
Как анализировать данные CSV в Bash
Опубликовано: 2022-09-16
Файлы со значениями, разделенными запятыми (CSV), являются одним из наиболее распространенных форматов для экспортируемых данных. В Linux мы можем читать файлы CSV с помощью команд Bash. Но это может стать очень сложным, очень быстро. Мы протянем руку помощи.
Что такое CSV-файл?
Файл значений, разделенных запятыми, представляет собой текстовый файл, содержащий табличные данные. CSV — это тип данных с разделителями. Как следует из названия, запятая « , » используется для отделения каждого поля данных — или значения — от его соседей.
CSV везде. Если приложение имеет функции импорта и экспорта, оно почти всегда будет поддерживать CSV. Файлы CSV удобочитаемы. Вы можете заглянуть внутрь них с меньшими затратами, открыть их в любом текстовом редакторе и переместить из программы в программу. Например, вы можете экспортировать данные из базы данных SQLite и открыть их в LibreOffice Calc.
Однако даже CSV может стать сложным. Хотите иметь запятую в поле данных? Это поле должно быть заключено в кавычки " " ". Чтобы включить кавычки в поле, необходимо ввести каждую кавычку дважды.
Конечно, если вы работаете с CSV, сгенерированным написанной вами программой или сценарием, формат CSV, скорее всего, будет простым и понятным. Если вы вынуждены работать с более сложными форматами CSV, а Linux — это Linux, есть решения, которые мы можем использовать и для этого.
Некоторые примеры данных
Вы можете легко создать некоторые образцы данных CSV, используя такие сайты, как Online Data Generator. Вы можете определить нужные поля и выбрать, сколько строк данных вы хотите. Ваши данные генерируются с использованием реалистичных фиктивных значений и загружаются на ваш компьютер.
Мы создали файл, содержащий 50 строк фиктивной информации о сотрудниках:
- id : Простое уникальное целочисленное значение.
- firstname : Имя человека.
- lastname : Фамилия человека.
- job-title : Должность человека.
- адрес электронной почты : адрес электронной почты человека.
- branch : Филиал компании, в котором они работают.
- state : состояние, в котором находится ветка.
Некоторые файлы CSV имеют строку заголовка, в которой перечислены имена полей. В нашем образце файл есть один. Вот верхняя часть нашего файла:
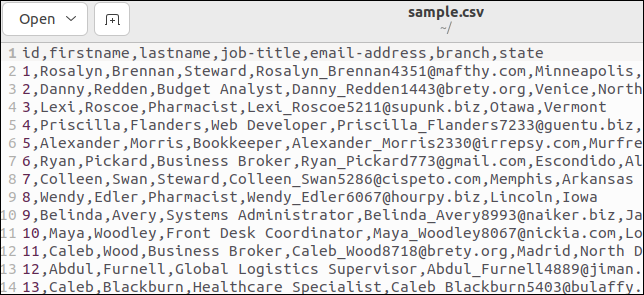
Первая строка содержит имена полей в виде значений, разделенных запятыми.
Разбор данных из файла CSV
Давайте напишем скрипт, который будет читать файл CSV и извлекать поля из каждой записи. Скопируйте этот сценарий в редактор и сохраните его в файл с именем «field.sh».
#! /бин/баш в то время как IFS="," read -r id имя фамилия должность электронная почта филиал состояние делать echo "Идентификатор записи: $id" эхо "Имя: $firstname" эхо "Фамилия: $lastname" echo "Название должности: $jobtitle" echo "Добавить адрес электронной почты: $email" эхо "Ветка: $ветка" эхо "Состояние: $state" эхо "" сделано < <(хвост -n +2 образец.csv)
В нашем маленьком сценарии довольно много всего. Давайте сломаем это.

