说,这些并不会直接转化为更高的 FPS,但它们是使其在 Tensor 操作中整体速度快近三倍的部分原因。
然后,为了进一步加快计算速度,他们引入了细粒度结构化稀疏的概念,对于一个非常简单的概念来说,这是一个非常花哨的词。 神经网络使用大量的数字列表,称为权重,它们会影响最终输出。 要处理的数字越多,它就会越慢。
然而,并非所有这些数字都是真正有用的。 其中一些实际上只是零,并且基本上可以被丢弃,当您可以同时处理更多数字时,这会导致巨大的加速。 稀疏性本质上压缩了数字,从而减少了计算工作量。 新的“稀疏张量核心”旨在对压缩数据进行操作。
尽管发生了这些变化,NVIDIA 表示这根本不会显着影响训练模型的准确性。
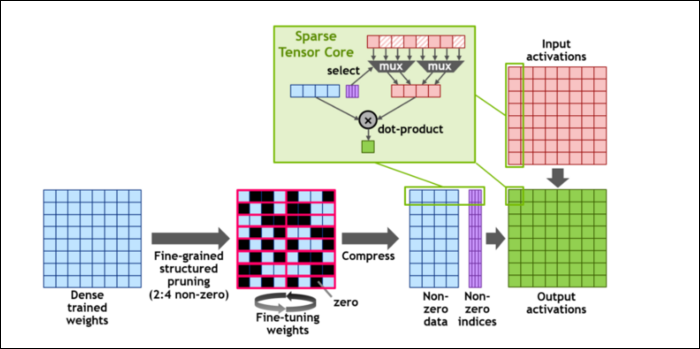
对于最小数字格式之一的稀疏 INT8 计算,单个 A100 GPU 的峰值性能超过 1.25 PetaFLOPs,这是一个惊人的高数字。 当然,这只是在处理一种特定的数字时,但它仍然令人印象深刻。