
วิธีแยกวิเคราะห์ข้อความ
เผยแพร่แล้ว: 2022-10-15
หากคุณได้เรียนรู้ภาษาการเขียนโปรแกรมคอมพิวเตอร์มาสองสามภาษา คุณอาจเคยได้ยินคำนี้โดยแยกวิเคราะห์ข้อความ ใช้เพื่อลดความซับซ้อนของค่าข้อมูลที่ซับซ้อนของไฟล์ บทความนี้ช่วยคุณในการรู้วิธีแยกวิเคราะห์ข้อความโดยใช้ภาษา นอกจากนี้ หากคุณพบข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x คุณจะทราบวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ในบทความ
สารบัญ
- วิธีแยกวิเคราะห์ข้อความ
- การแยกวิเคราะห์ข้อความคืออะไร?
- NLP หรือการประมวลผลภาษาธรรมชาติ
- การแยกวิเคราะห์ข้อความคืออะไร?
- เหตุผลในการแยกวิเคราะห์ข้อความคืออะไร
- วิธีที่ 1: ผ่าน DataFrame Class
- วิธีที่ 2: ผ่าน Word Tokenization
- วิธีที่ 3: ผ่าน DocParser Class
- วิธีที่ 4: ผ่านเครื่องมือแยกวิเคราะห์ข้อความ
- วิธีที่ 5: ผ่าน TextFieldParser (Visual Basic)
- เคล็ดลับแบบมือโปร: วิธีแยกวิเคราะห์ข้อความผ่าน MS Excel
- วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์
วิธีแยกวิเคราะห์ข้อความ
ในบทความนี้ เราได้แสดงคู่มือฉบับเต็มเพื่อแยกวิเคราะห์ข้อความด้วยวิธีต่างๆ และได้แนะนำสั้นๆ เกี่ยวกับการแยกวิเคราะห์ข้อความ
การแยกวิเคราะห์ข้อความคืออะไร?
ก่อนที่จะเจาะลึกเพื่อเรียนรู้แนวคิดของการแยกวิเคราะห์ข้อความโดยใช้รหัสใด ๆ สิ่งสำคัญคือต้องรู้เกี่ยวกับพื้นฐานของภาษาและการเข้ารหัส
NLP หรือการประมวลผลภาษาธรรมชาติ
ในการแยกวิเคราะห์ข้อความ ใช้การประมวลผลภาษาธรรมชาติหรือ NLP ซึ่งเป็นฟิลด์ย่อยของโดเมนปัญญาประดิษฐ์ ภาษา Python ซึ่งเป็นหนึ่งในภาษาที่อยู่ในหมวดหมู่นี้ใช้เพื่อแยกวิเคราะห์ข้อความ
รหัส NLP ช่วยให้คอมพิวเตอร์สามารถเข้าใจและประมวลผลภาษามนุษย์เพื่อให้เหมาะสมกับการใช้งานที่หลากหลาย หากต้องการนำเทคนิค ML หรือ Machine Learning ไปใช้กับภาษา ข้อมูลข้อความที่ไม่มีโครงสร้างจะต้องถูกแปลงเป็นข้อมูลตารางที่มีโครงสร้าง สำหรับการทำกิจกรรมการแยกวิเคราะห์ให้เสร็จสิ้น ภาษา Python ถูกใช้เพื่อแก้ไขรหัสโปรแกรม
การแยกวิเคราะห์ข้อความคืออะไร?
การแยกวิเคราะห์ข้อความหมายถึงการแปลงข้อมูลจากรูปแบบหนึ่งไปเป็นรูปแบบอื่น รูปแบบที่บันทึกไฟล์จะถูกแยกวิเคราะห์หรือแปลงเป็นไฟล์ในรูปแบบอื่นเพื่อให้ผู้ใช้สามารถใช้งานได้ในแอพพลิเคชั่นต่างๆ
- กล่าวอีกนัยหนึ่ง กระบวนการนี้หมายถึงการวิเคราะห์สตริงหรือข้อความ และแปลงเป็นส่วนประกอบทางลอจิคัลโดยการเปลี่ยนรูปแบบของไฟล์
- กฎบางอย่างของภาษา Python ถูกใช้เพื่อทำงานเขียนโปรแกรมทั่วไปนี้ให้เสร็จสมบูรณ์ ขณะแยกวิเคราะห์ข้อความ ชุดข้อความที่กำหนดจะแบ่งออกเป็นส่วนประกอบย่อยๆ
เหตุผลในการแยกวิเคราะห์ข้อความคืออะไร
เหตุผลที่ต้องแยกวิเคราะห์ข้อความแสดงไว้ในส่วนนี้ และเป็นความรู้ที่จำเป็นก่อนจะทราบวิธีแยกวิเคราะห์ข้อความ
- ข้อมูลคอมพิวเตอร์ทั้งหมดจะไม่อยู่ในรูปแบบเดียวกันและอาจแตกต่างไปตามการใช้งานต่างๆ
- รูปแบบข้อมูลแตกต่างกันไปสำหรับแอปพลิเคชันต่างๆ และรหัสที่เข้ากันไม่ได้จะทำให้เกิดข้อผิดพลาดนี้
- ไม่มีโปรแกรมคอมพิวเตอร์สากลสำหรับเลือกข้อมูลของรูปแบบข้อมูลทั้งหมด
วิธีที่ 1: ผ่าน DataFrame Class
DataFrame Class ของภาษา Python มีฟังก์ชันที่จำเป็นทั้งหมดในการแยกวิเคราะห์ข้อความ ไลบรารีที่สร้างขึ้นนี้ประกอบด้วยรหัสที่จำเป็นในการแยกวิเคราะห์ข้อมูลของรูปแบบใดๆ เป็นรูปแบบอื่น
แนะนำสั้นๆ ของ DataFrame Class
DataFrame Class เป็นโครงสร้างข้อมูลที่มีคุณลักษณะหลากหลาย ซึ่งใช้เป็นเครื่องมือวิเคราะห์ข้อมูล นี่คือเครื่องมือวิเคราะห์ข้อมูลที่ทรงพลังที่สามารถใช้วิเคราะห์ข้อมูลได้โดยใช้ความพยายามเพียงเล็กน้อย
- รหัสจะถูกอ่านใน DataFrame แพนด้าเพื่อทำการวิเคราะห์ในภาษา Python
- Class มาพร้อมกับแพ็คเกจมากมายที่จัดเตรียมโดยแพนด้า ซึ่งใช้โดยนักวิเคราะห์ข้อมูล Python
- คุณสมบัติของคลาสนี้เป็นนามธรรม ซึ่งเป็นรหัสที่ฟังก์ชันการทำงานภายในของฟังก์ชันถูกซ่อนจากผู้ใช้ ของไลบรารี NumPy ไลบรารี NumPy เป็นไลบรารีหลามที่รวมคำสั่งและฟังก์ชันสำหรับการทำงานกับอาร์เรย์
