
เสิร์ชเอ็นจิ้นทำงานอย่างไรและทำให้ชีวิตของคุณง่ายขึ้น?
เผยแพร่แล้ว: 2015-11-06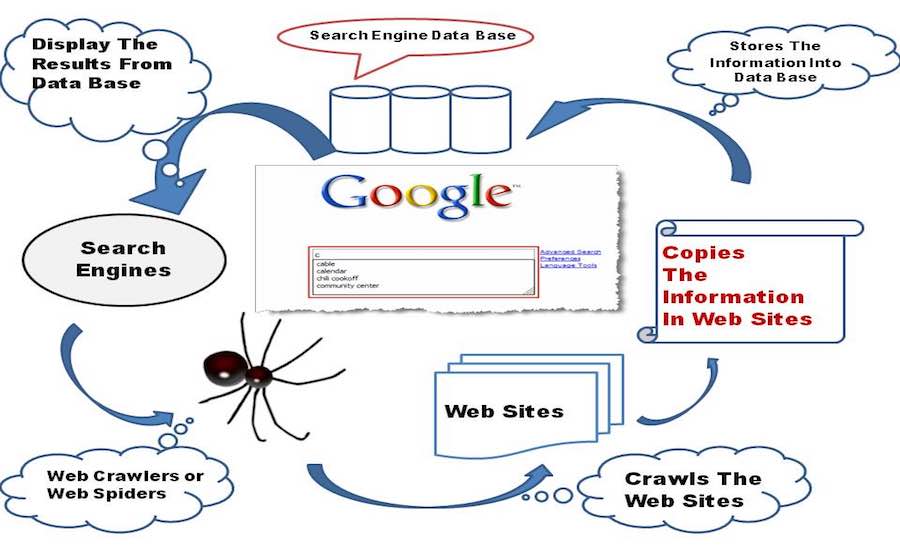 ไบต์สั้น: เสิร์ชเอ็นจิ้นเป็นซอฟต์แวร์ที่ช่วยให้สามารถแสดงผลลัพธ์ของหน้าเว็บที่เกี่ยวข้องตามการป้อนคำค้นหาโดยใช้ Web Crawling และ Web Indexing สูตรอ้วนบางสูตรและอัลกอริธึมอัจฉริยะเพื่อรวบรวมข้อมูลที่เหมาะสม
ไบต์สั้น: เสิร์ชเอ็นจิ้นเป็นซอฟต์แวร์ที่ช่วยให้สามารถแสดงผลลัพธ์ของหน้าเว็บที่เกี่ยวข้องตามการป้อนคำค้นหาโดยใช้ Web Crawling และ Web Indexing สูตรอ้วนบางสูตรและอัลกอริธึมอัจฉริยะเพื่อรวบรวมข้อมูลที่เหมาะสม
Google ให้ผลลัพธ์ที่ดีที่สุดแก่คุณในพริบตาได้อย่างไร จริงๆ แล้ว มันไม่สำคัญหรอก จนกว่า Google, Bing จะอยู่ที่นั่น สถานการณ์จะแตกต่างออกไปมากหากไม่มี Google, Bing หรือ Yahoo ให้เราดำดิ่งสู่โลกของเครื่องมือค้นหาและดูว่าเครื่องมือค้นหาทำงานอย่างไร
ส่องประวัติศาสตร์
เทพนิยายของเสิร์ชเอ็นจิ้นเริ่มต้นขึ้นในปี 1990 เมื่อทิม เบอร์เนอร์ส-ลีเคยเกณฑ์เว็บเซิร์ฟเวอร์ใหม่ทุกเว็บที่ออนไลน์ ให้อยู่ในรายการที่ดูแลโดยเว็บเซิร์ฟเวอร์ของ CERN จนถึงเดือนกันยายน 93 ไม่มีเครื่องมือค้นหาบนอินเทอร์เน็ต แต่มีเครื่องมือเพียงไม่กี่ตัวที่สามารถรักษาฐานข้อมูลของชื่อไฟล์ได้ Archie, Veronica, Jughead เป็นผู้เข้าแข่งขันกลุ่มแรกในหมวดหมู่นี้
Oscar Nierstrasz จากมหาวิทยาลัยเจนีวาได้รับการรับรองให้เป็นเสิร์ชเอ็นจิ้นตัวแรกที่มีชื่อเรียกว่า W3Catalog เขาเขียนสคริปต์ Perl อย่างจริงจังและในที่สุดก็ออกมาพร้อมกับเครื่องมือค้นหาแรกของโลกเมื่อวันที่ 3 กันยายน 1993 นอกจากนี้ ในปี 1993 ยังได้เห็นเครื่องมือค้นหาอื่นๆ อีกจำนวนมากถือกำเนิดขึ้น JumpStation โดย Jonathon Fletcher, AliWeb, WWW Worm เป็นต้น Yahoo! เปิดตัวในปี 1995 เป็นไดเรกทอรีเว็บ แต่เริ่มใช้การค้นหาเอ็นจิ้นของ Inktomi ตั้งแต่ปี 2000 จากนั้นจึงเปลี่ยนมาใช้ Bing ของ Microsoft ในปี 2009
