
Bash'de CSV Verileri Nasıl Ayrıştırılır
Yayınlanan: 2022-09-16
Virgülle Ayrılmış Değerler (CSV) dosyaları, dışa aktarılan veriler için en yaygın biçimlerden biridir. Linux'ta Bash komutlarını kullanarak CSV dosyalarını okuyabiliriz. Ama çok hızlı, çok karmaşık hale gelebilir. Bir el uzatacağız.
CSV Dosyası Nedir?
Virgülle Ayrılmış Değerler dosyası, tablolaştırılmış verileri tutan bir metin dosyasıdır. CSV, bir tür sınırlandırılmış veridir. Adından da anlaşılacağı gibi , her bir veri veya değer alanını komşularından ayırmak için virgül “ ” kullanılır.
CSV her yerdedir. Bir uygulamanın içe ve dışa aktarma işlevleri varsa, neredeyse her zaman CSV'yi destekler. CSV dosyaları insan tarafından okunabilir. Daha azıyla içlerine bakabilir, herhangi bir metin düzenleyicide açabilir ve programdan programa taşıyabilirsiniz. Örneğin, verileri bir SQLite veritabanından dışa aktarabilir ve LibreOffice Calc'de açabilirsiniz.
Ancak, CSV bile karmaşık hale gelebilir. Veri alanında virgül olmasını ister misiniz? Bu alanın etrafına tırnak işareti “ " ” sarılmış olmalıdır. Bir alana tırnak işareti eklemek için her bir tırnak işaretinin iki kez girilmesi gerekir.
Elbette, yazdığınız bir program veya komut dosyası tarafından oluşturulan CSV ile çalışıyorsanız, CSV formatı muhtemelen basit ve anlaşılır olacaktır. Linux'un Linux olduğu daha karmaşık CSV formatlarıyla çalışmak zorunda kalırsanız, bunun için de kullanabileceğimiz çözümler var.
Bazı Örnek Veriler
Online Data Generator gibi siteleri kullanarak bazı örnek CSV verilerini kolayca oluşturabilirsiniz. İstediğiniz alanları tanımlayabilir ve kaç satır veri istediğinizi seçebilirsiniz. Verileriniz gerçekçi kukla değerler kullanılarak oluşturulur ve bilgisayarınıza indirilir.
50 satırlık sahte çalışan bilgilerini içeren bir dosya oluşturduk:
- id : Basit bir benzersiz tamsayı değeri.
- firstname : Kişinin adı.
- soyadı : Kişinin soyadı.
- job-unvan : Kişinin iş unvanı.
- email-address : Kişinin e-posta adresi.
- şube : Çalıştıkları şirket şubesi.
- state : Şubenin bulunduğu eyalet.
Bazı CSV dosyalarının alan adlarını listeleyen bir başlık satırı vardır. Örnek dosyamızda bir tane var. İşte dosyamızın başı:
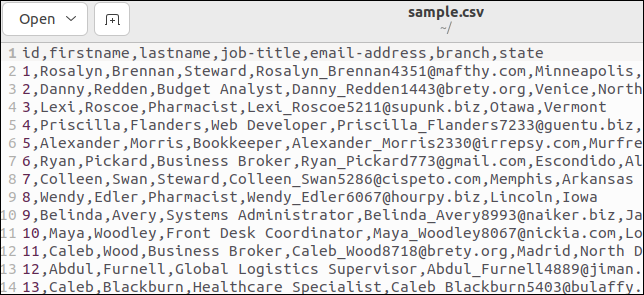
İlk satır, alan adlarını virgülle ayrılmış değerler olarak tutar.
CSV dosyasından Verileri Ayrıştırma
CSV dosyasını okuyacak ve her kayıttan alanları çıkaracak bir script yazalım. Bu komut dosyasını bir düzenleyiciye kopyalayın ve “field.sh” adlı bir dosyaya kaydedin.
#! /bin/bash while IFS="," read -r id ad soyadı iş unvanı e-posta şube durumu yapmak echo "Kayıt Kimliği: $id" echo "Ad: $ad" echo "Soyadı: $soyad" echo "İş Unvanı: $jobtitle" echo "E-posta ekleme: $email" echo " Şube: $dal" echo "Durum: $durum" Eko "" yapıldı < <(kuyruk -n +2 örnek.csv)
Küçük senaryomuzda oldukça fazla şey var. Hadi parçalayalım.

