
如何在 Linux 上比较二进制文件
已发表: 2022-08-20
如何检查两个 Linux 二进制文件是否相同? 如果它们是可执行文件,则任何差异都可能意味着不需要的或恶意的行为。 这是检查它们是否不同的最简单方法。
比较二进制文件
Linux 有丰富的方法来比较和分析文本文件。 diff命令将为您比较两个文件,并突出显示差异。 它甚至可以在更改的两侧提供几行,以围绕更改的行提供一些上下文。 colordiff命令添加颜色,使视觉上的差异解析更加容易。
开发人员和作者使用diff来突出显示不同版本的程序源代码文件或草稿文本之间的差异。 它快速简单,您不需要任何技术技能即可查看文本字符串之间的差异。
在二进制文件的世界里,事情并不是那么简单。 二进制文件不是由纯文本组成的。 它们由许多包含数值的字节组成。 如果它是压缩文件,例如 TAR 存档或 ZIP 文件,则这些值表示存储在存档文件中的压缩文件,以及解压缩和提取文件所需的符号表。

如果二进制文件是可执行文件,则文件字节的数值被解释为 CPU 的机器代码指令、元数据、标签或编码数据。 当二进制文件执行或被另一个应用程序使用时,对二进制文件或库文件的更改可能会导致行为差异。
欺骗文件的创建或修改日期和时间很容易。 这意味着可能有两个版本的文件具有相同的名称、文件大小(如果更改逐字节替换现有内容)和日期戳。 然而,其中一个文件可能已被更改。
安全哈希算法
安全哈希算法是一种基于数学的算法。 它通过扫描文件中的所有字节并对它们应用数学变换以生成哈希值来创建一个 64 位值。 在任何一天,同一个文件总是会产生相同的哈希值。 即使是一个字节的差异也会导致完全不同的哈希值。
您经常会在其下载页面上看到文件的哈希值。 下载文件后,您应该为该文件生成一个哈希值。 如果它与网页上显示的哈希值不同,则表明该文件已被盗用。 它要么被篡改并替换了真实文件(以使人们下载受污染的文件),要么在传输过程中被损坏。
在我们的测试计算机上,我们有同一个文件的两个副本,一个共享库。 这些文件已被重命名,以便它们可以位于同一目录中。 理论上,这些文件应该是相同的。 毕竟,它们应该是共享库的相同版本。
ls -l *.so

这些文件具有相同的大小、相同的日期戳和相同的时间戳。 对于不经意的观察者来说,它们看起来是一样的。 让我们使用sha256sum命令并为每个文件生成一个哈希。
sha256sum binary_file1.so
sha256sum binary_file2.so
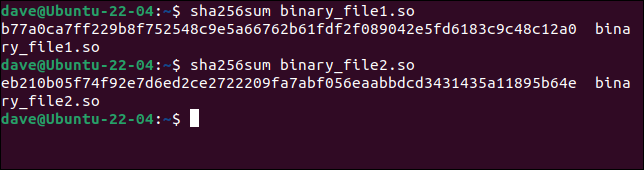
哈希完全不同,清楚地表明两个文件之间存在差异。 如果网站显示正版文件的哈希,您可以丢弃不匹配的文件。
寻找差异
如果您想查看更改,也有办法做到这一点。 你不需要能够反编译文件,也不需要理解汇编或机器代码就可以看到修改。 理解这些变化意味着什么,以及它们的目的是什么,当然需要更深入的技术知识。 但只要知道这些变化有多大就可以表明文件发生了什么。
如果我们在这两个二进制文件上使用diff ,我们会得到一个有点平淡无奇的响应。
diff binary_file1.so binary_file2.so

