
Как защитить свои изображения от генераторов искусственного интеллекта
Опубликовано: 2023-03-24
- Отказ от наборов обучающих данных с помощью такого инструмента, как HaveIBeenTrained.com.
- Используйте файл robots.txt для защиты от поисковых роботов, многие из которых в первую очередь используются для создания наборов данных.
- Защитите права на свои работы и бросьте вызов разработчикам этих инструментов в суде (или присоединитесь к существующим коллективным искам).
- Загружайте только изображения с агрессивными водяными знаками.
- Избегайте размещения своего искусства в Интернете в первую очередь.
Генераторы искусства ИИ, возможно, не смогут подражать человеческому творчеству, но они точно могут вас ободрать. Это беспокоит как художников, так и тех, кто боится захвата власти ИИ, но не все еще может быть потеряно.
Как защитить защищенное авторским правом искусство от ИИ
Генераторы рисунков ИИ ничто без наборов данных, на которых они были обучены. Это включает в себя взятие огромного образца существующих произведений искусства и их контекстуализацию таким образом, чтобы люди могли использовать подсказки на естественном языке для создания подобных произведений искусства. Вы можете попробовать это сами, используя приложение для генеративного искусства, такое как DALL-E 2 или Midjourney от OpenAI.
Мы попросили DALL-E 2 изготовить «картину Элмо с «Улицы Сезам» в стиле Пабло Пикассо» и вот что мы получили (да, это была лучшая из всех):

Возможность создавать произведения искусства в стиле умерших художников, возможно, не вызывает большого беспокойства, особенно в таком узнаваемом стиле. Но для современных художников, которые делятся своими творениями через ArtStation, DeviantArt, Behance, личные веб-сайты и страницы в социальных сетях, таких как Instagram или Facebook, это гораздо более важно.
Итак, что вы можете сделать, чтобы защитить ваши собственные творения от использования для обучения ИИ, который может создавать творения намного быстрее, чем вы?
Отказ от обучающих наборов данных
Вы можете отказаться от двух крупнейших открытых наборов данных для обучения изображений в Интернете, LAION-400M и LAION-5B, используя HaveIBeenTrained.com. Эти наборы данных используются некоторыми из крупнейших генераторов изображений в Интернете, включая Stable Diffusion и Google Imagen. Поскольку они действительно открыты, многие другие инструменты генеративного ИИ также используют их.
К сожалению, этот процесс является медленным и утомительным. Вам нужно будет сначала зарегистрировать учетную запись, а затем выполнить поиск или загрузить изображение, чтобы найти совпадения в наборе данных. Затем вы можете щелкнуть правой кнопкой мыши изображение в веб-браузере на настольном компьютере и выбрать опцию «Добавить в мои отказы». Кроме того, вы можете дать набору данных явное разрешение на использование изображения, вместо этого нажав «Добавить в мои подписки».
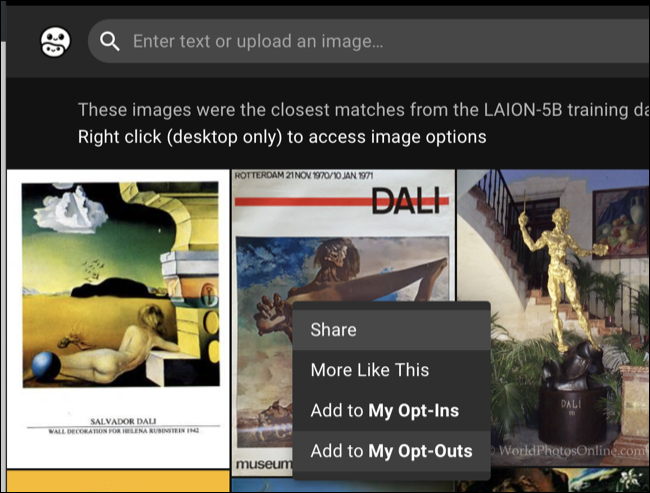
Вам нужно будет сделать это для каждого изображения, которое вы найдете, так что это может быть кропотливым процессом, если вы художник с большим объемом работы. Сколько времени это реально займет, в конечном итоге зависит от того, насколько легко отфильтровать вашу работу, что может быть проще, если у вас есть работа, связанная с уникальным именем или проектом, большим числом подписчиков в Интернете и так далее.