- คลาส DataFrame สามารถใช้เพื่อแสดงอาร์เรย์สองมิติที่มีดัชนีหลายแถวและคอลัมน์ ดัชนีเหล่านี้ช่วยในการจัดเก็บข้อมูลหลายมิติ และด้วยเหตุนี้จึงเรียกว่า MultiIndex สิ่งเหล่านี้ต้องมีการเปลี่ยนแปลงเพื่อทราบวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์
แพนด้าของภาษา Python ช่วยในการดำเนินการ SQL หรือรูปแบบฐานข้อมูลด้วยความสมบูรณ์แบบสูงสุดเพื่อหลีกเลี่ยงข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x นอกจากนี้ยังมีเครื่องมือ IO บางอย่างที่ช่วยในการวิเคราะห์ไฟล์ CSV, MS Excel, JSON, HDF5 และรูปแบบข้อมูลอื่นๆ
อ่านเพิ่มเติม: แก้ไขข้อผิดพลาดที่เกิดขึ้นขณะพยายามขอพร็อกซี
กระบวนการแยกวิเคราะห์ข้อความโดยใช้ DataFrame Class
หากต้องการทราบวิธีแยกวิเคราะห์ข้อความ คุณสามารถใช้กระบวนการมาตรฐานโดยใช้คลาส DataFrame ที่ระบุในส่วนนี้
- ถอดรหัสรูปแบบข้อมูลของข้อมูลที่ป้อน
- กำหนดข้อมูลผลลัพธ์ของข้อมูล เช่น CSV หรือ Comma Separated Value
- เขียนรหัสประเภทข้อมูลพื้นฐานเช่นรายการหรือ dict
หมายเหตุ: การเขียนโค้ดบน DataFrame ที่ว่างเปล่าอาจเป็นเรื่องน่าเบื่อและซับซ้อน แพนด้าอนุญาตให้สร้างข้อมูลในคลาส DataFrame จากประเภทข้อมูลเหล่านี้ ดังนั้นข้อมูลในประเภทข้อมูลพื้นฐานสามารถแยกวิเคราะห์เป็นรูปแบบข้อมูลที่ต้องการได้อย่างง่ายดาย
- วิเคราะห์ข้อมูลโดยใช้เครื่องมือวิเคราะห์ข้อมูล pandas DataFrame และพิมพ์ผลลัพธ์
ตัวเลือกที่ 1: รูปแบบมาตรฐาน
วิธีการมาตรฐานในการจัดรูปแบบไฟล์ใดๆ ที่มีรูปแบบข้อมูลบางอย่าง เช่น CSV ได้อธิบายไว้ที่นี่
- บันทึกไฟล์ด้วยค่าข้อมูลในเครื่องพีซีของคุณ ตัวอย่างเช่น คุณสามารถตั้งชื่อไฟล์ data.txt
- นำเข้าไฟล์ในแพนด้าด้วยชื่อเฉพาะและนำเข้าข้อมูลไปยังตัวแปรอื่น ตัวอย่างเช่น แพนด้าของภาษานั้นถูกนำเข้ามาในชื่อ pd ในรหัสที่กำหนด
- การนำเข้าควรมีโค้ดที่สมบูรณ์พร้อมรายละเอียดของชื่อไฟล์อินพุต ฟังก์ชัน และรูปแบบไฟล์อินพุต
หมายเหตุ: ในที่นี้ ตัวแปรที่ชื่อ res ใช้เพื่อทำหน้าที่ อ่าน ข้อมูลในไฟล์ data.txt โดยใช้แพนด้าที่นำเข้าใน pd รูปแบบข้อมูลของข้อความที่ป้อนถูกระบุในรูปแบบ CSV
- เรียกประเภทไฟล์ที่มีชื่อและวิเคราะห์ข้อความที่แยกวิเคราะห์ในผลงานพิมพ์ ตัวอย่างเช่น คำสั่ง res หลังจากการดำเนินการบรรทัดคำสั่งจะช่วยในการพิมพ์ข้อความที่แยกวิเคราะห์
โค้ดตัวอย่างสำหรับกระบวนการที่อธิบายข้างต้นแสดงไว้ด้านล่างและจะช่วยในการทำความเข้าใจวิธีแยกวิเคราะห์ข้อความ
นำเข้าแพนด้าเป็น pd
res = pd.read_csv('data.txt')
resในกรณีนี้ หากคุณป้อนค่าข้อมูลในไฟล์ data.txt เช่น [1,2,3] จะถูกแยกวิเคราะห์และแสดงเป็น 1 2 3
ตัวเลือก II: วิธีสตริง
หากข้อความที่กำหนดให้กับโค้ดมีเฉพาะสตริงหรืออักขระอัลฟา สามารถใช้อักขระพิเศษในสตริง เช่น จุลภาค ช่องว่าง ฯลฯ เพื่อแยกและแยกวิเคราะห์ข้อความได้ กระบวนการนี้คล้ายกับการดำเนินการสตริงภายในทั่วไป หากต้องการค้นหาวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ คุณต้องทำตามขั้นตอนการแยกวิเคราะห์ข้อความโดยใช้ตัวเลือกนี้ตามที่อธิบายไว้ด้านล่าง
- ข้อมูลถูกดึงออกมาจากสตริงและอักขระพิเศษทั้งหมดที่แยกข้อความจะถูกบันทึกไว้
ตัวอย่างเช่น ในโค้ดที่ระบุด้านล่าง จะมีการระบุอักขระพิเศษในสตริง my_string ซึ่งได้แก่ ' , ' และ ' : ' ขั้นตอนนี้ต้องทำอย่างระมัดระวังเพื่อหลีกเลี่ยงข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x
- ข้อความในสตริงจะถูกแยกตามค่าและตำแหน่งของอักขระพิเศษ
ตัวอย่างเช่น สตริงถูกแบ่งออกเป็นค่าข้อมูลข้อความตามอักขระพิเศษที่ระบุโดยใช้คำสั่ง split
- ค่าข้อมูลของสตริงจะถูกพิมพ์เพียงอย่างเดียวเป็นข้อความที่แยกวิเคราะห์ ในที่นี้ คำสั่ง print ใช้เพื่อพิมพ์ค่าข้อมูลที่แยกวิเคราะห์ของข้อความ
โค้ดตัวอย่างสำหรับกระบวนการที่อธิบายไว้ข้างต้นแสดงไว้ด้านล่าง
my_string = 'ชื่อ: เทค, คอมพิวเตอร์'
sfinal = [name.strip() สำหรับชื่อใน my_string.split(':')[1].split(',')]
พิมพ์("ชื่อ: {}".format(sfinal))ในกรณีนี้ ผลลัพธ์ของสตริงที่แยกวิเคราะห์จะแสดงดังที่แสดงด้านล่าง
ชื่อ: ['เทค', 'คอมพิวเตอร์']
เพื่อให้ได้ความชัดเจนที่ดีขึ้นและรู้วิธีแยกวิเคราะห์ข้อความในขณะที่ใช้ข้อความสตริง จะใช้ for loop และแก้ไขโค้ดดังนี้
