
วิธีแยกวิเคราะห์ข้อมูล CSV ใน Bash
เผยแพร่แล้ว: 2022-09-16
ไฟล์ Comma Separated Values (CSV) เป็นหนึ่งในรูปแบบที่ใช้กันมากที่สุดสำหรับข้อมูลที่ส่งออก บน Linux เราสามารถอ่านไฟล์ CSV โดยใช้คำสั่ง Bash แต่มันอาจซับซ้อนได้เร็วมาก เราจะให้ยืมมือ
ไฟล์ CSV คืออะไร?
ไฟล์ Comma Separated Values เป็นไฟล์ข้อความที่เก็บข้อมูลแบบตาราง CSV เป็นประเภทของข้อมูลที่มีตัวคั่น ตามชื่อที่แนะนำ เครื่องหมายจุลภาค “ , ถูกใช้เพื่อแยกแต่ละฟิลด์ของข้อมูล—หรือ ค่า —จากเพื่อนบ้าน
CSV มีอยู่ทุกที่ หากแอปพลิเคชันมีฟังก์ชันนำเข้าและส่งออก แอปพลิเคชันจะรองรับ CSV เกือบทุกครั้ง ไฟล์ CSV นั้นมนุษย์สามารถอ่านได้ คุณสามารถดูภายในได้โดยใช้เวลาน้อยลง เปิดในโปรแกรมแก้ไขข้อความ และย้ายจากโปรแกรมหนึ่งไปอีกโปรแกรมหนึ่ง ตัวอย่างเช่น คุณสามารถส่งออกข้อมูลจากฐานข้อมูล SQLite และเปิดใน LibreOffice Calc
อย่างไรก็ตาม แม้แต่ CSV ก็อาจซับซ้อนได้ ต้องการมีเครื่องหมายจุลภาคในช่องข้อมูลหรือไม่? ฟิลด์นั้นต้องมีเครื่องหมายอัญประกาศ “ " ” ล้อมรอบ เมื่อต้องการรวมอัญประกาศลงในฟิลด์ เครื่องหมายอัญประกาศแต่ละอันต้องป้อนสองครั้ง
แน่นอน หากคุณกำลังทำงานกับ CSV ที่สร้างโดยโปรแกรมหรือสคริปต์ที่คุณเขียนขึ้น รูปแบบ CSV มักจะเรียบง่ายและตรงไปตรงมา หากคุณถูกบังคับให้ทำงานกับรูปแบบ CSV ที่ซับซ้อนมากขึ้น โดยที่ Linux เป็น Linux ก็มีโซลูชันที่เราสามารถใช้ได้เช่นกัน
ข้อมูลตัวอย่างบางส่วน
คุณสามารถสร้างข้อมูล CSV ตัวอย่างได้อย่างง่ายดาย โดยใช้ไซต์เช่น Online Data Generator คุณสามารถกำหนดเขตข้อมูลที่คุณต้องการและเลือกจำนวนแถวของข้อมูลที่คุณต้องการได้ ข้อมูลของคุณถูกสร้างขึ้นโดยใช้ค่าจำลองที่เหมือนจริงและดาวน์โหลดไปยังคอมพิวเตอร์ของคุณ
เราสร้างไฟล์ที่มีข้อมูลจำลองพนักงาน 50 แถว:
- id : ค่าจำนวนเต็มที่ไม่ซ้ำกันอย่างง่าย
- ชื่อ จริง : ชื่อจริงของบุคคล