Мы используем цикл while . Пока условие цикла while принимает значение true, будет выполняться тело цикла while . Тело цикла довольно простое. Набор операторов echo используется для вывода значений некоторых переменных в окно терминала.
Условие цикла while более интересно, чем тело цикла. Мы указываем, что запятая должна использоваться в качестве внутреннего разделителя полей, с оператором IFS="," . IFS — это переменная среды. Команда read обращается к своему значению при разборе последовательности текста.
Мы используем параметр -r (сохранять обратную косую черту) команды read , чтобы игнорировать любые обратные косые черты, которые могут быть в данных. Они будут рассматриваться как обычные персонажи.
Текст, анализируемый командой read , хранится в наборе переменных, названных в соответствии с полями CSV. С таким же успехом их можно было бы назвать field1, field2, ... field7 , но осмысленные имена облегчают жизнь.
Данные получаются на выходе команды tail . Мы используем tail , потому что это дает нам простой способ пропустить строку заголовка CSV-файла. Опция -n +2 (номер строки) указывает tail начать чтение со второй строки.
Конструкция <(...) называется подстановкой процесса. Это заставляет Bash принимать выходные данные процесса, как если бы они исходили из файлового дескриптора. Затем он перенаправляется в цикл while , предоставляя текст, который будет анализировать команда read .
Сделайте скрипт исполняемым с помощью команды chmod . Вам нужно будет делать это каждый раз, когда вы копируете сценарий из этой статьи. Подставьте имя соответствующего скрипта в каждом случае.
chmod +x field.sh

Когда мы запускаем скрипт, записи правильно разбиваются на составляющие их поля, причем каждое поле сохраняется в отдельной переменной.
./поле.ш
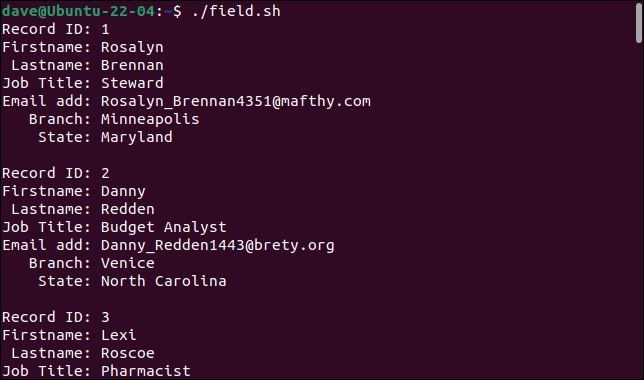
Каждая запись печатается как набор полей.
Выбор полей
Возможно, мы не хотим или не должны извлекать каждое поле. Мы можем получить набор полей, включив команду cut .
Этот скрипт называется «select.sh».
#!/бин/баш в то время как IFS="," read -r id состояние ветки jobtitle делать echo "Идентификатор записи: $id" echo "Название должности: $jobtitle" эхо "Ветка: $ветка" эхо "Состояние: $state" эхо "" сделано < <(cut -d "," -f1,4,6,7 sample.csv | хвост -n +2)
Мы добавили команду cut в предложение замены процесса. Мы используем параметр -d (разделитель), чтобы указать cut использовать запятые « , » в качестве разделителя. Параметр -f (поле) сообщает cut , что нам нужны поля один, четыре, шесть и семь. Эти четыре поля считываются в четыре переменные, которые печатаются в теле цикла while .
Вот что мы получаем, когда запускаем скрипт.
./выбрать.ш
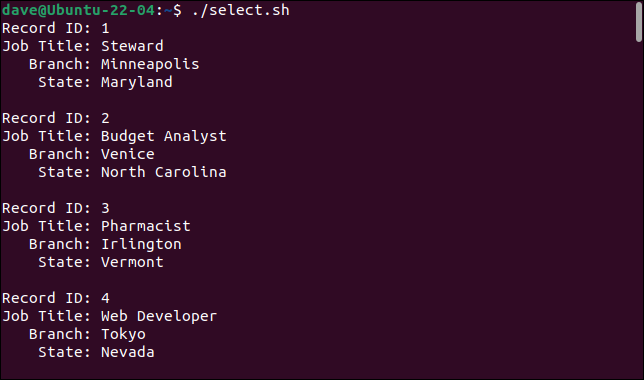
Добавив команду cut , мы можем выбирать нужные поля и игнорировать те, которые нам не нужны.
Все идет нормально. Но…
Если CSV, с которым вы имеете дело, несложный, без запятых или кавычек в данных поля, то, что мы рассмотрели, вероятно, удовлетворит ваши потребности в анализе CSV. Чтобы показать проблемы, с которыми мы можем столкнуться, мы изменили небольшую выборку данных, чтобы она выглядела следующим образом.
идентификатор, имя, фамилия, должность, адрес электронной почты, филиал, штат 1, Розалин, Бреннан, "Стюард, старший", Rosalyn_Brennan4351@mafthy.com, Миннеаполис, Мэриленд 2, Дэнни, Редден, «Аналитик «Бюджет»», Danny_Redden1443@brety.org, Венеция, Северная Каролина 3, Лекси, Роско, фармацевт, Ирлингтон, Вермонт
- Первая запись содержит запятую в поле
job-title, поэтому это поле необходимо заключить в кавычки. - Во второй записи есть слово, заключенное в два набора кавычек в поле
jobs-title. - Запись три не содержит данных в поле
email-address.
Эти данные были сохранены как «sample2.csv». Измените свой сценарий «field.sh», чтобы он вызывал «sample2.csv», и сохраните его как «field2.sh».