my_string = 'ชื่อ: เทค, คอมพิวเตอร์'
s1 = my_string.split(':')
s2 = s1 [1]
s3 = s2.split(',')
s4 = [name.strip() สำหรับชื่อใน s3]
สำหรับ idx รายการในการแจกแจง ([s1, s2, s3, s4]):
print(“ขั้นตอน {}: {}”.format(idx, item)) 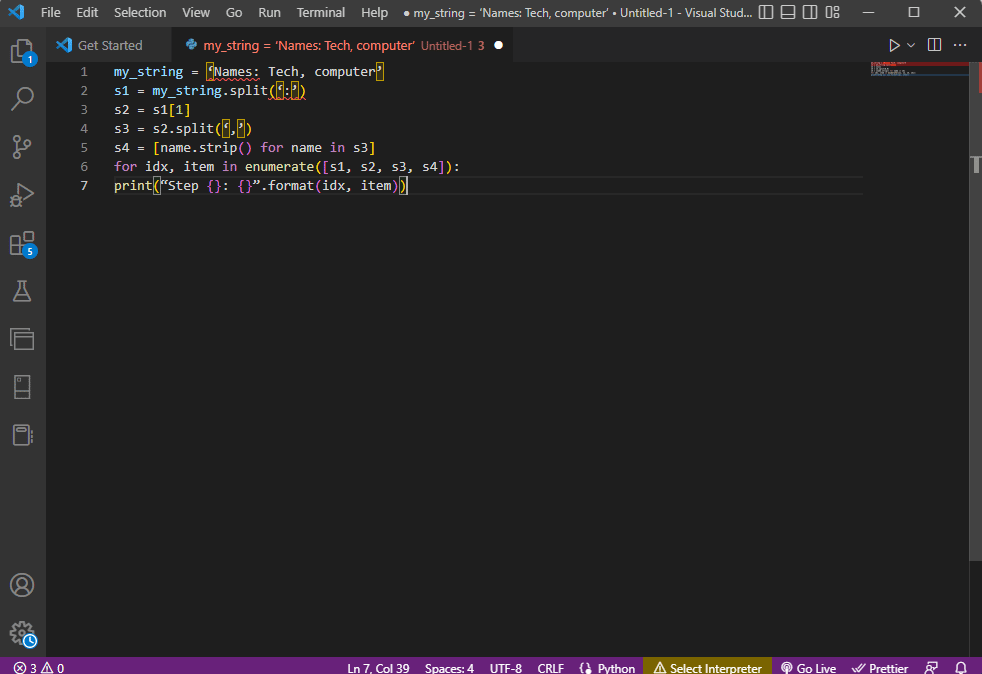
ผลลัพธ์ของข้อความที่แยกวิเคราะห์สำหรับแต่ละขั้นตอนเหล่านี้จะแสดงตามที่ระบุด้านล่าง คุณสามารถสังเกตได้ว่าในขั้นตอนที่ 0 สตริงจะถูกแยกตามอักขระพิเศษ : และค่าข้อมูลข้อความจะถูกแยกตามอักขระในขั้นตอนต่อไป
ขั้นตอนที่ 0: ['ชื่อ', 'เทคโนโลยี, คอมพิวเตอร์'] ขั้นตอนที่ 1: เทคโนโลยี คอมพิวเตอร์ ขั้นตอนที่ 2: [' เทค ', ' คอมพิวเตอร์'] ขั้นตอนที่ 3: ['เทคนิค', 'คอมพิวเตอร์']
ตัวเลือก III: การแยกวิเคราะห์ไฟล์ที่ซับซ้อน
ในกรณีส่วนใหญ่ ข้อมูลไฟล์ที่ต้องแยกวิเคราะห์ประกอบด้วยประเภทข้อมูลและค่าข้อมูลที่แตกต่างกัน ในกรณีนี้ อาจเป็นเรื่องยากที่จะแยกวิเคราะห์ไฟล์โดยใช้วิธีการที่อธิบายไว้ก่อนหน้านี้
คุณสมบัติของการแยกวิเคราะห์ข้อมูลที่ซับซ้อนในไฟล์คือการทำให้ค่าข้อมูลแสดงในรูปแบบตาราง
- ชื่อหรือข้อมูลเมตาของค่าจะถูกพิมพ์ที่ด้านบนของไฟล์
- ตัวแปรและฟิลด์จะพิมพ์ออกมาในรูปแบบตารางและ
- ค่าข้อมูลในรูปแบบคีย์ผสม
ก่อนที่จะศึกษาวิธีแยกวิเคราะห์ข้อความในวิธีนี้ จำเป็นต้องเรียนรู้แนวคิดพื้นฐานบางประการก่อน การแยกวิเคราะห์ค่าข้อมูลทำได้โดยใช้นิพจน์ทั่วไปหรือ Regex
รูปแบบ Regex
หากต้องการทราบวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ คุณต้องแน่ใจว่ารูปแบบ regex ในนิพจน์นั้นเหมาะสม รหัสสำหรับแยกวิเคราะห์ค่าข้อมูลของสตริงจะเกี่ยวข้องกับรูปแบบ Regex ทั่วไปที่แสดงด้านล่างในส่วนนี้
- '\d' : จับคู่ตัวเลขทศนิยมในสตริง
- '\s' : จับคู่อักขระช่องว่าง
- '\w' : จับคู่อักขระที่เป็นตัวอักษรและตัวเลขคละกัน
- '+' หรือ '*' : ทำการจับคู่โลภโดยจับคู่อักขระอย่างน้อยหนึ่งตัวในสตริง
- 'a-z' : จับคู่กลุ่มตัวพิมพ์เล็กในค่าข้อมูลข้อความ
- 'A-Z' หรือ 'a-z' : จับคู่กลุ่มตัวพิมพ์ใหญ่และตัวพิมพ์เล็กของสตริง และ
- '0-9' : จับคู่ค่าตัวเลข
นิพจน์ทั่วไป
โมดูลนิพจน์ทั่วไปเป็นส่วนสำคัญของแพ็คเกจ pandas ในภาษา Python และ re ที่ไม่ถูกต้องสามารถนำไปสู่ข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x เป็นภาษาเล็กๆ ที่ฝังอยู่ใน Python เพื่อค้นหารูปแบบสตริงในนิพจน์ Regular Expressions หรือ Regex เป็นสตริงที่มีไวยากรณ์พิเศษ อนุญาตให้ผู้ใช้จับคู่รูปแบบในสตริงอื่นๆ ตามค่าในสตริง
Regex ถูกสร้างขึ้นตามชนิดข้อมูลและข้อกำหนดของนิพจน์ในสตริง เช่น 'String = (.*)\n regex ถูกใช้ก่อนรูปแบบในทุกนิพจน์ สัญลักษณ์ที่ใช้ในนิพจน์ทั่วไปแสดงไว้ด้านล่างและจะช่วยในการทราบวิธีแยกวิเคราะห์ข้อความ
- . : เพื่อดึงอักขระใด ๆ จากข้อมูล
- * : ใช้ข้อมูลศูนย์หรือมากกว่าจากนิพจน์ก่อนหน้า
- (.*) : เพื่อจัดกลุ่มส่วนของนิพจน์ทั่วไปภายในวงเล็บ
- \n : สร้างอักขระบรรทัดใหม่ที่ท้ายบรรทัดในโค้ด
- \d : สร้างค่าอินทิกรัลสั้น ๆ ในช่วง 0 ถึง 9
- + : ใช้ข้อมูลอย่างน้อยหนึ่งรายการจากนิพจน์ก่อนหน้า และ
- | : สร้างคำสั่งเชิงตรรกะ ใช้สำหรับ หรือ นิพจน์
RegexObjects
RegexObject เป็นค่าส่งคืนสำหรับฟังก์ชันคอมไพล์และใช้เพื่อส่งคืน MatchObject หากนิพจน์ตรงกับค่าที่ตรงกัน
1. MatchObject
เนื่องจากค่าบูลีนของ MatchObject จะเป็น True เสมอ คุณสามารถใช้คำสั่ง if เพื่อระบุการจับคู่ที่เป็นค่าบวกในออบเจกต์ได้ ในกรณีของการใช้คำสั่ง if กลุ่มที่อ้างอิงถึงโดยดัชนีจะใช้เพื่อค้นหาการจับคู่ของวัตถุในนิพจน์
- group() ส่งคืนกลุ่มย่อยของการแข่งขันอย่างน้อยหนึ่งกลุ่ม
- group(0) คืนค่าการแข่งขันทั้งหมด
- group(1) ส่งคืนกลุ่มย่อยในวงเล็บแรก และ
- ในขณะที่อ้างถึงหลายกลุ่ม เราควรใช้ส่วนขยายเฉพาะของหลาม ส่วนขยายนี้ใช้เพื่อระบุชื่อของกลุ่มที่ต้องการค้นหารายการที่ตรงกัน ส่วนขยายเฉพาะมีให้ภายในกลุ่มในวงเล็บ ตัวอย่างเช่น นิพจน์ (?P<group1>regex1) จะอ้างถึงกลุ่มเฉพาะที่มีชื่อ group1 และตรวจสอบการจับคู่ในนิพจน์ทั่วไป regex1 หากต้องการเรียนรู้วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ คุณต้องตรวจสอบว่าชี้กลุ่มถูกต้องหรือไม่
