
Как работает поисковая система и делает вашу жизнь проще?
Опубликовано: 2015-11-06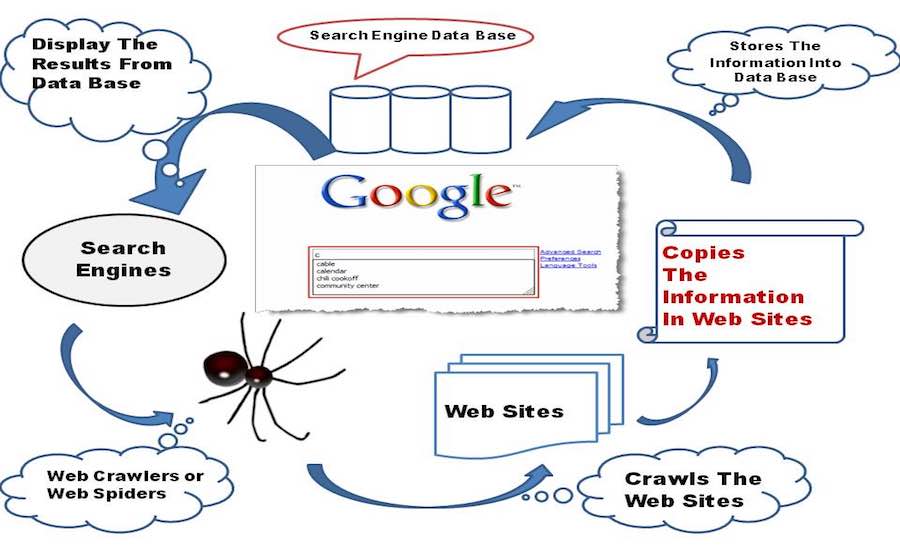 Short Bytes: Search Engine — это программное обеспечение, которое позволяет отображать релевантные результаты веб-страницы на основе введенного поискового запроса с использованием веб-сканирования и веб-индексирования, некоторых сложных формул и интеллектуальных алгоритмов для сбора соответствующих данных.
Short Bytes: Search Engine — это программное обеспечение, которое позволяет отображать релевантные результаты веб-страницы на основе введенного поискового запроса с использованием веб-сканирования и веб-индексирования, некоторых сложных формул и интеллектуальных алгоритмов для сбора соответствующих данных.
Как Google предоставляет вам лучшие результаты в мгновение ока? На самом деле, это не имеет значения, пока не появятся Google, Bing. Сценарий был бы совсем другим, если бы не Google, Bing или Yahoo. Давайте погрузимся в мир поисковых систем и посмотрим, как работает поисковая система.
Заглядывая в историю
Сказка о поисковых системах началась в 1990-х годах, когда Тим Бернерс-Ли зачислял каждый новый веб-сервер, выходящий в сеть, в список, поддерживаемый веб-сервером CERN. До сентября 93 года в Интернете не существовало поисковых систем, а было лишь несколько инструментов, способных вести базу данных имен файлов. Арчи, Вероника, Джагхед были самыми первыми участниками этой категории.
Оскар Нирстраз из Женевского университета аккредитован на разработку самой первой поисковой системы под названием W3Catalog. Он написал несколько серьезных сценариев на Perl и, наконец, 3 сентября 1993 года выпустил первую в мире поисковую систему. Кроме того, в 1993 году появилось множество других поисковых систем. JumpStation от Джонатона Флетчера, AliWeb, WWW Worm и т. д. Yahoo! был запущен в 1995 году как веб-каталог, но он начал использовать поисковую систему Inktomi с 2000 года, а затем перешел на Microsoft Bing в 2009 году.
Теперь, говоря о названии, которое является основным синонимом термина поисковая система, поиск Google, был исследовательским проектом двух выпускников Стэнфорда, Ларри Пейджа и Серджи Брина, начавшего свою деятельность в марте 1995 года. Работа Google изначально была вдохновлена с помощью метода обратных ссылок Пейджа, который проводил расчеты на основе количества обратных ссылок, исходящих с веб-страницы, чтобы измерить важность этой страницы во всемирной паутине. «Лучший совет, который я когда-либо получал», — сказал Пейдж, вспоминая, как его руководитель Терри Виноград поддержал его идею. И с тех пор Google никогда не оглядывался назад.
