
如何解析文本
已发表: 2022-10-15
如果您学过一些计算机编程语言,您可能听说过解析文本这个术语。 这用于简化文件的复杂数据值。 本文帮助您了解如何使用该语言解析文本。 除此之外,如果您在解析文本 x 时遇到错误,您将在文章中了解如何修复解析错误。
内容
- 如何解析文本
- 什么是解析文本?
- NLP 或自然语言处理
- 什么是解析文本?
- 解析文本的原因是什么?
- 方法一:通过DataFrame类
- 方法二:通过词分词
- 方法三:通过DocParser类
- 方法四:通过解析文本工具
- 方法 5:通过 TextFieldParser (Visual Basic)
- 专业提示:如何通过 MS Excel 解析文本
- 如何修复解析错误
如何解析文本
在本文中,我们展示了通过各种方式解析文本的完整指南,并简要介绍了解析文本。
什么是解析文本?
在深入学习使用任何代码解析文本的概念之前。 了解语言和编码的基础知识很重要。
NLP 或自然语言处理
为了解析文本,使用自然语言处理或 NLP,它是人工智能领域的一个子领域。 Python 语言是属于该类别的语言之一,用于解析文本。
NLP 代码使计算机能够理解和处理人类语言,以使其适用于各种应用程序。 要将 ML 或机器学习技术应用于语言,必须将非结构化文本数据转换为结构化表格数据。 为了完成解析活动,Python 语言用于更改程序代码。
什么是解析文本?
解析文本只是意味着将数据从一种格式转换为另一种格式。 保存文件的格式应解析或转换为不同格式的文件,以使用户能够在各种应用程序中使用它。
- 换句话说,该过程意味着分析字符串或文本,并通过更改文件的格式将其转换为逻辑组件。
- 利用 Python 语言的一些规则来完成这个常见的编程任务。 在解析文本时,给定的一系列文本被分解成更小的组件。
解析文本的原因是什么?
本节给出了必须解析文本的原因,这是了解如何解析文本之前的先决知识。
- 所有计算机化数据的格式都不相同,并且可能会根据不同的应用程序而有所不同。
- 数据格式因应用程序而异,不兼容的代码会导致此错误。
- 没有单独的通用计算机程序来选择所有数据格式的数据。
方法一:通过DataFrame类
Python 语言的 DataFrame 类具有解析文本所需的所有功能。 这个内置库包含将任何格式的数据解析为另一种格式的必要代码。
DataFrame类简介
DataFrame 类是一种功能丰富的数据结构,用作数据分析工具。 这是一款功能强大的数据分析工具,可用于轻松分析数据。
- 代码被读入 pandas DataFrame 以使用 Python 语言执行分析。
- 该类附带了 Python 数据分析师使用的 pandas 提供的许多包。
- 此类的特性是 NumPy 库的抽象,即函数的内部功能对用户隐藏的代码。 NumPy 库是一个 Python 库,其中包含用于处理数组的命令和函数。
- DataFrame 类可用于渲染具有多个行和列索引的二维数组。 这些索引有助于存储多维数据,因此被称为 MultiIndex。 必须更改这些才能知道如何修复解析错误。
Python 语言的 pandas 有助于以最完美的方式执行 SQL 或数据库样式的操作,以避免在解析文本 x 时出错。 它还包含一些 IO 工具,有助于分析 CSV、MS Excel、JSON、HDF5 和其他数据格式的文件。
另请阅读:修复尝试代理请求时发生的错误
使用 DataFrame 类解析文本的过程
要了解如何解析文本,您可以使用本节中给出的 DataFrame 类的标准流程。
