
Как использовать команду grep в Linux
Опубликовано: 2022-01-29
Команда Linux grep — это утилита сопоставления строк и шаблонов, которая отображает совпадающие строки из нескольких файлов. Он также работает с конвейерным выводом других команд. Мы покажем вам, как это сделать.
История создания grep
Команда grep известна в кругах Linux и Unix по трем причинам. Во-первых, это невероятно полезно. Во-вторых, богатство вариантов может быть ошеломляющим. В-третьих, он был написан за одну ночь, чтобы удовлетворить конкретную потребность. Первые два удара; третья немного отстала.
Кен Томпсон извлек возможности поиска по регулярным выражениям из редактора ed (произносится как «и-ди») и создал небольшую программу — для собственного использования — для поиска в текстовых файлах. Глава его отдела в Bell Labs Дуг Макилрой подошел к Томпсону и описал проблему, с которой столкнулся один из его коллег, Ли МакМахон.

МакМахон пытался определить авторов статей федералистов с помощью текстового анализа. Ему нужен был инструмент, который мог бы искать фразы и строки в текстовых файлах. В тот вечер Томпсон потратил около часа на то, чтобы сделать свой инструмент универсальной утилитой, которую могли бы использовать другие, и переименовал ее в grep . Он взял название из командной строки ed g/re/p , что переводится как «глобальный поиск по регулярным выражениям».
Вы можете посмотреть, как Томпсон говорит с Брайаном Керниганом о рождении grep .
Простой поиск с помощью grep
Чтобы найти строку в файле, передайте условие поиска и имя файла в командной строке:

Отображаются совпадающие строки. В данном случае это одна линия. Соответствующий текст выделяется. Это связано с тем, что в большинстве дистрибутивов grep имеет псевдоним:
псевдоним grep='grep --color=auto'
Давайте посмотрим на результаты, где есть несколько совпадающих строк. Мы будем искать слово «Среднее» в файле журнала приложения. Поскольку мы не можем вспомнить, написано ли слово в файле журнала строчными буквами, мы будем использовать параметр -i (игнорировать регистр):
grep -i Средний geek-1.log

Отображается каждая совпадающая строка с выделенным в каждой совпадающим текстом.
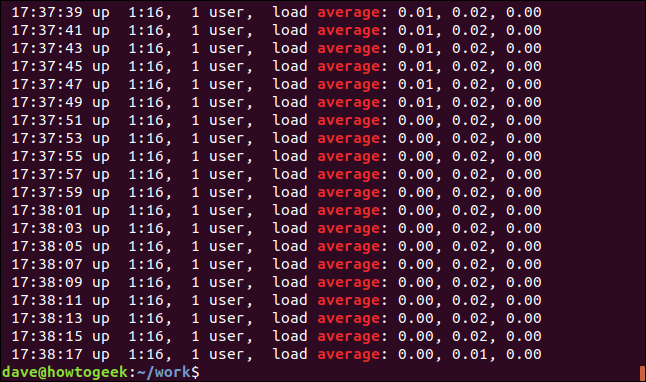
Мы можем отобразить несовпадающие строки, используя параметр -v (инвертировать совпадение).
grep -v Память geek-1.log