- นามสกุล : นามสกุลของบุคคล
- job-title : ตำแหน่งงานของบุคคล
- email-address : ที่อยู่อีเมลของบุคคล
- สาขา : สาขาของบริษัทที่พวกเขาทำงานอยู่
- state : รัฐที่สาขาตั้งอยู่
ไฟล์ CSV บางไฟล์มีส่วนหัวที่แสดงชื่อฟิลด์ ไฟล์ตัวอย่างของเรามีหนึ่งไฟล์ นี่คือส่วนบนของไฟล์ของเรา:
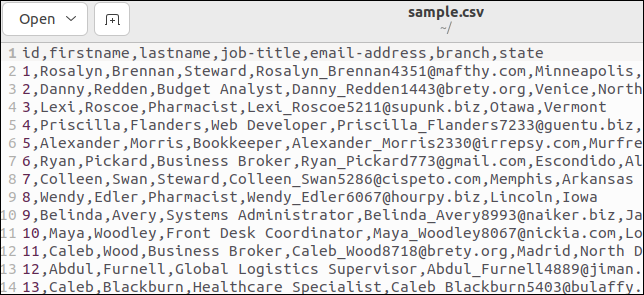
บรรทัดแรกเก็บชื่อฟิลด์เป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค
การแยกวิเคราะห์ข้อมูลในรูปแบบไฟล์ CSV
มาเขียนสคริปต์ที่จะอ่านไฟล์ CSV และแยกฟิลด์ออกจากแต่ละระเบียน คัดลอกสคริปต์นี้ไปยังโปรแกรมแก้ไข และบันทึกลงในไฟล์ชื่อ “field.sh”
#! /bin/bash ในขณะที่ IFS="," อ่าน -r id ชื่อนามสกุล jobtitle อีเมลสาขา state ทำ echo "รหัสบันทึก: $id" echo "ชื่อ: $firstname" echo " นามสกุล: $lastname" echo "ตำแหน่งงาน: $jobtitle" echo "เพิ่มอีเมล: $email" echo "สาขา: $branch" echo "สถานะ: $state" เสียงสะท้อน "" เสร็จสิ้น < <(tail -n +2 sample.csv)
มีเนื้อหาค่อนข้างมากในสคริปต์เล็กๆ ของเรา มาทำลายมันกันเถอะ

เราใช้ while loop ตราบใดที่ เงื่อนไข while loop เป็นจริง เนื้อหาของ while loop จะถูกดำเนินการ เนื้อหาของลูปค่อนข้างง่าย คอลเลกชันของคำสั่ง echo ใช้เพื่อพิมพ์ค่าของตัวแปรบางตัวไปยังหน้าต่างเทอร์มินัล
เงื่อนไข while loop น่าสนใจกว่า body ของ loop เราระบุว่าควรใช้เครื่องหมายจุลภาคเป็นตัวคั่นฟิลด์ภายใน โดยใช้คำสั่ง IFS="," IFS เป็นตัวแปรสภาพแวดล้อม คำสั่ง read อ้างถึงค่าของมันเมื่อแยกวิเคราะห์ลำดับข้อความ
เรากำลังใช้ตัวเลือก -r (retain backslashes) ของคำสั่ง read เพื่อละเว้นแบ็กสแลชที่อาจอยู่ในข้อมูล พวกเขาจะถือว่าเป็นตัวละครปกติ
ข้อความที่แยกวิเคราะห์คำสั่ง read จะถูกเก็บไว้ในชุดของตัวแปรที่ตั้งชื่อตามฟิลด์ CSV พวกเขาสามารถได้รับการตั้งชื่ออย่างง่ายดาย field1, field2, ... field7 แต่ชื่อที่มีความหมายทำให้ชีวิตง่ายขึ้น