- 破译输入数据的数据格式。
- 决定CSV或逗号分隔值等数据的输出数据。
- 在代码上写一个原始数据类型,如列表或字典。
注意:在空的 DataFrame 上编写代码可能既乏味又复杂。 pandas 允许从这些数据类型创建 DataFrame 类的数据。 因此,原始数据类型中的数据可以很容易地解析为所需的数据格式。
- 使用数据分析工具 pandas DataFrame 分析数据,并打印结果。
选项一:标准格式
此处解释了使用特定数据格式(例如 CSV)格式化任何文件的标准方法。
- 将带有数据值的文件保存在您的 PC 上。 例如,您可以将文件命名为data.txt 。
- 在 pandas 中以特定名称导入文件并将数据导入另一个变量。 例如,该语言的 pandas 被导入到给定代码中的名称pd中。
- 导入应该有一个完整的代码,其中包含输入文件的名称、函数和输入文件格式的详细信息。
注意:这里,名为res的变量用于使用pd中导入的 pandas 执行文件data.txt中数据的读取功能。 输入文本的数据格式以CSV格式指定。
- 调用命名的文件类型并分析打印结果上的解析文本。 例如,命令行执行后的命令res将有助于打印解析的文本。
下面给出了上述过程的示例代码,将有助于理解如何解析文本。
将熊猫导入为 pd
res = pd.read_csv('data.txt')
资源在这种情况下,如果您在文件data.txt中输入数据值,例如[1,2,3] ,它将被解析并显示为1 2 3 。
选项二:字符串方法
如果提供给代码的文本仅包含字符串或字母字符,则可以使用字符串中的特殊字符(如逗号、空格等)来分隔和解析文本。 该过程类似于常见的内部字符串操作。 要查找如何修复解析错误,您必须遵循使用此选项解析文本的过程,如下所述。
- 数据是从字符串中提取的,所有分隔文本的特殊字符都会被记录下来。
例如,在下面给出的代码中,识别了字符串my_string中的特殊字符,即 ' 、 ' 和 ' : '。 这个过程必须小心完成,以避免在解析文本 x 时出错。
- 字符串中的文本根据特殊字符的值和位置单独拆分。
例如,根据使用 split 命令识别的特殊字符,将字符串拆分为文本数据值。
- 字符串的数据值作为解析文本单独打印。 这里, print语句用于打印文本的解析数据值。
下面给出了上述过程的示例代码。
my_string = '名称:技术,计算机'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print(“名称:{}”.format(sfinal))在这种情况下,解析字符串的结果将如下所示。
名称:['技术','计算机']
为了获得更好的清晰度并知道如何在使用字符串文本时解析文本,使用了for循环并将代码修改如下。
my_string = '名称:技术,计算机'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
对于 idx,枚举中的项目([s1,s2,s3,s4]):
print(“步骤 {}: {}”.format(idx, item)) 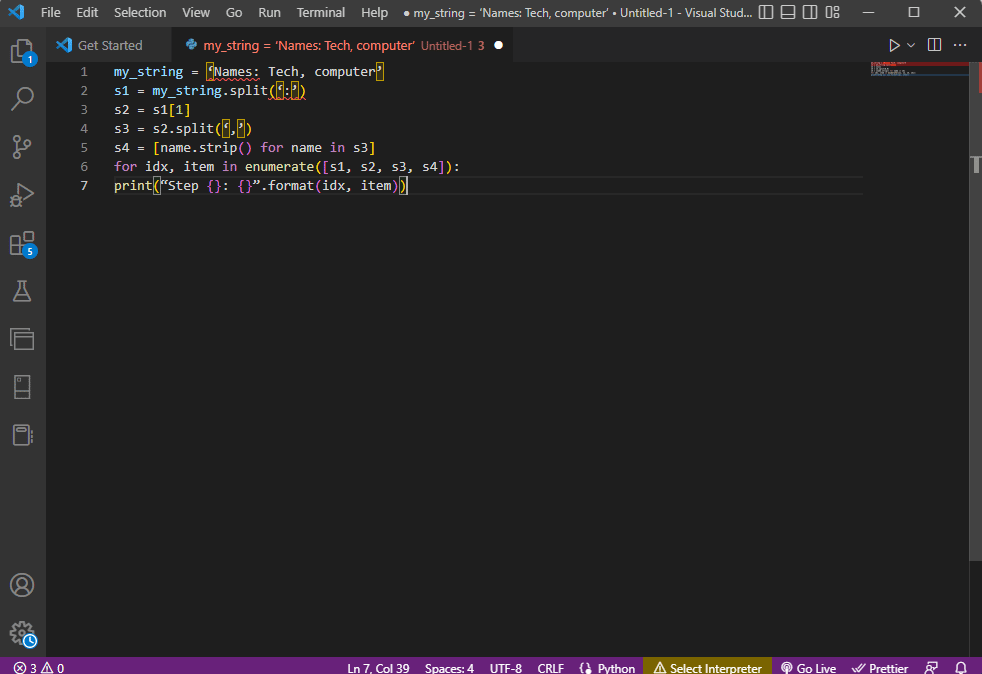
每个步骤的解析文本结果如下所示。 您可以注意到,在步骤 0 中,字符串基于特殊字符:进行分隔,文本数据值在进一步的步骤中基于字符进行分隔。
第 0 步:['名称','技术,计算机'] 第 1 步:技术、计算机 第2步:['技术','计算机'] 第 3 步:['技术','计算机']
选项三:解析复杂文件