Подсветки нет, потому что это несовпадающие строки.
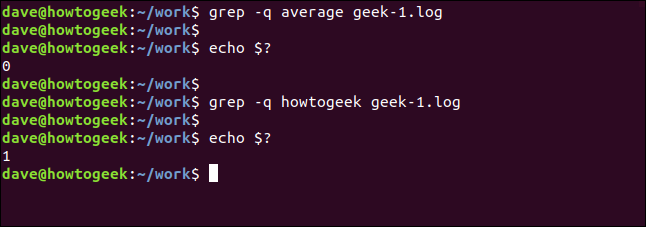
Мы можем заставить grep полностью молчать. Результат передается оболочке как возвращаемое значение от grep . Результат, равный нулю, означает, что строка найдена , а результат, равный единице, означает, что она не найдена. Мы можем проверить код возврата, используя $? специальные параметры:
grep -q средний geek-1.log
эхо $?
grep -q Howtogeek geek-1.log
эхо $?
Рекурсивный поиск с помощью grep
Для поиска во вложенных каталогах и подкаталогах используйте параметр -r (рекурсивный). Обратите внимание, что вы не указываете имя файла в командной строке, вы должны указать путь. Здесь мы ищем в текущем каталоге «.» и любые подкаталоги:
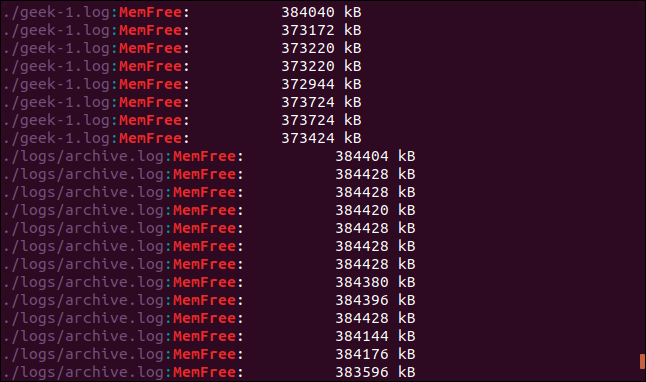
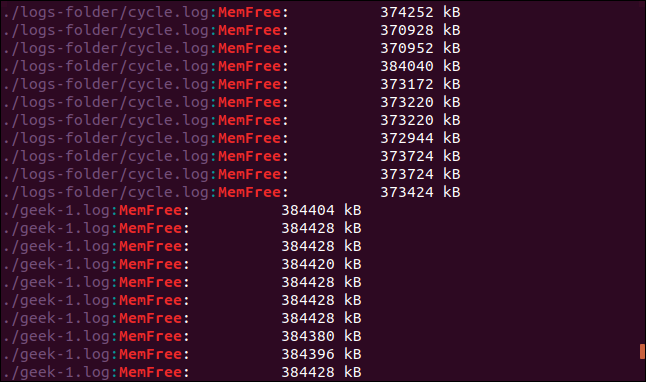
grep -r -i memfree .

Вывод включает каталог и имя файла каждой соответствующей строки.
Мы можем заставить grep следовать символическим ссылкам, используя параметр -R (рекурсивное разыменование). У нас есть символическая ссылка в этом каталоге, которая называется logs-folder . Он указывает на /home/dave/logs .
ls -l папка-журналы

Давайте повторим наш последний поиск с опцией -R (рекурсивное разыменование):
grep -R -i memfree .

Выполняется переход по символической ссылке, и каталог, на который она указывает, также ищется с помощью grep .
Поиск целых слов
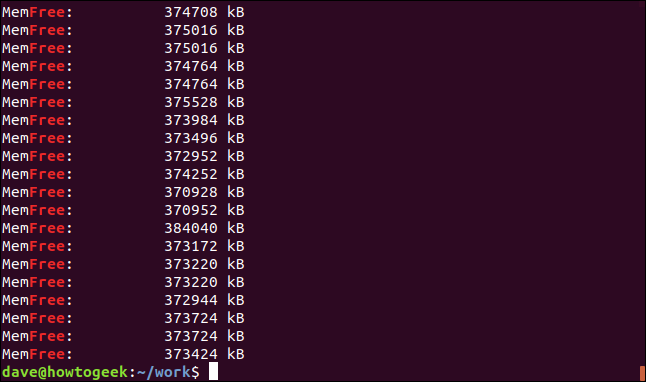
По умолчанию grep будет соответствовать строке, если цель поиска появляется где-либо в этой строке, в том числе внутри другой строки. Посмотрите на этот пример. Мы будем искать слово «бесплатно».
grep -i бесплатно geek-1.log

Результатом являются строки, в которых есть строка «free», но они не являются отдельными словами. Они являются частью строки «MemFree».
Чтобы заставить grep сопоставлять только отдельные «слова», используйте параметр -w (слово регулярное выражение).
grep -w -i бесплатно geek-1.log
эхо $?
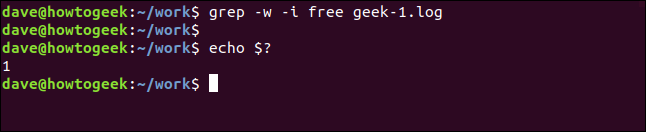
На этот раз результатов нет, потому что поисковый запрос «бесплатно» не появляется в файле как отдельное слово.
Использование нескольких условий поиска
Параметр -E (расширенное регулярное выражение) позволяет выполнять поиск по нескольким словам. (Опция -E заменяет устаревшую версию grep egrep .)
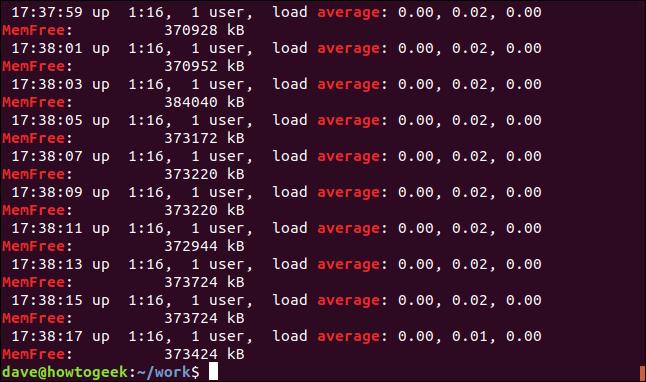
Эта команда выполняет поиск по двум поисковым запросам: «средний» и «memfree».
grep -E -w -i "средний | memfree" geek-1.log

