
Tesseract Kullanarak Linux Komut Satırından OCR Nasıl Yapılır
Yayınlanan: 2022-01-29
Tesseract OCR motorunu kullanarak Linux komut satırındaki görüntülerden metin ayıklayabilirsiniz. Hızlı, doğru ve yaklaşık 100 dilde çalışıyor. İşte nasıl kullanılacağı.
Optik karakter tanıma
Optik karakter tanıma (OCR), bir görüntüdeki sözcüklere bakma ve bu sözcükleri bulma ve ardından bunları düzenlenebilir metin olarak çıkarma yeteneğidir. İnsanlar için bu basit görevi yapmak bilgisayarlar için çok zordur. İlk çabalar en hafif tabirle hantaldı. Yazı tipi veya boyut OCR yazılımının beğenisine uygun değilse, bilgisayarlar genellikle karıştırıldı.
Bununla birlikte, bu alandaki öncülere hâlâ büyük saygı duyuluyordu. Bir belgenin elektronik kopyasını kaybettiyseniz ancak hala basılı bir sürümü varsa, OCR elektronik, düzenlenebilir bir sürümü yeniden oluşturabilir. Sonuçlar yüzde 100 doğru olmasa bile, bu yine de büyük bir zaman tasarrufu sağladı.
Bazı manuel toparlamalarla belgenizi geri alırsınız. İnsanlar, bir OCR paketinin karşı karşıya olduğu görevin karmaşıklığını anladıkları için yaptığı hataları affediyorlardı. Ayrıca, tüm belgeyi yeniden yazmaktan daha iyiydi.
O zamandan beri işler önemli ölçüde iyileşti. Hewlett Packard tarafından yazılan Tesseract OCR uygulaması, 1980'lerde ticari bir uygulama olarak başladı. 2005 yılında açık kaynaklıydı ve şimdi Google tarafından destekleniyor. Çoklu dil özelliklerine sahiptir, mevcut en doğru OCR sistemlerinden biri olarak kabul edilir ve ücretsiz olarak kullanabilirsiniz.
Tesseract OCR'yi Yükleme
Tesseract OCR'yi Ubuntu'ya kurmak için şu komutu kullanın:
sudo apt-get kurulum tesseract-ocr

Fedora'da komut şudur:
sudo dnf tesseract'ı kurun

Manjaro'da şunları yazmanız gerekir:
sudo pacman -Syu tesseract

Tesseract OCR'yi kullanma
Tesseract OCR için bir dizi zorluk oluşturacağız. Metin içeren ilk görselimiz, Genel Veri Koruma Yönetmeliği'nin 63. gerekçesinden bir alıntıdır. Bakalım OCR bunu okuyabilecek mi (ve uyanık kal).

Zor bir görüntü çünkü her cümle, yasama belgelerinde tipik olan, soluk bir üst simge numarasıyla başlıyor.
tesseract komutuna aşağıdakiler dahil bazı bilgiler vermemiz gerekiyor:
- İşlemesini istediğimiz görüntü dosyasının adı.
- Ayıklanan metni tutmak için oluşturacağı metin dosyasının adı. Dosya uzantısını sağlamak zorunda değiliz (her zaman .txt olacaktır). Aynı ada sahip bir dosya zaten varsa, üzerine yazılacaktır.
- Görüntünün nokta/inç (dpi) çözünürlüğünün ne olduğunu
tesseractsöylemek için--dpiseçeneğini kullanabiliriz. Bir dpi değeri sağlamazsak,tesseractonu bulmaya çalışacaktır.
Resim dosyamızın adı “resital-63.png” olup çözünürlüğü 150 dpi'dir. Ondan “resital.txt” adında bir metin dosyası oluşturacağız.
Komutumuz şöyle görünür:
tesseract resitali-63.png resitali --dpi 150

Sonuçlar çok iyi. Tek sorun üst simgeler - doğru okunamayacak kadar soluktular. İyi sonuçlar elde etmek için kaliteli bir görüntü çok önemlidir.

tesseract üst simge sayılarını tırnak işaretleri (“) ve derece simgeleri (°) olarak yorumladı, ancak asıl metin mükemmel bir şekilde çıkarıldı (resmin sağ tarafının buraya sığması için kırpılması gerekiyordu).
Son karakter, satır başı olan 0x0C onaltılı değerine sahip bir bayttır.
Aşağıda, farklı boyutlarda ve hem kalın hem de italik olarak metin içeren başka bir resim bulunmaktadır.

Bu dosyanın adı “bold-italic.png”dir. “bold.txt” adında bir metin dosyası oluşturmak istiyoruz, bu yüzden komutumuz:
tesseract bold-italic.png bold --dpi 150

Bu herhangi bir sorun yaratmadı ve metin mükemmel bir şekilde çıkarıldı.

Farklı Diller Kullanmak
Tesseract OCR yaklaşık 100 dili destekler. Bir dili kullanmak için önce onu yüklemelisiniz. Listede kullanmak istediğiniz dili bulduğunuzda kısaltmasını not edin. Galce için destek yükleyeceğiz. Kısaltması, Galce anlamına gelen "Cymru"nun kısaltması olan "cym"dir.
Kurulum paketi, dil kısaltması sonuna etiketlenmiş olarak “tesseract-ocr-” olarak adlandırılır. Galce dil dosyasını Ubuntu'ya kurmak için şunları kullanacağız:
sudo apt-get kurulum tesseract-ocr-cym


Yazılı görsel aşağıdadır. Galler milli marşının ilk mısrasıdır.