在大多数情况下,需要解析的文件数据包含不同的数据类型和数据值。 在这种情况下,使用前面解释的方法可能难以解析文件。
解析文件中复杂数据的特点是使数据值以表格形式显示。
- 值的标题或元数据打印在文件顶部,
- 变量和字段以表格形式打印在输出中,并且
- 数据值形成一个复合键。
在深入学习如何用这种方法解析文本之前,有必要学习一些基本概念。 数据值的解析是基于正则表达式或 Regex 完成的。
正则表达式模式
要知道如何修复解析错误,您必须确保表达式中的正则表达式模式是正确的。 解析字符串数据值的代码将涉及本节下面列出的常见正则表达式模式。
- '\d' :匹配字符串中的十进制数字,
- '\s' :匹配空白字符,
- '\w' :匹配字母数字字符,
- '+'或'*' : 通过匹配字符串中的一个或多个字符来执行贪婪匹配,
- 'a-z' :匹配文本数据值中的小写组,
- 'A-Z'或'a-z' :匹配字符串的大小写组,并且
- '0-9' :匹配数值。
常用表达
正则表达式模块是 Python 语言中 pandas 包的主要部分,错误的 re 可能导致解析文本 x 时出错。 它是一种嵌入在 Python 中的微型语言,用于在表达式中查找字符串模式。 正则表达式或正则表达式是具有特殊语法的字符串。 它允许用户根据字符串中的值匹配其他字符串中的模式。
Regex 是根据数据类型和字符串中表达式的要求创建的,例如'String = (.*)\n 。 正则表达式在每个表达式的模式之前使用。 下面列出了正则表达式中使用的符号,有助于了解如何解析文本。
- . :从数据中检索任何字符,
- * :使用前一个表达式中的零个或多个数据,
- (.*) :将正则表达式的一部分分组在括号内,
- \n :在代码行尾创建一个换行符,
- \d :在 0 到 9 范围内创建一个短整数值,
- + :使用前一个表达式中的一个或多个数据,并且
- | :创建一个逻辑语句; 用于或表达式。
正则表达式对象
RegexObject 是编译函数的返回值,如果表达式与匹配值匹配,则用于返回 MatchObject。
1. 匹配对象
由于 MatchObject 的布尔值始终为 True,您可以使用if语句来识别对象中的正匹配。 在使用if语句的情况下,索引引用的组用于查找表达式中对象的匹配。
- group()返回一个或多个匹配子组,
- group(0)返回整个匹配,
- group(1)返回第一个带括号的子组,并且
- 在引用多个组时,我们应该使用 python 特定的扩展。 此扩展名用于指定必须在其中找到匹配项的组的名称。 括号内的组中提供了特定的扩展名。 例如,表达式(?P<group1>regex1)将引用名称为group1的特定组,并检查正则表达式regex1中的匹配项。 要了解如何修复解析错误,您必须检查组是否正确指向。
2. MatchObject的方法
在寻找如何解析文本时,重要的是要知道 MatchObject 有两种基本方法,如下所示。 如果在指定的表达式中找到 MatchObject,它将返回其实例,否则,它将返回 None。
- match(string)方法用于在正则表达式的开头查找字符串的匹配项,并且
- search(string)方法用于扫描字符串以查找正则表达式中匹配的位置。
正则表达式函数
正则表达式函数是用于执行用户从获取的数据值集中指定的特定函数的代码行。
注意:为了编写函数,原始字符串用于正则表达式以避免解析文本 x 时出错。 这是通过在表达式中的每个模式之前添加下标r来完成的。
