
การประมวลผลภาษาธรรมชาติคืออะไรและทำงานอย่างไร
เผยแพร่แล้ว: 2022-01-29
การประมวลผลภาษาธรรมชาติทำให้คอมพิวเตอร์สามารถประมวลผลสิ่งที่เราพูดเป็นคำสั่งที่สามารถดำเนินการได้ ค้นหาข้อมูลพื้นฐานเกี่ยวกับวิธีการทำงาน และวิธีการใช้เพื่อปรับปรุงชีวิตของเรา
การประมวลผลภาษาธรรมชาติคืออะไร?
ไม่ว่าจะเป็น Alexa, Siri, Google Assistant, Bixby หรือ Cortana ทุกคนที่มีสมาร์ทโฟนหรือลำโพงอัจฉริยะมีผู้ช่วยที่สั่งงานด้วยเสียงในปัจจุบัน ทุกๆ ปี ผู้ช่วยเสียงเหล่านี้ดูเหมือนจะสามารถจดจำและดำเนินการตามสิ่งที่เราบอกให้พวกเขาทำได้ดีขึ้น แต่คุณเคยสงสัยหรือไม่ว่าผู้ช่วยเหล่านี้ประมวลผลสิ่งที่เราพูด? พวกเขาสามารถทำได้ด้วยการประมวลผลภาษาธรรมชาติหรือ NLP
ในอดีต ซอฟต์แวร์ส่วนใหญ่สามารถตอบสนองต่อชุดคำสั่งเฉพาะที่กำหนดไว้เท่านั้น ไฟล์จะเปิดขึ้นเนื่องจากคุณคลิกเปิด มิฉะนั้นสเปรดชีตจะคำนวณสูตรตามสัญลักษณ์และชื่อสูตรบางอย่าง โปรแกรมสื่อสารโดยใช้ภาษาการเขียนโปรแกรมที่เข้ารหัสไว้และจะสร้างเอาต์พุตเมื่อได้รับอินพุตที่รู้จัก ในบริบทนี้ คำต่างๆ เป็นเหมือนชุดของคันโยกกลไกต่างๆ ที่ให้ผลลัพธ์ที่ต้องการเสมอ
ซึ่งตรงกันข้ามกับภาษามนุษย์ที่มีความซับซ้อน ไม่มีโครงสร้าง และมีความหมายมากมายตามโครงสร้างประโยค น้ำเสียง สำเนียง เวลา เครื่องหมายวรรคตอน และบริบท การประมวลผลภาษาธรรมชาติเป็นสาขาหนึ่งของปัญญาประดิษฐ์ที่พยายามเชื่อมช่องว่างระหว่างสิ่งที่เครื่องรับรู้ว่าเป็นข้อมูลป้อนเข้าและภาษามนุษย์ เพื่อให้เมื่อเราพูดหรือพิมพ์อย่างเป็นธรรมชาติ เครื่องจะสร้างเอาต์พุตตามที่เราพูด
ทำได้โดยใช้จุดข้อมูลจำนวนมากเพื่อให้ได้มาซึ่งความหมายจากองค์ประกอบต่างๆ ของภาษามนุษย์ นอกเหนือจากความหมายของคำจริง กระบวนการนี้เชื่อมโยงอย่างใกล้ชิดกับแนวคิดที่เรียกว่าการเรียนรู้ของเครื่อง ซึ่งช่วยให้คอมพิวเตอร์เรียนรู้เพิ่มเติมเมื่อได้รับข้อมูลมากขึ้น นั่นคือเหตุผลที่ว่าทำไมเครื่องประมวลผลภาษาธรรมชาติส่วนใหญ่ที่เราโต้ตอบด้วยมักจะดีขึ้นเมื่อเวลาผ่านไป
เพื่อให้แนวคิดนี้กระจ่างยิ่งขึ้น มาดูสองเทคนิคระดับบนสุดที่ใช้ใน NLP เพื่อประมวลผลภาษาและข้อมูล
ที่เกี่ยวข้อง: ปัญหากับ AI: เครื่องจักรกำลังเรียนรู้สิ่งต่าง ๆ แต่ไม่สามารถเข้าใจได้
Tokenization

Tokenization หมายถึงการแยกคำพูดออกเป็นคำหรือประโยค ข้อความแต่ละชิ้นเป็นโทเค็น และโทเค็นเหล่านี้จะแสดงขึ้นเมื่อคุณประมวลผลคำพูดของคุณ ฟังดูง่าย แต่ในทางปฏิบัติ เป็นกระบวนการที่ยุ่งยาก
สมมติว่าคุณกำลังใช้ซอฟต์แวร์แปลงข้อความเป็นคำพูด เช่น แป้นพิมพ์ของ Google เพื่อส่งข้อความถึงเพื่อน คุณต้องการส่งข้อความว่า "พบฉันที่สวนสาธารณะ" เมื่อโทรศัพท์ของคุณใช้การบันทึกนั้นและประมวลผลผ่านอัลกอริธึมการแปลงข้อความเป็นคำพูดของ Google จากนั้น Google จะต้องแยกสิ่งที่คุณเพิ่งพูดออกเป็นโทเค็น โทเค็นเหล่านี้จะเป็น "meet" "me" "at" "the" และ "park"

