
Как анализировать текст
Опубликовано: 2022-10-15
Если вы изучили несколько языков программирования, возможно, вы слышали термин «разбор текста». Это используется для упрощения сложных значений данных файла. Статья поможет вам узнать, как анализировать текст с помощью языка. В дополнение к этому, если вы столкнулись с ошибкой при разборе текста x, вы узнаете, как исправить ошибку при разборе в статье.
Содержание
- Как анализировать текст
- Что такое парсинг текста?
- НЛП или обработка естественного языка
- Что такое парсинг текста?
- Каковы причины парсить текст?
- Способ 1: через класс DataFrame
- Способ 2: через токенизацию Word
- Способ 3: через класс DocParser
- Способ 4: с помощью инструмента «Синтаксический анализ текста»
- Способ 5: через TextFieldParser (Visual Basic)
- Совет для профессионалов: как анализировать текст в MS Excel
- Как исправить ошибку синтаксического анализа
Как анализировать текст
В этой статье мы показали полное руководство по анализу текста различными способами, а также кратко познакомили с парсингом текста.
Что такое парсинг текста?
Прежде чем углубляться, изучите концепции парсинга текста с помощью любого кода. Важно знать основы языка и кодирования.
НЛП или обработка естественного языка
Для анализа текста используется обработка естественного языка или НЛП, которая является подполем домена искусственного интеллекта. Язык Python, который является одним из языков, принадлежащих к категории, используется для анализа текста.
Коды НЛП позволяют компьютерам понимать и обрабатывать человеческие языки, чтобы сделать их пригодными для различных приложений. Чтобы применить методы машинного обучения или машинного обучения к языку, неструктурированные текстовые данные необходимо преобразовать в структурированные табличные данные. Для завершения синтаксического анализа используется язык Python для изменения программных кодов.
Что такое парсинг текста?
Синтаксический анализ текста просто означает преобразование данных из одного формата в другой формат. Формат, в котором сохранен файл, должен быть проанализирован или преобразован в файл другого формата, чтобы пользователь мог использовать его в различных приложениях.
- Другими словами, процесс означает анализ строки или текста и преобразование в логические компоненты путем изменения формата файла.
- Некоторые правила языка Python используются для выполнения этой общей задачи программирования. При разборе текста данная серия текста разбивается на более мелкие компоненты.
Каковы причины парсить текст?
Причины, по которым текст должен быть проанализирован, приведены в этом разделе, и это необходимое знание, прежде чем знать, как анализировать текст.
- Все компьютеризированные данные не будут в одном и том же формате и могут различаться в зависимости от различных приложений.
- Форматы данных различаются для разных приложений, и несовместимый код может привести к этой ошибке.
- Не существует индивидуальной универсальной компьютерной программы для выбора данных всех форматов данных.
Способ 1: через класс DataFrame
Класс DataFrame языка Python имеет все необходимые функции для разбора текста. Эта встроенная библиотека содержит необходимые коды для преобразования данных любого формата в другой формат.
Краткое введение в класс DataFrame
Класс DataFrame — это многофункциональная структура данных, которая используется в качестве инструмента анализа данных. Это мощный инструмент анализа данных, который можно использовать для анализа данных с минимальными усилиями.
- Код считывается в кадр данных pandas для выполнения анализа на языке Python.
- Класс поставляется с многочисленными пакетами, предоставляемыми пандами, которые используются аналитиками данных Python.
- Особенностью этого класса является абстракция, код, в котором внутренний функционал функции скрыт от пользователей, библиотеки NumPy. Библиотека NumPy — это библиотека Python, которая включает в себя команды и функции для работы с массивами.
- Класс DataFrame можно использовать для визуализации двумерного массива с несколькими индексами строк и столбцов. Эти индексы помогают хранить многомерные данные и, следовательно, называются MultiIndex. Их нужно изменить, чтобы знать, как исправить ошибку синтаксического анализа.
Панды языка Python помогают выполнять операции в стиле SQL или базы данных с максимальным совершенством, чтобы избежать ошибок при синтаксическом анализе текста x. Он также содержит некоторые инструменты ввода-вывода, которые помогают анализировать файлы CSV, MS Excel, JSON, HDF5 и других форматов данных.
Читайте также: Исправление ошибки при попытке прокси-запроса
Процесс разбора текста с использованием класса DataFrame
Чтобы узнать, как анализировать текст, вы можете использовать стандартный процесс с использованием класса DataFrame, описанного в этом разделе.