下面解释表达式中使用的常用函数。
1. re.findall()
如果找到匹配项,则此函数返回字符串中的所有模式,如果未找到匹配项,则返回一个空列表。 例如,函数string = re.findall('[aeiou]', regex_filename)用于查找文件名中出现的元音。
2. re.split()
此函数用于在找到与指定字符(例如空格)匹配的情况下拆分字符串。 如果未找到匹配项,则返回一个空字符串。
3. re.sub()
该函数用给定的替换变量的内容替换匹配的文本。 与其他函数相反,如果没有找到模式,则返回原始字符串。
4. re.search()
帮助学习如何解析文本的基本功能之一是搜索功能。 它有助于在字符串中搜索模式并返回匹配对象。 如果搜索未能识别匹配项,则不返回任何值。
5.重新编译(模式)
该函数用于将正则表达式模式编译为 RegexObject,这在前面已经讨论过了。
其他需求
列出的要求是高级程序员在数据分析中使用的附加功能。
- 为了可视化正则表达式,使用了regexper ,并且
- 为了测试正则表达式,使用了regex101 。
另请阅读:如何在 Windows 10 上安装 NumPy
解析文本的过程
在此复杂选项中解析文本的方法如下所述。
- 最重要的一步是通过读取文件的内容来理解输入格式。 例如, with open和read()函数用于打开和读取名为sample的文件的内容。 示例文件包含文件file.txt中的内容; 要了解如何修复解析错误,必须完整读取文件。
- 打印文件的内容以手动分析数据以找出值的元数据。 这里, print()函数用于打印示例文件的内容。
- 解析文本所需的数据包被导入到代码中,并为类命名以进行进一步编码。 在这里,正则表达式和pandas被导入。
- 代码所需的正则表达式在文件中定义,包括正则表达式模式和正则表达式函数。 这允许文本对象或语料库采用代码进行数据分析。
- 要了解如何解析文本,您可以参考此处给出的示例代码。 compile()函数用于从文件filename的组stringname1编译字符串。 命令ief_parse_line(line)使用了在正则表达式中检查匹配的函数,
- 代码的行解析器是使用def_parse_file(filepath)编写的,其中定义的函数检查指定函数中的所有正则表达式匹配。 在这里,regex search()方法在文件filename中搜索键rx并返回第一个匹配的正则表达式的键和匹配项。 该步骤的任何问题都可能导致解析文本 x 时出错。
- 下一步是使用文件解析器函数编写文件解析器,即def_parse_file(filepath) 。 创建一个空列表来收集代码的数据,如data = [] ,通过match = _parse_line(line)在每一行检查匹配,并根据数据类型返回确切的值数据。
- 要提取表格的数字和值,使用命令行.strip().split(',') 。 row{}命令用于创建包含数据行的字典。 data.append(row)命令用于理解数据并将其解析为表格格式。
命令data = pd.DataFrame(data)用于从 dict 值创建 pandas DataFrame。 或者,您可以将以下命令用于如下所述的相应目的。

- data.set_index(['string', 'integer'], inplace=True)设置表的索引。
- data = data.groupby(level=data.index.names).first()合并和删除 nans。
