
Metin Ayrıştırma Nasıl Yapılır?
Yayınlanan: 2022-10-15
Birkaç bilgisayar programlama dili öğrendiyseniz, metni ayrıştırma terimini duymuş olabilirsiniz. Bu, dosyanın karmaşık veri değerlerini basitleştirmek için kullanılır. Makale, dili kullanarak metni nasıl ayrıştıracağınızı bilmenize yardımcı olur. Buna ek olarak eğer parse text x'te hata ile karşılaştıysanız, parse hatasını nasıl düzelteceğinizi makaleden öğreneceksiniz.
İçindekiler
- Metin Ayrıştırma Nasıl Yapılır?
- Metin Ayrıştırma Nedir?
- NLP veya Doğal Dil İşleme
- Metin Ayrıştırma Nedir?
- Metni Ayrıştırma Nedenleri Nelerdir?
- Yöntem 1: DataFrame Sınıfı aracılığıyla
- Yöntem 2: Kelime Belirteçleştirme Yoluyla
- Yöntem 3: DocParser Sınıfı aracılığıyla
- Yöntem 4: Metni Ayrıştırma Aracı Aracılığıyla
- Yöntem 5: TextFieldParser aracılığıyla (Visual Basic)
- Profesyonel İpucu: MS Excel Üzerinden Metin Nasıl Ayrıştırılır
- Ayrıştırma Hatası Nasıl Onarılır
Metin Ayrıştırma Nasıl Yapılır?
Bu makalede, metni çeşitli yollarla ayrıştırmak için tam bir kılavuz gösterdik ve ayrıca metin ayrıştırmaya kısaca giriş yaptık.
Metin Ayrıştırma Nedir?
Herhangi bir kod kullanarak metin ayrıştırma kavramlarını öğrenmek için derine dalmadan önce. Dilin temellerini ve kodlamayı bilmek önemlidir.
NLP veya Doğal Dil İşleme
Metni ayrıştırmak için Yapay Zeka alanının bir alt alanı olan Doğal Dil İşleme veya NLP kullanılır. Metin ayrıştırmak için kategoriye ait dillerden biri olan Python dili kullanılır.
NLP kodları, bilgisayarların çeşitli uygulamalar için uygun hale getirmek için insan dillerini anlamasını ve işlemesini sağlar. ML veya Makine Öğrenimi tekniklerini dile uygulamak için yapılandırılmamış metin verilerinin yapılandırılmış tablo verilerine dönüştürülmesi gerekir. Ayrıştırma etkinliğini tamamlamak için program kodlarını değiştirmek için Python dili kullanılır.
Metin Ayrıştırma Nedir?
Metni ayrıştırmak, basitçe, verileri bir biçimden başka bir biçime dönüştürmek anlamına gelir. Dosyanın kaydedildiği format, kullanıcının çeşitli uygulamalarda kullanabilmesi için ayrıştırılmalı veya farklı bir formatta bir dosyaya dönüştürülmelidir.
- Başka bir deyişle, süreç, dizeyi veya metni analiz etmek ve dosyanın biçimini değiştirerek mantıksal bileşenlere dönüştürmek anlamına gelir.
- Bu ortak programlama görevini tamamlamak için Python dilinin bazı kuralları kullanılır. Metin ayrıştırılırken, verilen metin dizisi daha küçük bileşenlere bölünür.
Metni Ayrıştırma Nedenleri Nelerdir?
Metnin ayrıştırılması gereken nedenler bu bölümde verilmiştir ve metnin nasıl ayrıştırılacağını bilmeden önce bu bir ön koşul bilgidir.
- Tüm bilgisayarlı veriler aynı formatta olmayacaktır ve çeşitli uygulamalara göre farklılık gösterebilir.
- Veri biçimleri çeşitli uygulamalar için değişiklik gösterir ve uyumsuz bir kod bu hataya neden olabilir.
- Tüm veri formatlarının verilerini seçmek için tek bir evrensel bilgisayar programı yoktur.
Yöntem 1: DataFrame Sınıfı aracılığıyla
Python dilinin DataFrame Sınıfı, metni ayrıştırmak için gerekli tüm işlevlere sahiptir. Bu yerleşik kitaplık, herhangi bir biçimdeki verileri başka bir biçime ayrıştırmak için gerekli kodları barındırır.
DataFrame Sınıfının Kısa Tanıtımı
DataFrame Class, veri analiz aracı olarak kullanılan, zengin özelliklere sahip bir veri yapısıdır. Bu, verileri minimum çabayla analiz etmek için kullanılabilecek güçlü bir veri analiz aracıdır.
- Kod, analizi Python dilinde gerçekleştirmek için pandaların DataFrame'ine okunur.
- Sınıf, Python veri analistleri tarafından kullanılan pandalar tarafından sağlanan çok sayıda paketle birlikte gelir.
- Bu sınıfın özelliği, işlevin dahili işlevselliğinin NumPy kitaplığının kullanıcılarından gizlendiği bir kod olan bir soyutlamadır. NumPy kitaplığı, dizilerle çalışmak için komutları ve işlevleri kapsayan bir python kitaplığıdır.
- DataFrame sınıfı, birden çok satır ve sütun diziniyle iki boyutlu bir dizi oluşturmak için kullanılabilir. Bu endeksler çok boyutlu verilerin depolanmasına yardımcı olur ve bu nedenle MultiIndex olarak adlandırılır. Ayrıştırma hatasının nasıl düzeltileceğini bilmek için bunların değiştirilmesi gerekir.
Python dilinin pandaları, x ayrıştırma metninde hatadan kaçınmak için SQL veya veritabanı tarzı işlemleri son derece mükemmel bir şekilde gerçekleştirmeye yardımcı olur. Ayrıca, CSV, MS Excel, JSON, HDF5 ve diğer veri biçimlerinin dosyalarının analizine yardımcı olan bazı IO araçları içerir.