Хотя эти два массивных набора данных — отличное место для начала, они далеко не единственные, которые используются. Люди могут создавать свои собственные наборы данных, а некоторые делают это для воспроизведения определенного художника или художественного стиля. Некоторые компании, такие как OpenAI, вообще не раскрывают, какие наборы данных используют их инструменты, поэтому с этим невозможно бороться.
Используйте robots.txt для защиты от краулеров
Файл robots.txt — это небольшой текстовый документ, который помещается в корневой каталог веб-сайта, чтобы сообщить поисковым роботам, куда им разрешено или не разрешено заходить. Хотя Google прямо заявляет, что «это не механизм для защиты веб-страницы от Google», вы все равно можете попробовать использовать его, чтобы не допустить доступа поисковых роботов к вашим работам, если вы размещаете их на своем собственном веб-сайте.
Как следует из названия, поисковые роботы сканируют Интернет в поисках контента для индексации. Поисковые системы — далеко не единственные краулеры, и краулеры также используются для создания наборов данных, очень похожих на упомянутые выше наборы данных ЛАИОН-400М и ЛАИОН-5Б. Основная проблема с robots.txt заключается в том, что он полагается на то, что поисковый робот обработает ваш запрос.
Одним из самых больших наборов данных является Common Crawl, данные из которого использовались для создания наборов данных LAION. Процесс сканирования сети является непрерывным, и LAION заявляет, что его текущий (на момент написания) набор данных LAION-400M был создан «из случайных веб-страниц, просканированных в период с 2014 по 2021 год».
Common Crawl заявляет, что он соблюдает robots.txt и протокол исключения роботов как с точки зрения блокировки контента, так и с точки зрения задержки сканирования (для экономии полосы пропускания). Вы можете сделать это, создав правило для пользовательского агента «CCBot» в файле Robots.txt. Конечно, ничто из этого не поможет, если вы не размещаете свои работы самостоятельно.
В Google Search Central есть удобное руководство по созданию файла robots.txt, или вы можете использовать веб-сайт, например Ryte's Robots.txt Generator, чтобы создать его для себя. Вы можете разрешить или отключить определенные пользовательские агенты из определенных каталогов или просто заблокировать все с помощью подстановочного знака (*). Например, файл robots.txt, который блокирует все файлы в вашем каталоге /images/ от Common Crawl, но при этом позволяет другим поисковым роботам индексировать ваш веб-сайт, будет выглядеть так:
Агент пользователя: CCbot Запретить: /изображения/ Пользовательский агент: * Позволять: / Карта сайта: https://www.example.com/sitemap.xml
Это не остановит сканеры, которые уже посещали ваш веб-сайт, но предотвратит индексирование Common Crawl вашей папки /images/ (и любых новых загрузок с момента последнего сканирования) в будущем.
Авторские права на ваши работы
Хотя авторское право подразумевается в работе, которую вы создали, попытка защитить авторское право на вашу работу также может стоить затраченных усилий. В США вы можете сделать это, зарегистрировав свои работы на Copyright.gov. Вы можете отправить до 10 неопубликованных работ в одном приложении, но имейте в виду, что обработка ваших работ может занять некоторое время (в настоящее время около года).
Зарегистрировав авторские права на свою работу, вы получаете больше опоры в делах, связанных с судами. Это идея коллективного иска, поданного против Stability AI (разработчика Stable Diffusion и DreamStudio, спонсора LAION), DeviantArt (платформы для художников и разработчика DreamUp) и Midjourney, приложения для генеративного искусства от имени затронутых художников. .
Вы можете прочитать все о судебном процессе на StableDiffusionLitigation.com, и если вы считаете, что ваша работа была использована для обучения этих генераторов, у вас могут быть основания присоединиться к групповому иску, обратившись к команде юристов. Подача заявки на регистрацию вашего произведения искусства в Бюро регистрации авторских прав США является важным первым шагом, если вы хотите пойти по этому пути.