- data = data.apply(pd.to_numeric, errors='ignore')将分数从浮点数升级为整数值。
了解如何解析文本的最后一步是使用if 语句测试解析器,方法是将值分配给变量data并使用print(data)命令打印它。
此处给出了上述解释的示例代码。
以 open('file.txt') 作为示例:
sample_contents = sample.read()
打印(样本内容)
重新进口
将熊猫导入为 pd
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line(行):
对于 rx_filename.items() 中的密钥 rx:
匹配 = rx.search(行)
如果匹配:
返回键,匹配
返回无,无
def parse_file(文件路径):
数据 = []
使用 open(filepath, 'r') 作为 file_object:
line = file_object.readline()
而线:
键,匹配 = _parse_line(line)
如果键 == 'string1':
字符串 = match.group('string1')
整数 = int(string1)
value_type = match.group('string1')
line = file_object.readline()
而 line.strip():
数字,值 = line.strip().split(',')
值 = 值.strip()
行 = {
“数据1”:字符串1,
'Data2':数字,
值类型:值
}
data.append(行)
line = file_object.readline()
line = file_object.readline()
数据 = pd.DataFrame(数据)
返回数据
如果_ _name_ _ = = '_ _main_ _':
文件路径 = 'sample.txt'
数据 = 解析(文件路径)
打印(数据) 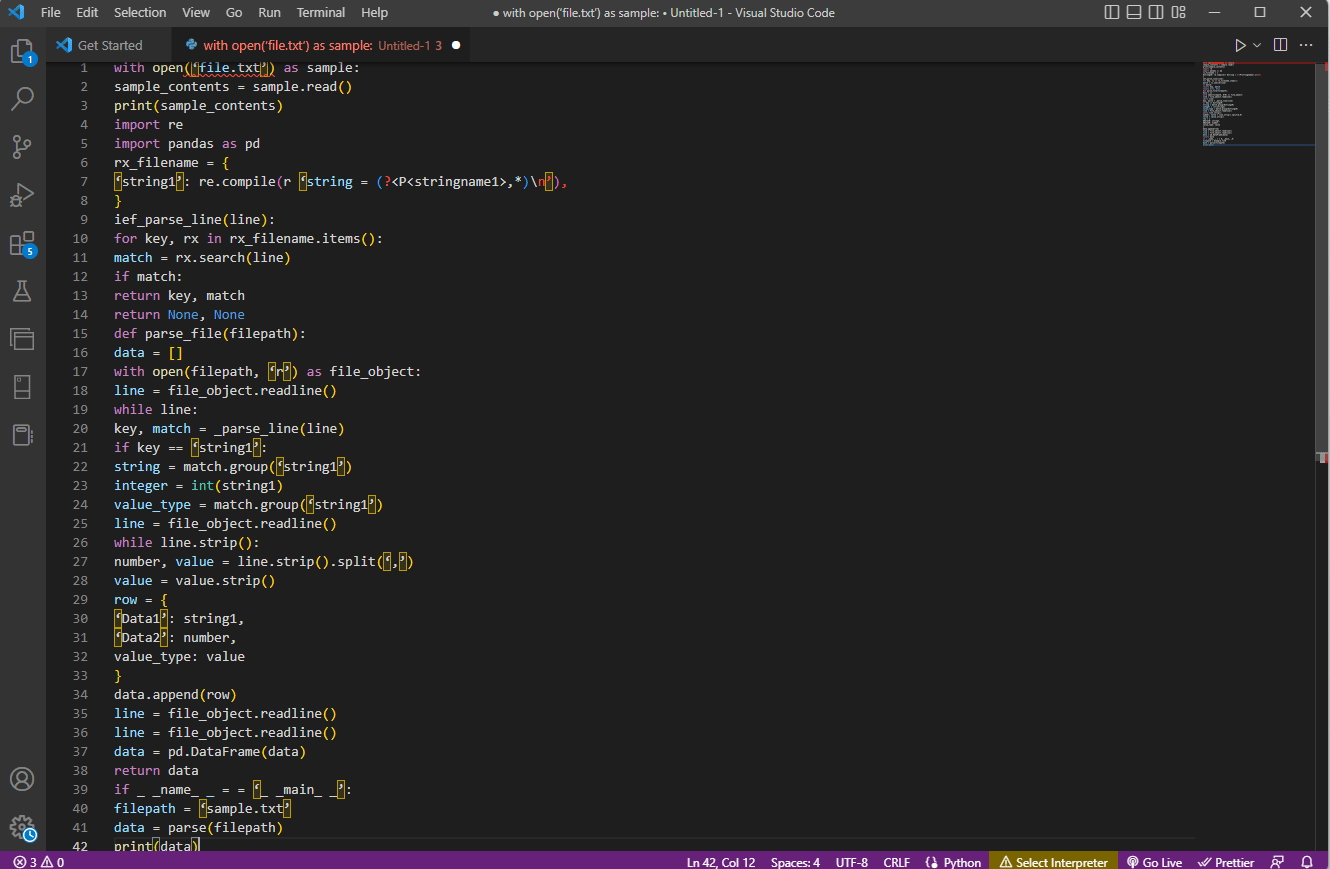
方法二:通过词分词
根据某些规则将文本或语料库转换为标记或更小片段的过程称为标记化。 要了解如何修复解析错误,分析代码中的单词标记化命令很重要。 与正则表达式类似,可以在此方法中创建自己的规则,它有助于文本预处理任务,例如映射词性。 此外,这种方法还执行诸如查找和匹配常用词、清理文本以及为高级文本分析技术(如情感分析)准备数据等活动。 如果分词不当,可能会出现解析文本 x 的错误。
Ntlk 库
该过程借助称为 nltk 的流行语言工具包库的帮助,该库具有用于执行许多 NLP 作业的丰富函数集。 这些可以通过 Pip 或 Pip 安装包下载。 要了解如何解析文本,您可以使用默认包含该库的 Anaconda 发行版的基本包。
标记化形式
这种方法的常见形式是词分词和句子分词。 由于单词级别的标记,前者只打印一个单词一次,而后者在句子级别打印单词。
解析文本的过程
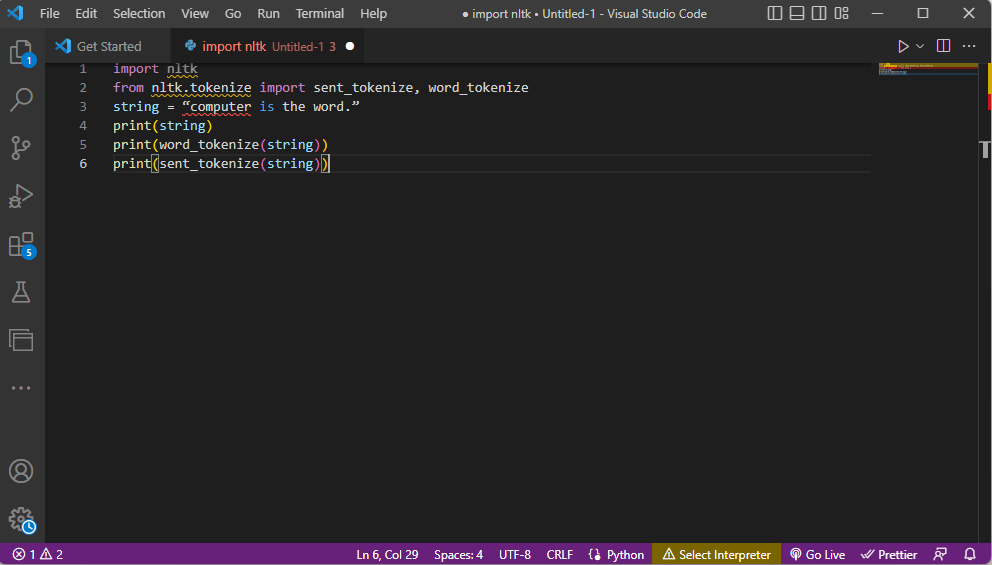
- 导入 ntlk 工具包库,并从库中导入标记化表格。
- 给出了一个字符串,并给出了执行标记化的命令。
- 打印字符串时,输出将是computer is the word。
- 在单词标记化或word_tokenize()的情况下,句子中的每个单词都单独打印在''中,并用逗号分隔。 该命令的输出将是'computer'、'is'、'the'、'word'、'.'