เมื่อพูดถึงชื่อที่เป็นพ้องความหมายเฉพาะของคำว่าเสิร์ชเอ็นจิ้น Google Search เป็นโครงการวิจัยสำหรับผู้สำเร็จการศึกษาจากมหาวิทยาลัยสแตนฟอร์ดสองคน ได้แก่ แลร์รี เพจ และเซอร์กี บริน ซึ่งเริ่มมีรอยเท้าเริ่มต้นในเดือนมีนาคม 2538 ผลงานของ Google เป็นแรงบันดาลใจในขั้นต้น โดยวิธีการลิงก์ย้อนกลับของเพจ ซึ่งคำนวณตามจำนวนลิงก์ย้อนกลับที่มาจากหน้าเว็บหนึ่งๆ เพื่อวัดความสำคัญของหน้านั้นในเวิลด์ไวด์เว็บ “คำแนะนำที่ดีที่สุดที่ฉันเคยได้รับ” เพจกล่าวในขณะที่เขาจำได้ว่า Terry Winograd ผู้บังคับบัญชาของเขาสนับสนุนความคิดของเขาอย่างไร และตั้งแต่นั้นเป็นต้นมา Google ก็ไม่เคยหันกลับมามองอีกเลย
ทุกอย่างเริ่มต้นด้วยการรวบรวมข้อมูล
เสิร์ชเอ็นจิ้นทารกในระยะตั้งไข่เริ่มสำรวจเวิลด์ไวด์เว็บโดยใช้มือและเข่าเล็กๆ ของมันสำรวจทุกลิงก์ที่พบบนเว็บเพจและจัดเก็บไว้ในฐานข้อมูล
ตอนนี้ มาเน้นที่ความคิดทางเทคนิคเบื้องหลังกันบ้าง เครื่องมือค้นหารวมซอฟต์แวร์ Web Crawler ซึ่งโดยพื้นฐานแล้วอินเทอร์เน็ตบอทมอบหมายงานให้เปิดไฮเปอร์ลิงก์ทั้งหมดที่ปรากฏบนหน้าเว็บและสร้างฐานข้อมูลของข้อความและข้อมูลเมตาจากลิงก์ทั้งหมด . เริ่มต้นด้วยชุดลิงก์เริ่มต้นเพื่อเข้าชม เรียกว่า Seeds ทันทีที่ดำเนินการไปที่ลิงก์เหล่านั้น ให้เพิ่มลิงก์ใหม่ในรายการ URL ที่มีอยู่เพื่อเข้าชม ซึ่งเรียกว่า Crawl Frontier
ในขณะที่โปรแกรมรวบรวมข้อมูลข้ามผ่านลิงก์ต่างๆ จะดาวน์โหลดข้อมูลจากหน้าเว็บเหล่านั้นเพื่อดูในภายหลังในรูปแบบของสแนปชอต เนื่องจากการดาวน์โหลดทั้งหน้าเว็บจะต้องใช้ข้อมูลจำนวนมาก และมาในราคาที่ไม่แพง อย่างน้อยก็ใน ประเทศอย่างอินเดีย และฉันสามารถเดิมพันได้ ถ้า Google ก่อตั้งขึ้นในอินเดีย เงินทั้งหมดของพวกเขาจะถูกนำไปใช้จ่ายค่าอินเทอร์เน็ต หวังว่านั่นจะไม่ใช่หัวข้อที่น่ากังวลในตอนนี้