#! /бин/баш в то время как IFS="," read -r id имя фамилия должность электронная почта филиал состояние делать echo "Идентификатор записи: $id" эхо "Имя: $firstname" эхо "Фамилия: $lastname" echo "Название должности: $jobtitle" echo "Добавить адрес электронной почты: $email" эхо "Ветка: $ветка" эхо "Состояние: $state" эхо "" сделано < <(хвост -n +2 sample2.csv)
Когда мы запускаем этот скрипт, мы видим появление трещин в наших простых парсерах CSV.
./поле2.ш

Первая запись разбивает поле «название должности» на два поля, а вторая часть обрабатывается как адрес электронной почты. Каждое поле после этого сдвигается на одну позицию вправо. Последнее поле содержит значения как branch , так и state .
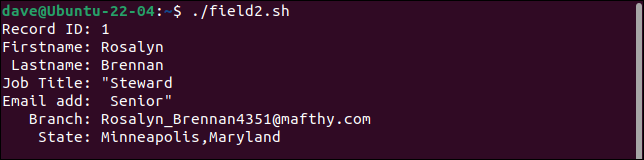
Вторая запись сохраняет все кавычки. Слово «Бюджет» должно быть заключено только в одну пару кавычек.
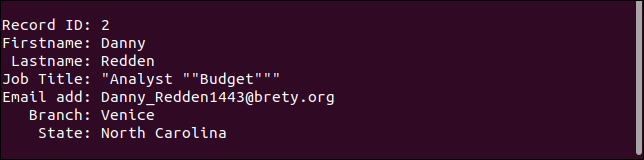
Третья запись фактически обрабатывает отсутствующее поле, как и должно быть. Адрес электронной почты отсутствует, но все остальное в порядке.

Как ни странно, для простого формата данных очень сложно написать надежный анализатор CSV общего случая. Такие инструменты, как awk , позволят вам приблизиться, но всегда есть крайние случаи и исключения, которые ускользают.

