
Что такое обработка естественного языка и как она работает?
Опубликовано: 2022-01-29
Обработка естественного языка позволяет компьютерам преобразовывать то, что мы говорим, в команды, которые он может выполнять. Узнайте, как это работает и как оно используется для улучшения нашей жизни.
Что такое обработка естественного языка?
Будь то Alexa, Siri, Google Assistant, Bixby или Cortana, у каждого, у кого есть смартфон или смарт-динамик, в настоящее время есть голосовой помощник. Кажется, что с каждым годом эти голосовые помощники лучше распознают и выполняют то, что мы им приказываем. Но задумывались ли вы когда-нибудь, как эти помощники обрабатывают то, что мы говорим? Им удается это делать благодаря обработке естественного языка или НЛП.
Исторически сложилось так, что большая часть программного обеспечения могла реагировать только на фиксированный набор конкретных команд. Файл откроется, потому что вы нажали «Открыть», или электронная таблица вычислит формулу на основе определенных символов и имен формул. Программа общается, используя язык программирования, на котором она была закодирована, и, таким образом, будет производить вывод, когда ей будет предоставлен ввод, который она распознает. В этом контексте слова подобны набору различных механических рычагов, которые всегда обеспечивают желаемый результат.
Это контрастирует с человеческими языками, которые сложны, неструктурированы и имеют множество значений в зависимости от структуры предложения, тона, акцента, времени, пунктуации и контекста. Обработка естественного языка — это ветвь искусственного интеллекта, которая пытается преодолеть разрыв между тем, что машина распознает как ввод, и человеческим языком. Это делается для того, чтобы, когда мы говорим или печатаем естественным образом, машина производила вывод в соответствии с тем, что мы сказали.
Это делается путем использования огромного количества точек данных для получения значения из различных элементов человеческого языка поверх значений реальных слов. Этот процесс тесно связан с концепцией, известной как машинное обучение, которая позволяет компьютерам узнавать больше по мере получения большего количества точек данных. Вот почему большинство машин для обработки естественного языка, с которыми мы часто взаимодействуем, со временем становятся лучше.
Чтобы лучше осветить концепцию, давайте рассмотрим две самые высокоуровневые техники, используемые в НЛП для обработки языка и информации.
СВЯЗАННЫЙ: Проблема с ИИ: машины изучают вещи, но не могут их понять
Токенизация

Токенизация означает разделение речи на слова или предложения. Каждый фрагмент текста — это токен, и именно эти токены появляются при обработке вашей речи. Звучит просто, но на практике это сложный процесс.
Предположим, вы используете программное обеспечение для преобразования текста в речь, такое как Google Keyboard, для отправки сообщения другу. Вы хотите написать: «Встретимся в парке». Когда ваш телефон берет эту запись и обрабатывает ее с помощью алгоритма преобразования текста в речь Google, Google должен разделить то, что вы только что сказали, на токены. Этими токенами будут «встреча», «я», «в», «в» и «парк».

У людей разная длина пауз между словами, а в других языках может быть не так уж мало слышимых пауз между словами. Процесс токенизации сильно различается между языками и диалектами.
Стемминг и лемматизация
И стемминг, и лемматизация включают в себя процесс удаления дополнений или вариаций корневого слова, которые машина может распознать. Это делается для того, чтобы сделать интерпретацию речи последовательной для разных слов, которые по сути означают одно и то же, что ускоряет обработку НЛП.
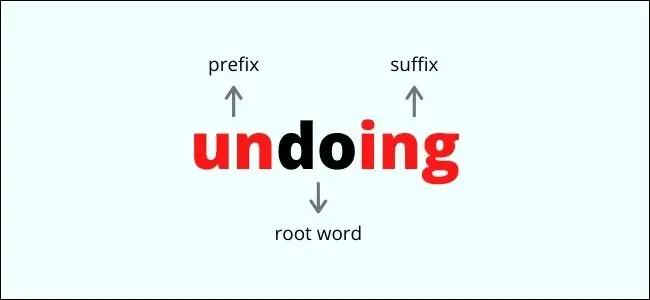
Stemming — это грубый быстрый процесс, который включает удаление аффиксов из корневого слова, которые являются дополнениями к слову, прикрепленному до или после корня. Это превращает слово в простейшую базовую форму, просто удаляя буквы. Например:
- «Ходьба» превращается в «прогулку»
- «Быстрее» превращается в «быстрее»
- «Серьезность» превращается в «серьезность»
Как видите, определение основы может иметь неблагоприятный эффект, полностью изменяя значение слова. «Severity» и «sever» означают не одно и то же, но суффикс «ity» был удален в процессе образования корня.
С другой стороны, лемматизация — это более сложный процесс, включающий преобразование слова в его основу, известную как лемма. При этом учитывается контекст слова и то, как оно используется в предложении. Это также включает в себя поиск термина в базе данных слов и соответствующей леммы. Например:
- «Есть» превращается в «быть»
- «Операция» превращается в «эксплуатация».
- «Тяжесть» превращается в «суровость»
В этом примере лемматизации удалось превратить термин «серьезность» в «серьезность», что является его леммной формой и корнем слова.
Варианты использования НЛП и будущее
Предыдущие примеры только начинают царапать поверхность того, что такое обработка естественного языка. Он охватывает широкий спектр практик и сценариев использования, многие из которых мы используем в повседневной жизни. Вот несколько примеров того, где в настоящее время используется НЛП:
- Интеллектуальный текст: когда вы печатаете сообщение на своем смартфоне, он автоматически предлагает вам слова, которые вписываются в предложение или которые вы использовали ранее.
- Машинный перевод: широко используемые услуги потребительского перевода, такие как Google Translate, для включения высокоуровневой формы НЛП для обработки языка и его перевода.
- Чат- боты: NLP является основой для интеллектуальных чат-ботов, особенно в сфере обслуживания клиентов, где они могут помогать клиентам и обрабатывать их запросы до того, как они столкнутся с реальным человеком.
Это еще не все. Использование НЛП в настоящее время разрабатывается и внедряется в таких областях, как средства массовой информации, медицинские технологии, управление рабочим местом и финансы. Есть шанс, что в будущем мы сможем вести полноценный сложный разговор с роботом.
Если вы хотите узнать больше о NLP, вы можете ознакомиться с множеством фантастических ресурсов в блоге Towards Data Science или в Standford National Language Processing Group.