โปรแกรมรวบรวมข้อมูลเว็บสำรวจหน้าเว็บตามนโยบายบางประการ:
นโยบายการเลือก: โปรแกรมรวบรวมข้อมูลตัดสินใจว่าควรดาวน์โหลดหน้าใดและหน้าใดไม่ควร นโยบายการเลือกมุ่งเน้นไปที่การดาวน์โหลดเนื้อหาที่เกี่ยวข้องมากที่สุดของหน้าเว็บแทนที่จะเป็นข้อมูลที่ไม่สำคัญ
นโยบายการเยี่ยมชมซ้ำ: โปรแกรมรวบรวมข้อมูลกำหนดเวลาที่ควรเปิดหน้าเว็บอีกครั้งและแก้ไขการเปลี่ยนแปลงในฐานข้อมูล ด้วยลักษณะแบบไดนามิกของอินเทอร์เน็ต ซึ่งทำให้โปรแกรมรวบรวมข้อมูลอัปเดตเวอร์ชันล่าสุดได้ยาก หน้าเว็บ
นโยบายการทำให้เป็นคู่ขนาน: โปรแกรมรวบรวมข้อมูลใช้หลายกระบวนการพร้อมกันเพื่อสำรวจลิงก์ที่เรียกว่าการรวบรวมข้อมูลแบบกระจาย แต่บางครั้งมีโอกาสที่กระบวนการที่แตกต่างกันอาจดาวน์โหลดหน้าเว็บเดียวกัน ดังนั้นโปรแกรมรวบรวมข้อมูลจึงรักษาการประสานงานระหว่างกระบวนการทั้งหมดเพื่อขจัดโอกาส ความซ้ำซ้อน
นโยบายด้านความสุภาพ: เมื่อโปรแกรมรวบรวมข้อมูลสำรวจเว็บไซต์ โปรแกรมจะดาวน์โหลดหน้าเว็บจากเว็บไซต์พร้อมกัน จึงเป็นการเพิ่มภาระให้กับเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์ ดังนั้น คำว่า "การล่าช้าในการรวบรวมข้อมูล" จึงถูกนำมาใช้โดยโปรแกรมรวบรวมข้อมูลต้องรอสองสามวินาทีหลังจากที่ดาวน์โหลดข้อมูลบางส่วนจากเว็บเซิร์ฟเวอร์ และอยู่ภายใต้นโยบายความสุภาพ
อ่านเพิ่มเติม: วิธีสร้างโปรแกรมรวบรวมข้อมูลเว็บพื้นฐานใน Python
สถาปัตยกรรมระดับสูงของโปรแกรมรวบรวมข้อมูลเว็บมาตรฐาน:
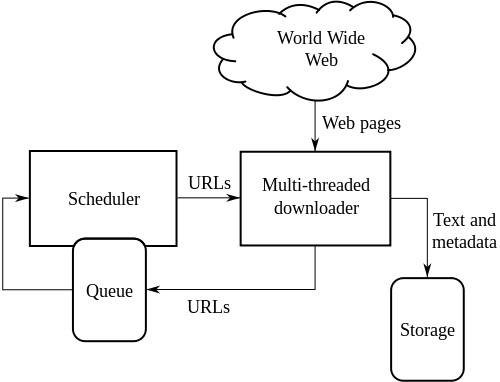
ภาพประกอบด้านบนแสดงวิธีการทำงานของโปรแกรมรวบรวมข้อมูลเว็บ โดยจะเปิดรายการลิงก์เริ่มต้น จากนั้นจึงลิงก์ภายในลิงก์เหล่านั้น เป็นต้น
Wikipedia เขียน นักวิจัยด้านวิทยาการคอมพิวเตอร์ Vladislav Shkapenyuk และ Torsten Suel ตั้งข้อสังเกตว่า:
แม้ว่าจะค่อนข้างง่ายที่จะสร้างโปรแกรมรวบรวมข้อมูลที่ช้าซึ่งดาวน์โหลดสองสามหน้าต่อวินาทีในช่วงเวลาสั้น ๆ แต่การสร้างระบบที่มีประสิทธิภาพสูงที่สามารถดาวน์โหลดหน้าได้หลายร้อยล้านหน้าในช่วงหลายสัปดาห์ทำให้เกิดความท้าทายหลายประการในการออกแบบระบบ I/O และประสิทธิภาพของเครือข่าย ความทนทาน และความสามารถในการจัดการ
จัดทำดัชนีการรวบรวมข้อมูล
หลังจากที่เสิร์ชเอ็นจิ้นเด็กรวบรวมข้อมูลทั่วอินเทอร์เน็ตแล้ว จะสร้างดัชนีของหน้าเว็บทั้งหมดที่พบในทางนั้น การมีดัชนีดีกว่าเสียเวลาในการค้นหาคำค้นหาจากกองเอกสารขนาดใหญ่ ซึ่งจะช่วยประหยัดทั้งเวลาและทรัพยากร
มีหลายปัจจัยที่ส่งผลต่อการสร้างระบบการจัดทำดัชนีที่มีประสิทธิภาพสำหรับเครื่องมือค้นหา เทคนิคการจัดเก็บที่ใช้โดยตัวสร้างดัชนี ขนาดของดัชนี ความสามารถในการค้นหาเอกสารที่มีคำสำคัญที่ค้นหาอย่างรวดเร็ว ฯลฯ เป็นปัจจัยที่รับผิดชอบต่อประสิทธิภาพและความน่าเชื่อถือของดัชนี
อุปสรรคสำคัญประการหนึ่งในเส้นทางสู่การสร้างดัชนีเว็บที่ประสบความสำเร็จคือการปะทะกันระหว่างสองกระบวนการ สมมติว่ากระบวนการหนึ่งต้องการค้นหาเอกสาร และในขณะเดียวกันก็มีกระบวนการอื่นต้องการเพิ่มเอกสารในดัชนี ซึ่งทำให้เกิดข้อขัดแย้งระหว่างสองกระบวนการ ปัญหาแย่ลงไปอีกโดยการใช้การคำนวณแบบกระจายโดยเครื่องมือค้นหาเพื่อจัดการกับข้อมูลมากขึ้น
ประเภทของดัชนี
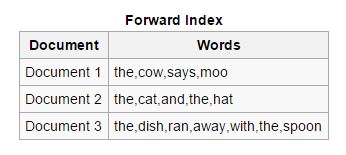
ไปข้างหน้า: ในดัชนีประเภทนี้ คำหลักทั้งหมดที่มีอยู่ในเอกสารจะถูกจัดเก็บไว้ในรายการ ดัชนีการส่งต่อนั้นสร้างได้ง่ายในช่วงเริ่มต้นของการทำดัชนี เนื่องจากช่วยให้ตัวทำดัชนีแบบอะซิงโครนัสสามารถทำงานร่วมกันได้

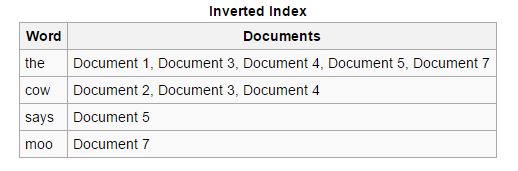
ย้อนกลับ: ดัชนีไปข้างหน้าจะถูกจัดเรียงและแปลงเป็นดัชนีย้อนกลับ ซึ่งแต่ละเอกสารที่มีคีย์เวิร์ดเฉพาะจะถูกรวมเข้ากับเอกสารอื่นๆ ที่มีคีย์เวิร์ดนั้น ดัชนีย้อนกลับช่วยให้ขั้นตอนการค้นหาเอกสารที่เกี่ยวข้องง่ายขึ้นสำหรับคำค้นหาที่กำหนด ซึ่งไม่ใช่กรณีของดัชนีการส่งต่อ