Ayrıca Okuyun: Proxy İsteği Çalışırken Oluşan Hatayı Düzeltin
DataFrame Sınıfını Kullanarak Metni Ayrıştırma İşlemi
Metnin nasıl ayrıştırılacağını öğrenmek için bu bölümde verilen DataFrame Sınıfını kullanarak standart süreci kullanabilirsiniz.
- Giriş verilerinin veri biçimini deşifre edin.
- CSV veya Virgülle Ayrılmış Değer gibi verilerin çıktı verilerine karar verin.
- Kod üzerine list veya dict gibi ilkel bir veri türü yazın.
Not: Kodu boş bir DataFrame'e yazmak sıkıcı ve karmaşık olabilir. Pandalar, bu veri türlerinden DataFrame sınıfında veri oluşturmaya izin verir. Bu nedenle, ilkel veri türündeki veriler, gerekli veri formatına kolayca ayrıştırılabilir.
- Veri analiz aracını, pandas DataFrame'i kullanarak verileri analiz edin ve sonucu yazdırın.
Seçenek I: Standart Format
Herhangi bir dosyayı CSV gibi belirli bir veri biçimiyle biçimlendirmenin standart yöntemi burada açıklanmıştır.
- Dosyayı veri değerleriyle birlikte yerel olarak PC'nize kaydedin. Örneğin, data.txt dosyasını adlandırabilirsiniz.
- Dosyayı belirli bir adla pandalarda içe aktarın ve verileri başka bir değişkene aktarın. Örneğin, dilin pandaları verilen kodda pd ismine aktarılır.
- İçe aktarma, girdi dosyasının adının, işlevin ve girdi dosyası biçiminin ayrıntısıyla birlikte eksiksiz bir kod içermelidir.
Not: Burada res adlı değişken, pd'ye aktarılan pandaları kullanarak data.txt dosyasındaki verilerin okuma işlevini gerçekleştirmek için kullanılır. Giriş metninin veri formatı, CSV formatında belirtilir.
- Adlandırılmış dosya türünü arayın ve yazdırılan sonuçtaki ayrıştırılmış metni analiz edin. Örneğin, komut satırının yürütülmesinden sonraki res komutu, ayrıştırılmış metnin yazdırılmasına yardımcı olacaktır.
Yukarıda açıklanan işlem için örnek bir kod aşağıda verilmiştir ve metnin nasıl ayrıştırılacağını anlamada yardımcı olacaktır.
pandaları pd olarak içe aktar
res = pd.read_csv('data.txt')
resBu durumda, data.txt dosyasına [1,2,3] gibi veri değerlerini girerseniz, ayrıştırılır ve 1 2 3 olarak görüntülenir.
Seçenek II: Dize Yöntemi
Koda verilen metin yalnızca dizeler veya alfa karakterler içeriyorsa, metni ayırmak ve ayrıştırmak için dizedeki virgül, boşluk vb. özel karakterler kullanılabilir. İşlem, yaygın dahili dize işlemlerine benzer. Ayrıştırma hatasını nasıl düzelteceğinizi bulmak için, aşağıda açıklanan bu seçeneği kullanarak metni ayrıştırma işlemini izlemeniz gerekir.
- Veriler dizeden çıkarılır ve metni ayıran tüm özel karakterler not edilir.
Örneğin, aşağıda verilen kodda my_string dizisindeki ' , ' ve ' : ' olan özel karakterler tanımlanmıştır. Bu işlem, x ayrıştırma metninde hata olmaması için dikkatli bir şekilde yapılmalıdır.
- Dizedeki metin, değerlere ve özel karakterlerin konumuna göre ayrı ayrı bölünür.
Örneğin, dize, split komutu kullanılarak tanımlanan özel karakterlere dayalı olarak metin veri değerlerine bölünür.
- Dizenin veri değerleri, ayrıştırılmış metin olarak tek başına yazdırılır. Burada print ifadesi, metnin ayrıştırılmış veri değerini yazdırmak için kullanılır.
Yukarıda açıklanan işlem için örnek kod aşağıda verilmiştir.
my_string = 'İsimler: Teknoloji, bilgisayar'
sfinal = my_string.split(':')[1].split(',')] içindeki ad için [name.strip()]
print(“İsimler: {}”.format(son))Bu durumda, ayrıştırılan dizenin sonucu aşağıda gösterildiği gibi görüntülenecektir.
İsimler: ['Teknik', 'bilgisayar']
Daha iyi netlik elde etmek ve dize metnini kullanırken metnin nasıl ayrıştırılacağını bilmek için bir for döngüsü kullanılır ve kod aşağıdaki gibi değiştirilir.
my_string = 'İsimler: Teknoloji, bilgisayar'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [isim.strip() s3'teki isim için]
idx için, numaralandırmadaki öğe ([s1, s2, s3, s4]):
print(“Adım {}: {}”.format(idx, item)) 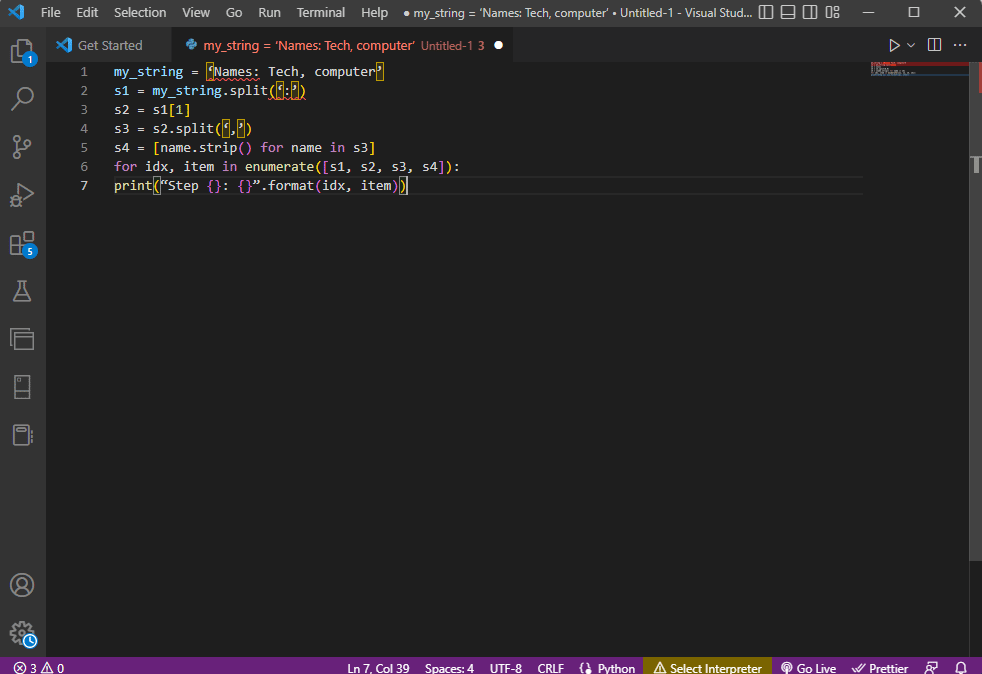
Bu adımların her biri için ayrıştırılan metnin sonucu aşağıda verildiği gibi görüntülenir. Adım 0'da dizenin özel karakter : temelinde ayrıldığını ve sonraki adımlarda karaktere göre metin veri değerlerinin ayrıldığını not edebilirsiniz.