- 在句子标记化或sent_tokenize()的情况下,单个句子放置在''内,并且允许单词重复。 该命令的输出将是“computer is the word”。
此处给出了解释上述标记化步骤的代码。
导入 nltk 从 nltk.tokenize 导入 sent_tokenize,word_tokenize string = “计算机就是这个词。” 打印(字符串) 打印(word_tokenize(字符串)) 打印(sent_tokenize(字符串))
另请阅读:如何修复 javascript:void(0) 错误
方法三:通过DocParser类
与 DataFrame Class 类似,可以使用 Class DocParser 来解析代码中的文本。 该类允许您使用文件路径调用 parse 函数。
解析文本的过程
要了解如何使用 DocParser 类解析文本,请按照以下说明进行操作。
- get_format(filename)函数用于提取文件扩展名,将其返回给函数的集合变量,并将其传递给下一个函数。 例如, p1 = get_format(filename)将提取 filename 的文件扩展名,将其设置为变量p1 ,并将其传递给下一个函数。
- 使用if-elif-else语句和函数构建具有其他函数的逻辑结构。
- 如果文件扩展名有效且结构符合逻辑,则使用get_parser函数解析文件路径中的数据,并将字符串对象返回给用户。
注意:要知道如何修复解析错误,必须正确实现此功能。
- 数据值的解析是通过文件的文件扩展名完成的。 该类的具体实现是parse_txt或parse_docx ,用于从给定文件类型的部分生成字符串对象。
- 可以对其他可读扩展名的文件进行解析,例如parse_pdf 、 parse_html和parse_pptx 。
- 可以使用 import 语句将数据值和接口导入应用程序并实例化 DocParser 对象。 这可以通过解析 Python 语言中的文件来完成,例如parse_file.py 。 此操作必须小心完成,以避免在解析文本 x 时出错。
方法四:通过解析文本工具