ข้อมูลจะได้รับเป็นผลลัพธ์จากคำสั่ง tail เราใช้ tail เพราะมันทำให้เรามีวิธีง่ายๆ ในการข้ามบรรทัดส่วนหัวของไฟล์ CSV ตัวเลือก -n +2 (หมายเลขบรรทัด) บอกให้ tail เริ่มอ่านที่บรรทัดที่สอง
โครงสร้าง <(...) เรียกว่าการทดแทนกระบวนการ ทำให้ Bash ยอมรับผลลัพธ์ของกระบวนการราวกับว่ามาจากตัวอธิบายไฟล์ จากนั้นจะถูกเปลี่ยนเส้นทางไปยังลูป while โดยระบุข้อความที่คำสั่ง read จะแยกวิเคราะห์
ทำให้สคริปต์ทำงานได้โดยใช้คำสั่ง chmod คุณจะต้องทำทุกครั้งที่คัดลอกสคริปต์จากบทความนี้ แทนที่ชื่อของสคริปต์ที่เหมาะสมในแต่ละกรณี
chmod +x field.sh

เมื่อเราเรียกใช้สคริปต์ เร็กคอร์ดจะถูกแบ่งออกเป็นฟิลด์ที่เป็นส่วนประกอบอย่างถูกต้อง โดยแต่ละฟิลด์จะจัดเก็บในตัวแปรที่แตกต่างกัน
./field.sh
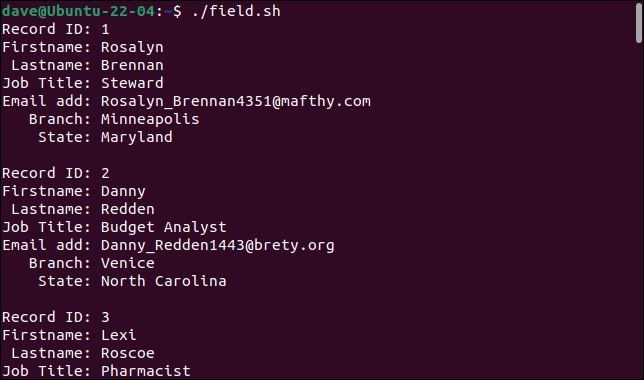
แต่ละเร็กคอร์ดจะถูกพิมพ์เป็นชุดของฟิลด์
การเลือกฟิลด์
บางทีเราไม่ต้องการหรือต้องการดึงข้อมูลทุกฟิลด์ เราสามารถเลือกฟิลด์ได้โดยการรวมคำสั่ง cut
สคริปต์นี้เรียกว่า “select.sh”
#!/bin/bash ในขณะที่ IFS="" อ่าน -r id jobtitle branch state ทำ echo "รหัสบันทึก: $id" echo "ตำแหน่งงาน: $jobtitle" echo "สาขา: $branch" echo "สถานะ: $state" เสียงสะท้อน "" เสร็จแล้ว < <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
เราได้เพิ่มคำสั่ง cut เข้าไปในส่วนคำสั่งการทดแทนกระบวนการ เรากำลังใช้ตัวเลือก -d (ตัวคั่น) เพื่อบอกให้ cut ใช้เครื่องหมายจุลภาค “ , ” เป็นตัวคั่น ตัวเลือก -f (ฟิลด์) บอกการ cut ว่าเราต้องการฟิลด์หนึ่ง สี่ หก และเจ็ด ฟิลด์ทั้งสี่นั้นถูกอ่านเป็นตัวแปรสี่ตัว ซึ่งจะถูกพิมพ์ในเนื้อความของ while loop
นี่คือสิ่งที่เราได้รับเมื่อเราเรียกใช้สคริปต์
./select.sh
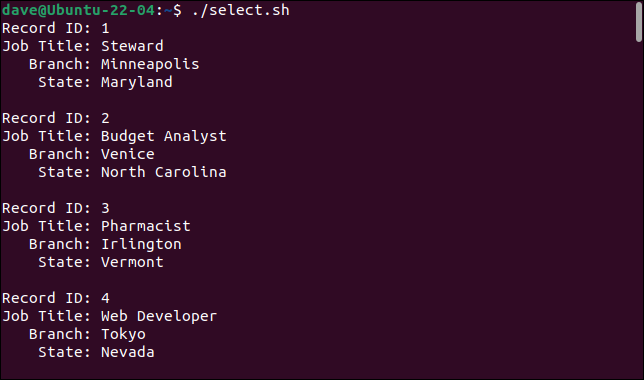
ด้วยการเพิ่มคำสั่ง cut เราสามารถเลือกฟิลด์ที่เราต้องการและละเว้นฟิลด์ที่เราไม่ต้องการได้