Bakalım Tesseract OCR mücadeleye hazır mı? tesseract çalışmak istediğimiz dili bilmesini sağlamak için -l (dil) seçeneğini kullanacağız:
tesseract hen-wlad-fy-nhadau.png marşı -l cym --dpi 150

tesseract , aşağıdaki metinde gösterildiği gibi mükemmel bir şekilde başa çıkıyor. Da iawn , Tesseract OCR.

Belgeniz iki veya daha fazla dil içeriyorsa (örneğin, Galce-İngilizce sözlük gibi), tesseract başka bir dil eklemesini söylemek için bir artı işareti ( + ) kullanabilirsiniz, örneğin:
tesseract image.png metin dosyası -l eng+cym+fra
Tesseract OCR'yi PDF'lerle Kullanma
tesseract komutu, görüntü dosyalarıyla çalışmak üzere tasarlanmıştır, ancak PDF'leri okuyamaz. Ancak, bir PDF'den metin çıkarmanız gerekiyorsa, bir dizi görüntü oluşturmak için önce başka bir yardımcı program kullanabilirsiniz. Tek bir resim, PDF'nin tek bir sayfasını temsil edecektir.
İhtiyacınız olan pdftppm yardımcı programı, Linux bilgisayarınızda zaten kurulu olmalıdır. Örneğimiz için kullanacağımız PDF, Alan Turing'in yapay zeka üzerine çığır açan makalesinin bir kopyası, “Bilgisayar Makineleri ve Zeka”.

PNG dosyaları oluşturmak istediğimizi belirtmek için -png seçeneğini kullanıyoruz. PDF dosyamızın adı “turing.pdf”dir. Resim dosyalarımızı “turing-01.png”, “turing-02.png” vb. olarak adlandıracağız:
pdftoppm -png turing.pdf turing

Tek bir komut kullanarak her görüntü dosyasında tesseract çalıştırmak için bir for döngüsü kullanmamız gerekir. "Turing- nn .png" dosyalarımızın her biri için tesseract çalıştırırız ve görüntü dosyası adının bir parçası olarak "text-" artı "turing- nn " adlı bir metin dosyası oluştururuz:
i için turing-??.png; "$i" "text-$i" -l eng; tamamlamak;

Tüm metin dosyalarını tek bir dosyada birleştirmek için cat kullanabiliriz:
cat text-turing* > tam.txt

Peki, nasıl oldu? Aşağıda göreceğiniz gibi çok iyi. Yine de ilk sayfa oldukça zor görünüyor. Farklı yazı stilleri ve boyutları ve dekorasyonu vardır. Ayrıca sayfanın sağ kenarında dikey bir "filigran" vardır.
Ancak, çıktı orijinaline yakındır. Açıkçası, biçimlendirme kayboldu, ancak metin doğru.
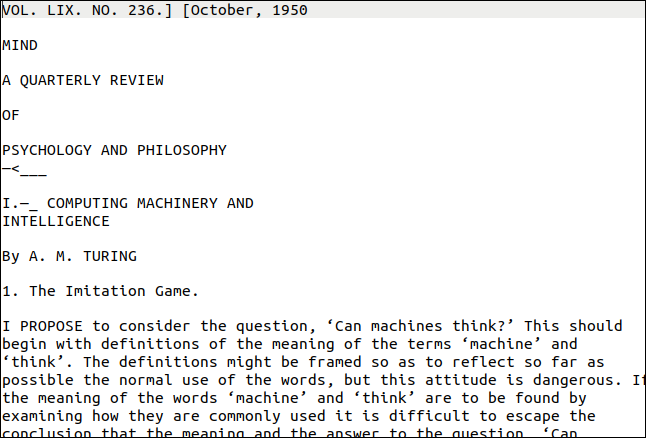
Dikey filigran, sayfanın alt kısmında anlamsız bir satır olarak yazılmıştır. Metin, tesseract tarafından doğru bir şekilde okunamayacak kadar küçüktü, ancak onu bulup silmek yeterince kolay olurdu. En kötü sonuç, her satırın sonunda başıboş karakterler olurdu.
Merakla, ikinci sayfadaki soru ve cevap listesinin başındaki tek harfler göz ardı edildi. PDF'den alınan bölüm aşağıda gösterilmiştir.

Aşağıda görebileceğiniz gibi, sorular kaldı, ancak her satırın başındaki “Q” ve “A” kayboldu.

Diyagramlar da doğru şekilde kopyalanmayacaktır. Aşağıda gösterileni Turing PDF'sinden çıkarmaya çalıştığımızda ne olduğuna bakalım.

Aşağıdaki sonucumuzda da görebileceğiniz gibi karakterler okunmuş ancak diyagramın formatı kaybolmuş.

Yine, tesseract , alt simgelerin küçük boyutuyla mücadele etti ve bunlar yanlış oluşturuldu.
Adil olmak gerekirse, yine de, yine de iyi bir sonuçtu. Basit metni çıkaramadık, ancak daha sonra, bu örnek bir zorluk teşkil ettiği için kasıtlı olarak seçildi.
İhtiyacınız Olduğunda İyi Bir Çözüm
OCR, günlük olarak kullanmanız gereken bir şey değildir. Ancak ihtiyaç doğduğunda, emrinizde en iyi OCR motorlarından birine sahip olduğunuzu bilmek güzel.