我们已经知道这些文件是不同的。 让我们试试cmp 。
cmp binary_file1.so binary_file2.so

这告诉我们更多一点。 两个文件不同的第一个字节是字节数13451。即从二进制文件的开头算起,两个二进制文件的字节13451不同。 所以 13451 是第一个差异的偏移量,从文件的开头开始。
偶然地,在整个文件中,会有包含十六进制值 0x10 的字节。 这是 Linux 在文本文件中用作行尾字符的值。 cmp命令在二进制文件的开头和第一个差异的位置之间遇到了 131 个字节和这个值。 所以它认为它在第 132 行。在这种情况下,它真的没有任何意义。
如果我们添加-l (详细)选项,我们将开始获得有用的信息。
cmp -l binary_file1.so binary_file2.so
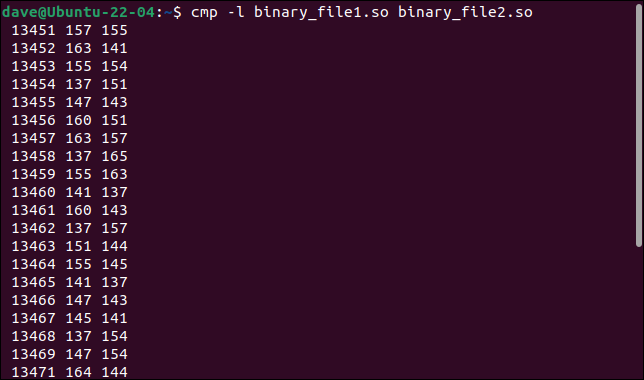
列出了所有不同的字节。 显示字节数或偏移量、第一个文件的值和第二个文件的值,每行输出一个字节。
字节值以八进制显示,而不是二进制文件使用的通常十六进制格式。 尽管如此,我们还是学到了一些别的东西。 所有改变的字节都在一个连续的序列中。 它们的偏移量每字节增加一。
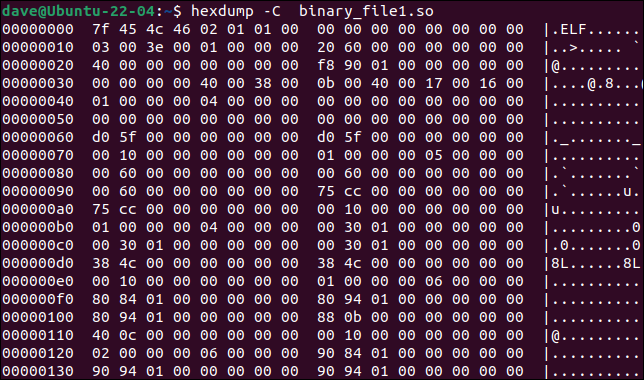
hexdump工具会将二进制文件转储到终端窗口。 如果我们使用-C (规范)选项,输出将在每一行列出偏移量、该偏移量处 16 个字节的值,以及(如果有的话)字节值的 ASCII 表示。

hexdump -C binary_file1.so
我们可以使用hexdump的输出作为diff的输入,让diff像读取两个文本文件一样工作。
差异<(hexdump binary_file1.so)<(hexdump binary_file2.so)
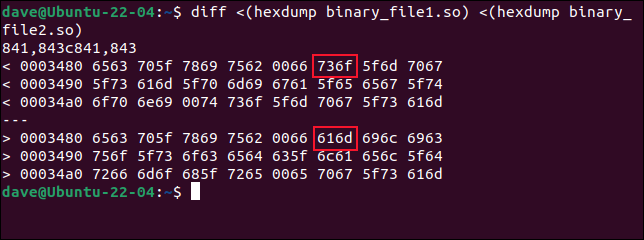
diff查找不同的行,并将第一个文件中的十六进制字节值显示在第二个文件中的值之上。 第一行的偏移量是 0x3480,即十进制的 13440。 早些时候, cmp告诉我们第一个变化发生在字节 13451,即 0x348B。 这实际上与我们在这里看到的相符。
diff的输出是两个字节的块。 第一对字节是偏移量 0x3480 的字节 0 和 1,第二个块保存偏移量的字节 2 和 3。 块 6 将保存字节 0xA 和 0xB,或十进制的 10 和 11。 这些是字节 13450 和 13451。我们可以看到它们是第一个不同的字节。 两个文件中的前五对字节相同。
但是,因为diff从零开始计数,所以cmp调用的 13451 将是字节 13540 到diff 。 更令人困惑的是,每个两字节块中的字节顺序由diff颠倒。 字节实际上是按以下顺序列出的:1 和 0、3 和 2、5 和 4、7 和 6,依此类推。
该命令在计算上也很昂贵——一次两个 hexdump 和一个hexdumps尤其是在被diff的文件很大的情况下。
但是如果hexdump -C可以将二进制文件的 ASCII 版本发送到终端窗口,我们为什么不将输出重定向到文本文件,然后将这两个文本文件与diff进行比较?
hexdump -C binary_file1.so > binary1.txt
hexdump -C binary_file2.so > binary2.txt
diff binary1.txt binary2.txt
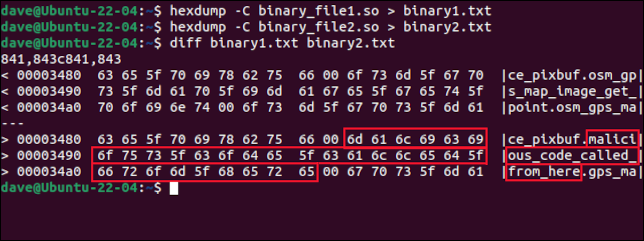
两个文件之间的差异显示在两个简短的摘录中。 它们旁边有一个 ASCII 表示。 文件之间的每个差异都会有一对提取。 在这个例子中,只有一个区别。
这一切都很好,但如果有什么东西可以为你做这一切,那不是很好吗?
VBinDiff
VBinDiff 程序可以从所有主要发行版的常用存储库中安装。 要在 Ubuntu 上安装它,请使用以下命令:
sudo apt install vbindiff