จนถึงตอนนี้ดีมาก แต่…
หาก CSV ที่คุณจัดการไม่ซับซ้อนโดยไม่มีเครื่องหมายจุลภาคหรือเครื่องหมายคำพูดในข้อมูลช่อง สิ่งที่เรากล่าวถึงอาจตรงกับความต้องการในการแยกวิเคราะห์ CSV ของคุณ เพื่อแสดงปัญหาที่เราพบ เราได้แก้ไขตัวอย่างข้อมูลเล็กน้อยเพื่อให้มีลักษณะดังนี้
รหัส, ชื่อ, นามสกุล, ตำแหน่งงาน, ที่อยู่อีเมล, สาขา, รัฐ 1,โรซาลิน,เบรนแนน,"สจ๊วต, รุ่นพี่",Rosalyn_Brennan4351@mafthy.com,มินนิอาโปลิส,แมริแลนด์ 2,แดนนี่,เรดเดน,"นักวิเคราะห์ ""งบประมาณ""",Danny_Redden1443@brety.org,เวนิส,นอร์ทแคโรไลนา 3,Lexi,รอสโค,เภสัชกร,,เออร์ลิงตัน,เวอร์มอนต์
- ระเบียนหนึ่งมีเครื่องหมายจุลภาคในเขตข้อมูล
job-titleงาน ดังนั้นเขตข้อมูลนั้นจะต้องถูกห่อด้วยเครื่องหมายอัญประกาศ - เร็กคอร์ดที่สองมีคำที่ห่อด้วยเครื่องหมายอัญประกาศสองชุดในฟิลด์
jobs-titleงาน - ระเบียนที่สามไม่มีข้อมูลในช่องที่
email-address
ข้อมูลนี้ถูกบันทึกเป็น “sample2.csv” แก้ไขสคริปต์ "field.sh" ของคุณเพื่อเรียก "sample2.csv" และบันทึกเป็น "field2.sh"
#! /bin/bash ในขณะที่ IFS="," อ่าน -r id ชื่อนามสกุล jobtitle อีเมลสาขา state ทำ echo "รหัสบันทึก: $id" echo "ชื่อ: $firstname" echo " นามสกุล: $lastname" echo "ตำแหน่งงาน: $jobtitle" echo "เพิ่มอีเมล: $email" echo "สาขา: $branch" echo "สถานะ: $state" เสียงสะท้อน "" เสร็จสิ้น < <(tail -n +2 sample2.csv)
เมื่อเราเรียกใช้สคริปต์นี้ เราจะเห็นการแคร็กปรากฏในตัวแยกวิเคราะห์ CSV แบบง่ายของเรา

./field2.sh

เรกคอร์ดแรกแบ่งฟิลด์ตำแหน่งงานออกเป็นสองฟิลด์ โดยถือว่าส่วนที่สองเป็นที่อยู่อีเมล ทุกสนามหลังจากนี้จะถูกเลื่อนไปทางขวาหนึ่งแห่ง ฟิลด์สุดท้ายมีทั้งค่า branch และ state
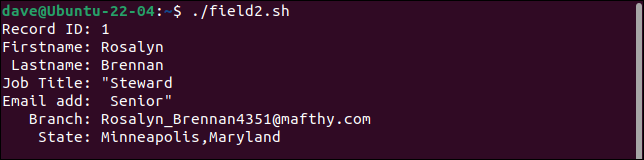
ระเบียนที่สองเก็บเครื่องหมายอัญประกาศทั้งหมด ควรมีเครื่องหมายคำพูดเพียงคู่เดียวรอบคำว่า "งบประมาณ"