Bir while döngüsü kullanıyoruz. while döngüsü koşulu doğru olduğu sürece, while döngüsünün gövdesi yürütülür. Döngünün gövdesi oldukça basittir. Bazı değişkenlerin değerlerini terminal penceresine yazdırmak için bir echo ifadesi koleksiyonu kullanılır.
while döngüsü koşulu, döngünün gövdesinden daha ilginçtir. IFS="," deyimi ile dahili alan ayırıcı olarak virgül kullanılması gerektiğini belirtiyoruz. IFS bir ortam değişkenidir. read komutu, metin dizilerini ayrıştırırken değerine başvurur.
Verilerde olabilecek ters eğik çizgileri yok saymak için read komutunun -r (ters eğik çizgileri koru) seçeneğini kullanıyoruz. Normal karakterler olarak kabul edilecekler.
read komutunun ayrıştırdığı metin, CSV alanlarından sonra adlandırılan bir dizi değişkende depolanır. Aynı şekilde field1, field2, ... field7 olarak adlandırılabilirlerdi, ancak anlamlı isimler hayatı kolaylaştırır.
Veriler tail komutundan çıktı olarak elde edilir. tail kullanıyoruz çünkü bize CSV dosyasının başlık satırını atlamanın basit bir yolunu sunuyor. -n +2 (satır numarası) seçeneği, tail iki numaralı satırdan okumaya başlamasını söyler.
<(...) yapısına süreç ikamesi denir. Bash'in bir sürecin çıktısını bir dosya tanıtıcısından geliyormuş gibi kabul etmesine neden olur. Bu daha sonra while döngüsüne yönlendirilir ve read komutunun ayrıştıracağı metin sağlanır.
Komut dosyasını chmod komutunu kullanarak yürütülebilir hale getirin. Bu makaleden her komut dosyası kopyaladığınızda bunu yapmanız gerekecektir. Her durumda uygun komut dosyasının adını değiştirin.
chmod +x alan.sh

Komut dosyasını çalıştırdığımızda, kayıtlar, her bir alan farklı bir değişkende depolanacak şekilde, kendi kurucu alanlarına doğru bir şekilde bölünür.
./field.sh
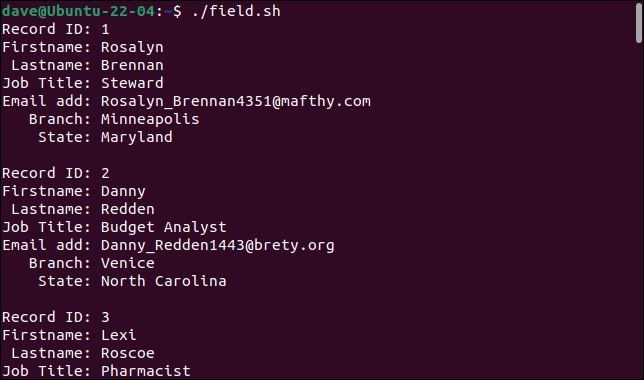
Her kayıt bir dizi alan olarak yazdırılır.
Alanları Seçme
Belki de her alanı almak istemiyoruz veya buna ihtiyacımız yok. cut komutunu dahil ederek bir alan seçimi elde edebiliriz.
Bu komut dosyası "select.sh" olarak adlandırılır.
#!/bin/bash while IFS="," read -r id jobtitle şube durumu yapmak echo "Kayıt Kimliği: $id" echo "İş Unvanı: $jobtitle" echo " Şube: $dal" echo "Durum: $durum" Eko "" yapıldı <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
İşlem ikame maddesine cut komutunu ekledik. -d (sınırlayıcı) seçeneğini, cut sınırlayıcı , “ ” kullanmasını söylemek için kullanıyoruz. -f (alan) seçeneği, cut bir, dört, altı ve yedi numaralı alanları istediğimizi söyler. Bu dört alan, while döngüsünün gövdesinde yazdırılan dört değişkene okunur.
Komut dosyasını çalıştırdığımızda elde ettiğimiz şey budur.
./select.sh
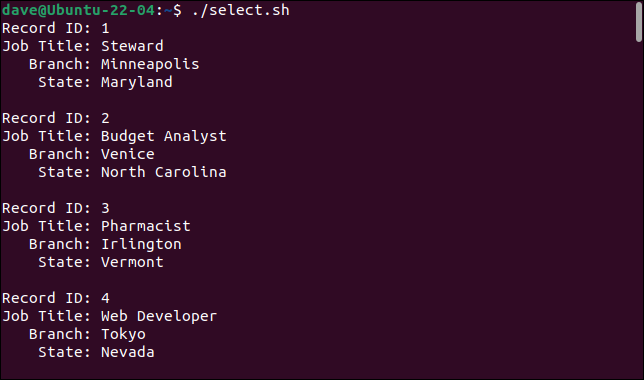
cut komutunu ekleyerek istediğimiz alanları seçip, istemediklerimizi yok sayabiliyoruz.
Şimdiye kadar, çok iyi. Fakat…
Uğraştığınız CSV, alan verilerinde virgül veya tırnak işareti olmadan karmaşık değilse, ele aldıklarımız muhtemelen CSV ayrıştırma ihtiyaçlarınızı karşılayacaktır. Karşılaşabileceğimiz sorunları göstermek için, küçük bir veri örneğini şöyle görünecek şekilde değiştirdik.
id,ad,soyadı,iş unvanı,e-posta adresi,şube,devlet 1,Rosalyn,Brennan,"Steward, Senior",Rosalyn_Brennan4351@mafthy.com,Minneapolis,Maryland 2,Danny,Redden,"Analyst ""Budget""",Danny_Redden1443@brety.org,Venedik,Kuzey Karolina 3,Lexi,Roscoe,Eczacı,,Irlington,Vermont
- Birinci kaydın
job-titlealanında virgül vardır, bu nedenle alanın tırnak içine alınması gerekir. - İkinci kayıt,
jobs-titlealanında iki çift tırnak içine alınmış bir kelimeye sahiptir. - Üçüncü kayıtta
email-addressalanında veri yok.
Bu veriler “sample2.csv” olarak kaydedildi. “field.sh” komut dosyanızı “sample2.csv” olarak adlandıracak şekilde değiştirin ve “field2.sh” olarak kaydedin.
#! /bin/bash while IFS="," read -r id ad soyadı iş unvanı e-posta şube durumu yapmak echo "Kayıt Kimliği: $id" echo "Ad: $ad" echo "Soyadı: $soyad" echo "İş Unvanı: $jobtitle" echo "E-posta ekleme: $email" echo " Şube: $dal" echo "Durum: $durum" Eko "" yapıldı < <(kuyruk -n +2 sample2.csv)
Bu betiği çalıştırdığımızda, basit CSV ayrıştırıcılarımızda görünen çatlakları görebiliriz.

