
วิธีทำ OCR จากบรรทัดคำสั่ง Linux โดยใช้ Tesseract
เผยแพร่แล้ว: 2022-01-29
คุณสามารถแยกข้อความจากรูปภาพบนบรรทัดคำสั่ง Linux โดยใช้เอ็นจิน Tesseract OCR รวดเร็ว แม่นยำ และใช้งานได้ประมาณ 100 ภาษา นี่คือวิธีการใช้งาน
การรู้จำอักขระด้วยแสง
การรู้จำอักขระด้วยแสง (OCR) คือความสามารถในการดูและค้นหาคำในรูปภาพ แล้วแยกออกเป็นข้อความที่แก้ไขได้ งานง่าย ๆ สำหรับมนุษย์นี้เป็นเรื่องยากมากสำหรับคอมพิวเตอร์ที่จะทำ ความพยายามในช่วงแรกนั้นไม่ราบรื่นนัก คอมพิวเตอร์มักสับสนหากแบบอักษรหรือขนาดไม่เหมาะกับซอฟต์แวร์ OCR
อย่างไรก็ตาม ผู้บุกเบิกในสาขานี้ยังคงได้รับการยกย่องอย่างสูง หากคุณทำสำเนาอิเล็กทรอนิกส์ของเอกสารหาย แต่ยังมีฉบับพิมพ์อยู่ OCR สามารถสร้างเวอร์ชันอิเล็กทรอนิกส์ที่แก้ไขได้ขึ้นใหม่ แม้ว่าผลลัพธ์จะไม่ถูกต้อง 100 เปอร์เซ็นต์ แต่ก็ยังช่วยประหยัดเวลาได้มาก
เมื่อจัดเตรียมเอกสารด้วยตนเอง คุณก็จะได้เอกสารคืน ผู้คนต่างให้อภัยกับความผิดพลาดที่เกิดขึ้นเพราะพวกเขาเข้าใจความซับซ้อนของงานที่ต้องเผชิญกับแพ็คเกจ OCR นอกจากนี้ยังดีกว่าการพิมพ์เอกสารใหม่ทั้งหมดอีกครั้ง
สิ่งต่าง ๆ ดีขึ้นอย่างมากตั้งแต่นั้นมา แอปพลิเคชัน Tesseract OCR ซึ่งเขียนโดย Hewlett Packard เริ่มต้นในปี 1980 เป็นแอปพลิเคชันเชิงพาณิชย์ เป็นโอเพ่นซอร์สในปี 2548 และขณะนี้ได้รับการสนับสนุนจาก Google มีความสามารถหลายภาษา ถือได้ว่าเป็นระบบ OCR ที่แม่นยำที่สุดระบบหนึ่ง และคุณสามารถใช้งานได้ฟรี
การติดตั้ง Tesseract OCR
ในการติดตั้ง Tesseract OCR บน Ubuntu ให้ใช้คำสั่งนี้:
sudo apt-get ติดตั้ง tesseract-ocr

บน Fedora คำสั่งคือ:
sudo dnf ติดตั้ง tesseract

บน Manjaro คุณต้องพิมพ์:
sudo pacman -Syu tesseract

ใช้ Tesseract OCR
เรากำลังจะสร้างความท้าทายให้กับ Tesseract OCR ภาพแรกของเราที่มีข้อความเป็นข้อความที่คัดลอกมาจาก Recital 63 ของ General Data Protection Regulations มาดูกันว่า OCR สามารถอ่านสิ่งนี้ได้หรือไม่ (และตื่นอยู่)

เป็นภาพที่ดูยากเพราะแต่ละประโยคขึ้นต้นด้วยตัวเลขตัวยกจางๆ ซึ่งเป็นเรื่องปกติในเอกสารทางกฎหมาย
เราจำเป็นต้องให้ข้อมูลบางอย่างแก่คำสั่ง tesseract รวมถึง:
- ชื่อของไฟล์รูปภาพที่เราต้องการให้ประมวลผล
- ชื่อของไฟล์ข้อความที่จะสร้างเพื่อเก็บข้อความที่แยกออกมา เราไม่จำเป็นต้องระบุนามสกุลไฟล์ (จะเป็น .txt เสมอ) หากมีไฟล์ที่มีชื่อเดียวกันอยู่แล้ว ไฟล์นั้นจะถูกเขียนทับ
- เราสามารถใช้ตัวเลือก
--dpiเพื่อบอกtesseractว่าความละเอียดของภาพต่อจุดต่อนิ้ว (dpi) คืออะไร หากเราไม่ได้ระบุค่า dpi ไว้tesseractจะพยายามหาค่าออกมา
ไฟล์ภาพของเรามีชื่อว่า “recital-63.png” และมีความละเอียด 150 dpi เราจะสร้างไฟล์ข้อความจากไฟล์ที่เรียกว่า “recital.txt”
คำสั่งของเรามีลักษณะดังนี้:
tesseract recital-63.png บรรยาย --dpi 150