- Расшифруйте формат данных входных данных.
- Определите выходные данные данных, таких как CSV или значения, разделенные запятыми .
- Напишите в коде примитивный тип данных, например list или dict.
Примечание. Написание кода на пустом фрейме данных может быть утомительным и сложным. Панды позволяют создавать данные в классе DataFrame из этих типов данных. Следовательно, данные в примитивном типе данных могут быть легко преобразованы в требуемый формат данных.
- Проанализируйте данные с помощью инструмента анализа данных pandas DataFrame и распечатайте результат.
Вариант I: стандартный формат
Здесь объясняется стандартный метод форматирования любого файла с использованием определенного формата данных, например CSV.
- Сохраните файл со значениями данных локально на вашем ПК. Например, вы можете назвать файл data.txt .
- Импортируйте файл в pandas с определенным именем и импортируйте данные в другую переменную. Например, панды языка импортируются в имя pd в приведенном коде.
- Импорт должен иметь полный код с подробным описанием имени входного файла, функции и формата входного файла.
Примечание. Здесь переменная с именем res используется для выполнения функции чтения данных в файле data.txt с использованием pandas, импортированных в pd . Формат данных вводимого текста указывается в формате CSV .
- Вызовите указанный тип файла и проанализируйте проанализированный текст на распечатанном результате. Например, команда res после выполнения командной строки поможет распечатать проанализированный текст.
Ниже приведен пример кода для описанного выше процесса, который поможет понять, как анализировать текст.
импортировать панд как pd
res = pd.read_csv('data.txt')
разрешениеВ этом случае, если вы введете значения данных в файл data.txt , например [1,2,3] , они будут проанализированы и отображены как 1 2 3 .
Вариант II: строковый метод
Если текст, указанный в коде, содержит только строки или буквенные символы, специальные символы в строке, такие как запятые, пробел и т. д., можно использовать для разделения и разбора текста. Этот процесс аналогичен обычным внутренним строковым операциям. Чтобы узнать, как исправить ошибку синтаксического анализа, вы должны следовать процессу синтаксического анализа текста с использованием этой опции, описанной ниже.
- Данные извлекаются из строки, и отмечаются все специальные символы, разделяющие текст.
Например, в приведенном ниже коде идентифицируются специальные символы в строке my_string , ' , ' и ' : '. Этот процесс должен выполняться осторожно, чтобы избежать ошибок при разборе текста x.
- Текст в строке разбивается индивидуально на основе значений и положения специальных символов.
Например, строка разбивается на текстовые значения данных на основе специальных символов, определенных с помощью команды разделения.
- Значения данных строки печатаются отдельно как проанализированный текст. Здесь оператор печати используется для печати проанализированного значения данных текста.
Пример кода для описанного выше процесса приведен ниже.
my_string = 'Имена: техника, компьютер'
sfinal = [name.strip() для имени в my_string.split(':')[1].split(',')]
print("Имена: {}".format(sfinal))В этом случае результат проанализированной строки будет отображаться, как показано ниже.
Имена: ['Технология', 'компьютер']
Чтобы получить лучшую ясность и знать, как анализировать текст при использовании строкового текста, используется цикл for , и код изменяется следующим образом.