Все совпадающие строки отображаются для каждого условия поиска.
Вы также можете искать несколько терминов, которые не обязательно являются целыми словами, но могут быть и целыми словами.
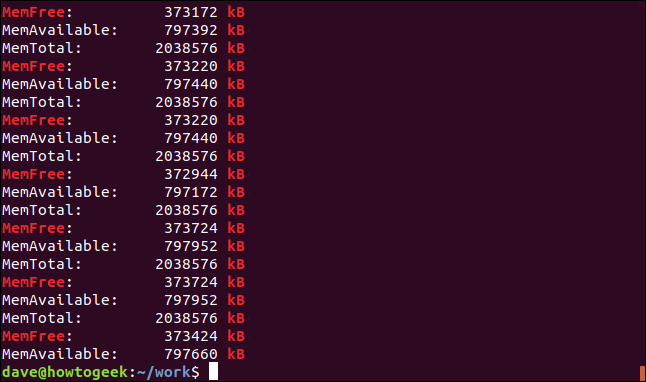
Параметр -e (шаблоны) позволяет использовать несколько условий поиска в командной строке. Мы используем функцию скобок регулярного выражения для создания шаблона поиска. Он сообщает grep , что он должен соответствовать любому из символов, содержащихся в квадратных скобках «[].» Это означает, что при поиске grep будет соответствовать либо «kB», либо «KB».

Обе строки совпадают, и фактически некоторые строки содержат обе строки.
Точное совпадение строк
-x (регулярное выражение строки) будет соответствовать только строкам, где вся строка соответствует поисковому запросу. Давайте найдем отметку даты и времени, которая, как мы знаем, появляется в файле журнала только один раз:
grep -x "20 января -- 06 15:24:35" geek-1.log

Единственная совпадающая строка будет найдена и отображена.
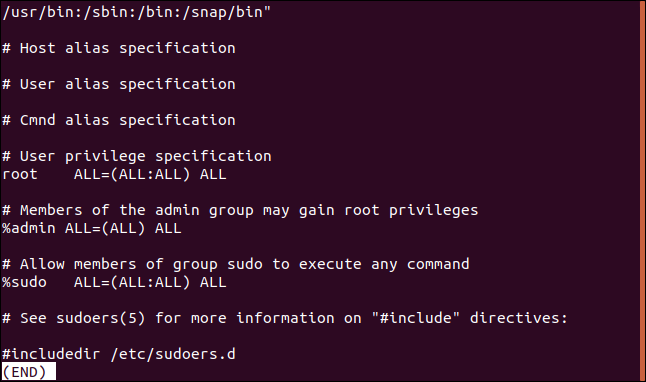
Противоположным этому является отображение только строк, которые не совпадают. Это может быть полезно, когда вы просматриваете файлы конфигурации. Комментарии — это здорово, но иногда среди них трудно найти реальные настройки. Вот файл /etc/sudoers :
Мы можем эффективно отфильтровать строки комментариев следующим образом:
sudo grep -v "#" /etc/sudoers
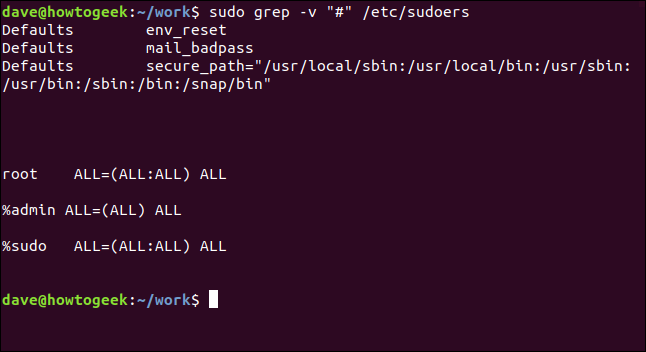
Это гораздо проще разобрать.
Отображение только совпадающего текста
Может быть случай, когда вы не хотите видеть всю совпадающую строку, а только совпадающий текст. Опция -o (только соответствие) делает именно это.
grep -o MemFree geek-1.log

Отображение сводится к отображению только текста, соответствующего поисковому запросу, а не всей соответствующей строки.