./alan2.sh

İlk kayıt, iş unvanı alanını iki alana böler ve ikinci kısmı e-posta adresi olarak değerlendirir. Bundan sonraki her alan bir yer sağa kaydırılır. Son alan hem branch hem de state değerlerini içerir.
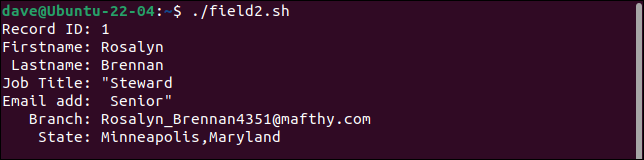
İkinci kayıt tüm tırnak işaretlerini korur. "Bütçe" kelimesinin etrafında yalnızca bir çift tırnak işareti olmalıdır.
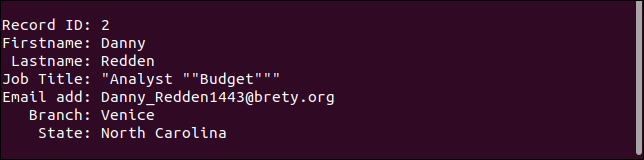
Üçüncü kayıt aslında eksik alanı gerektiği gibi işler. E-posta adresi eksik, ancak her şey olması gerektiği gibi.

Sezgisel olarak, basit bir veri formatı için sağlam bir genel durum CSV ayrıştırıcısı yazmak çok zordur. awk gibi araçlar yaklaşmanıza izin verir, ancak her zaman gözden kaçan uç durumlar ve istisnalar vardır.

Hatasız bir CSV ayrıştırıcısı yazmaya çalışmak muhtemelen ileriye dönük en iyi yol değildir. Alternatif bir yaklaşım - özellikle bir tür son teslim tarihine kadar çalışıyorsanız - iki farklı strateji kullanır.
Biri, verilerinizi işlemek ve çıkarmak için amaca yönelik tasarlanmış bir araç kullanmaktır. İkincisi, verilerinizi sterilize etmek ve katıştırılmış virgül ve tırnak işaretleri gibi sorun senaryolarını değiştirmektir. Basit Bash ayrıştırıcılarınız daha sonra Bash dostu CSV ile başa çıkabilir.
csvkit Araç Takımı
CSV araç seti csvkit , CSV dosyalarıyla çalışmaya yardımcı olmak için açıkça oluşturulmuş bir yardımcı programlar topluluğudur. Bilgisayarınıza yüklemeniz gerekecek.
Ubuntu'ya kurmak için şu komutu kullanın:
sudo apt yükleme csvkit