Подобно другим практикам, привлекавшим юристов в прошлом, — пиратству, джейлбрейку, обмену файлами — маловероятно, что судебный процесс полностью остановит эту практику. Защита, вероятно, будет утверждать, что эти инструменты были обучены на материалах «добросовестного использования», собранных с общедоступных веб-сайтов. Нам придется подождать и посмотреть, какой эффект окажут такие судебные процессы, если таковые будут.

Агрессивный водяной знак
Если вы когда-либо загружаете свои изображения только с агрессивными или граничащими с саморазрушением водяными знаками, изображения, включенные в наборы данных, будут отражать это. В конечном счете, это во многом зависит от того, почему ваша работа загружается в первую очередь. Если вы создаете произведения искусства некоммерчески для удовольствия в Интернете, это кажется в конечном счете обреченным на провал.

Однако, если вы продаете картины из реального мира и хотите выставить их в Интернете перед продажей, это может немного помочь. Это, безусловно, будет отвлекать внимание от готового произведения искусства, поэтому вам придется подумать об этом самостоятельно.
Не загружайте свое искусство в Интернет
Это может показаться смешным (и это так), но если ваша работа вообще никогда не загружалась в Интернет, нет никаких шансов, что она попадет в сеть и будет использована для обучения ИИ. Конечно, зарабатывать на жизнь как художник, не используя Интернет для обмена своими работами, может быть почти невозможно (особенно если вы работаете в цифровом носителе).
Для артистов, работающих над музыкой, это невозможно. Даже если вы работаете с традиционными материалами, такими как масло или акварель, неизвестно, собирается ли кто-то сфотографировать готовую работу и загрузить ее самостоятельно.
Может ли искусство ИИ быть защищено авторским правом?
Вопрос о том, могут ли результаты генеративного ИИ быть защищены авторским правом, сложный. Общепризнано, что инструмент ИИ, используемый для создания искусства, редко имеет какие-либо права на результат.
Об этом четко сказано в условиях обслуживания большинства инструментов, включая Stable Diffusion:
За исключением случаев, изложенных в настоящем документе, Лицензиар не претендует на какие-либо права на Результат, который Вы создаете с помощью Модели. Вы несете ответственность за результат, который вы создаете, и его последующее использование. Никакое использование вывода не может противоречить любому положению, указанному в Лицензии.
Далее лицензия запрещает любое использование, «нарушающее любые применимые национальные, федеральные, государственные, местные или международные законы или правила», включая закон об авторском праве.
Середина пути:
Вы владеете всеми Активами, которые создаете с помощью Сервисов, насколько это возможно в соответствии с действующим законодательством. Это исключает масштабирование чужих изображений, которые остаются собственностью первоначальных создателей активов.
И OpenAI (DALL-E 2):
В отношениях между сторонами и в той степени, в которой это разрешено применимым законодательством, вы владеете всеми Входными данными, и при условии соблюдения вами настоящих Условий OpenAI настоящим передает вам все свои права, право собственности и интересы в отношении Выходных данных.
Что касается защиты авторских прав на все, что вы создали с помощью такого инструмента, Бюро регистрации авторских прав США заявило, что авторское право распространяется только на искусство, созданное людьми (наряду с другими требованиями, такими как оригинальность):
В случаях, когда утверждается нечеловеческое авторство, апелляционные суды приходят к выводу, что авторское право не защищает предполагаемые творения.
Право постоянно развивается, так что это может быть успешно оспорено в будущем. Также стоит отметить, что элементы конечного продукта, которые не являются продуктом генератора ИИ (например, сюжет или диалоги), по-прежнему могут быть защищены авторским правом, даже если другие элементы (например, иллюстрации или музыка) не защищены авторским правом.
Могут ли генераторы изображений с искусственным интеллектом использовать мои произведения искусства, защищенные авторским правом?
Вопрос не обязательно в том, «могут ли» генераторы ИИ использовать ваше искусство, защищенное авторским правом, а в том, «используют ли» они уже ваше искусство, защищенное авторским правом. Ответ на этот вопрос, как выяснили многие художники, звучит утвердительно. Выше мы обсудили некоторые методы отказа от наборов данных и предотвращения индексации вашего контента поисковыми роботами, но эти методы в конечном итоге зависят от того, кто стоит у руля и уважает ваши предпочтения.