Parse text 工具用于从变量中提取特定数据并将它们映射到其他变量。 这独立于任务中使用的任何其他工具,并且 BPA 平台工具用于使用和输出变量。 使用此处提供的链接在线访问 Parse Text Tool 并使用前面给出的有关如何解析文本的答案。
方法 5:通过 TextFieldParser (Visual Basic)
TextFieldParser 利用对象来解析和处理非常大的结构化和分隔文件。 这种方法可以使用文本的宽度和列,例如日志文件或遗留数据库信息。 解析方法类似于在文本文件上迭代代码,主要用于提取文本字段,类似于字符串操作方法。 这样做是为了使用定义的分隔符(例如逗号或制表符空格)对分隔的字符串和各种宽度的字段进行标记。
解析文本的函数
以下函数可用于解析此方法中的文本。
- 要定义分隔符,使用SetDelimiters 。 例如,命令testReader.SetDelimiters (vbTab)用于将制表符空间设置为分隔符。
- 要将字段宽度设置为正整数值到文本文件的固定字段宽度,可以使用testReader.SetFieldWidths (integer)命令。
- 要测试文本的字段类型,可以使用以下命令testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth 。
查找 MatchObject 的方法
有两种基本方法可以在代码或解析后的文本中找到 MatchObject。
- 第一种方法是定义格式并使用ReadFields方法循环文件。 此方法将有助于处理代码的每一行。
- PeekChars方法用于在读取之前单独检查每个字段,定义多种格式并做出反应。
在任何一种情况下,如果在执行解析或查找如何解析文本时字段与指定格式不匹配,则会返回MalformedLineException异常。
专业提示:如何通过 MS Excel 解析文本
作为解析文本的最后且简单的方法,您可以使用 MS Excel 应用程序作为解析器来创建制表符分隔和逗号分隔的文件。 这将有助于与您的解析结果进行交叉检查,并有助于找到如何修复解析错误。
1. 选择源文件中的数据值,同时按Ctrl+C键复制文件。
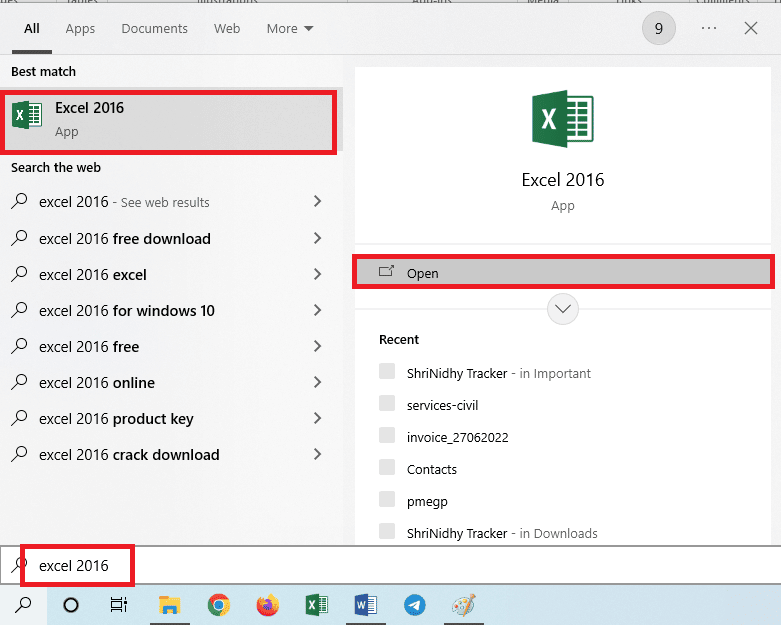
