
Как узнать, содержит ли строка Bash подстроку в Linux
Опубликовано: 2022-09-21
Иногда в сценариях Linux вам нужно знать, содержит ли строка текста определенную меньшую строку. Есть много способов сделать это. Мы покажем вам несколько простых и надежных методов.
Почему это полезно?
Обычным требованием является поиск в строке меньшей подстроки. Одним из примеров может быть чтение текста из файла или человеческого ввода и поиск в строке определенной подстроки, чтобы ваш сценарий мог решить, что делать дальше. Это может быть поиск метки или имени устройства в файле конфигурации или командной строки в строке ввода от пользователя.
Пользователи Linux наделены множеством утилит для работы с текстом. Некоторые из них встроены в оболочку Bash, другие предоставляются как отдельные утилиты или приложения. Есть причина, по которой операционные системы, производные от Unix, богато снабжены возможностями манипулирования строками.

Некоторые вещи, которые кажутся файлами, не являются простыми файлами. Это специальные файлы, представляющие такие вещи, как аппаратные устройства и источники системной информации. Абстракция, выполняемая операционной системой, придает им внешний вид и характеристики файлов. Вы можете читать из них информацию — в виде текста, естественно — и в некоторых случаях писать в них, но это не обычные файлы.
Текст также используется в качестве ввода и вывода для команд в окне терминала. Это позволяет перенаправлять и передавать входные и выходные данные. Эта функциональность лежит в основе способности объединять последовательности команд Linux вместе, передавая выходные данные одной команды в качестве входных данных для следующей.
Независимо от происхождения, поиск в полученном тексте значимого слова, команды, метки или какого-либо другого индикатора является стандартной частью работы с текстовыми данными. Вот набор простых приемов, которые вы можете включить в свои собственные сценарии.
Поиск подстрок с помощью встроенных функций Bash
Проверка сравнения строк в двойных скобках « [[...]] » может использоваться в операторах if , чтобы определить, содержит ли одна строка другую строку.
Скопируйте этот сценарий в редактор и сохраните его в файл с именем «double.sh».
#!/бин/баш если [[ "обезьяна" = *"ключ"* ]]; тогда echo "ключ находится в обезьяне" еще echo "ключ не в обезьяне" фи
Вам нужно будет сделать скрипт исполняемым с помощью команды chmod . Это шаг, который всегда необходим для того, чтобы сделать любой скрипт исполняемым. Вам нужно будет делать это каждый раз, когда вы создаете файл сценария. Подставьте имя соответствующего скрипта в каждом случае.
chmod +x двойной.sh

Запустим скрипт.
./двойной.ш

Это работает, потому что звездочка « * » представляет собой любую последовательность символов, включая отсутствие символов. Если подстрока «ключ» находится в целевой строке, с какими-либо символами впереди или позади нее или без них, тест вернет значение «истина».
В нашем примере перед подстрокой стоят символы. Они соответствуют первой звездочке. За подстрокой нет букв, но, поскольку звездочка также не соответствует ни одному символу, тест все равно проходит.
Для гибкости мы можем модифицировать наш скрипт, чтобы он обрабатывал переменные, а не литеральные строки. Это скрипт «double2.sh».
#!/бин/баш строка = "обезьяна" подстрока = "ключ" если [[ $string = *$substring* ]]; тогда echo "В $string найдена $substring" еще echo "$substring не найден в $string" фи
Посмотрим, как это работает.
./двойной2.ш

Это работает таким же образом, с тем преимуществом, что мы можем использовать имена переменных вместо буквальных строк. Превращение нашего небольшого решения в функцию обеспечит наибольшую гибкость.
Это скрипт «double3.sh».
#!/бин/баш
shopt -s nocasematch
строка = "обезьяна"
подстрока = "Ключ"
столица = "Лондон"
проверка_подстрока ()
{
если [[ $1 = *$2* ]]; тогда
echo "$2 найдено в $1"
еще
echo "$2 не найдено в $1"
фи
}
check_substring "Обезьяна" "ключ"
check_substring $строка $подстрока
check_substring $string "банан"
check_substring "Уэльс" $capital Мы вызываем нашу функцию check_substring , используя сочетание переменных и буквенных строк. Мы использовали shopt с опцией -s (set) для установки nocasematch , чтобы совпадения не учитывали регистр.