Adım 0: ['Adlar', 'Teknik, bilgisayar'] Adım 1: Teknoloji, bilgisayar 2. Adım: ['Teknik', 'bilgisayar'] 3. Adım: ['Teknik', 'bilgisayar']
Seçenek III: Karmaşık Dosyayı Ayrıştırma
Çoğu durumda, ayrıştırılması gereken dosya verileri, değişen veri türleri ve veri değerleri içerir. Bu durumda, daha önce açıklanan yöntemleri kullanarak dosyayı ayrıştırmak zor olabilir.
Dosyadaki karmaşık verileri ayrıştırmanın özellikleri, veri değerlerinin tablo biçiminde görüntülenmesini sağlamaktır.
- Değerlerin Başlığı veya Meta Verileri dosyanın en üstünde yazdırılır,
- Değişkenler ve alanlar çıktıda tablo şeklinde yazdırılır ve
- Veri değerleri bir bileşik anahtar oluşturur.
Bu yöntemle metnin nasıl ayrıştırılacağını öğrenmeye başlamadan önce, birkaç temel kavramı öğrenmek gerekir. Veri değerlerinin ayrıştırılması, normal ifadelere veya Regex'e göre yapılır.
Normal İfade Kalıpları
Ayrıştırma hatasını nasıl düzelteceğinizi bilmek için ifadelerdeki normal ifade kalıplarının doğru olduğundan emin olmalısınız. Dizelerin veri değerlerini ayrıştıracak kod, bu bölümde aşağıda listelenen genel Regex kalıplarını içerecektir.
- '\d' : dizedeki ondalık basamakla eşleşir,
- '\s' : boşluk karakteriyle eşleşir,
- '\w' : alfasayısal karakterle eşleşir,
- '+' veya '*' : dizelerdeki bir veya daha fazla karakteri eşleştirerek açgözlü bir eşleşme gerçekleştirir,
- 'a-z' : metin veri değerlerindeki küçük harf gruplarıyla eşleşir,
- 'A-Z' veya 'a-z' : dizenin büyük ve küçük harf gruplarıyla eşleşir ve
- '0-9' : sayısal değerlerle eşleşir.
Düzenli ifadeler
Normal ifade modülleri, Python dilinde panda paketinin önemli bir parçasıdır ve yanlış bir yeniden, ayrıştırma metninde bir hataya neden olabilir x. İfadedeki dize modelini bulmak için Python'un içine yerleştirilmiş küçük bir dildir. Normal İfadeler veya Normal İfade, özel sözdizimine sahip dizelerdir. Kullanıcının, dizilerdeki değerlere göre diğer dizilerdeki kalıpları eşleştirmesini sağlar.
Regex, veri türüne ve 'String = (.*)\n gibi dizedeki ifadenin gereksinimine göre oluşturulur. Normal ifade, her ifadede kalıptan önce kullanılır. Normal ifadelerde kullanılan semboller aşağıda listelenmiştir ve metnin nasıl ayrıştırılacağını bilmeye yardımcı olacaktır.
- . : verilerden herhangi bir karakter almak için,
- * : önceki ifadeden sıfır veya daha fazla veri kullanın,
- (.*) : normal ifadenin bir kısmını parantez içinde gruplamak için,
- \n : Kodda satırın sonunda yeni bir satır karakteri oluşturun,
- \d : 0 ila 9 aralığında kısa bir integral değeri oluşturun,
- + : önceki ifadeden bir veya daha fazla veri kullanın ve
- | : mantıksal bir ifade oluşturun; veya ifadeleri için kullanılır.
Normal İfade Nesneleri
RegexObject, derleme işlevi için bir dönüş değeridir ve ifade eşleşme değeriyle eşleşirse MatchObject döndürmek için kullanılır.
1. MatchObject
MatchObject'in Boole değeri her zaman True olduğundan, nesnedeki pozitif eşleşmeleri tanımlamak için bir if ifadesi kullanabilirsiniz. if ifadesinin kullanılması durumunda, ifadedeki nesnenin eşleşmesini bulmak için indeksin başvurduğu grup kullanılır.
- group() bir veya daha fazla eşleşme alt grubunu döndürür,
- group(0) tüm eşleşmeyi döndürür,
- group(1) ilk parantez içindeki alt grubu döndürür ve
- Birden fazla gruba atıfta bulunurken, python'a özgü bir uzantı kullanmalıyız. Bu uzantı, eşleşmenin bulunması gereken grubun adını belirtmek için kullanılır. Spesifik uzantı, parantez içindeki grup içinde sağlanır. Örneğin, (?P<group1>regex1) ifadesi, group1 adlı belirli bir gruba atıfta bulunur ve normal ifade olan regex1'deki eşleşmeyi kontrol eder. Ayrıştırma hatasını nasıl düzelteceğinizi öğrenmek için grubun doğru işaretlenip işaretlenmediğini kontrol etmeniz gerekir.
