
如何使用 Tesseract 从 Linux 命令行执行 OCR
已发表: 2022-01-29
您可以使用 Tesseract OCR 引擎在 Linux 命令行上从图像中提取文本。 它快速、准确,支持大约 100 种语言。 以下是如何使用它。
光学字符识别
光学字符识别 (OCR) 是一种查看和查找图像中的单词,然后将它们提取为可编辑文本的能力。 对于人类来说,这个简单的任务对于计算机来说是非常困难的。 至少可以说,早期的努力很笨拙。 如果字体或大小不符合 OCR 软件的喜好,计算机通常会感到困惑。
尽管如此,这一领域的先驱者仍然受到高度尊重。 如果您丢失了文档的电子副本,但仍有打印版本,OCR 可以重新创建可编辑的电子版本。 即使结果不是 100% 准确,这仍然可以节省大量时间。
通过一些手动整理,您将获得您的文档。 人们原谅了它所犯的错误,因为他们了解 OCR 包所面临的任务的复杂性。 另外,这比重新输入整个文档要好。
从那以后,情况有了显着改善。 由 Hewlett Packard 编写的 Tesseract OCR 应用程序于 1980 年代作为商业应用程序开始。 它于 2005 年开源,现在得到 Google 的支持。 它具有多语言功能,被认为是可用的最准确的 OCR 系统之一,您可以免费使用它。
安装 Tesseract OCR
要在 Ubuntu 上安装 Tesseract OCR,请使用以下命令:
sudo apt-get install tesseract-ocr

在 Fedora 上,命令是:
须藤 dnf 安装 tesseract

在 Manjaro 上,您需要输入:
sudo pacman -Syu tesseract

使用 Tesseract OCR
我们将对 Tesseract OCR 提出一系列挑战。 我们的第一个包含文本的图像是从《通用数据保护条例》的第 63 条独奏会中摘录的。 让我们看看 OCR 是否可以读取(并保持清醒)。

这是一个棘手的图像,因为每个句子都以微弱的上标数字开头,这在立法文件中很常见。
我们需要给tesseract命令一些信息,包括:
- 我们希望它处理的图像文件的名称。
- 它将创建以保存提取的文本的文本文件的名称。 我们不必提供文件扩展名(它始终是 .txt)。 如果同名文件已经存在,它将被覆盖。
- 我们可以使用
--dpi选项告诉tesseract图像的每英寸点数 (dpi) 分辨率是多少。 如果我们不提供 dpi 值,tesseract会尝试找出它。
我们的图像文件名为“recital-63.png”,其分辨率为 150 dpi。 我们将从它创建一个名为“recital.txt”的文本文件。
我们的命令如下所示:
tesseract 独奏会-63.png 独奏会--dpi 150

结果非常好。 唯一的问题是上标——它们太暗而无法正确阅读。 高质量的图像对于获得良好的效果至关重要。

tesseract已将上标数字解释为引号 (") 和度数符号 (°),但实际文本已被完美提取(必须修剪图像的右侧以适合此处)。
最后一个字符是一个字节,十六进制值为0x0C,即回车。
下面是另一张不同大小的文字图片,包括粗体和斜体。

该文件的名称是“bold-italic.png”。 我们要创建一个名为“bold.txt”的文本文件,所以我们的命令是:
tesseract粗体斜体.png粗体--dpi 150

这篇没有任何问题,文本被完美地提取出来。

使用不同的语言
Tesseract OCR 支持大约 100 种语言。 要使用一种语言,您必须先安装它。 当您在列表中找到要使用的语言时,请记下其缩写。 我们将安装对威尔士语的支持。 它的缩写是“cym”,是“Cymru”的缩写,意思是威尔士语。
安装包名为“tesseract-ocr-”,末尾标注语言缩写。 要在 Ubuntu 中安装威尔士语言文件,我们将使用:
sudo apt-get install tesseract-ocr-cym