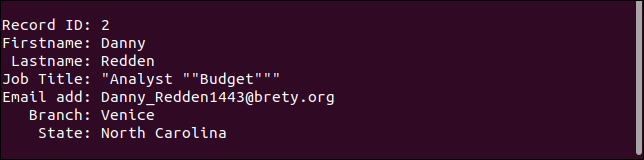
เร็กคอร์ดที่สามจัดการกับฟิลด์ที่ขาดหายไปตามที่ควร ที่อยู่อีเมลหายไป แต่ทุกอย่างอื่นตามที่ควรจะเป็น

ตามสัญชาตญาณ สำหรับรูปแบบข้อมูลอย่างง่าย เป็นเรื่องยากมากที่จะเขียนตัวแยกวิเคราะห์ CSV กรณีทั่วไปที่มีประสิทธิภาพ เครื่องมืออย่าง awk จะช่วยให้คุณเข้าใกล้ได้ แต่มีเคสขอบและข้อยกเว้นอยู่เสมอ

การพยายามเขียนตัวแยกวิเคราะห์ CSV ที่ไม่ถูกต้องอาจไม่ใช่วิธีที่ดีที่สุด แนวทางอื่น—โดยเฉพาะอย่างยิ่งหากคุณกำลังทำงานจนถึงเส้นตายบางอย่าง—ใช้สองกลยุทธ์ที่แตกต่างกัน
หนึ่งคือการใช้เครื่องมือที่ออกแบบมาโดยเฉพาะเพื่อจัดการและดึงข้อมูลของคุณ ประการที่สองคือการล้างข้อมูลของคุณและแทนที่สถานการณ์ปัญหาเช่นเครื่องหมายจุลภาคและเครื่องหมายคำพูดที่ฝังอยู่ ตัวแยกวิเคราะห์ Bash แบบธรรมดาของคุณสามารถรับมือกับ CSV ที่เป็นมิตรกับ Bash ได้
ชุดเครื่องมือ csvkit
ชุดเครื่องมือ CSV csvkit คือชุดของยูทิลิตี้ที่สร้างขึ้นโดยเฉพาะเพื่อช่วยในการทำงานกับไฟล์ CSV คุณจะต้องติดตั้งบนคอมพิวเตอร์ของคุณ
ในการติดตั้งบน Ubuntu ให้ใช้คำสั่งนี้:
sudo apt ติดตั้ง csvkit

ในการติดตั้งบน Fedora คุณต้องพิมพ์:
sudo dnf ติดตั้ง python3-csvkit

บน Manjaro คำสั่งคือ:
sudo pacman -S csvkit

หากเราส่งชื่อไฟล์ CSV ไปให้ยูทิลิตี้ csvlook จะแสดงตารางที่แสดงเนื้อหาของแต่ละฟิลด์ เนื้อหาของฟิลด์จะแสดงขึ้นเพื่อแสดงว่าเนื้อหาของฟิลด์แสดงถึงอะไร ไม่ใช่ตามที่เก็บไว้ในไฟล์ CSV
มาลอง csvlook กับไฟล์ “sample2.csv” ที่มีปัญหากัน
csvlook sample2.csv
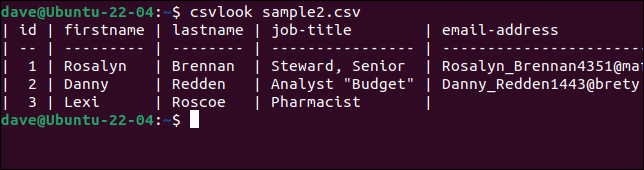
ฟิลด์ทั้งหมดจะแสดงอย่างถูกต้อง นี่เป็นการพิสูจน์ว่าปัญหาไม่ใช่ CSV ปัญหาคือสคริปต์ของเรานั้นง่ายเกินไปที่จะตีความ CSV ได้อย่างถูกต้อง