Вы можете узнать, включено ли ваше искусство в крупнейшие общедоступные наборы данных изображений, используя HaveIBeenTrained.com. Загрузите одно из своих наиболее известных произведений искусства или найдите свое имя, название произведения, веб-комикс или другое творение и посмотрите. Если вы видите свое произведение искусства на веб-сайте, оно включено в набор данных, используемый Stable Diffusion и другими.
Это не говоря уже о других приложениях для генеративного искусства, которые не раскрывают, какие наборы данных используются (например, DALL-E от OpenAI). Вы всегда можете попробовать подсказку, такую как «произведение искусства в стиле вашего имени», чтобы увидеть, появится ли что-нибудь знакомое.
Предстоящие инструменты могут помочь победить генераторы искусств на основе искусственного интеллекта
У художников может быть некоторая надежда на появление инструментов, которые могут затруднить генеративному ИИ воспроизведение произведений искусства на основе изображений в наборе данных. К сожалению, этих решений еще нет (на момент написания статьи), и неизвестно, насколько эффективными они будут в долгосрочной перспективе. Инструменты искусственного интеллекта развиваются быстро, поэтому вполне возможно, что они смогут обойти такие меры безопасности.
Первый — это Glaze, проект Чикагского университета, который «вносит очень небольшие изменения» в иллюстрацию перед загрузкой. Разработчики называют эти изменения «прикрытием стиля» и отмечают, что произведение искусства кажется человеческому глазу почти идентичным оригиналу, в то время как ИИ неправильно интерпретирует стиль как стиль другого.
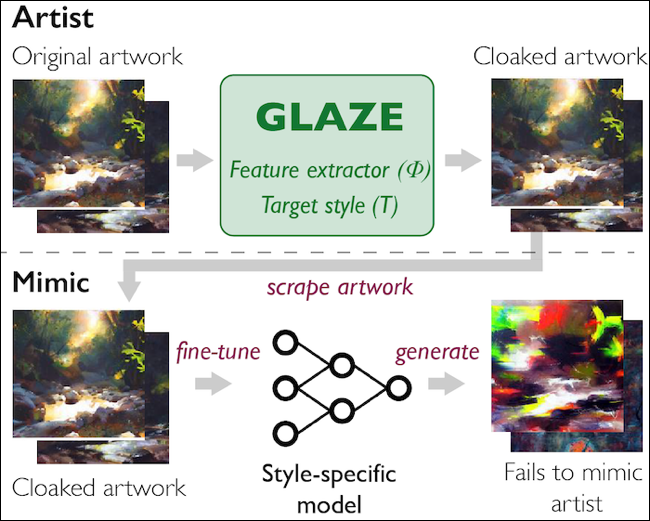
Glaze будет выпущен в виде приложения для Mac и Windows, так что работы можно будет «замаскировать», не отходя от компьютера художника. Разработчики заявляют, что не будут коммерциализировать инструмент, поэтому им сможет пользоваться любой желающий. Проект Glaze рассматривает этот инструмент как «необходимый первый шаг к инструментам защиты, ориентированным на художников, чтобы противостоять имитации ИИ».
Другой метод, описанный в блоге Pursuit Мельбурнского университета, описывает тонкое использование шума, который «меняет ровно столько пикселей в изображении, чтобы сбить с толку ИИ и превратить его в «необучаемое» изображение». Учреждение утверждает, что разработало метод, который использует слабые места моделей и доходит до того, что называет такие инструменты, как Stable Diffusion, «ленивыми учениками».
Этот метод имеет широкий спектр потенциальных применений, включая визуальные изображения, а также аудио и фотографии, которые идентифицируют вас лично. Важно признать, что эти методы все еще находятся на ранней стадии разработки, поэтому нам придется подождать и посмотреть, на что они действительно способны.
Восстание роботов
Приложения для генеративного искусства могут создавать произведения искусства в кратчайшие сроки, но они не настолько креативны, как люди. ChatGPT, возможно, сможет написать ваше резюме, но вам нужно будет внимательно его вычитать, потому что чат-бот часто ошибается.
Суть в том, что текущие решения ИИ могут быть полезными, но они также слабы.