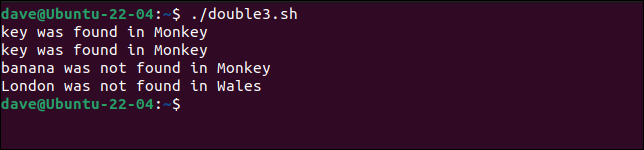
Вот как это работает.
./double3.sh
Мы также можем использовать прием, заключающий подстроку в звездочки в операторах case . Это «case.sh».
#!/бин/баш
shopt -s nocasematch
строка = "валлаби"
подстрока = "Стена"
case $строка в
*$подстрока*)
echo "В $string найдена $substring"
;;
*)
echo "Ничего не совпало: $string"
;;
эсак Использование операторов case вместо очень длинных операторов if может упростить чтение и отладку сценариев. Если вам нужно проверить, содержит ли строка одну из многих возможных подстрок, оператор case будет лучшим выбором.
./case.sh

Подстрока найдена.
Поиск подстрок с помощью grep
Помимо встроенных функций Bash, первым инструментом текстового поиска, который вам, вероятно, понадобится, является grep . Мы можем использовать врожденную способность grep искать строку в строке для поиска наших подстрок.
Этот сценарий называется «subgrep.sh».
#!/бин/баш string="горшок с кашей" подстрока = "гребень" если $(echo $string | grep -q $substring); тогда echo "В $string найдена $substring" еще echo "$substring не найден в $string" фи
Сценарий использует echo для отправки строки в grep , которая ищет подстроку. Мы используем параметр -q (quiet), чтобы остановить запись grep в стандартный вывод.

Если результат команд в скобках « (...) » равен нулю, это означает, что совпадение найдено. Поскольку в Bash ноль равен true , выполняется оператор if и выполняется предложение then .
Посмотрим, каков его выход.
./subgrep.sh

Поиск подстрок с помощью sed
Мы также можем использовать sed для поиска подстроки.
По умолчанию sed печатает весь введенный в него текст. Использование sed -n предотвращает это. Печатаются только совпадающие строки. Это выражение напечатает все строки, которые соответствуют или содержат значение $substring.
"/$подстрока/p"
Мы передаем значение $string в sed , используя перенаправление здесь, <<< . Это используется для перенаправления значений в команду в текущей оболочке. Он не вызывает подоболочку, как канал.
Первый -n - это тест. Он вернет true , если вывод команды sed не равен нулю. Единственный способ, которым вывод sed может быть ненулевым, — это найти совпадающую строку. Если это так, $substring должна быть найдена в $string .
Это «subsed.sh».
#!/бин/баш строка = "Швеция" подстрока = "Эден" если [ -n "$(sed -n "/$substring/p" <<< $string)" ]; тогда echo "В $string найдена $substring" еще echo "$substring не найден в $string" фи
Мы получаем ожидаемый ответ при запуске скрипта.
./subsed.sh

Мы можем проверить логику скрипта, отредактировав значение $substring так, чтобы сравнение не удавалось.
./subsed.sh

Хватит искать, нашел
Другие инструменты, такие как awk и Perl , могут находить подстроки, но простой вариант использования, такой как поиск подстроки, не гарантирует их дополнительной функциональности или дополнительной сложности. В частности, использование встроенных функций Bash для поиска подстрок выполняется быстро, просто и не требует внешних инструментов.
СВЯЗАННЫЕ С: Как использовать операторы case в сценариях Bash