带有文字的图像如下。 这是威尔士国歌的第一节。

让我们看看 Tesseract OCR 是否能够应对挑战。 我们将使用-l (语言)选项让tesseract知道我们想要使用的语言:
tesseract hen-wlad-fy-nhadau.png 国歌 -l cym --dpi 150

tesseract完美应对,如下面的摘录文本所示。 Da iawn ,正方体 OCR。

如果您的文档包含两种或多种语言(例如威尔士语到英语词典),您可以使用加号 ( + ) 告诉tesseract添加另一种语言,如下所示:
tesseract image.png 文本文件 -l eng+cym+fra
将 Tesseract OCR 与 PDF 结合使用
tesseract命令旨在处理图像文件,但它无法读取 PDF。 但是,如果您需要从 PDF 中提取文本,您可以先使用另一个实用程序来生成一组图像。 单个图像将代表 PDF 的单个页面。
您需要的pdftppm实用程序应该已经安装在您的 Linux 计算机上。 我们将用于示例的 PDF 是 Alan Turing 关于人工智能的开创性论文“计算机与智能”的副本。

我们使用-png选项来指定我们要创建 PNG 文件。 我们的 PDF 文件名为“turing.pdf”。 我们将图像文件命名为“turing-01.png”、“turing-02.png”等:
pdftoppm -png 图灵.pdf 图灵

要使用单个命令对每个图像文件运行tesseract ,我们需要使用 for 循环。 对于我们的每个“turing- nn.png ”文件,我们运行tesseract ,并创建一个名为“text-”的文本文件,加上“turing- nn ”作为图像文件名的一部分:
对于我在图灵-??.png; 做 tesseract "$i" "text-$i" -l eng; 完毕;

要将所有文本文件合并为一个,我们可以使用cat :
cat text-turing* > complete.txt

那么,它是怎么做的呢? 很好,如下所示。 不过,第一页看起来很有挑战性。 它具有不同的文本样式和大小以及装饰。 页面右边缘还有一个垂直的“水印”。
但是,输出接近原始。 显然,格式丢失了,但文本是正确的。
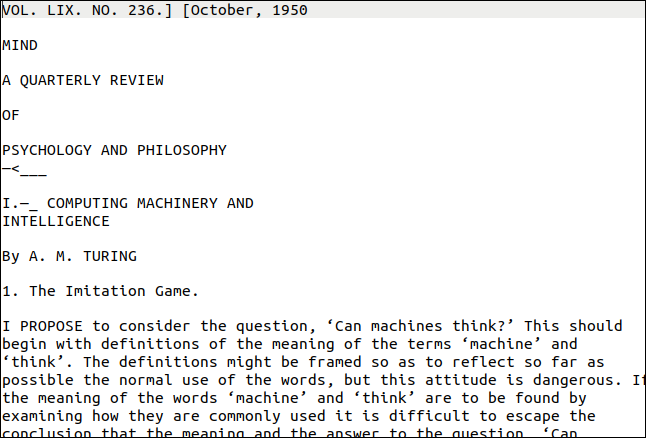
垂直水印被转录为页面底部的一行乱码。 文本太小,无法被tesseract准确读取,但很容易找到并删除它。 最糟糕的结果将是每行末尾的杂散字符。
奇怪的是,第二页问题和答案列表开头的单个字母被忽略了。 PDF 中的部分如下所示。

正如您在下面看到的,问题仍然存在,但每行开头的“Q”和“A”都丢失了。

图表也不会被正确转录。 让我们看看当我们尝试从图灵 PDF 中提取如下所示的内容时会发生什么。

正如您在下面的结果中看到的那样,字符被读取,但图表的格式丢失了。

再次, tesseract与小尺寸的下标作斗争,并且它们被错误地渲染。
不过,平心而论,这仍然是一个不错的结果。 我们无法提取简单的文本,但后来故意选择了这个示例,因为它提出了挑战。
需要时的好解决方案
OCR 不是您每天都需要使用的东西。 但是,当确实需要时,很高兴知道您拥有最好的 OCR 引擎之一。