2. MatchObject Yöntemleri
Metnin nasıl ayrıştırılacağını bulurken MatchObject'in aşağıda listelendiği gibi iki temel yöntemi olduğunu bilmek önemlidir. Belirtilen ifadede MatchObject bulunursa, örneğini döndürür, yoksa None döndürür.
- Match(string) yöntemi, normal ifadenin başlangıcındaki dizenin eşleşmelerini bulmak için kullanılır ve
- search(string) yöntemi, normal ifadede bir eşleşmenin yerini bulmak için dizeyi taramak için kullanılır.
Normal İfade İşlevleri
Regex İşlevleri, sağlanan veri değerleri kümesinden kullanıcı tarafından belirtilen belirli bir işlevi gerçekleştirmek için kullanılan kod satırlarıdır.
Not: Fonksiyonları yazmak için, x ayrıştırma metninde hatayı önlemek için normal ifadeler için ham dizeler kullanılır. Bu, ifadedeki her kalıptan önce r alt indisi eklenerek yapılır.
İfadelerde kullanılan ortak işlevler aşağıda açıklanmıştır.
1. yeniden bul()
Bu işlev, bir eşleşme bulunursa dizedeki tüm kalıpları döndürür ve eşleşme bulunamazsa boş bir liste döndürür. Örneğin, string = re.findall('[aeiou]', regex_filename) işlevi, dosya adındaki sesli harf oluşumunu bulmak için kullanılır.
2. yeniden.split()
Bu işlev, boşluk gibi belirtilen bir karakterle eşleşme olması durumunda dizeyi bölmek için kullanılır. Eşleşme bulunamazsa boş bir dize döndürür.
3. re.sub()
İşlev, eşleşen metni verilen değiştirme değişkeninin içeriğiyle değiştirir. Diğer işlevlerin aksine, desen bulunamazsa orijinal dize döndürülür.
4. yeniden araştırma()
Metnin nasıl ayrıştırılacağını öğrenmeye yardımcı olacak temel işlevlerden biri arama işlevidir. Dizedeki kalıbı aramaya ve eşleşme nesnesini döndürmeye yardımcı olur. Arama eşleşmeyi belirlemede başarısız olursa, hiçbir değer döndürülmez.
5. yeniden derleme(desen)
Bu işlev, daha önce tartışılan bir RegexObject içinde düzenli ifade kalıplarını derlemek için kullanılır.
Diğer gereklilikler
Listelenen gereksinimler, gelişmiş programcılar tarafından veri analizinde kullanılan ek bir özelliktir.
- Normal ifadeyi görselleştirmek için regexper kullanılır ve
- Normal ifadeyi test etmek için regex101 kullanılır.
Ayrıca Okuyun: Windows 10'da NumPy Nasıl Kurulur

Metni Ayrıştırma Süreci
Bu karmaşık seçenekteki metni ayrıştırma yöntemi aşağıda verildiği gibi açıklanmıştır.
- En önemli adım, dosyanın içeriğini okuyarak giriş biçimini anlamaktır. Örneğin, with open ve read() işlevleri, örnek adlı dosyanın içeriğini açmak ve okumak için kullanılır. Örnek dosya, file.txt dosyasındaki içeriğe sahiptir; ayrıştırma hatasının nasıl düzeltileceğini öğrenmek için dosyanın tamamen okunması gerekir.
- Değerlerin meta verilerini bulmak için verileri manuel olarak analiz etmek için dosyanın içeriği yazdırılır. Burada, örnek dosyanın içeriğini yazdırmak için print() işlevi kullanılır.
- Metni ayrıştırmak için gerekli veri paketleri koda aktarılır ve daha fazla kodlama için sınıfa bir ad verilir. Burada normal ifadeler ve pandalar içe aktarılır.
- Kod için gereken düzenli ifadeler, dosyada normal ifade kalıbı ve normal ifade işlevi dahil edilerek tanımlanır. Bu, metin nesnesinin veya tümcenin veri analizi için kodu almasına izin verir.
- Metnin nasıl ayrıştırılacağını öğrenmek için burada verilen örnek koda bakabilirsiniz. compile() işlevi, dosyaadı dosyasının stringname1 grubundan dizeyi derlemek için kullanılır. Normal ifadedeki eşleşmeleri kontrol etme işlevi, ief_parse_line(line) komutu tarafından kullanılır,
- Kodun satır ayrıştırıcısı, tanımlanan işlevin belirtilen işlevdeki tüm normal ifade eşleşmelerini kontrol ettiği def_parse_file(filepath) kullanılarak yazılır. Burada, normal ifade arama() yöntemi, dosya dosya adındaki rx anahtarını arar ve eşleşen ilk normal ifadenin anahtarını ve eşleşmesini döndürür. Adımla ilgili herhangi bir sorun, x ayrıştırma metninde bir hataya neden olabilir.
- Sonraki adım, def_parse_file(filepath) olan dosya ayrıştırıcı işlevini kullanarak bir Dosya Ayrıştırıcı yazmaktır. Kodun verilerini toplamak için data = [] olarak boş bir liste oluşturulur, eşleşme her satırda match = _parse_line(line) ile kontrol edilir ve veri türüne göre tam değer verisi döndürülür.
- Tablonun numarasını ve değerini çıkarmak için line.strip().split(',') komutu kullanılır. satır{} komutu, veri satırı ile bir sözlük oluşturmak için kullanılır. data.append(row) komutu, verileri anlamak ve tablo biçiminde ayrıştırmak için kullanılır.
data = pd.DataFrame(data) komutu, dict değerlerinden bir panda DataFrame oluşturmak için kullanılır. Alternatif olarak, aşağıda belirtildiği gibi ilgili amaç için aşağıdaki komutları kullanabilirsiniz.
- Tablonun dizinini ayarlamak için data.set_index(['string', 'integer'], inplace=True) .
- nans'ı birleştirmek ve kaldırmak için data = data.groupby(level=data.index.names).first() .