my_string = 'Имена: техника, компьютер'
s1 = my_string.split(':')
с2 = с1[1]
s3 = s2.split(',')
s4 = [name.strip() для имени в s3]
для idx, элемент перечисления ([s1, s2, s3, s4]):
print("Шаг {}: {}".format(idx, item)) 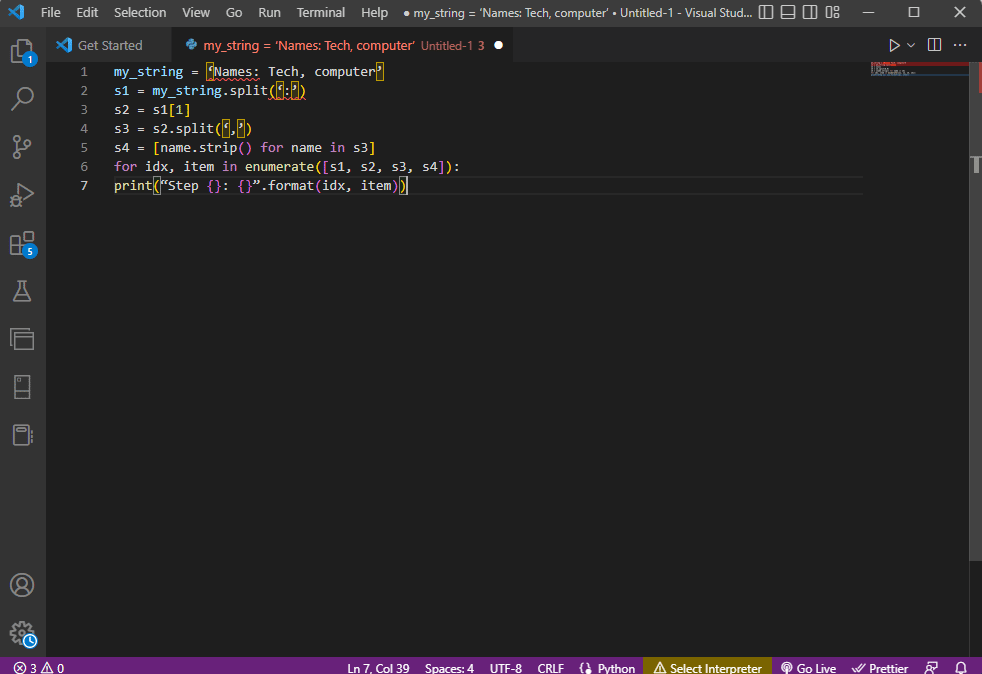
Результат проанализированного текста для каждого из этих шагов отображается, как показано ниже. Вы можете заметить, что на шаге 0 строка разделяется на основе специального символа : , а значения текстовых данных разделяются на основе символа на следующих шагах.
Шаг 0: ['Имена', 'Технология, компьютер'] Шаг 1: Техника, компьютер Шаг 2: ['Технология', 'компьютер'] Шаг 3: ['Технология', 'компьютер']
Вариант III: разбор сложного файла
В большинстве случаев данные файла, которые необходимо проанализировать, содержат различные типы данных и значения данных. В этом случае может быть сложно проанализировать файл с помощью методов, описанных ранее.
Особенности анализа сложных данных в файле заключаются в том, чтобы значения данных отображались в табличном формате.
- Название или метаданные значений печатаются в верхней части файла,
- Переменные и поля печатаются в выходных данных в табличной форме, и
- Значения данных образуют составной ключ.
Прежде чем углубляться в изучение того, как анализировать текст этим методом, необходимо изучить несколько основных понятий. Анализ значений данных выполняется на основе регулярных выражений или регулярных выражений.
Шаблоны регулярных выражений
Чтобы знать, как исправить ошибку синтаксического анализа, вы должны убедиться, что шаблоны регулярных выражений в выражениях правильные. Код для анализа значений данных строк будет включать общие шаблоны регулярных выражений, перечисленные ниже в этом разделе.
- '\d' : соответствует десятичной цифре в строке,
- '\s' : соответствует символу пробела,
- '\w' : соответствует буквенно-цифровому символу,
- '+' или '*' : выполняет жадное сопоставление, сопоставляя один или несколько символов в строках,
- 'a-z' : соответствует группам нижнего регистра в значениях текстовых данных,
- 'A-Z' или 'a-z': соответствует группам верхнего и нижнего регистра строки, и
- '0-9': соответствует числовым значениям.
Обычные выражения
Модули регулярных выражений являются основной частью пакета pandas на языке Python, и неправильное re может привести к ошибке при синтаксическом анализе текста x. Это крошечный язык, встроенный в Python для поиска шаблона строки в выражении. Регулярные выражения или регулярное выражение — это строки со специальным синтаксисом. Это позволяет пользователю сопоставлять шаблоны в других строках на основе значений в строках.
Regex создается на основе типа данных и требования выражения в строке, например 'String = (.*)\n . Регулярное выражение используется перед шаблоном в каждом выражении. Символы, используемые в регулярных выражениях, перечислены ниже и помогут понять, как анализировать текст.
- . : для извлечения любого символа из данных,
- * : использовать ноль или более данных из предыдущего выражения,
- (.*) : чтобы сгруппировать часть регулярного выражения в круглых скобках,
- \n : создать новый символ строки в конце строки кода,
- \d : создать короткое целочисленное значение в диапазоне от 0 до 9,
- + : использовать одно или несколько данных из предыдущего выражения и
- | : создать логическое утверждение; используется для или выражений.