อ่านเพิ่มเติม: DNS (ระบบชื่อโดเมน) คืออะไรและทำงานอย่างไร
การแยกวิเคราะห์เอกสาร
เรียกอีกอย่างว่า Tokenization หมายถึงการแยกส่วนของเอกสาร เช่น คำหลัก (เรียกว่าโทเค็น) รูปภาพ และสื่ออื่นๆ เพื่อให้สามารถแทรกลงในดัชนีได้ในภายหลัง วิธีการโดยทั่วไปจะเน้นที่การทำความเข้าใจภาษาแม่และการคาดเดาคำหลักที่ผู้ใช้อาจค้นหา ซึ่งทำหน้าที่เป็นรากฐานสำหรับการสร้างระบบการจัดทำดัชนีเว็บที่มีประสิทธิภาพ
ความท้าทายที่สำคัญ ได้แก่ การค้นหาขอบเขตของคำของคำหลักที่จะแยกออก เนื่องจากเราสามารถเห็นภาษาต่างๆ เช่น จีนและญี่ปุ่น โดยทั่วไปไม่มีช่องว่างใน สคริปต์ภาษา การเข้าใจถึงความกำกวมของภาษานั้นก็เป็นเรื่องที่น่ากังวลเช่นกัน เนื่องจากบางภาษาเริ่มมีความแตกต่างกันเล็กน้อยหรือมากขึ้นตามการเปลี่ยนแปลงทางภูมิศาสตร์ นอกจากนี้ ความไม่มีประสิทธิภาพของหน้าเว็บบางหน้าที่ไม่ระบุภาษาที่ใช้อย่างชัดเจนยังเป็นประเด็นที่น่ากังวลและเพิ่มภาระงานในตัวสร้างดัชนี
เสิร์ชเอ็นจิ้นมีความสามารถในการรับรู้รูปแบบไฟล์ต่างๆ และดึงข้อมูลจากไฟล์เหล่านี้ได้สำเร็จ และมีความจำเป็นที่ควรใช้ความระมัดระวังสูงสุดในกรณีเหล่านี้
เมตาแท็กยังมีประโยชน์มากในการสร้างดัชนีอย่างรวดเร็ว ซึ่งช่วยลดความพยายามของตัวสร้างดัชนีเว็บ และลดความจำเป็นในการแยกวิเคราะห์เอกสารทั้งหมดโดยสมบูรณ์ คุณจะพบ Meta Tags ที่แนบมาที่ด้านล่างของบทความนี้
ค้นหาดัชนี
ตอนนี้เสิร์ชเอ็นจิ้นเด็กไม่ใช่ทารกอีกต่อไป เขาได้เรียนรู้วิธีคลาน วิธีคว้าสิ่งของอย่างรวดเร็วและมีประสิทธิภาพ และวิธีจัดเรียงสิ่งของอย่างเป็นระบบ สมมุติว่าเพื่อนขอให้เขาหาของบางอย่างจากการจัดวาง เขาจะทำอย่างไร? มีการใช้คำค้นหาที่ใช้อยู่สี่ประเภท แม้ว่าจะไม่ได้มาจากคำค้นหาอย่างเป็นทางการ แต่มีการพัฒนาเมื่อเวลาผ่านไป และพบว่ามีความรู้สึกที่ถูกต้องในแง่ของ ข้อความค้นหาในชีวิตจริงที่ผู้ใช้สร้างขึ้น