Попытка написать безошибочный синтаксический анализатор CSV, вероятно, не лучший путь вперед. Альтернативный подход — особенно если вы работаете в какой-то срок — использует две разные стратегии.
Один из них — использовать специально разработанный инструмент для обработки и извлечения ваших данных. Второй — очистить ваши данные и заменить проблемные сценарии, такие как встроенные запятые и кавычки. Тогда ваши простые парсеры Bash смогут справиться с удобным для Bash CSV.
Инструментарий csvkit
Инструментарий CSV csvkit — это набор утилит, специально созданных для помощи в работе с CSV-файлами. Вам нужно будет установить его на свой компьютер.
Чтобы установить его в Ubuntu, используйте эту команду:
sudo apt установить csvkit

Чтобы установить его в Fedora, вам нужно ввести:
sudo dnf установить python3-csvkit

На Manjaro команда:
sudo pacman -S csvkit

Если мы передаем ему имя CSV-файла, утилита csvlook отображает таблицу, показывающую содержимое каждого поля. Содержимое поля отображается, чтобы показать, что представляет собой содержимое поля, а не так, как оно хранится в файле CSV.
Давайте попробуем csvlook с нашим проблемным файлом «sample2.csv».
csvlook образец2.csv
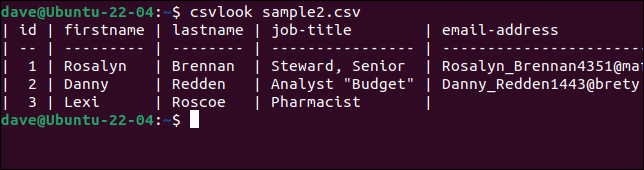
Все поля отображаются корректно. Это доказывает, что проблема не в CSV. Проблема в том, что наши скрипты слишком упрощены, чтобы правильно интерпретировать CSV.
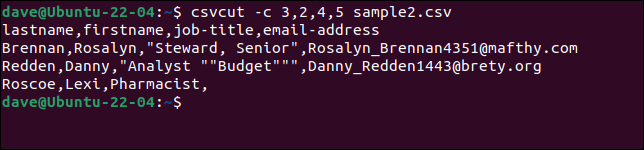
Чтобы выбрать определенные столбцы, используйте команду csvcut . -c (столбец) можно использовать с именами полей или номерами столбцов, или с тем и другим вместе.
Предположим, нам нужно извлечь имя и фамилию, должность и адрес электронной почты из каждой записи, но мы хотим, чтобы порядок имен был «фамилия, имя». Все, что нам нужно сделать, это расположить имена полей или номера в нужном нам порядке.
Все эти три команды эквивалентны.
csvcut -c фамилия, имя, должность, адрес электронной почты sample2.csv
csvcut -c фамилия, имя, 4,5 sample2.csv
csvcut -c 3,2,4,5 пример2.csv
Мы можем добавить команду csvsort для сортировки вывода по полю. Мы используем параметр -c (столбец), чтобы указать столбец для сортировки, и параметр -r (обратный), чтобы сортировать в порядке убывания.
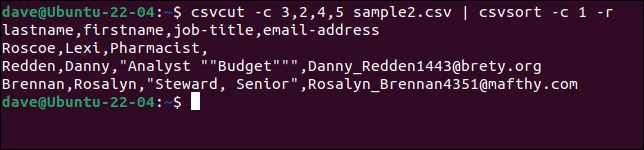
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
Чтобы сделать вывод более красивым, мы можем передать его через csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
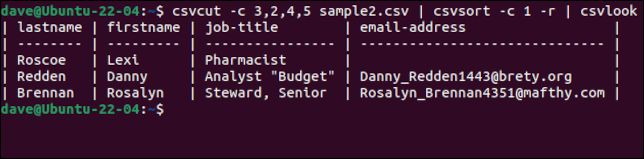
Аккуратным штрихом является то, что, хотя записи отсортированы, строка заголовка с именами полей остается первой строкой. Как только мы будем довольны, что у нас есть данные, как мы хотим, мы можем удалить csvlook из цепочки команд и создать новый файл CSV, перенаправив вывод в файл.
Мы добавили больше данных в файл «sample2.file», удалили команду csvsort и создали новый файл с именем «sample3.csv».
csvcut -c 3,2,4,5 образец2.csv > образец3.csv