2. วิธีการของ MatchObject
ขณะค้นหาวิธีแยกวิเคราะห์ข้อความ สิ่งสำคัญคือต้องรู้ว่า MatchObject มีวิธีพื้นฐานสองวิธีตามรายการด้านล่าง หากพบ MatchObject ในนิพจน์ที่ระบุ มันจะส่งคืนอินสแตนซ์ มิฉะนั้น จะส่งคืน None
- ใช้เมธอด match(string) เพื่อค้นหาการจับคู่ของสตริงที่จุดเริ่มต้นของนิพจน์ทั่วไป และ
- วิธีการ ค้นหา (สตริง) ใช้เพื่อสแกนผ่านสตริงเพื่อค้นหาตำแหน่งสำหรับการจับคู่ในนิพจน์ทั่วไป
ฟังก์ชันนิพจน์ทั่วไป
ฟังก์ชัน Regex คือบรรทัดโค้ดที่ใช้เพื่อทำหน้าที่บางอย่างตามที่ผู้ใช้ระบุจากชุดของค่าข้อมูลที่จัดหา
หมายเหตุ: ในการเขียนฟังก์ชัน สตริงดิบจะใช้สำหรับนิพจน์ทั่วไปเพื่อหลีกเลี่ยงข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x ทำได้โดยการเพิ่มตัวห้อย r ก่อนแต่ละรูปแบบในนิพจน์
ฟังก์ชันทั่วไปที่ใช้ในนิพจน์อธิบายไว้ด้านล่าง
1. re.findall()
ฟังก์ชันนี้ส่งคืนรูปแบบทั้งหมดในสตริงหากพบการจับคู่และส่งคืนรายการว่างหากไม่พบรายการที่ตรงกัน ตัวอย่างเช่น ฟังก์ชัน string = re.findall('[aeiou]', regex_filename) ถูกใช้เพื่อค้นหาการเกิดเสียงสระในชื่อไฟล์
2. re.split()
ฟังก์ชันนี้ใช้เพื่อแยกสตริงในกรณีที่มีการจับคู่กับอักขระที่ระบุ เช่น พบช่องว่าง ในกรณีที่ไม่พบรายการที่ตรงกัน จะส่งคืนสตริงว่าง
3. re.sub()
ฟังก์ชันแทนที่ข้อความที่ตรงกันด้วยเนื้อหาของตัวแปรแทนที่ที่กำหนด ตรงกันข้ามกับฟังก์ชันอื่นๆ หากไม่พบรูปแบบ สตริงเดิมจะถูกส่งคืน
4. วิจัย ()
หนึ่งในฟังก์ชันพื้นฐานที่ช่วยในการเรียนรู้วิธีแยกวิเคราะห์ข้อความคือฟังก์ชันการค้นหา ช่วยในการค้นหารูปแบบในสตริงและส่งคืนวัตถุที่ตรงกัน หากการค้นหาล้มเหลวในการระบุการจับคู่ จะไม่มีการคืนค่าใดๆ
5. คอมไพล์ใหม่ (แพทเทิร์น)
ฟังก์ชันนี้ใช้เพื่อรวบรวมรูปแบบนิพจน์ทั่วไปลงใน RegexObject ซึ่งได้กล่าวถึงก่อนหน้านี้
ข้อกำหนดอื่น ๆ
ข้อกำหนดที่ระบุไว้เป็นคุณสมบัติเพิ่มเติมที่ใช้โดยโปรแกรมเมอร์ขั้นสูงในการวิเคราะห์ข้อมูล
- เพื่อให้เห็นภาพนิพจน์ทั่วไป ใช้ regexper และ
- ในการทดสอบนิพจน์ทั่วไป จะใช้ regex101
อ่านเพิ่มเติม: วิธีติดตั้ง NumPy บน Windows 10
กระบวนการแยกวิเคราะห์ข้อความ

วิธีการแยกวิเคราะห์ข้อความในตัวเลือกที่ซับซ้อนนี้อธิบายไว้ด้านล่าง
- ขั้นตอนสำคัญที่สุดคือการทำความเข้าใจรูปแบบการป้อนข้อมูลโดยการอ่านเนื้อหาของไฟล์ ตัวอย่างเช่น ใช้ฟังก์ชัน with open และ read() เพื่อเปิดและอ่านเนื้อหาของไฟล์ที่ชื่อ sample ไฟล์ ตัวอย่าง มีเนื้อหาจากไฟล์ file.txt ; หากต้องการเรียนรู้วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ ไฟล์จะต้องอ่านให้ครบถ้วน
- เนื้อหาของไฟล์ถูกพิมพ์เพื่อวิเคราะห์ข้อมูลด้วยตนเองเพื่อค้นหาข้อมูลเมตาของค่า ที่นี่ใช้ฟังก์ชัน print() เพื่อพิมพ์เนื้อหาของไฟล์ ตัวอย่าง
- แพ็คเกจข้อมูลที่จำเป็นในการแยกวิเคราะห์ข้อความจะถูกนำเข้าไปยังโค้ด และตั้งชื่อให้กับคลาสสำหรับการเข้ารหัสเพิ่มเติม ที่นี่ นิพจน์ทั่วไป และ แพนด้า จะถูกนำเข้า
- นิพจน์ทั่วไปที่จำเป็นสำหรับโค้ดถูกกำหนดไว้ในไฟล์โดยรวมถึงรูปแบบ regex และฟังก์ชัน regex ซึ่งช่วยให้วัตถุข้อความหรือคลังข้อมูลนำรหัสไปวิเคราะห์ข้อมูลได้
- หากต้องการทราบวิธีแยกวิเคราะห์ข้อความ คุณสามารถอ้างอิงถึงโค้ดตัวอย่างที่ให้ไว้ที่นี่ ฟังก์ชัน compile() ใช้เพื่อรวบรวมสตริงจากกลุ่ม stringname1 ของ ชื่อไฟล์ ฟังก์ชันตรวจสอบการจับคู่ใน regex ถูกใช้โดยคำสั่ง ief_parse_line(line) ,
- ตัวแยกวิเคราะห์บรรทัดสำหรับโค้ดเขียนโดยใช้ def_parse_file(filepath) ซึ่งฟังก์ชันที่กำหนดไว้จะตรวจสอบ regex ที่ตรงกันทั้งหมดในฟังก์ชันที่ระบุ ที่นี่เมธอด regex search() จะค้นหาคีย์ rx ในชื่อไฟล์ ไฟล์ และส่งคืนคีย์และการจับคู่ของ regex ที่ตรงกันครั้งแรก ปัญหาใดๆ กับขั้นตอนนี้อาจนำไปสู่ข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x
- ขั้นตอนต่อไปคือการเขียน File Parser โดยใช้ฟังก์ชัน file parser ซึ่งก็คือ def_parse_file(filepath) รายการว่างถูกสร้างขึ้นเพื่อรวบรวมข้อมูลของรหัส เนื่องจาก data = [] การจับคู่จะถูกตรวจสอบที่แต่ละบรรทัดโดย การจับคู่ = _parse_line(line) และข้อมูลค่าที่แน่นอนจะถูกส่งคืนตามประเภทข้อมูล