หากต้องการเลือกคอลัมน์เฉพาะ ให้ใช้คำสั่ง csvcut ตัวเลือก -c (คอลัมน์) สามารถใช้กับชื่อฟิลด์หรือหมายเลขคอลัมน์ หรือผสมทั้งสองอย่างก็ได้
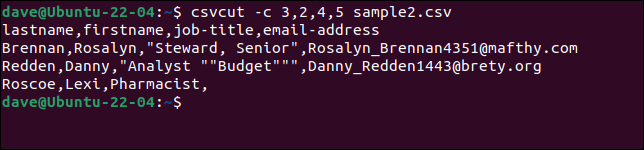
สมมติว่าเราจำเป็นต้องแยกชื่อและนามสกุล ตำแหน่งงาน และที่อยู่อีเมลออกจากแต่ละระเบียน แต่เราต้องการลำดับชื่อเป็น “นามสกุล ชื่อจริง” สิ่งที่เราต้องทำคือใส่ชื่อฟิลด์หรือหมายเลขตามลำดับที่เราต้องการ
คำสั่งทั้งสามนี้เทียบเท่ากันทั้งหมด
csvcut -c นามสกุล, ชื่อ, ตำแหน่งงาน, ที่อยู่อีเมล sample2.csv
csvcut -c นามสกุล, ชื่อจริง, 4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
เราสามารถเพิ่มคำสั่ง csvsort เพื่อเรียงลำดับผลลัพธ์ตามฟิลด์ เรากำลังใช้ตัวเลือก -c (คอลัมน์) เพื่อระบุคอลัมน์ที่จะจัดเรียง และตัวเลือก -r (ย้อนกลับ) เพื่อเรียงลำดับจากมากไปหาน้อย
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
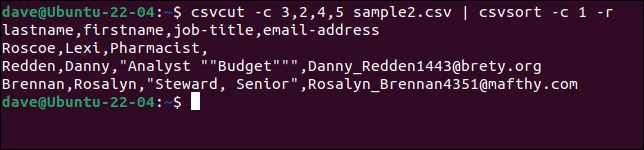
เพื่อให้ผลลัพธ์ออกมาสวยขึ้น เราสามารถป้อนผ่าน csvlook ได้
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
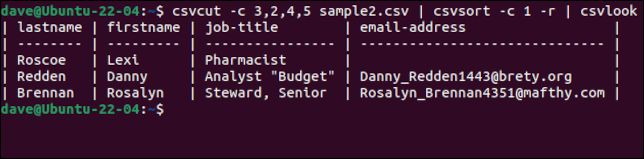
สิ่งที่ควรทราบก็คือ ถึงแม้ว่าเรกคอร์ดจะถูกจัดเรียง แต่บรรทัดส่วนหัวที่มีชื่อฟิลด์จะถูกเก็บไว้เป็นบรรทัดแรก เมื่อเราพอใจแล้ว เรามีข้อมูลในแบบที่เราต้องการ เราสามารถลบ csvlook ออกจาก command chain และสร้างไฟล์ CSV ใหม่โดยเปลี่ยนเส้นทางเอาต์พุตไปยังไฟล์
เราเพิ่มข้อมูลลงใน “sample2.file” ลบคำสั่ง csvsort และสร้างไฟล์ใหม่ชื่อ “sample3.csv”
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

วิธีที่ปลอดภัยในการฆ่าเชื้อข้อมูล CSV
หากคุณเปิดไฟล์ CSV ใน LibreOffice Calc แต่ละฟิลด์จะอยู่ในเซลล์ คุณสามารถใช้ฟังก์ชันค้นหาและแทนที่เพื่อค้นหาเครื่องหมายจุลภาคได้ คุณสามารถแทนที่ด้วย "ไม่มีอะไร" เพื่อให้หายไป หรือมีอักขระที่จะไม่ส่งผลต่อการแยกวิเคราะห์ CSV เช่น เซมิโคลอน “ ; " ตัวอย่างเช่น.