Безопасный способ очистки данных CSV
Если вы откроете файл CSV в LibreOffice Calc, каждое поле будет помещено в ячейку. Вы можете использовать функцию поиска и замены для поиска запятых. Вы можете заменить их на «ничего», чтобы они исчезли, или на символ, который не повлияет на синтаксический анализ CSV, например точку с запятой « ; " Например.
Вы не увидите кавычек вокруг полей в кавычках. Единственные кавычки, которые вы увидите, — это встроенные кавычки внутри данных поля. Они отображаются в виде одинарных кавычек. Поиск и замена их одним апострофом « ' » заменит двойные кавычки в файле CSV.
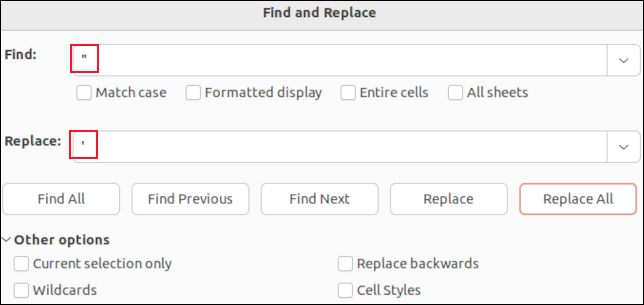
Выполнение поиска и замены в таком приложении, как LibreOffice Calc, означает, что вы не можете случайно удалить запятые-разделители полей или удалить кавычки вокруг полей в кавычках. Вы только измените значения данных полей.
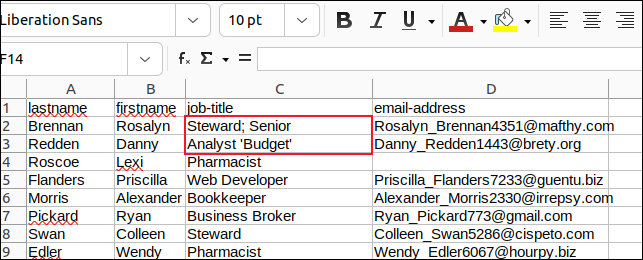
Мы заменили все запятые в полях точками с запятой и все встроенные кавычки на апострофы и сохранили наши изменения.
Затем мы создали скрипт под названием «field3.sh» для анализа «sample3.csv».
#! /бин/баш в то время как IFS = "," читать -r фамилия имя должность электронная почта делать эхо "Фамилия: $lastname" эхо "Имя: $firstname" echo "Название должности: $jobtitle" echo "Добавить адрес электронной почты: $email" эхо "" сделано < <(tail -n +2 sample3.csv)
Посмотрим, что мы получим, когда запустим его.
./поле3.ш
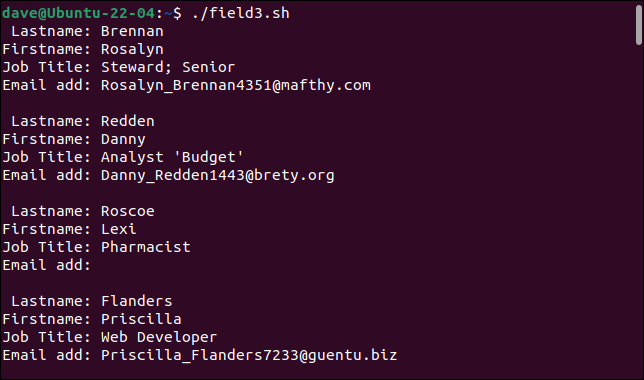
Наш простой синтаксический анализатор теперь может обрабатывать ранее проблемные записи.
Вы увидите много CSV
CSV, пожалуй, ближе всего к общему языку для данных приложений. Большинство приложений, обрабатывающих некоторые формы данных, поддерживают импорт и экспорт CSV. Знание того, как обращаться с CSV реалистичным и практичным способом, сослужит вам хорошую службу.
СВЯЗАННЫЕ С: 9 примеров сценариев Bash, которые помогут вам начать работу в Linux