- หากต้องการแยกตัวเลขและค่าของตาราง ให้ใช้คำสั่ง line.strip().split(',') คำสั่ง row{} ใช้เพื่อสร้างพจนานุกรมที่มีแถวข้อมูล คำสั่ง data.append(row) ใช้เพื่อทำความเข้าใจข้อมูลและแยกวิเคราะห์เป็นรูปแบบตาราง
คำสั่ง data = pd.DataFrame(data) ถูกใช้เพื่อสร้าง DataFrame แพนด้าจากค่า dict หรือคุณสามารถใช้คำสั่งต่อไปนี้เพื่อวัตถุประสงค์ที่เกี่ยวข้องตามที่ระบุไว้ด้านล่าง
- data.set_index(['string', 'integer'], inplace=True) เพื่อกำหนดดัชนีของตาราง
- data = data.groupby(level=data.index.names).first() เพื่อรวมและลบ nans
- data = data.apply(pd.to_numeric, errors='ignore') เพื่ออัปเกรดคะแนนจากค่าทศนิยมเป็นค่าจำนวนเต็ม
ขั้นตอนสุดท้ายในการทราบวิธีแยกวิเคราะห์ข้อความคือการทดสอบ parser โดยใช้ คำสั่ง if โดยการกำหนดค่าให้กับ ข้อมูล ตัวแปรและพิมพ์โดยใช้คำสั่ง print(data)
โค้ดตัวอย่างสำหรับคำอธิบายข้างต้นมีให้ที่นี่
ด้วย open('file.txt') เป็นตัวอย่าง:
sample_contents = sample.read()
พิมพ์ (sample_contents)
นำเข้าอีกครั้ง
นำเข้าแพนด้าเป็น pd
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line(บรรทัด):
สำหรับคีย์ rx ใน rx_filename.items():
ตรงกัน = rx.search(บรรทัด)
ถ้าตรงกัน:
คีย์กลับจับคู่
กลับไม่มี ไม่มี
def parse_file (เส้นทางของไฟล์):
ข้อมูล = []
ด้วย open(filepath, 'r') เป็น file_object:
บรรทัด = file_object.readline()
ในขณะที่สาย:
คีย์, จับคู่ = _parse_line(line)
ถ้าคีย์ == 'string1':
string = match.group('string1')
จำนวนเต็ม = int(string1)
value_type = match.group('string1')
บรรทัด = file_object.readline()
ในขณะที่ line.strip():
ตัวเลข ค่า = line.strip().split(',')
ค่า = ค่าแถบ ()
แถว = {
'Data1': string1,
'Data2': หมายเลข,
value_type: ค่า
}
data.append(แถว)
บรรทัด = file_object.readline()
บรรทัด = file_object.readline()
data = pd.DataFrame (ข้อมูล)
ส่งคืนข้อมูล
ถ้า _ _name_ _ = = '_ _main_ _':
filepath = 'sample.txt'
data = parse (พาธไฟล์)
พิมพ์ (ข้อมูล) 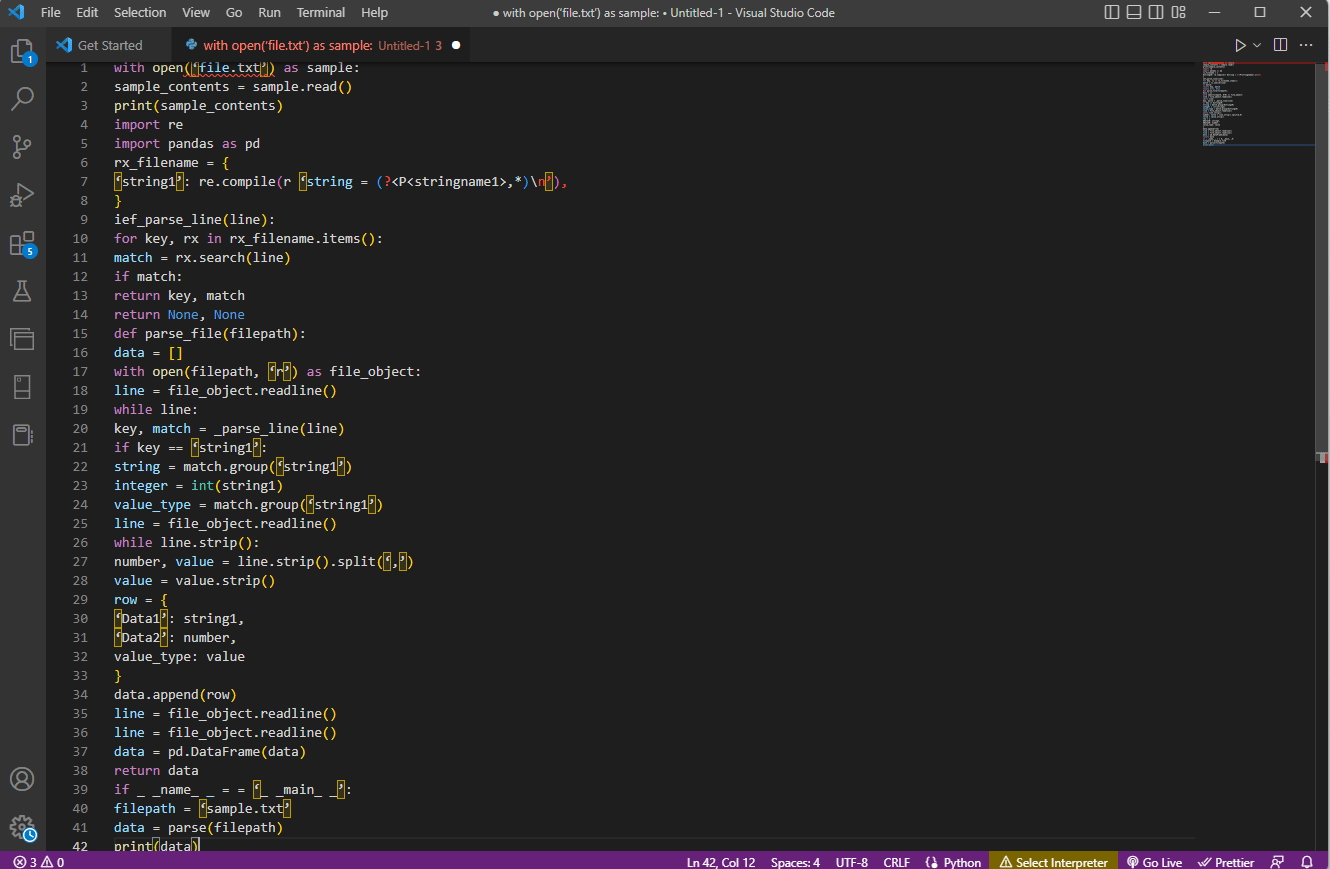
วิธีที่ 2: ผ่าน Word Tokenization
กระบวนการแปลงข้อความหรือคลังข้อมูลเป็นโทเค็นหรือชิ้นส่วนที่เล็กกว่าตามกฎบางอย่างเรียกว่า Tokenization หากต้องการเรียนรู้วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ จำเป็นต้องวิเคราะห์คำว่า tokenization commands ในโค้ด วิธีนี้คล้ายกับ regex คุณสามารถสร้างกฎของตัวเองได้ และช่วยในงานประมวลผลข้อความล่วงหน้า เช่น การจับคู่ส่วนของคำพูด นอกจากนี้ กิจกรรมต่างๆ เช่น การค้นหาและจับคู่คำทั่วไป การล้างข้อความ และการเตรียมข้อมูลให้พร้อมสำหรับเทคนิคการวิเคราะห์ข้อความขั้นสูง เช่น การวิเคราะห์ความคิดเห็น จะดำเนินการในวิธีนี้ หากการใช้โทเค็นไม่ถูกต้อง อาจเกิดข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x
ห้องสมุด Ntlk
กระบวนการนี้ได้รับความช่วยเหลือจากไลบรารีชุดเครื่องมือภาษายอดนิยมที่เรียกว่า nltk ซึ่งมีชุดฟังก์ชันมากมายสำหรับการทำงาน NLP จำนวนมาก สามารถดาวน์โหลดได้ผ่านแพ็คเกจการติดตั้ง Pip หรือ Pip หากต้องการทราบวิธีแยกวิเคราะห์ข้อความ คุณสามารถใช้ชุดฐานของการแจกจ่าย Anaconda ซึ่งรวมถึงไลบรารีโดยค่าเริ่มต้น
รูปแบบของ Tokenization
รูปแบบทั่วไปของวิธีการนี้คือ tokenization คำและ tokenization ประโยค เนื่องจากโทเค็นระดับคำ คำแรกจะพิมพ์คำเดียวเพียงครั้งเดียว ในขณะที่ชุดหลังพิมพ์คำที่ระดับประโยค
กระบวนการแยกวิเคราะห์ข้อความ
- ไลบรารีชุดเครื่องมือ ntlk ถูกนำเข้าและฟอร์มโทเค็นจะถูกนำเข้าจากไลบรารี
- มีการกำหนดสตริงและให้คำสั่งเพื่อดำเนินการโทเค็น
- ขณะที่พิมพ์สตริง ผลลัพธ์จะเป็น คอมพิวเตอร์เป็นคำ
- ในกรณีของ word tokenization หรือ word_tokenize() แต่ละคำในประโยคจะถูกพิมพ์แยกกันภายใน '' และ คั่นด้วยเครื่องหมายจุลภาค ผลลัพธ์ของคำสั่งจะเป็น 'คอมพิวเตอร์', 'คือ', 'ที่', 'คำ', '.'