Все начинается с обхода
Новорожденная поисковая система в зачаточном состоянии начинает изучать Всемирную паутину, своими маленькими ручонками и коленками она исследует все остальные ссылки, которые находит на веб-странице, и сохраняет их в своей базе данных.
Теперь давайте сосредоточимся на некоторых закулисных технических мыслях: поисковая система включает в себя программное обеспечение Web Crawler, которое в основном представляет собой интернет-бот, которому поручено открывать все гиперссылки, присутствующие на веб-странице, и создавать базу данных текста и метаданных из всех ссылок. . Он начинается с начального набора ссылок для посещения, который называется Seeds. Как только он переходит к посещению этих ссылок, добавляет новые ссылки в существующий список URL-адресов для посещения, известный как Crawl Frontier.
По мере того, как Crawler проходит по ссылкам, он загружает информацию с этих веб-страниц, чтобы просмотреть их позже в виде снимков, поскольку для загрузки всей веб-страницы потребуется много данных, и это обходится по карманной цене, по крайней мере в странах, как Индия. И я могу поспорить, если бы Google был основан в Индии, все их деньги были бы использованы для оплаты счетов за интернет. Надеюсь, сейчас это не тема для беспокойства.
Веб-сканер исследует веб-страницы на основе некоторых политик:
Политика выбора: Краулер решает, какие страницы он должен загружать, а какие нет. Политика выбора направлена на загрузку наиболее релевантного содержимого веб-страницы, а не некоторых неважных данных.
Политика повторного посещения: Краулер планирует время, когда он должен повторно открывать веб-страницы и редактировать изменения в своей базе данных, благодаря динамическому характеру Интернета, из-за которого сканерам очень сложно оставаться в курсе последних версий. веб-страницы.
Политика параллелизации: поисковые роботы используют несколько процессов одновременно для просмотра ссылок, известных как распределенное сканирование, но иногда существует вероятность того, что разные процессы могут загружать одну и ту же веб-страницу, поэтому сканер поддерживает координацию между всеми процессами, чтобы исключить любые шансы двуличие.
Политика вежливости: когда сканер просматривает веб-сайт, он одновременно загружает с него веб-страницы, тем самым увеличивая нагрузку на веб-сервер, на котором размещен веб-сайт. Следовательно, реализован термин «Crawl-Delay», при котором сканер должен ждать несколько секунд после того, как он загрузит некоторые данные с веб-сервера, и регулируется политикой вежливости.
Читайте также: Как создать базовый веб-краулер на Python
Высокоуровневая архитектура стандартного веб-краулера:
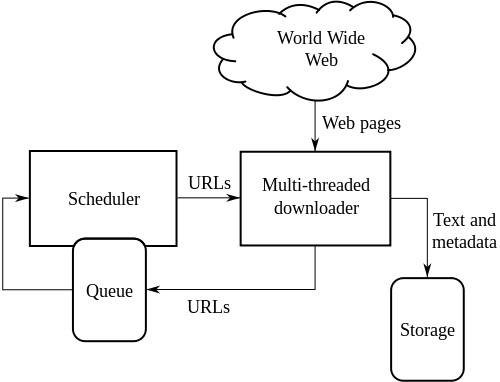
На приведенном выше рисунке показано, как работает поисковый робот. Он открывает первоначальный список ссылок, а затем ссылки внутри этих ссылок и так далее.
Википедия пишет, что исследователи информатики Владислав Шкапенюк и Торстен Суэль отметили, что:
Хотя довольно легко создать медленный поисковый робот, который загружает несколько страниц в секунду в течение короткого периода времени, создание высокопроизводительной системы, которая может загружать сотни миллионов страниц в течение нескольких недель, сопряжено с рядом проблем при проектировании системы. Эффективность ввода-вывода и сети, надежность и управляемость.
Индексирование сканирования
После того, как детская поисковая система просканирует весь Интернет, она создает индекс всех веб-страниц, которые находит на своем пути. Наличие индекса намного лучше, чем тратить время на поиск поискового запроса в куче документов большого размера, это сэкономит и время, и ресурсы.