2. 使用 Windows 搜索栏打开Excel应用程序。
3. 单击A1单元格并同时按Ctrl + V 键粘贴复制的文本。
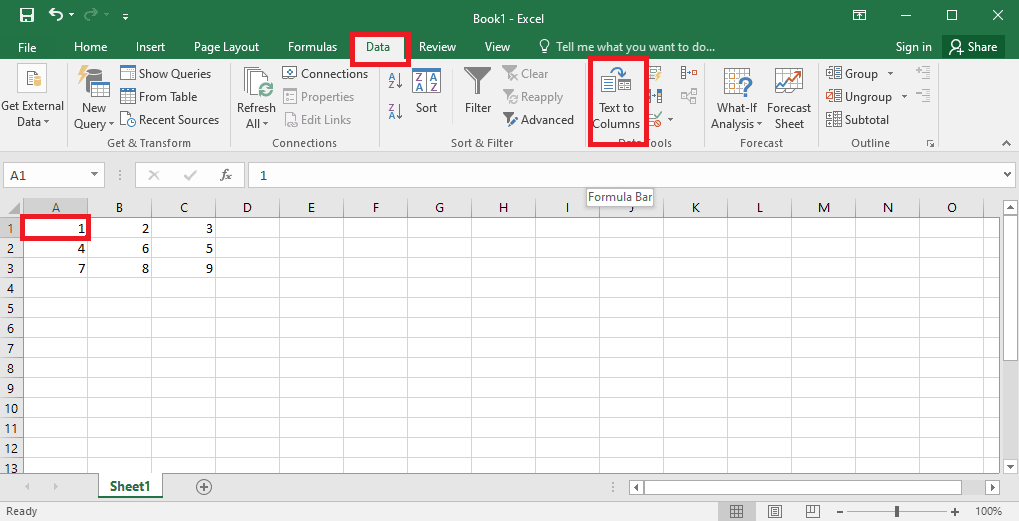
4. 选择A1单元格,导航到数据选项卡,然后单击数据工具部分中的文本到列选项。
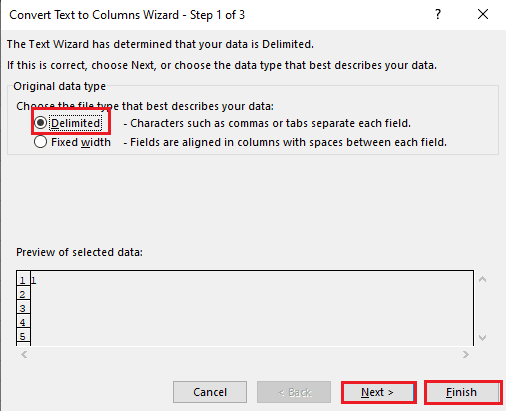
5A。 如果使用逗号或制表符空格作为分隔符,请选择Delimited选项,然后单击Next和Finish按钮。
5B。 选择固定宽度选项,为分隔符指定一个值,然后单击下一步和完成按钮。
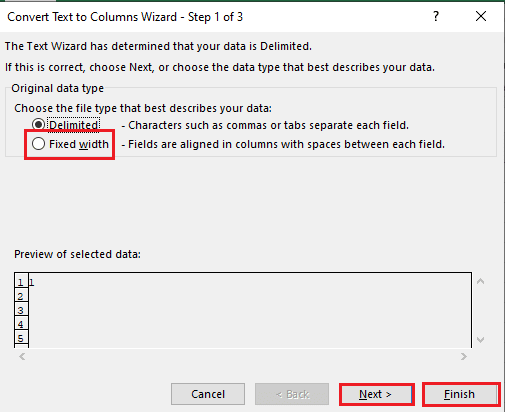
另请阅读:如何修复移动 Excel 列错误
如何修复解析错误
Android 设备上可能会出现解析文本 x 的错误,因为解析错误:解析包时出现问题。 这通常发生在应用无法从 Google Play 商店安装或运行第三方应用时。
如果字符向量列表被循环并且其他函数形成用于计算数据值的线性模型,则可能会出现错误文本 x。 错误消息是解析中的错误(文本 = x,keep.source = FALSE):<文本>:2.0:输入 1 的意外结束:OffenceAgainst ~ ^。
您可以阅读有关如何在 Android 上修复解析错误的文章,以了解修复错误的原因和方法。
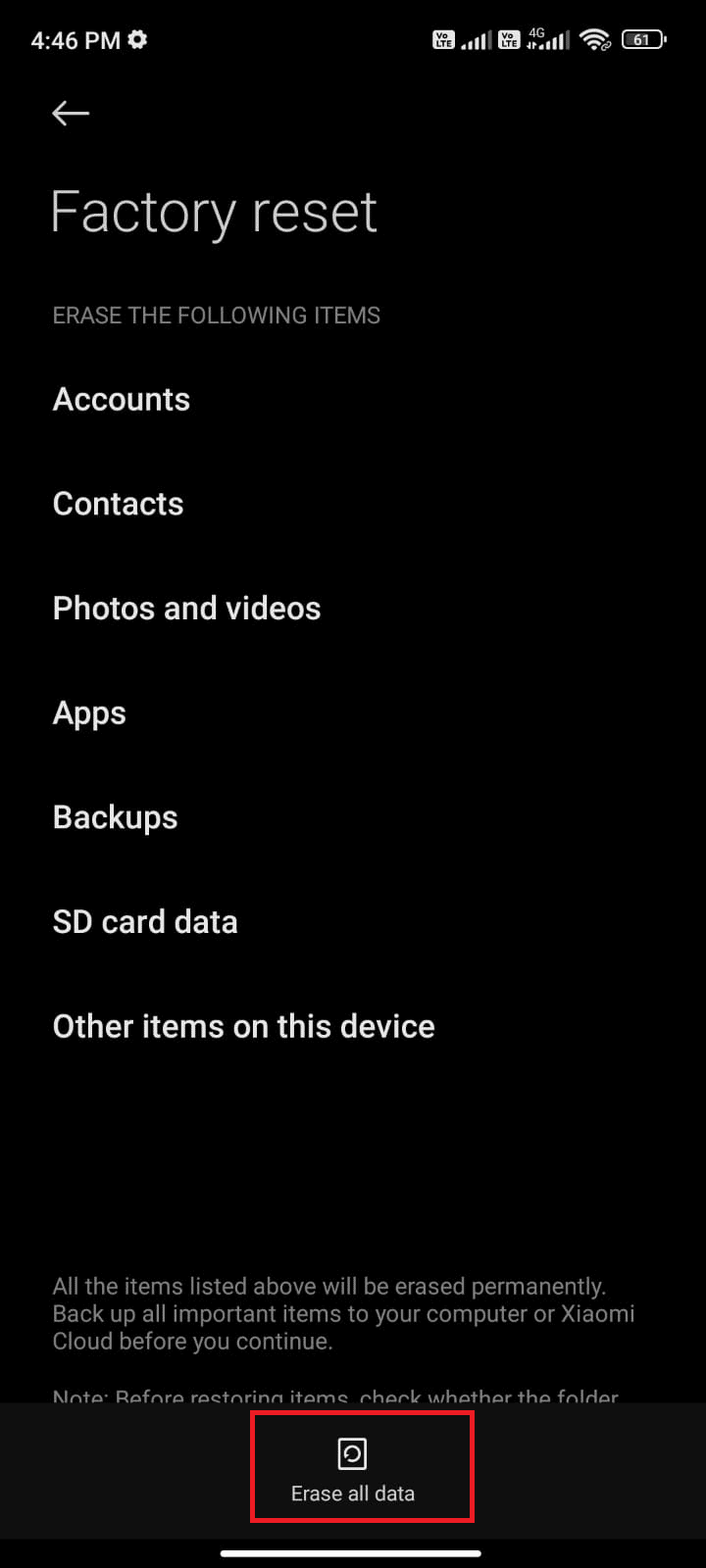
除了指南中的解决方案外,您还可以尝试以下修复。
- 重新下载.apk文件或恢复文件名。
- 如果您具有专家级编程技能,则恢复Androidmanifest.xml文件中的更改。
推荐的:
- 如何删除别人的 Facebook 帐户
- 成为道德黑客所需的 10 大技能
- 共享代码和文本的 21 种最佳 Pastebin 替代方案
- 修复命令失败并出现错误代码 1 Python Egg 信息
这篇文章有助于教授如何解析文本并学习如何修复解析错误。 让我们知道哪种方法有助于修复解析文本 x 中的错误以及首选哪种解析方法。 请在下面的评论部分分享您的建议和疑问。