- puanı kayan noktadan tamsayı değerine yükseltmek için data = data.apply(pd.to_numeric, error='ignore')
Metnin nasıl ayrıştırılacağını bilmek için son adım, değerleri bir değişken veriye atayarak ve print(data) komutunu kullanarak yazdırarak if ifadesini kullanarak ayrıştırıcıyı test etmektir.
Yukarıdaki açıklama için örnek kod burada verilmiştir.
örnek olarak open('file.txt') ile:
sample_contents = sample.read()
yazdır(örnek_içerikler)
yeniden içe aktar
pandaları pd olarak içe aktar
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line(satır):
anahtar için, rx_filename.items() içindeki rx:
eşleşme = rx.search(satır)
eşleşirse:
dönüş anahtarı, eşleşme
dönüş Yok, Yok
def parse_file(dosya yolu):
veri = []
open(filepath, 'r') ile file_object olarak:
satır = file_object.readline()
sıra satırı:
anahtar, eşleşme = _parse_line(satır)
if anahtar == 'string1':
string = match.group('string1')
tamsayı = int(string1)
value_type = match.group('string1')
satır = file_object.readline()
while line.strip():
sayı, değer = line.strip().split(',')
değer = değer.şerit()
satır = {
'Veri1': dize1,
'Veri2': sayı,
değer_türü: değer
}
data.append(satır)
satır = file_object.readline()
satır = file_object.readline()
veri = pd.DataFrame(veri)
veri döndürme
eğer _ _name_ _ = = '_ _main_ _':
dosyayolu = 'örnek.txt'
veri = ayrıştırma(dosya yolu)
yazdır(veri) 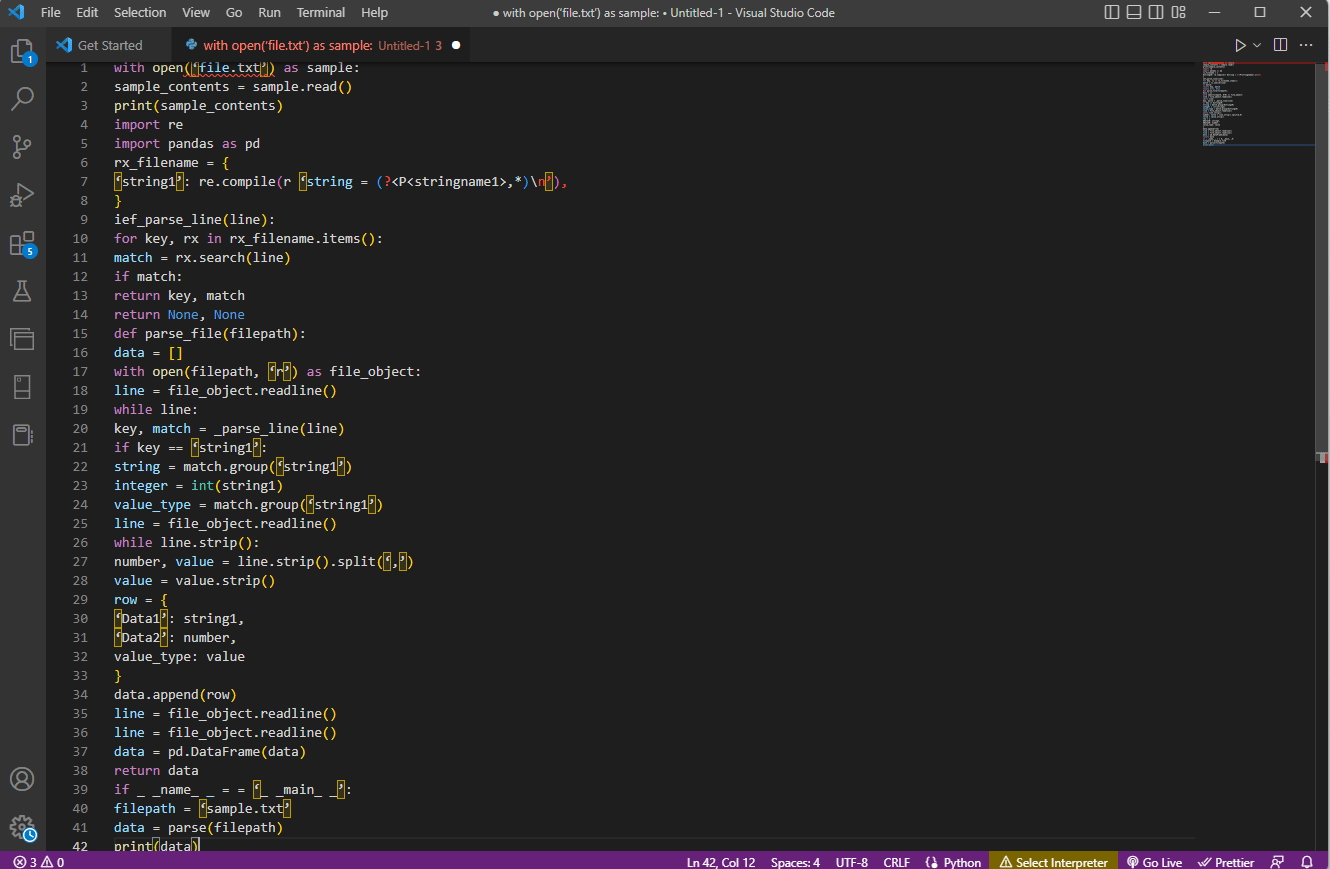
Yöntem 2: Kelime Belirteçleştirme Yoluyla
Bir metni veya derlemi belirli kurallara dayalı olarak jetonlara veya daha küçük parçalara dönüştürme işlemine Tokenization denir. Ayrıştırma hatasını nasıl düzelteceğinizi öğrenmek için koddaki word tokenization komutlarını analiz etmek önemlidir. Normal ifadeye benzer şekilde, bu yöntemde kendi kuralları oluşturulabilir ve konuşma bölümlerinin eşlenmesi gibi metin ön işleme görevlerinde yardımcı olur. Ayrıca ortak kelimeleri bulma ve eşleştirme, metin temizleme, verileri duygu analizi gibi ileri metin analitiği tekniklerine hazırlama gibi faaliyetler de bu yöntemde gerçekleştirilir. Belirteçleştirme yanlışsa, ayrıştırma metninde x hatası oluşabilir.