Есть много факторов, которые способствуют созданию эффективной системы индексации для поисковой системы. Методы хранения, используемые индексаторами, размер индекса, возможность быстрого поиска документов, содержащих искомые ключевые слова, и т. д. являются факторами, определяющими эффективность и надежность индекса.
Одним из основных препятствий на пути создания успешных веб-индексов является столкновение двух процессов. Скажем, один процесс хочет найти документ, и в то же время другой процесс хочет добавить документ в индекс, что создает конфликт между двумя процессами. Проблема усугубляется реализацией распределенных вычислений поисковыми системами для обработки большего количества данных.
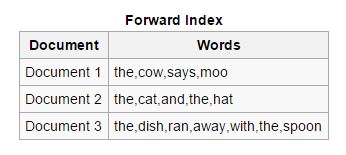
Типы индексов
Вперед: в индексах этого типа все ключевые слова, присутствующие в документе, хранятся в списке. Прямой индекс легко создать на начальном этапе индексации, поскольку он позволяет асинхронным индексаторам взаимодействовать друг с другом.

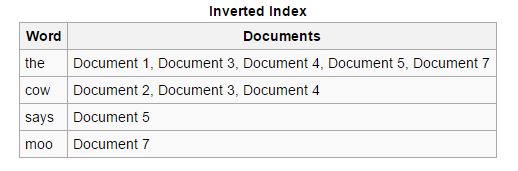
Обратный: прямые индексы сортируются и преобразуются в обратные индексы, в которых каждый документ, содержащий определенное ключевое слово, объединяется с другими документами, содержащими это ключевое слово. Обратные индексы упрощают процесс поиска релевантных документов для заданного поискового запроса, чего нельзя сказать о прямых индексах.
Читайте также: Что такое DNS (система доменных имен) и как она работает?
Парсинг документов
Также называемая токенизацией, относится к разбивке компонентов документа, таких как ключевые слова (называемые токенами), изображения и другие носители, чтобы их можно было позже вставить в индексы. Этот метод в основном фокусируется на понимании родного языка и прогнозировании ключевых слов, которые пользователь может искать, что служит основой для создания эффективной системы веб-индексирования.
Основные проблемы включают определение границ слов для ключевых слов, которые необходимо извлечь, поскольку мы видим, что такие языки, как китайский и японский, обычно не имеют пробелов в своих языковых скриптах. Понимание двусмысленности, которой обладает язык, также вызывает беспокойство, поскольку некоторые языки начинают незначительно или даже значительно отличаться с географическими изменениями. Кроме того, неэффективность некоторых веб-страниц из-за отсутствия четкого упоминания используемого языка также вызывает озабоченность и увеличивает нагрузку на индексаторов.
Поисковые системы имеют возможность распознавать различные форматы файлов и успешно извлекать из них данные, и в этих случаях необходимо соблюдать предельную осторожность.
Мета-теги также очень полезны для быстрого создания индексов, они сокращают усилия веб-индексатора и облегчают необходимость полного анализа всего документа. Вы найдете метатеги, прикрепленные внизу этой статьи.
Поиск по индексу
Теперь малыш-поисковик уже не младенец, он научился, как ползать и как быстро и эффективно хватать вещи, как систематизировать свои вещи. Предположим, его друг попросит его найти что-то из его аранжировки, что он будет делать? В настоящее время используются четыре типа поисковых запросов, хотя формально они не являются производными, но они развивались с течением времени, и было обнаружено, что они верны с точки зрения реальных запросов, сделанных пользователями.
Навигационные: этот термин используется для тех запросов, в которых пользователь хочет перейти на определенную веб-страницу или веб-сайт, существующий в Интернете. Например, когда вы ищете fossBytes в Google, вы инициируете навигационный запрос.
Информационные: этот тип запросов имеет тысячи результатов и охватывает общие темы, которые расширяют знания пользователя. Например, когда вы ищете, скажем, Стива Джобса, вам будут представлены все ссылки, относящиеся к Стиву Джобсу.
Транзакционные: запросы, ориентированные на намерение пользователя выполнить определенное действие, могут включать заранее определенный набор инструкций. Например, как найти потерянный/украденный ноутбук?