ผลลัพธ์ที่ได้จะดีมาก ปัญหาเดียวคือตัวยก—มันจางเกินกว่าจะอ่านได้อย่างถูกต้อง ภาพลักษณ์ที่ดีเป็นสิ่งสำคัญเพื่อให้ได้ผลลัพธ์ที่ดี

tesseract ได้ตีความตัวเลขตัวยกเป็นเครื่องหมายคำพูด (“) และสัญลักษณ์องศา (°) แต่ข้อความจริงถูกแยกออกมาอย่างสมบูรณ์ (ต้องตัดแต่งด้านขวาของภาพให้พอดีที่นี่)
อักขระสุดท้ายคือไบต์ที่มีค่าเลขฐานสิบหกเป็น 0x0C ซึ่งเป็นการขึ้นบรรทัดใหม่
ด้านล่างนี้เป็นรูปภาพอื่นที่มีข้อความขนาดต่างกัน ทั้งตัวหนาและตัวเอียง

ชื่อของไฟล์นี้คือ “bold-italic.png” เราต้องการสร้างไฟล์ข้อความชื่อ “bold.txt” ดังนั้นคำสั่งของเราคือ:
tesseract bold-italic.png ตัวหนา --dpi 150

สิ่งนี้ไม่ได้สร้างปัญหาใดๆ และข้อความก็ถูกดึงออกมาอย่างสมบูรณ์

การใช้ภาษาต่างๆ
Tesseract OCR รองรับประมาณ 100 ภาษา หากต้องการใช้ภาษา คุณต้องติดตั้งก่อน เมื่อคุณพบภาษาที่คุณต้องการใช้ในรายการ ให้สังเกตคำย่อของมัน เราจะติดตั้งการสนับสนุนสำหรับชาวเวลส์ ตัวย่อคือ "cym" ซึ่งย่อมาจาก "Cymru" ซึ่งแปลว่าเวลส์
แพ็คเกจการติดตั้งเรียกว่า “tesseract-ocr-” โดยมีตัวย่อภาษาติดแท็กไว้ที่ส่วนท้าย ในการติดตั้งไฟล์ภาษาเวลส์ใน Ubuntu เราจะใช้:
sudo apt-get ติดตั้ง tesseract-ocr-cym


รูปภาพพร้อมข้อความอยู่ด้านล่าง เป็นท่อนแรกของเพลงชาติเวลส์

มาดูกันว่า Tesseract OCR จะท้าทายหรือไม่ เราจะใช้ตัวเลือก -l (ภาษา) เพื่อให้ tesseract รู้ภาษาที่เราต้องการใช้งาน:
tesseract hen-wlad-fy-nhadau.png เพลงชาติ -l cym --dpi 150

tesseract ทำงานได้ดีดังแสดงในข้อความที่แยกด้านล่าง ดาวิน , Tesseract OCR.

ถ้าเอกสารของคุณมีสองภาษาขึ้นไป (เช่น พจนานุกรมภาษาเวลส์เป็นอังกฤษ) คุณสามารถใช้เครื่องหมายบวก ( + ) เพื่อบอกให้ tesseract เพิ่มภาษาอื่น เช่น
tesseract image.png ไฟล์ข้อความ -l eng+cym+fra
การใช้ Tesseract OCR กับ PDFs
คำสั่ง tesseract ออกแบบมาเพื่อทำงานกับไฟล์รูปภาพ แต่ไม่สามารถอ่าน PDF ได้ อย่างไรก็ตาม หากคุณต้องการแยกข้อความจาก PDF คุณสามารถใช้ยูทิลิตี้อื่นก่อนเพื่อสร้างชุดรูปภาพได้ รูปภาพเดียวจะแสดงหน้าเดียวของ PDF
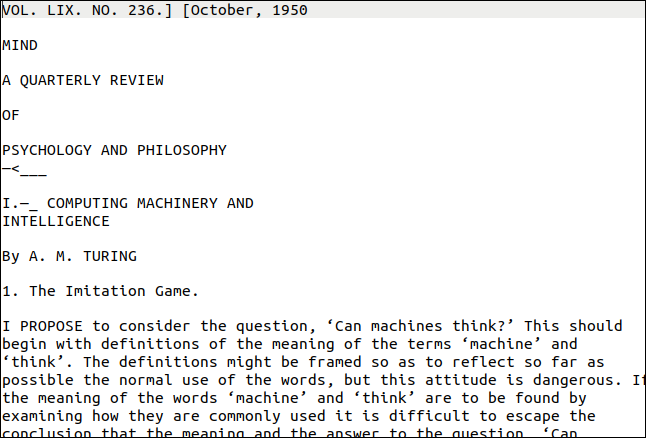
ยูทิลิตี้ pdftppm ที่คุณต้องการควรได้รับการติดตั้งในคอมพิวเตอร์ Linux ของคุณแล้ว PDF ที่เราจะใช้สำหรับตัวอย่างคือสำเนาเอกสารของ Alan Turing เกี่ยวกับปัญญาประดิษฐ์ "Computing Machinery and Intelligence"