Ntlk Kitaplığı
İşlem, birçok NLP işini gerçekleştirmek için zengin bir işlevler kümesine sahip olan nltk adlı popüler dil araç seti kitaplığının yardımını alır. Bunlar, Pip veya Pip Kurulum Paketleri aracılığıyla indirilebilir. Metnin nasıl ayrıştırılacağını öğrenmek için, varsayılan olarak kitaplığı içeren Anaconda dağıtımının temel paketini kullanabilirsiniz.
Tokenleştirme Biçimleri
Bu yöntemin yaygın biçimleri, kelime tokenizasyonu ve cümle tokenizasyonudur. Kelime seviyesindeki belirteç sayesinde, birincisi bir kelimeyi yalnızca bir kez yazdırırken, ikincisi kelimeyi cümle seviyesinde yazdırır.
Metni Ayrıştırma Süreci
- ntlk araç takımı kitaplığı içe aktarılır ve simgeleştirme formları kitaplıktan içe aktarılır.
- Bir dize verilir ve simgeleştirmeyi gerçekleştirecek komutlar verilir.
- Dize yazdırılırken, çıktı bilgisayar kelimesi olacaktır.
- Word tokenization veya word_tokenize() durumunda, cümledeki her bir kelime '' içinde ayrı ayrı yazdırılır ve virgülle ayrılır. Komutun çıktısı 'bilgisayar', 'is', 'the', 'word', ' olacaktır.'
- Cümle belirleme veya sent_tokenize() durumunda, bireysel cümleler '' içine yerleştirilir ve kelime tekrarına izin verilir. Komutun çıktısı 'bilgisayar kelimedir' olacaktır.
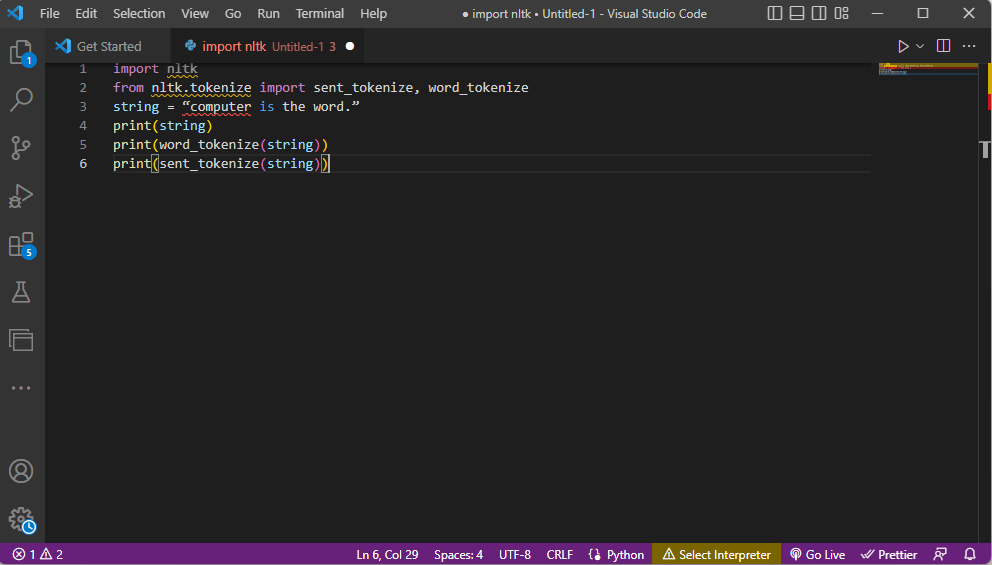
Yukarıdaki tokenizasyon adımlarını açıklayan kod burada verilmiştir.
nltk'yi içe aktar nltk.tokenize'den import send_tokenize, word_tokenize string = “bilgisayar kelimedir.” yazdır(dize) print(word_tokenize(string)) print(sent_tokenize(string))
Ayrıca Okuyun: javascript:void(0) Hatası Nasıl Düzeltilir
Yöntem 3: DocParser Sınıfı aracılığıyla
DataFrame Sınıfına benzer şekilde, DocParser Sınıfı, koddaki metni ayrıştırmak için kullanılabilir. Sınıf, dosya yolu ile ayrıştırma işlevini çağırmanıza izin verir.
Metni Ayrıştırma Süreci
DocParser Sınıfını kullanarak metnin nasıl ayrıştırılacağını öğrenmek için aşağıda verilen talimatları izleyin.
- get_format(filename) işlevi, dosya uzantısını çıkarmak, onu işlev için ayarlanmış bir değişkene döndürmek ve bir sonraki işleve iletmek için kullanılır. Örneğin, p1 = get_format(filename) , filename dosya uzantısını çıkarır, onu p1 değişkenine ayarlar ve bir sonraki işleve iletir.
- if-elif-else deyimleri ve işlevleri kullanılarak diğer işlevlerle mantıksal bir yapı oluşturulur.
- Dosya uzantısı geçerliyse ve yapı mantıklıysa, dosya yolundaki verileri ayrıştırmak ve dize nesnesini kullanıcıya döndürmek için get_parser işlevi kullanılır.
Not: Ayrıştırma hatasının nasıl düzeltileceğini bilmek için bu işlevin doğru şekilde uygulanması gerekir.
- Veri değerlerinin ayrıştırılması dosyanın dosya uzantısı ile yapılır. Parse_txt veya parse_docx olan sınıfın somut uygulaması, verilen dosya türünün parçalarından dize nesneleri oluşturmak için kullanılır.
- Parse_pdf , parse_html ve parse_pptx gibi diğer okunabilir uzantıların dosyaları için ayrıştırma yapılabilir.