- ในกรณีของการใช้ประโยค tokenization หรือ send_tokenize() แต่ละประโยคจะอยู่ภายใน '' และอนุญาตให้มีการทำซ้ำคำได้ ผลลัพธ์ของคำสั่งจะเป็น 'คอมพิวเตอร์คือคำ'
รหัสที่อธิบายขั้นตอนสำหรับการทำโทเค็นด้านบนมีให้ที่นี่
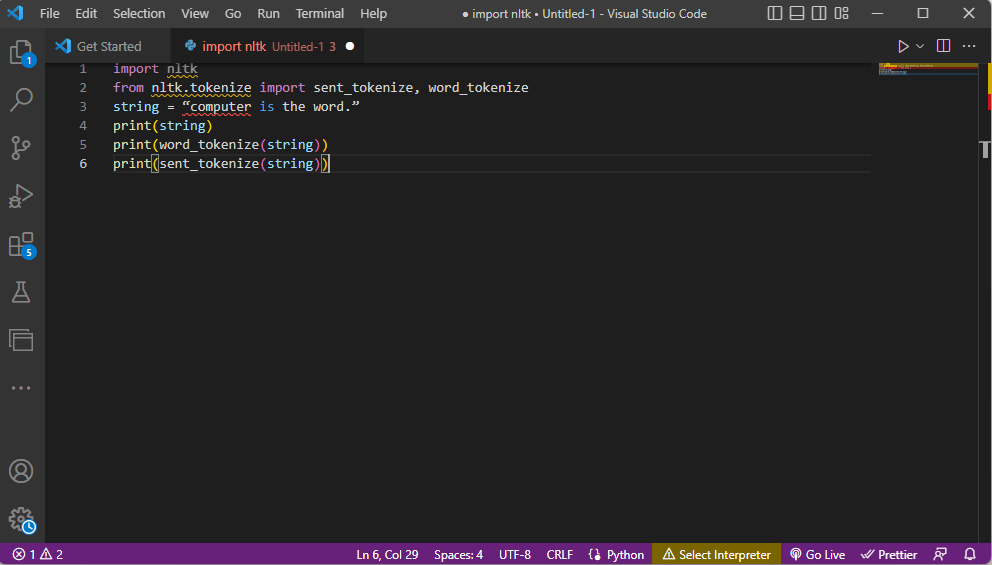
นำเข้า nltk จาก nltk.tokenize นำเข้า send_tokenize, word_tokenize string = "คอมพิวเตอร์คือคำ" พิมพ์ (สตริง) พิมพ์(word_tokenize(สตริง)) พิมพ์(sent_tokenize(สตริง))
อ่านเพิ่มเติม: วิธีแก้ไข javascript:void(0) Error
วิธีที่ 3: ผ่าน DocParser Class
เช่นเดียวกับ DataFrame Class คุณสามารถใช้ Class DocParser เพื่อแยกวิเคราะห์ข้อความในโค้ด คลาสอนุญาตให้คุณเรียกใช้ฟังก์ชัน parse ด้วยพาธไฟล์
กระบวนการแยกวิเคราะห์ข้อความ
หากต้องการทราบวิธีแยกวิเคราะห์ข้อความโดยใช้คลาส DocParser ให้ทำตามคำแนะนำด้านล่าง
- ฟังก์ชัน get_format(ชื่อไฟล์) ใช้เพื่อแยกนามสกุลไฟล์ ส่งคืนตัวแปรชุดสำหรับฟังก์ชัน และส่งผ่านไปยังฟังก์ชันถัดไป ตัวอย่างเช่น p1 = get_format(filename) จะแตกนามสกุลไฟล์ของ filename ตั้งค่าเป็นตัวแปร p1 และส่งไปยังฟังก์ชันถัดไป
- โครงสร้างเชิงตรรกะพร้อมฟังก์ชันอื่นๆ ถูกสร้างขึ้นโดยใช้คำสั่งและฟังก์ชัน if-elif-else
- หากนามสกุลไฟล์ถูกต้องและโครงสร้างเป็นตรรกะ ฟังก์ชัน get_parser จะใช้เพื่อแยกวิเคราะห์ข้อมูลในเส้นทางไฟล์และส่งคืนวัตถุสตริงให้กับผู้ใช้
หมายเหตุ: หากต้องการทราบวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ ฟังก์ชันนี้ต้องใช้งานอย่างถูกต้อง
- การแยกวิเคราะห์ค่าข้อมูลทำได้โดยใช้นามสกุลไฟล์ของไฟล์ การใช้งานคลาสที่เป็นรูปธรรมซึ่ง parse_txt หรือ parse_docx ใช้เพื่อสร้างวัตถุสตริงจากส่วนต่าง ๆ ของประเภทไฟล์ที่กำหนด
- การแยกวิเคราะห์สามารถทำได้สำหรับไฟล์ที่มีนามสกุลอื่นๆ ที่อ่านได้ เช่น parse_pdf , parse_html และ parse_pptx
- ค่าข้อมูลและอินเทอร์เฟซสามารถนำเข้าไปยังแอปพลิเคชันด้วยคำสั่งนำเข้าและสร้างอ็อบเจ็กต์ DocParser ซึ่งสามารถทำได้โดยแยกไฟล์ในภาษา Python เช่น parse_file.py การดำเนินการนี้ต้องทำอย่างระมัดระวังเพื่อหลีกเลี่ยงข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x
วิธีที่ 4: ผ่านเครื่องมือแยกวิเคราะห์ข้อความ
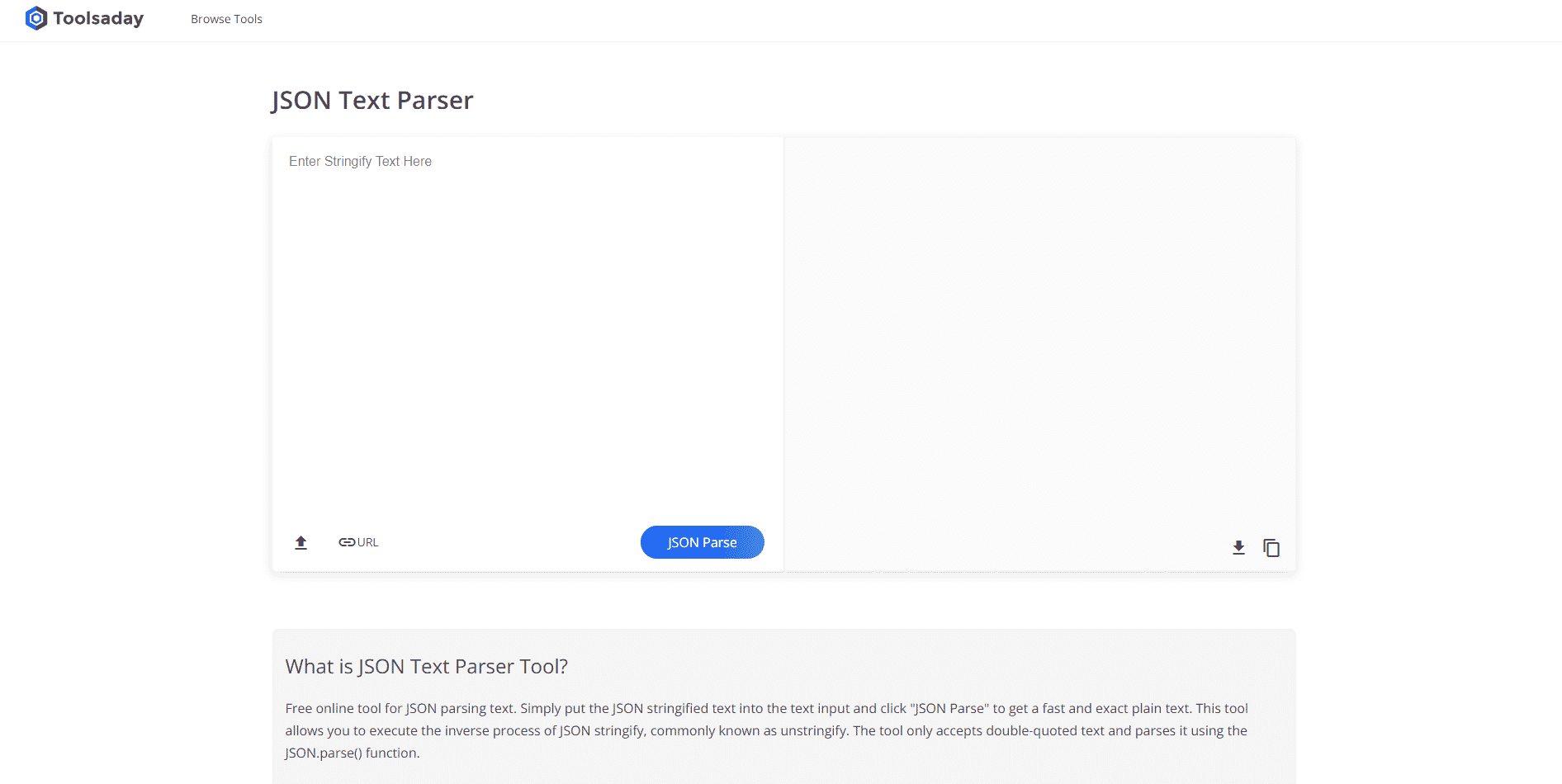