เราใช้ตัวเลือก -png เพื่อระบุว่าเราต้องการสร้างไฟล์ PNG ชื่อไฟล์ PDF ของเราคือ “turing.pdf” เราจะเรียกไฟล์ภาพของเราว่า “turing-01.png,” “turing-02.png” และอื่นๆ:
pdftoppm -png turing.pdf ทัวริง

ในการรัน tesseract ในแต่ละไฟล์รูปภาพโดยใช้คำสั่งเดียว เราจำเป็นต้องใช้ for loop สำหรับไฟล์ “turing- nn .png” แต่ละไฟล์ที่เราเรียกใช้ tesseract และสร้างไฟล์ข้อความชื่อ “text-” บวกกับ “turing- nn ” โดยเป็นส่วนหนึ่งของชื่อไฟล์รูปภาพ:
สำหรับฉันในทัวริง-??.png; ทำ tesseract "$i" "text-$i" -l eng; เสร็จแล้ว;

ในการรวมไฟล์ข้อความทั้งหมดเป็นไฟล์เดียว เราสามารถใช้ cat :
cat text-turing* > complete.txt

แล้วมันทำอย่างไร? ดีมากดังที่คุณเห็นด้านล่าง หน้าแรกดูค่อนข้างท้าทายแม้ว่า มันมีรูปแบบและขนาดข้อความที่แตกต่างกันและการตกแต่ง นอกจากนี้ยังมี "ลายน้ำ" แนวตั้งที่ขอบด้านขวาของหน้า
อย่างไรก็ตามเอาต์พุตใกล้เคียงกับต้นฉบับ เห็นได้ชัดว่าการจัดรูปแบบหายไป แต่ข้อความถูกต้อง
ลายน้ำแนวตั้งถูกคัดลอกเป็นบรรทัดที่ไม่มีความหมายที่ด้านล่างของหน้า ข้อความมีขนาดเล็กเกินกว่าจะอ่านโดย tesseract ได้อย่างถูกต้อง แต่จะง่ายต่อการค้นหาและลบออก ผลลัพธ์ที่แย่ที่สุดคืออักขระจรจัดที่ส่วนท้ายของแต่ละบรรทัด
น่าแปลกที่ตัวอักษรตัวเดียวที่จุดเริ่มต้นของรายการคำถามและคำตอบในหน้าสองถูกละเลย ส่วนจาก PDF แสดงอยู่ด้านล่าง

ดังที่คุณเห็นด้านล่าง คำถามยังคงอยู่ แต่ "Q" และ "A" ที่จุดเริ่มต้นของแต่ละบรรทัดหายไป

ไดอะแกรมจะไม่สามารถถอดเสียงได้อย่างถูกต้อง มาดูกันว่าจะเกิดอะไรขึ้นเมื่อเราพยายามดึงข้อมูลที่แสดงด้านล่างออกจาก Turing PDF

ดังที่คุณเห็นในผลลัพธ์ของเราด้านล่าง มีการอ่านอักขระ แต่รูปแบบของไดอะแกรมหายไป

อีกครั้ง tesseract ต่อสู้กับขนาดที่เล็กของตัวห้อยและแสดงผลอย่างไม่ถูกต้อง
แม้ว่าในทางธรรม ก็ยังเป็นผลดีอยู่ เราไม่สามารถแยกข้อความที่ตรงไปตรงมาได้ แต่จากนั้น ตัวอย่างนี้ได้รับการคัดเลือกอย่างจงใจเนื่องจากเป็นการท้าทาย
ทางออกที่ดีเมื่อคุณต้องการ
OCR ไม่ใช่สิ่งที่คุณจำเป็นต้องใช้ทุกวัน อย่างไรก็ตาม เมื่อมีความจำเป็น คุณควรทราบว่าคุณมีเครื่องยนต์ OCR ที่ดีที่สุดตัวหนึ่งพร้อมใช้