Подсчет с помощью grep
grep работает не только с текстом, но и с числовой информацией. Мы можем заставить grep считаться для нас разными способами. Если мы хотим узнать, сколько раз искомый термин появляется в файле, мы можем использовать параметр -c (количество).

grep -c средний geek-1.log

grep сообщает, что искомый термин встречается в этом файле 240 раз.
Вы можете заставить grep отображать номер строки для каждой соответствующей строки, используя параметр -n (номер строки).
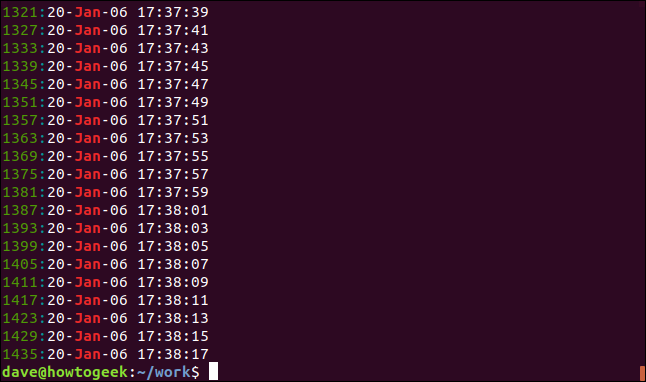
grep -n Янв geek-1.log

Номер строки для каждой соответствующей строки отображается в начале строки.
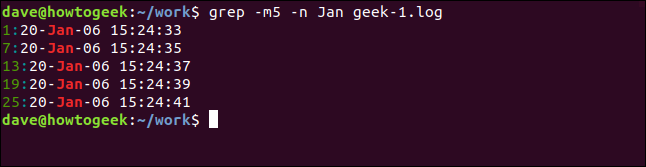
Чтобы уменьшить количество отображаемых результатов, используйте параметр -m (максимальное количество). Мы собираемся ограничить вывод пятью совпадающими строками:
grep -m5 -n Янв geek-1.log
Добавление контекста
Возможность увидеть дополнительные строки — возможно, не совпадающие — для каждой совпадающей строки часто оказывается полезной. это может помочь определить, какие из совпадающих строк интересуют вас.
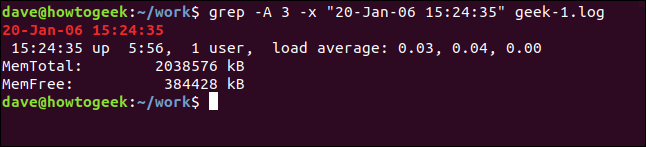
Чтобы показать несколько строк после совпадающей строки, используйте параметр -A (после контекста). В этом примере мы запрашиваем три строки:
grep -A 3 -x "20 января 2006 г. 15:24:35" geek-1.log
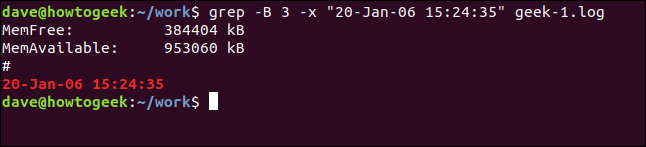
Чтобы увидеть несколько строк перед совпадающей строкой, используйте параметр -B (контекст перед).
grep -B 3 -x "20 января 2006 г. 15:24:35" geek-1.log
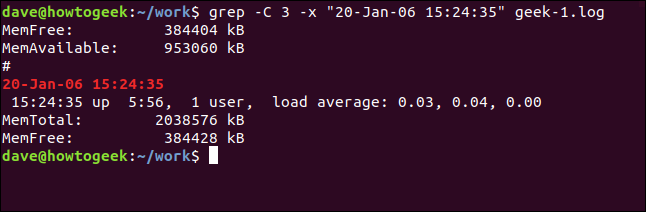
А чтобы включить строки до и после совпадающей строки, используйте параметр -C (контекст).
grep -C 3 -x "20 января 2006 г. 15:24:35" geek-1.log
Отображение совпадающих файлов
Чтобы просмотреть имена файлов, содержащих поисковый запрос, используйте параметр -l (файлы с совпадением). Чтобы узнать, какие файлы исходного кода C содержат ссылки на заголовочный файл sl.h , используйте эту команду:
grep -l "sl.h" *.c