การนำทาง: คำนี้ใช้สำหรับข้อความค้นหาที่ผู้ใช้ต้องการไปที่หน้าเว็บหรือเว็บไซต์เฉพาะที่มีอยู่บนอินเทอร์เน็ต ตัวอย่างเช่น เมื่อคุณค้นหา fossBytes บน Google แสดงว่าคุณกำลังเริ่มต้นการสืบค้นข้อมูลการนำทาง
ให้ ข้อมูล: แบบสอบถามประเภทนี้มีผลลัพธ์นับพันและครอบคลุมหัวข้อทั่วไปซึ่งช่วยเพิ่มความรู้ของผู้ใช้ ตัวอย่างเช่น เมื่อคุณค้นหา เช่น Steve Jobs คุณจะเห็นลิงก์ทั้งหมดที่เกี่ยวข้องกับ Steve Jobs
ทางธุรกรรม: การ สืบค้นที่มุ่งเน้นที่ความตั้งใจของผู้ใช้ในการดำเนินการบางอย่าง อาจเกี่ยวข้องกับชุดคำสั่งที่กำหนดไว้ล่วงหน้า ตัวอย่างเช่น จะค้นหาแล็ปท็อปที่สูญหาย/ถูกขโมยได้อย่างไร
การ เชื่อมต่อ: แบบสอบถามประเภทนี้ไม่ได้ใช้บ่อย แต่เน้นที่การเชื่อมต่อคือดัชนีที่สร้างขึ้นจากเว็บไซต์ ตัวอย่างเช่น หากคุณค้นหา Wikipedia มีกี่หน้า
Google และ Bing ได้สร้างอัลกอริธึมที่จริงจังซึ่งสามารถระบุผลลัพธ์ที่เกี่ยวข้องมากที่สุดสำหรับข้อความค้นหาของคุณ Google อ้างว่าคำนวณผลการค้นหาของคุณโดยพิจารณาจากปัจจัยมากกว่า 200 ประการ เช่น คุณภาพของเนื้อหา ใหม่หรือเก่า ความปลอดภัยของหน้าเว็บ และอื่นๆ อีกมากมาย พวกเขามีความคิดที่ยอดเยี่ยมที่สุดในโลกที่ได้รับการแต่งตั้งที่แล็บการค้นหาของพวกเขา ซึ่งทำการคำนวณอย่างหนักและจัดการกับสูตรที่เหลือเชื่อ เพียงเพื่อทำให้การค้นหาง่ายและรวดเร็วยิ่งขึ้นสำหรับคุณ
คุณสมบัติเด่นอื่นๆ*
ค้นหารูปภาพ: คุณจะแปลกใจที่ทราบแรงบันดาลใจของ Google เบื้องหลังเครื่องมือค้นหารูปภาพที่มีชื่อเสียง J.Lo ใช่คุณได้ยินถูกต้องแล้ว J.Lo และชุดสีเขียว Versace (ver-sah-chay) ของเธอที่งาน Grammy Awards ปี 2000 เป็นเหตุผลที่แท้จริงที่ Google ออกการค้นหารูปภาพ เนื่องจากผู้คนต่างยุ่งเกี่ยวกับ Googling ของเธอ.