ผู้คนมีความยาวการหยุดระหว่างคำต่างกัน และภาษาอื่นๆ อาจมีการหยุดเสียงระหว่างคำได้ไม่มากนัก กระบวนการสร้างโทเค็นจะแตกต่างกันอย่างมากระหว่างภาษาและภาษาถิ่น
ต้นกำเนิดและเล็มมาไรเซชัน
Stemming และ lemmatization เกี่ยวข้องกับกระบวนการลบคำเพิ่มเติมหรือการเปลี่ยนแปลงของคำรากศัพท์ที่เครื่องสามารถจดจำได้ สิ่งนี้ทำเพื่อให้การตีความคำพูดสอดคล้องกันในคำต่างๆ ซึ่งทั้งหมดมีความหมายเหมือนกันในสิ่งเดียวกัน ซึ่งทำให้การประมวลผล NLP เร็วขึ้น
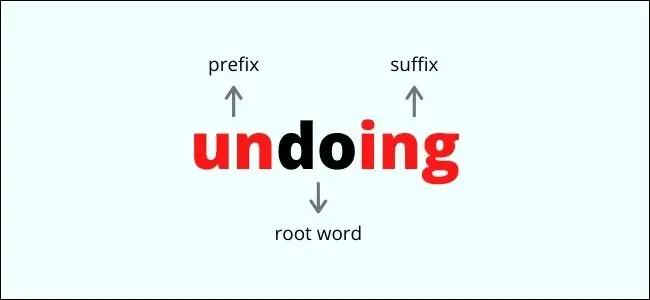
ต้นกำเนิดเป็นกระบวนการที่รวดเร็วอย่างคร่าวๆ ซึ่งเกี่ยวข้องกับการลบคำต่อท้ายออกจากคำรูท ซึ่งเป็นส่วนเพิ่มเติมของคำที่แนบมาก่อนหรือหลังรูท สิ่งนี้จะเปลี่ยนคำให้อยู่ในรูปแบบฐานที่ง่ายที่สุดโดยเพียงแค่ลบตัวอักษรออก ตัวอย่างเช่น:
- “เดิน” กลายเป็น “เดิน”
- “เร็ว” กลายเป็น “เร็ว”
- “ความรุนแรง” กลายเป็น “ความแตกแยก”
อย่างที่คุณเห็น การแยกตัวออกจากกันอาจส่งผลเสียต่อการเปลี่ยนความหมายของคำทั้งหมด "ความรุนแรง" และ "การตัด" ไม่ได้หมายถึงสิ่งเดียวกัน แต่คำต่อท้าย "ity" ถูกลบออกในกระบวนการหยุด
ในอีกทางหนึ่ง เล็มมาไลเซชันเป็นกระบวนการที่ซับซ้อนกว่าซึ่งเกี่ยวข้องกับการลดคำลงเป็นฐาน หรือที่เรียกว่า บทแทรก โดยคำนึงถึงบริบทของคำและวิธีการใช้คำในประโยค นอกจากนี้ยังเกี่ยวข้องกับการค้นหาคำศัพท์ในฐานข้อมูลของคำและบทแทรกตามลำดับ ตัวอย่างเช่น:
- “เป็น” กลายเป็น “เป็น”
- “ปฏิบัติการ” กลายเป็น “ปฏิบัติการ”
- “ความรุนแรง” กลายเป็น “รุนแรง”
ในตัวอย่างนี้ การจัดย่อให้เปลี่ยนคำว่า "ความรุนแรง" เป็น "รุนแรง" ซึ่งเป็นรูปแบบแทรกและคำรากศัพท์
กรณีการใช้งาน NLP และอนาคต
ตัวอย่างก่อนหน้านี้เริ่มที่จะขีดพื้นผิวของการประมวลผลภาษาธรรมชาติ ครอบคลุมแนวปฏิบัติและสถานการณ์การใช้งานที่หลากหลาย ซึ่งเราใช้ในชีวิตประจำวันของเรา ต่อไปนี้คือตัวอย่างบางส่วนที่ใช้ NLP ในปัจจุบัน:
- ระบบช่วย สะกดคำ: เมื่อคุณพิมพ์ข้อความบนสมาร์ทโฟน ระบบจะแนะนำคำที่เข้ากับประโยคหรือคำที่คุณเคยใช้มาก่อนโดยอัตโนมัติ
- การ แปลด้วยเครื่อง: บริการแปลสำหรับผู้บริโภคที่ใช้กันอย่างแพร่หลาย เช่น Google Translate เพื่อรวม NLP ในรูปแบบระดับสูงในการประมวลผลภาษาและแปล
- แชทบอท: NLP เป็นรากฐานสำหรับแชทบอทอัจฉริยะ โดยเฉพาะอย่างยิ่งในการบริการลูกค้า ซึ่งพวกเขาสามารถช่วยเหลือลูกค้าและดำเนินการตามคำขอก่อนที่จะเผชิญหน้ากับบุคคลจริง
มีมากขึ้นที่จะมา ปัจจุบันมีการใช้ NLP ในด้านต่างๆ เช่น สื่อข่าว เทคโนโลยีทางการแพทย์ การจัดการสถานที่ทำงาน และการเงิน มีโอกาสที่เราจะสามารถสนทนากับหุ่นยนต์ได้อย่างเต็มที่ในอนาคต
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับ NLP มีแหล่งข้อมูลที่ยอดเยี่ยมมากมายในบล็อก Towards Data Science หรือกลุ่มการประมวลผล Langauge แห่งชาติของ Standford ที่คุณสามารถดูได้