Перечислены имена файлов, а не совпадающие строки.
И, конечно же, мы можем искать файлы, которые не содержат поисковый запрос. Опция -L (файлы без совпадения) делает именно это.
grep -L "sl.h" *.c

Начало и конец строк
Мы можем заставить grep отображать только совпадения, которые находятся либо в начале, либо в конце строки. Оператор регулярного выражения «^» соответствует началу строки. Практически все строки в файле журнала будут содержать пробелы, но мы собираемся искать строки, в которых первым символом является пробел:
grep "^ " geek-1.log

Отображаются строки, в которых первым символом в начале строки является пробел.
Чтобы соответствовать концу строки, используйте оператор регулярного выражения «$». Мы собираемся искать строки, оканчивающиеся на «00».
grep "00$" geek-1.log

На дисплее отображаются строки, в конце которых стоит «00».
Использование каналов с grep
Конечно, вы можете направить входные данные в grep , направить вывод из grep в другую программу и расположить grep в середине цепочки конвейеров.
Допустим, мы хотим увидеть все вхождения строки «ExtractParameters» в наших файлах исходного кода C. Мы знаем, что их будет довольно много, поэтому мы передаем вывод в less :
grep "Извлечение параметров" *.c | меньше

Результат представлен в less .
Это позволяет пролистывать список файлов и использовать функцию поиска less's .
Если мы направим вывод grep в wc и воспользуемся параметром -l (lines), мы сможем подсчитать количество строк в файлах исходного кода, которые содержат «ExtractParameters». (Мы могли бы добиться этого, используя опцию grep -c (count), но это отличный способ продемонстрировать конвейер из grep .)
grep "Извлечение параметров" *.c | туалет -л

С помощью следующей команды мы передаем вывод ls в grep , а вывод grep — в sort . Мы перечисляем файлы в текущем каталоге, выбираем те, в которых есть строка «Aug», и сортируем их по размеру файла:
лс -л | grep "Авг" | сортировать +4n
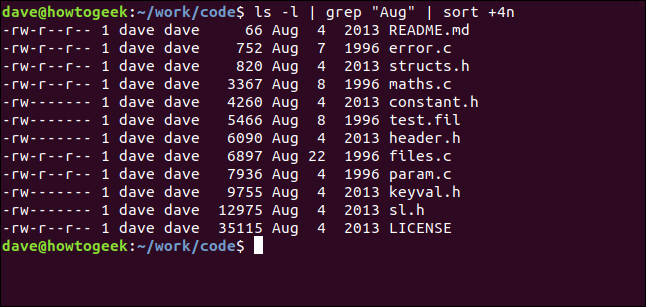
Давайте разберем это:
- ls -l : выполнить список файлов в длинном формате с помощью
ls. - grep «Aug» : выберите строки из списка
ls, в которых есть «Aug». Обратите внимание, что это также найдет файлы, в именах которых есть «Aug». - sort +4n : Сортировать вывод grep по четвертому столбцу (размер файла).
Мы получаем отсортированный список всех файлов, измененных в августе (независимо от года), в порядке возрастания размера файла.
СВЯЗАННЫЕ С: Как использовать каналы в Linux
grep: меньше команда, больше союзник
grep — потрясающий инструмент, которым можно воспользоваться. Он датируется 1974 годом и до сих пор набирает обороты, потому что нам нужно то, что он делает, и ничто не делает его лучше.
Сочетание grep с некоторыми регулярными выражениями действительно выводит его на новый уровень.
СВЯЗАННЫЕ С: Как использовать основные регулярные выражения для лучшего поиска и экономии времени
| Команды Linux | ||
| Файлы | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · tail · stat · ls · fstab · echo · less · chgrp · chown · rev · look · strings · type · rename · zip · unzip · mount · umount · install · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · patch · convert · rclone · shred · srm | |
| Процессы | alias · screen · top · nice · renice · progress · strace · systemd · tmux · chsh · history · at · batch · free · which · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · тайм-аут · стена · да · убить · спать · sudo · su · время · groupadd · usermod · группы · lshw · выключение · перезагрузка · halt · poweroff · passwd · lscpu · crontab · дата · bg · fg | |
| Сеть | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · dig · finger · nmap · ftp · curl · wget · who · whoami · w · iptables · ssh-keygen · ufw |
СВЯЗАННЫЕ С: Лучшие ноутбуки с Linux для разработчиков и энтузиастов