Eric Schmidt กล่าวในงานเขียนเรื่อง "The Tinkerer's Apprentice" ซึ่งเผยแพร่เมื่อวันที่ 19 มกราคม 2015
การค้นหาด้วยเสียง: Google เป็นคนแรกที่แนะนำการค้นหาด้วยเสียงบนเสิร์ชเอ็นจิ้นของตนหลังจากทำงานหนักมามาก และต่อมาเสิร์ชเอ็นจิ้นอื่นๆ ได้ปรับใช้มันด้วย
การต่อสู้กับสแปม: เสิร์ชเอ็นจิ้นปรับใช้อัลกอริธึมที่ร้ายแรง เพื่อให้สามารถ ปกป้องคุณจากการโจมตีของสแปม สแปมนั้นเป็นข้อความหรือไฟล์ที่แพร่กระจายไปทั่วอินเทอร์เน็ต อาจเป็นเพื่อการโฆษณาหรือเพื่อส่งไวรัส ในเรื่องนี้ Google ด้วยตนเองแจ้งเว็บไซต์ที่พวกเขาพบว่ามีหน้าที่ในการแพร่กระจายข้อความสแปมบนอินเทอร์เน็ต
การเพิ่มประสิทธิภาพตำแหน่ง: ขณะนี้เสิร์ชเอ็นจิ้นสามารถแสดงผลตามตำแหน่งของผู้ใช้ได้ หากค้นหา อากาศในเบงกาลูรูเป็นอย่างไร สถิติสภาพอากาศจะถูกอ้างอิงกับเบงกาลูรู
เข้าใจคุณมากขึ้น: เครื่องมือค้นหาสมัยใหม่สามารถเข้าใจความหมายของข้อความค้นหาของผู้ใช้ แทนที่จะค้นหาคำหลักที่ผู้ใช้ป้อน
เติมข้อความอัตโนมัติ : ความสามารถในการคาดเดาคำค้นหาของคุณขณะที่คุณพิมพ์โดยพิจารณาจากการค้นหาก่อนหน้าและการค้นหาของผู้ใช้รายอื่น
กราฟความรู้: ฟีเจอร์นี้ให้บริการโดย Google Search แสดงให้เห็นถึงความสามารถในการแสดงผลการค้นหาโดยอิงจากผู้คน สถานที่ และกิจกรรมในชีวิตจริง
การควบคุมโดยผู้ปกครอง: เสิร์ชเอ็นจิ้นช่วยให้ผู้ปกครองประเภทเล็กๆ สามารถควบคุมสิ่งที่บุตรหลานของตนทำบนอินเทอร์เน็ตได้
* เป็นการยากที่จะครอบคลุมรายการคุณสมบัติมากมายที่มีให้โดยเครื่องมือค้นหาที่ทรงพลังเหล่านี้
ไขลาน
เสิร์ชเอ็นจิ้นมีส่วนทำให้ชีวิตของเราง่ายขึ้นและการทำงานหนักที่พวกเขาทำเพื่อควบคุมข้อมูลทั้งหมดบนอินเทอร์เน็ตนั้นประเมินค่าไม่ได้ แต่การสำรวจนี้ได้นำไปสู่การจัดแสดงพื้นที่ส่วนตัวของเราบนแพลตฟอร์มสาธารณะ และต้องบอกว่า ถึงเวลาแล้วที่เราควรจะสับสนเกี่ยวกับเส้นทางที่เราได้เดินผ่านมาทั้งหมดนี้ เว้นแต่จะสายเกินไปที่เราจะทบทวนการกระทำของเรา และชีวิตของเราเป็นเพียงครึ่งปีแห่งความอับอายเท่านั้น เราไม่สามารถปฏิเสธความจริงที่ว่าตอนนี้เสิร์ชเอ็นจิ้นเป็นส่วนสำคัญของบุคลิกภาพที่แตกแยกทางดิจิทัลของเรา เราต้องใช้ประโยชน์จากเทคโนโลยีที่เราได้รับเท่านั้น ไม่อนุญาตให้มันจับเราเป็นทาสของการกระทำผิดของเราเอง
โอเค ไม่ต้องพูดถึงเรื่องอารมณ์อีกต่อไป แค่ชื่นชมความน่ารักและความสามารถของเสิร์ชเอ็นจิ้นทารกที่ตอนนี้กลายเป็นวัยรุ่นแล้ว และเข้าใจคุณมากขึ้น Google อยู่ที่นั่นเพื่อค้นหาทุกอย่างสำหรับเรา เป็นอินเทอร์เน็ตสำหรับพวกเราหลายคน และเราต้องชื่นชมกับประสบการณ์ที่ดีที่เราได้รับจากการใช้ Google Search โอ้! ฉันลืมบอก Bing คุณยอดเยี่ยมเช่นกัน ตื่นตัว อยู่อย่างปลอดภัยและใช้ Google
ดูวิดีโอนี้และเรียนรู้เพิ่มเติมเกี่ยวกับเครื่องมือค้นหา:
คุณเคยคลิกปุ่ม I'm Feeling Lucky บน Google Search หรือไม่ เปิดและบอกเราว่า doodle ใดที่คุณชอบมากที่สุดในส่วนความคิดเห็นด้านล่าง