- Veri değerleri ve arayüz, import ifadeleri ile uygulamalara alınabilir ve bir DocParser nesnesini somutlaştırabilir. Bu, parse_file.py gibi Python dilindeki dosyaları ayrıştırarak yapılabilir. Bu işlem, x ayrıştırma metninde hata olmaması için dikkatli bir şekilde yapılmalıdır.
Yöntem 4: Metni Ayrıştırma Aracı Aracılığıyla
Metni Ayrıştırma aracı, değişkenlerden belirli verileri çıkarmak ve bunları diğer değişkenlerle eşleştirmek için kullanılır. Bu, bir görevde kullanılan diğer araçlardan bağımsızdır ve değişkenleri tüketmek ve çıktı almak için BPA Platformu aracı kullanılır. Metni Ayrıştırma Aracına çevrimiçi erişmek için burada verilen bağlantıyı kullanın ve metnin nasıl ayrıştırılacağı konusunda daha önce verilen yanıtları kullanın.
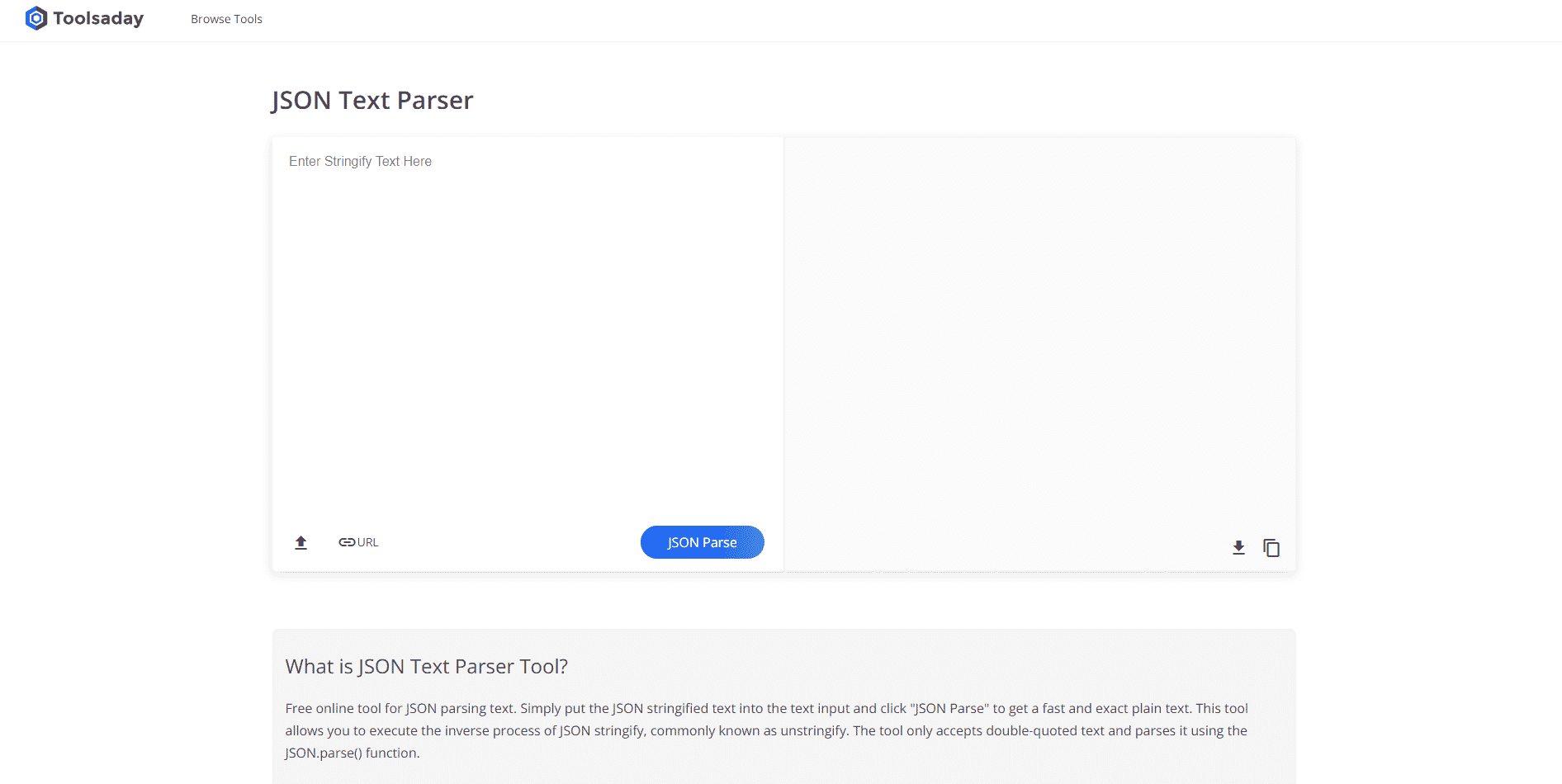
Yöntem 5: TextFieldParser aracılığıyla (Visual Basic)
TextFieldParser, yapılandırılmış ve sınırlandırılmış çok büyük dosyaları ayrıştırmak ve işlemek için nesneleri kullandı. Günlük dosyaları veya eski veritabanı bilgileri gibi metnin genişliği ve sütunu bu yöntemde kullanılabilir. Ayrıştırma yöntemi, kodu bir metin dosyası üzerinde yinelemeye benzer ve temel olarak dize işleme yöntemlerine benzer metin alanlarını çıkarmak için kullanılır. Bu, virgül veya sekme alanı gibi tanımlanmış sınırlayıcıyı kullanarak sınırlandırılmış dizeleri ve çeşitli genişlikteki alanları belirtmek için yapılır.
Metni Ayrıştırma İşlevleri
Metni bu yöntemde ayrıştırmak için aşağıdaki işlevler kullanılabilir.
- Bir sınırlayıcı tanımlamak için SetDelimiter'lar kullanılır. Örneğin, sınırlayıcı olarak sekme alanını ayarlamak için testReader.SetDelimiters (vbTab) komutu kullanılır.