Связность: запросы такого типа используются нечасто, они сосредоточены на том, насколько связан индекс, созданный с веб-сайта. Например, если вы ищете, сколько страниц в Википедии?
Google и Bing создали несколько серьезных алгоритмов, способных определить наиболее релевантные результаты для вашего запроса. Google утверждает, что рассчитывает ваши результаты поиска на основе более 200 факторов, таких как качество контента, новый или старый, безопасность веб-страницы и многое другое. В их поисковых лабораториях назначены величайшие умы мира, которые выполняют трудные расчеты и имеют дело с умопомрачительными формулами только для того, чтобы сделать поиск для вас более простым и быстрым.
Другие примечательные особенности*
Поиск изображений. Вы будете удивлены, узнав, что Google вдохновил их знаменитый инструмент поиска изображений. Джей Ло, да, вы не ослышались, Джей Ло и ее зеленое платье Versace (ver-sah-chay) на церемонии вручения премии «Грэмми» в 2000 году были настоящей причиной, по которой Google выпустил свой поиск изображений, поскольку люди были заняты гуглением. ее.
Сказал Эрик Шмидт в своем сочинении под названием «Ученик ремесленника», опубликованном 19 января 2015 года.
Голосовой поиск: Google был первым, кто внедрил голосовой поиск в своей поисковой системе после большой тяжелой работы, и впоследствии другие поисковые системы также внедрили его.
Борьба со спамом. Поисковые системы используют несколько серьезных алгоритмов, чтобы защитить вас от спам-атак . Спам — это в основном сообщение или файл, который распространяется по всему Интернету, может быть, для рекламы или для передачи вирусов. В этом вопросе также ребята из Google вручную информируют веб-сайт, который, по их мнению, несет ответственность за распространение спам-сообщений в Интернете.
Оптимизация местоположения: поисковые системы теперь могут отображать результаты в зависимости от местоположения пользователя. Если искать «Какая погода в Бангалоре», то статистика погоды будет со ссылкой на Бангалор.
Лучше понимает вас: современные поисковые системы способны понимать значение пользовательского запроса, а не находить ключевые слова, введенные пользователем.
Автозаполнение : возможность прогнозировать ваш поисковый запрос по мере ввода на основе ваших предыдущих поисков и поисков, выполненных другими пользователями.
График знаний: эта функция, предоставляемая поиском Google, демонстрирует свою способность предоставлять результаты поиска на основе реальных людей, мест и событий.
Родительский контроль. Поисковые системы позволяют родителям маленьких детей контролировать, чем занимается их ребенок в Интернете.
* Трудно охватить обширный список функций, предоставляемых этими мощными поисковыми системами.
Завершение
Поисковые системы внесли свой вклад в то, чтобы сделать нашу жизнь проще, и тяжелая работа, которую они проделали, чтобы использовать всю информацию в Интернете, бесценна. Но это исследование привело к тому, что наше личное пространство было выставлено на всеобщее обозрение, и я должен сказать, что пора нам побеспокоиться о пути, который мы проходим все это время, если только нам еще не поздно оглядываться назад на наши действия. и наша жизнь будет лишь биеннале смущений. Мы не можем отрицать тот факт, что поисковые системы теперь являются жизненно важной частью нашего цифрового раздвоения личности. Нам нужно только использовать данную нам технологию, а не позволять ей поработить нас в цепях наших собственных злодеяний.
Ладно, хватит эмоциональных разговоров, просто обожаю миловидность и таланты этого малыша-поисковика, который теперь стал подростком и понимает вас гораздо лучше. Google был там, чтобы искать все для нас, для многих из нас это Интернет, и мы должны дорожить тем хорошим опытом, который мы заработали, используя поиск Google. Ой! Я забыл упомянуть Бинга, ты тоже классный. Будьте бдительны, оставайтесь в безопасности и погуглите.
Посмотрите это видео и узнайте больше о поисковых системах:
Вы когда-нибудь нажимали кнопку «Мне повезет » в поиске Google. Откройте его и расскажите нам, какой дудл вам понравился больше всего в разделе комментариев ниже.