เครื่องมือ Parse text ใช้เพื่อดึงข้อมูลเฉพาะจากตัวแปรและจับคู่กับตัวแปรอื่นๆ สิ่งนี้ไม่ขึ้นกับเครื่องมืออื่นๆ ที่ใช้ในงาน และเครื่องมือแพลตฟอร์ม BPA ใช้เพื่อบริโภคและส่งออกตัวแปร ใช้ลิงก์ที่ให้ไว้ที่นี่เพื่อเข้าถึง Parse Text Tool ออนไลน์และใช้คำตอบที่ให้ไว้ก่อนหน้านี้เกี่ยวกับวิธีการแยกวิเคราะห์ข้อความ
วิธีที่ 5: ผ่าน TextFieldParser (Visual Basic)
TextFieldParser ใช้อ็อบเจ็กต์เพื่อแยกวิเคราะห์และประมวลผลไฟล์ขนาดใหญ่มากที่มีโครงสร้างและตัวคั่น ความกว้างและคอลัมน์ของข้อความ เช่น ไฟล์บันทึกหรือข้อมูลฐานข้อมูลดั้งเดิม สามารถใช้วิธีนี้ได้ วิธีการแยกวิเคราะห์คล้ายกับการวนซ้ำโค้ดบนไฟล์ข้อความ และส่วนใหญ่จะใช้เพื่อแยกฟิลด์ของข้อความที่คล้ายกับวิธีการจัดการสตริง สิ่งนี้ทำเพื่อโทเค็นสตริงที่คั่นและฟิลด์ที่มีความกว้างต่างๆ โดยใช้ตัวคั่นที่กำหนดไว้ เช่น เครื่องหมายจุลภาคหรือพื้นที่แท็บ
ฟังก์ชั่นการแยกวิเคราะห์ข้อความ
สามารถใช้ฟังก์ชันต่อไปนี้เพื่อแยกวิเคราะห์ข้อความในวิธีนี้
- ในการกำหนดตัวคั่น จะใช้ SetDelimiters ตัวอย่างเช่น คำสั่ง testReader.SetDelimiters (vbTab) ใช้เพื่อตั้งค่าพื้นที่ แท็บ เป็นตัวคั่น
- ในการตั้งค่าความกว้างของฟิลด์เป็นค่าจำนวนเต็มบวกเป็นความกว้างของฟิลด์คงที่ของไฟล์ข้อความ คุณสามารถใช้คำสั่ง testReader.SetFieldWidths (จำนวนเต็ม)
- ในการทดสอบประเภทฟิลด์ของข้อความ คุณสามารถใช้คำสั่งต่อไปนี้ testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth
วิธีการหา MatchObject
มีวิธีพื้นฐานสองวิธีในการค้นหา MatchObject ในโค้ดหรือข้อความที่แยกวิเคราะห์
- วิธีแรกคือการกำหนดรูปแบบและวนรอบไฟล์โดยใช้วิธี ReadFields วิธีนี้จะช่วยในการประมวลผลแต่ละบรรทัดของรหัส
- เมธอด PeekChars ใช้สำหรับตรวจสอบแต่ละฟิลด์ทีละฟิลด์ก่อนอ่าน กำหนดหลายรูปแบบ และตอบสนอง
ไม่ว่าในกรณีใด หากฟิลด์ไม่ตรงกับรูปแบบที่ระบุขณะดำเนินการแยกวิเคราะห์หรือค้นหาวิธีแยกวิเคราะห์ข้อความ ข้อยกเว้น MalformedLineException จะถูกส่งกลับ
เคล็ดลับแบบมือโปร: วิธีแยกวิเคราะห์ข้อความผ่าน MS Excel
เป็นวิธีสุดท้ายและง่ายในการแยกวิเคราะห์ข้อความ คุณสามารถใช้แอป MS Excel เป็นตัวแยกวิเคราะห์เพื่อสร้างไฟล์ที่คั่นด้วยแท็บและคั่นด้วยเครื่องหมายจุลภาค ซึ่งจะช่วยในการตรวจสอบผลการแยกวิเคราะห์ของคุณและช่วยในการค้นหาวิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์
1. เลือกค่าข้อมูลในไฟล์ต้นฉบับแล้วกดปุ่ม Ctrl + C พร้อมกันเพื่อคัดลอกไฟล์