Fedora'ya yüklemek için şunu yazmanız gerekir:
sudo dnf python3-csvkit'i kurun

Manjaro'da komut şudur:
sudo pacman -S csvkit

Bir CSV dosyasının adını ona iletirsek, csvlook yardımcı programı her alanın içeriğini gösteren bir tablo görüntüler. Alan içeriği, CSV dosyasında depolandıkları gibi değil, alan içeriklerinin neyi temsil ettiğini göstermek için görüntülenir.
Sorunlu “sample2.csv” dosyamızla csvlook deneyelim.
csvlook örnek2.csv
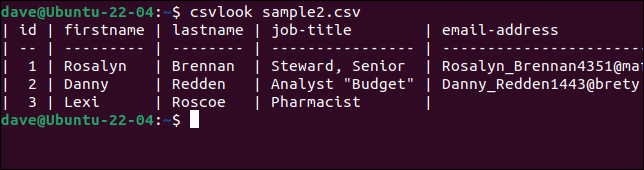
Tüm alanlar doğru şekilde görüntüleniyor. Bu, sorunun CSV olmadığını kanıtlar. Sorun şu ki, betiklerimiz CSV'yi doğru şekilde yorumlamak için çok basit.
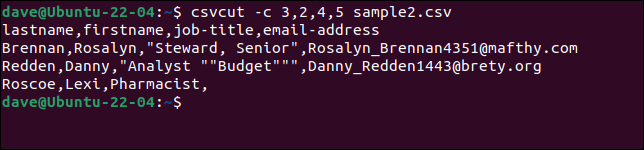
Belirli sütunları seçmek için csvcut komutunu kullanın. -c (sütun) seçeneği, alan adları veya sütun numaraları veya her ikisinin karışımı ile kullanılabilir.
Her kayıttan ad ve soyadları, iş unvanları ve e-posta adreslerini çıkarmamız gerektiğini varsayalım, ancak ad sırasını “soyadı, ad” olarak almak istiyoruz. Tek yapmamız gereken alan adlarını veya numaralarını istediğimiz sıraya koymak.
Bu üç komutun hepsi eşdeğerdir.
csvcut -c soyadı,ad,iş unvanı,e-posta adresi sample2.csv
csvcut -c soyadı,ad,4,5 sample2.csv
csvcut -c 3,2,4,5 örnek2.csv
Çıktıyı bir alana göre sıralamak için csvsort komutunu ekleyebiliriz. Sıralanacak sütunu belirtmek için -c (sütun) seçeneğini ve azalan düzende sıralamak için -r (ters) seçeneğini kullanıyoruz.
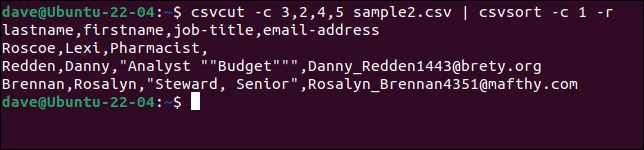
csvcut -c 3,2,4,5 örnek2.csv | csvsort -c 1 -r
Çıktıyı daha güzel hale getirmek için csvlook aracılığıyla besleyebiliriz.
csvcut -c 3,2,4,5 örnek2.csv | csvsort -c 1 -r | csvlook
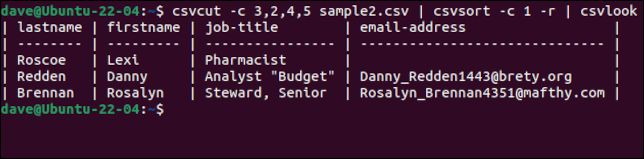
Düzgün bir dokunuş, kayıtlar sıralansa bile, alan adlarının bulunduğu başlık satırının ilk satır olarak tutulmasıdır. Verileri istediğimiz şekilde elde ettiğimiz için mutlu olduğumuzda, csvlook komut zincirinden kaldırabilir ve çıktıyı bir dosyaya yeniden yönlendirerek yeni bir CSV dosyası oluşturabiliriz.
“sample2.file” dosyasına daha fazla veri ekledik, csvsort komutunu kaldırdık ve “sample3.csv” adında yeni bir dosya oluşturduk.
csvcut -c 3,2,4,5 numune2.csv > numune3.csv