- Bir alan genişliğini pozitif bir tamsayı değerine, metin dosyalarının sabit bir alan genişliğine ayarlamak için testReader.SetFieldWidths (integer) komutunu kullanabilirsiniz.
- Metnin alan türünü test etmek için aşağıdaki komutu kullanabilirsiniz testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth .
MatchObject Bulma Yöntemleri
Kodda veya ayrıştırılmış metinde MatchObject'i bulmanın iki temel yöntemi vardır.
- İlk yöntem, formatı tanımlamak ve ReadFields yöntemini kullanarak dosyada döngü yapmaktır. Bu yöntem, kodun her satırının işlenmesine yardımcı olur.
- PeekChars yöntemi, her alanı okumadan önce ayrı ayrı kontrol etmek, birden çok format tanımlamak ve tepki vermek için kullanılır.
Her iki durumda da, ayrıştırma gerçekleştirilirken veya metnin nasıl ayrıştırılacağını bulurken bir alan belirtilen formatla eşleşmezse, bir MalformedLineException istisnası döndürülür.
Profesyonel İpucu: MS Excel Üzerinden Metin Nasıl Ayrıştırılır
Metni ayrıştırmanın son ve basit bir yöntemi olarak, sekmeyle ayrılmış ve virgülle ayrılmış dosyalar oluşturmak için ayrıştırıcı olarak MS Excel uygulamasını kullanabilirsiniz. Bu, ayrıştırılmış sonucunuzla çapraz kontrol yapmanıza ve ayrıştırma hatasının nasıl düzeltileceğini bulmanıza yardımcı olur.
1. Kaynak dosyadaki veri değerlerini seçin ve dosyayı kopyalamak için Ctrl + C tuşlarına birlikte basın.
2. Windows arama çubuğunu kullanarak Excel uygulamasını açın.
3. Kopyalanan metni yapıştırmak için A1 hücresine tıklayın ve Ctrl + V tuşlarına aynı anda basın.
4. A1 hücresini seçin, Veri sekmesine gidin ve Veri Araçları bölümünde Metni sütunlara dönüştür seçeneğine tıklayın.
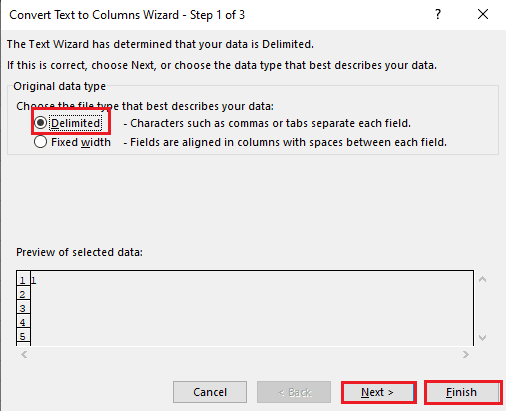
5A. Ayırıcı olarak virgül veya sekme alanı kullanılıyorsa Sınırlandırılmış seçeneğini seçin ve İleri ve Bitir düğmelerine tıklayın.
5B. Sabit genişlik seçeneğini seçin, ayırıcı için bir değer atayın ve İleri ve Bitir düğmelerine tıklayın.
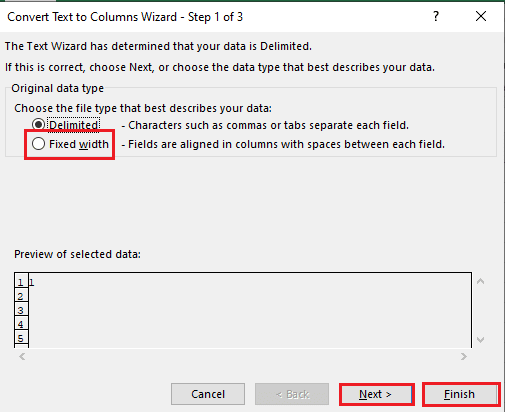
Ayrıca Okuyun: Excel Sütunu Taşıma Hatası Nasıl Onarılır
Ayrıştırma Hatası Nasıl Onarılır
Ayrıştırma metninde x hatası Android cihazlarda şu şekilde oluşabilir: Ayrıştırma Hatası: Paket ayrıştırılırken bir sorun oluştu. Bu genellikle, uygulama Google Play Store'dan yüklenemediğinde veya bir üçüncü taraf uygulaması çalıştırıldığında ortaya çıkar.
Karakter vektörleri listesi döngülüyse ve diğer işlevler veri değerlerini hesaplamak için doğrusal bir model oluşturuyorsa x hata metni oluşabilir. Hata mesajı, Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^.
Hatayı düzeltmenin nedenlerini ve yöntemlerini öğrenmek için Android'de ayrıştırma hatasının nasıl düzeltileceğine ilişkin makaleyi okuyabilirsiniz.
Kılavuzdaki çözümlerin dışında aşağıdaki düzeltmeleri deneyebilirsiniz.
- .apk dosyasını yeniden indirmek veya dosyanın adını geri yüklemek.
- Uzman düzeyinde programlama becerileriniz varsa, Androidmanifest.xml dosyasındaki değişiklikleri geri yükleme.
Önerilen:
- Başkasının Facebook Hesabı Nasıl Silinir?
- Etik Hacker Olmak İçin Gerekli En İyi 10 Beceri
- Kod ve Metni Paylaşmak İçin En İyi 21 Pastebin Alternatifi
- Düzeltme Komutu Hata Kodu 1 ile Başarısız Oldu Python Yumurtası Bilgisi
Makale, metnin nasıl ayrıştırılacağını öğretmeye ve ayrıştırma hatasının nasıl düzeltileceğini öğrenmeye yardımcı olur. x ayrıştırma metnindeki hatayı hangi yöntemin düzeltmeye yardımcı olduğunu ve hangi ayrıştırma yönteminin tercih edildiğini bize bildirin. Lütfen önerilerinizi ve sorularınızı aşağıdaki yorumlar bölümünde paylaşın.