在 Fedora 上,您需要输入:
须藤 dnf 安装 vbindiff

Manjaro 用户需要使用pacman 。
sudo pacman -Sy vbindiff

要使用该程序,请在命令行上传递两个二进制文件的名称。
vbindiff binary_file1.so binary_file2.so

基于终端的应用程序打开,在滚动视图中显示这两个文件。
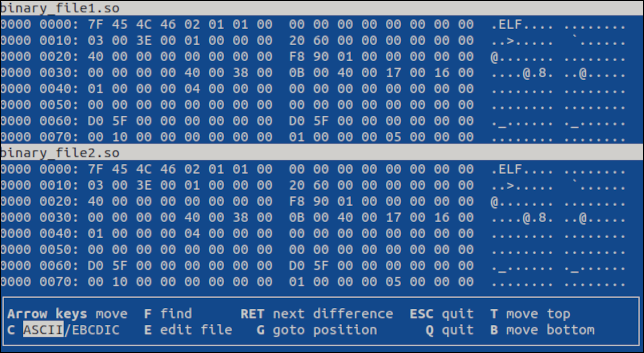
您可以使用鼠标滚轮或“UpArrow”、“DownArrow”、“Home”、“End”、“PageUp”和“PageDown”键来浏览文件。 两个文件都会滚动。
点击“Enter”键跳转到第一个差异。 两个文件中都突出显示了差异。
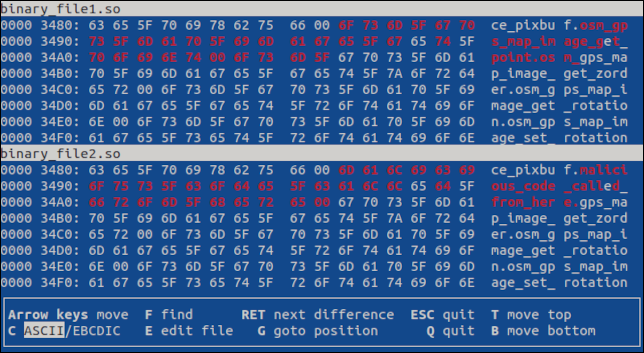
如果有更多差异,点击“Enter”将显示下一个差异。 按“q”或“Esc”将退出程序。
有什么不同?
如果您正在使用属于其他人的计算机并且不允许安装任何软件包,则可以使用cmp 、 diff和hexdump 。 如果您需要捕获输出以进行进一步处理,这些工具也是可以使用的。
但是,如果您被允许安装包,VBinDiff 会使您的工作流程更轻松、更快捷。 事实上,将 VBinDiff 与单个二进制文件一起使用是浏览二进制文件的一种简单方便的方法,这是一个不错的好处。
相关:如何从 Linux 命令行查看二进制文件