คุณจะไม่เห็นเครื่องหมายอัญประกาศรอบฟิลด์ที่ยกมา เครื่องหมายอัญประกาศเดียวที่คุณจะเห็นคือเครื่องหมายอัญประกาศที่ฝังอยู่ ภายใน ข้อมูลฟิลด์ สิ่งเหล่านี้จะแสดงเป็นเครื่องหมายอัญประกาศเดี่ยว การค้นหาและแทนที่ด้วยเครื่องหมายอัญประกาศเดี่ยว “ ' ” จะแทนที่เครื่องหมายอัญประกาศคู่ในไฟล์ CSV
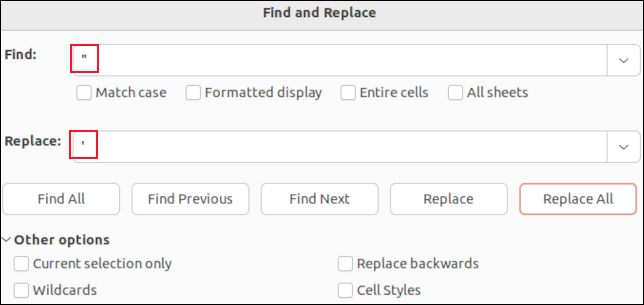
การค้นหาและแทนที่ในแอปพลิเคชัน เช่น LibreOffice Calc หมายความว่าคุณไม่สามารถลบเครื่องหมายจุลภาคคั่นฟิลด์ใดๆ โดยไม่ตั้งใจ หรือลบเครื่องหมายอัญประกาศรอบฟิลด์ที่ยกมา คุณจะเปลี่ยนเฉพาะ ค่าข้อมูล ของฟิลด์เท่านั้น
เราเปลี่ยนเครื่องหมายจุลภาคทั้งหมดในฟิลด์ด้วยเครื่องหมายอัฒภาคและเครื่องหมายอัญประกาศที่ฝังไว้ทั้งหมดด้วยอะพอสทรอฟีและบันทึกการเปลี่ยนแปลงของเรา
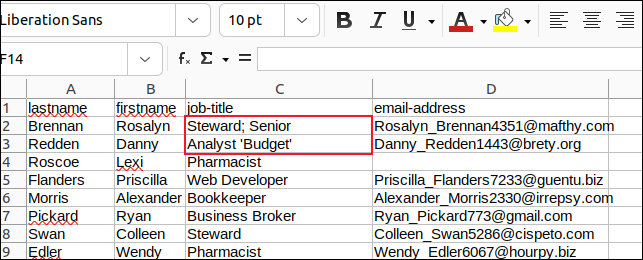
จากนั้นเราสร้างสคริปต์ชื่อ “field3.sh” เพื่อแยกวิเคราะห์ “sample3.csv”
#! /bin/bash ในขณะที่ IFS="," อ่าน -r นามสกุล ชื่อ ตำแหน่งงาน อีเมล ทำ echo " นามสกุล: $lastname" echo "ชื่อ: $firstname" echo "ตำแหน่งงาน: $jobtitle" echo "เพิ่มอีเมล: $email" เสียงสะท้อน "" เสร็จสิ้น < <(tail -n +2 sample3.csv)
มาดูกันว่าเราได้อะไรเมื่อเรารันมัน
./field3.sh
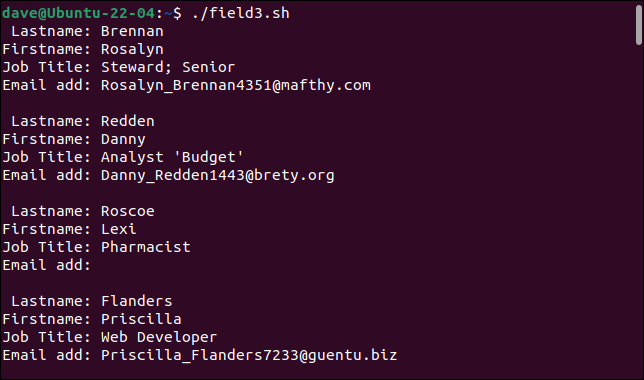
parser อย่างง่ายของเราสามารถจัดการบันทึกที่มีปัญหาก่อนหน้านี้ได้
คุณจะเห็น CSV มากมาย
CSV เป็นสิ่งที่ใกล้เคียงที่สุดกับภาษาทั่วไปสำหรับข้อมูลแอปพลิเคชัน แอปพลิเคชันส่วนใหญ่ที่จัดการข้อมูลบางรูปแบบรองรับการนำเข้าและส่งออก CSV การรู้วิธีจัดการกับ CSV อย่างสมจริงและใช้งานได้จริง จะทำให้คุณอยู่ในตำแหน่งที่ดี
ที่เกี่ยวข้อง: 9 ตัวอย่างสคริปต์ทุบตีเพื่อให้คุณเริ่มต้นบน Linux