2. เปิดแอป Excel โดยใช้แถบค้นหาของ windows
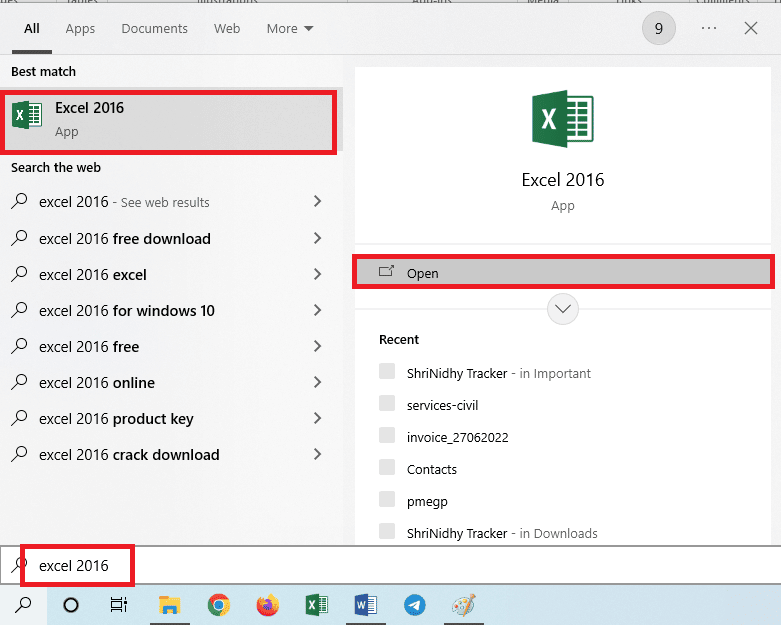
3. คลิกที่เซลล์ A1 และกดปุ่ม Ctrl + V พร้อมกันเพื่อวางข้อความที่คัดลอก
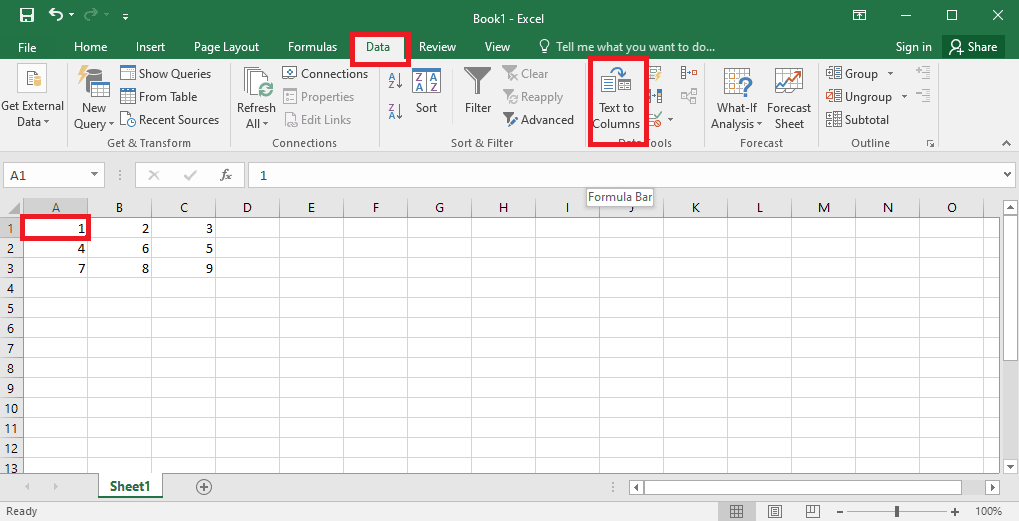
4. เลือกเซลล์ A1 ไปที่แท็บ ข้อมูล แล้วคลิกตัวเลือก ข้อความเป็นคอลัมน์ ในส่วน เครื่องมือข้อมูล
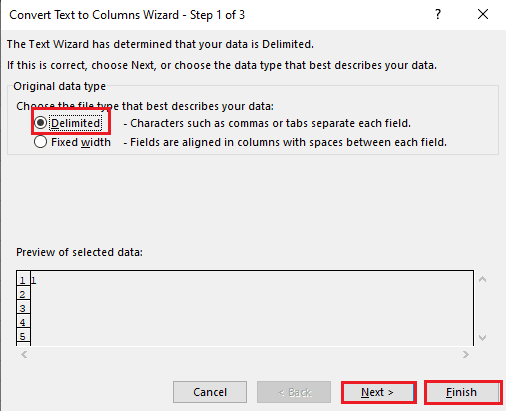
5ก. เลือกตัวเลือก ตัว คั่น หากใช้ เครื่องหมายจุลภาค หรือพื้นที่ แท็บ เป็นตัวคั่น แล้วคลิกปุ่ม ถัดไป และ เสร็จสิ้น
5B. เลือกตัวเลือก ความกว้างคง ที่ กำหนดค่าสำหรับตัวคั่น และคลิกที่ปุ่ม ถัดไป และ เสร็จสิ้น
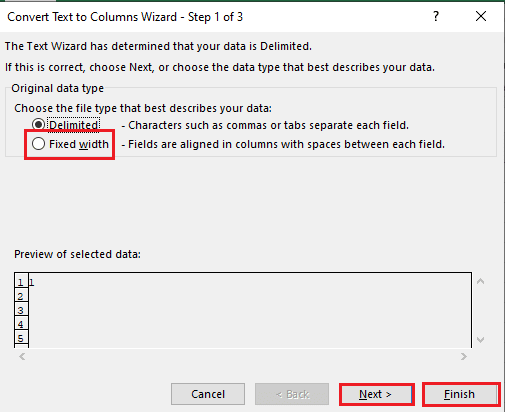
อ่านเพิ่มเติม: วิธีแก้ไขข้อผิดพลาดการย้ายคอลัมน์ Excel
วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์
ข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x อาจเกิดขึ้นบนอุปกรณ์ Android เช่น ข้อผิดพลาดในการแยกวิเคราะห์: มีปัญหาในการแยกวิเคราะห์แพ็คเกจ กรณีนี้มักเกิดขึ้นเมื่อติดตั้งแอปจาก Google Play Store ไม่สำเร็จหรือขณะใช้งานแอปของบุคคลที่สาม
ข้อความแสดงข้อผิดพลาด x อาจเกิดขึ้นหากรายการของเวกเตอร์อักขระเป็นแบบวนซ้ำ และฟังก์ชันอื่นๆ สร้างแบบจำลองเชิงเส้นสำหรับการคำนวณค่าข้อมูล ข้อความแสดงข้อผิดพลาดคือ Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^
คุณสามารถอ่านบทความเกี่ยวกับวิธีการแก้ไขข้อผิดพลาดในการแยกวิเคราะห์บน Android เพื่อเรียนรู้สาเหตุและวิธีการแก้ไขข้อผิดพลาด
นอกเหนือจากวิธีแก้ปัญหาในคู่มือแล้ว คุณสามารถลองแก้ไขดังต่อไปนี้
- ดาวน์โหลดไฟล์ .apk อีกครั้งหรือกู้คืนชื่อไฟล์
- การกู้คืนการเปลี่ยนแปลงในไฟล์ Androidmanifest.xml หากคุณมีทักษะการเขียนโปรแกรมระดับผู้เชี่ยวชาญ
ที่แนะนำ:
- วิธีลบบัญชี Facebook ของคนอื่น
- ทักษะ 10 อันดับแรกที่จำเป็นสำหรับการเป็นแฮ็กเกอร์ที่มีจริยธรรม
- 21 ทางเลือก Pastebin ที่ดีที่สุดในการแชร์รหัสและข้อความ
- คำสั่งแก้ไขล้มเหลวด้วยรหัสข้อผิดพลาด 1 Python Egg Info
บทความนี้ช่วยในการสอน วิธีแยกวิเคราะห์ข้อความ และเรียนรู้วิธีแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ แจ้งให้เราทราบว่าวิธีใดที่ช่วยแก้ไขข้อผิดพลาดในการแยกวิเคราะห์ข้อความ x และวิธีการแยกวิเคราะห์ที่ต้องการ กรุณาแบ่งปันข้อเสนอแนะและข้อสงสัยของคุณในส่วนความคิดเห็นด้านล่าง