CSV Verilerini Temizlemenin Güvenli Yolu
LibreOffice Calc'de bir CSV dosyası açarsanız, her alan bir hücreye yerleştirilecektir. Virgül aramak için bul ve değiştir işlevini kullanabilirsiniz. Bunları ortadan kaybolmaları için “hiçbir şey” ile veya noktalı virgül gibi CSV ayrıştırmasını etkilemeyecek bir karakterle değiştirebilirsiniz “ ; " örneğin.
Alıntılanan alanların çevresinde tırnak işaretleri görmezsiniz. Göreceğiniz tek tırnak işaretleri, alan verilerinin içindeki gömülü tırnak işaretleridir. Bunlar tek tırnak içinde gösterilir. Bunları bulmak ve tek bir kesme işareti “ ' ” ile değiştirmek, CSV dosyasındaki çift tırnak işaretinin yerini alacaktır.
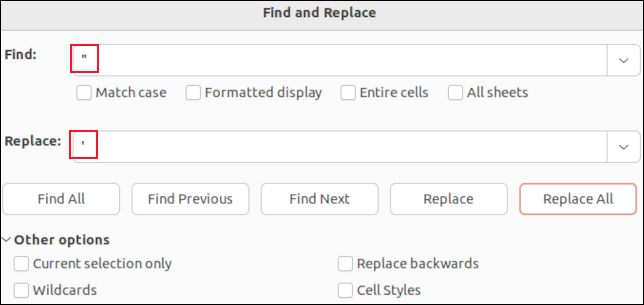
Bul ve değiştir LibreOffice Calc gibi bir uygulamada yapmak, alan ayırıcı virgüllerin hiçbirini yanlışlıkla silemeyeceğiniz veya alıntı yapılan alanların etrafındaki tırnak işaretlerini silemeyeceğiniz anlamına gelir. Yalnızca alanların veri değerlerini değiştireceksiniz.
Noktalı virgüllü alanlardaki tüm virgülleri ve kesme işaretli tüm gömülü tırnak işaretlerini değiştirdik ve değişikliklerimizi kaydettik.
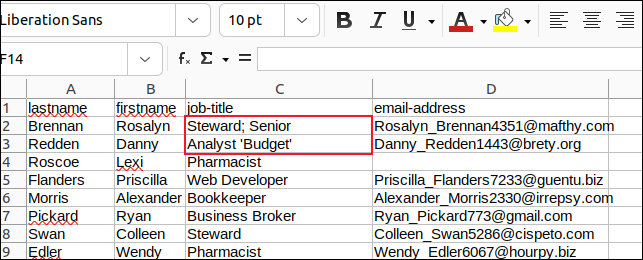
Ardından, “sample3.csv”yi ayrıştırmak için “field3.sh” adlı bir komut dosyası oluşturduk.
#! /bin/bash while IFS="," read -r soyadı ad iş unvanı e-postası yapmak echo "Soyadı: $soyad" echo "Ad: $ad" echo "İş Unvanı: $jobtitle" echo "E-posta ekleme: $email" Eko "" yapıldı < <(kuyruk -n +2 sample3.csv)
Bakalım çalıştırdığımızda ne elde edeceğiz.
./field3.sh
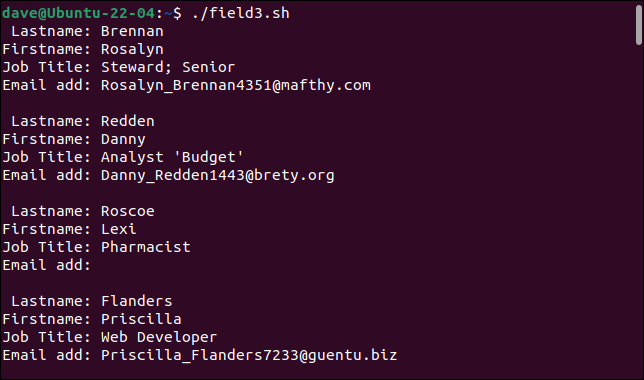
Basit ayrıştırıcımız artık daha önce sorunlu kayıtlarımızı işleyebilir.
Çok Fazla CSV Göreceksiniz
CSV, muhtemelen uygulama verileri için ortak bir dile en yakın şeydir. Bir tür veriyi işleyen çoğu uygulama, CSV'yi içe ve dışa aktarmayı destekler. CSV'yi gerçekçi ve pratik bir şekilde nasıl ele alacağınızı bilmek, sizi iyi durumda tutacaktır.
İLGİLİ: Linux'ta Başlamak için 9 Bash Komut Dosyası Örneği