RegexObjects
RegexObject является возвращаемым значением для функции компиляции и используется для возврата MatchObject, если выражение соответствует значению соответствия.
1. Объект соответствия
Поскольку логическое значение MatchObject всегда равно True, вы можете использовать оператор if для определения положительных совпадений в объекте. В случае использования оператора if группа, на которую ссылается индекс, используется для поиска совпадения объекта в выражении.
- group() возвращает одну или несколько подгрупп соответствия,
- group(0) возвращает полное совпадение,
- group(1) возвращает первую подгруппу в скобках и
- При обращении к нескольким группам мы должны использовать специальное расширение для Python. Это расширение используется для указания имени группы, в которой должно быть найдено совпадение. Конкретное расширение предоставляется в группе в скобках. Например, выражение (?P<group1>regex1) будет ссылаться на конкретную группу с именем group1 и проверять соответствие в регулярном выражении regex1 . Чтобы узнать, как исправить ошибку синтаксического анализа, вы должны проверить, правильно ли указана группа.
2. Методы MatchObject
При поиске того, как анализировать текст, важно знать, что MatchObject имеет два основных метода, перечисленных ниже. Если MatchObject найден в указанном выражении, он вернет свой экземпляр, иначе он вернет None.
- Метод match(string) используется для поиска совпадений строки в начале регулярного выражения и
- Метод search(string) используется для сканирования строки, чтобы найти место для совпадения в регулярном выражении.
Функции регулярных выражений
Функции регулярных выражений — это строки кода, которые используются для выполнения определенной функции, указанной пользователем, из набора полученных значений данных.
Примечание. Для написания функций для регулярных выражений используются необработанные строки, чтобы избежать ошибок при анализе текста x. Это делается путем добавления нижнего индекса r перед каждым образцом в выражении.
Общие функции, используемые в выражениях, объясняются ниже.
1. перенайти()
Эта функция возвращает все шаблоны в строке, если совпадение найдено, и возвращает пустой список, если совпадение не найдено. Например, функция string = re.findall('[aeiou]', regex_filename) используется для поиска вхождения гласной в имени файла.
2. re.split()
Эта функция используется для разделения строки в случае совпадения с указанным символом, например пробелом. Если совпадений не найдено, возвращается пустая строка.
3. re.sub()
Функция заменяет совпадающий текст содержимым заданной переменной замены. В отличие от других функций, если шаблон не найден, возвращается исходная строка.
4. исследование()
Одной из основных функций, помогающих научиться анализировать текст, является функция поиска. Это помогает в поиске шаблона в строке и возврате объекта соответствия. Если при поиске совпадение не удается найти, значение не возвращается.
5. перекомпилировать (шаблон)
Эта функция используется для компиляции шаблонов регулярных выражений в RegexObject, что обсуждалось ранее.
Другие требования
Перечисленные требования являются дополнительной возможностью, используемой продвинутыми программистами при анализе данных.
- Для визуализации регулярного выражения используется regexper , а
- Для проверки регулярного выражения используется regex101 .
Читайте также: Как установить NumPy в Windows 10

Процесс разбора текста
Метод разбора текста в этом сложном варианте описан ниже.
- Первый шаг — понять формат ввода, прочитав содержимое файла. Например, функции with open и read() используются для открытия и чтения содержимого файла с именем sample . Файл примера содержит содержимое файла file.txt ; чтобы узнать, как исправить ошибку синтаксического анализа, файл необходимо прочитать полностью.
- Содержимое файла печатается для анализа данных вручную, чтобы узнать метаданные значений. Здесь функция print() используется для печати содержимого файла примера .
- Необходимые пакеты данных для разбора текста импортируются в код, и классу присваивается имя для дальнейшего кодирования. Здесь импортируются регулярные выражения и панды .
- Регулярные выражения, необходимые для кода, определяются в файле путем включения шаблона регулярного выражения и функции регулярного выражения. Это позволяет текстовому объекту или корпусу брать код для анализа данных.
- Чтобы узнать, как анализировать текст, вы можете обратиться к приведенному здесь примеру кода. Функция compile() используется для компиляции строки из группы stringname1 файла filename . Функция проверки совпадений в регулярном выражении используется командой ief_parse_line(line) ,
- Анализатор строк для кода написан с использованием def_parse_file(filepath) , в котором определенная функция проверяет все совпадения регулярных выражений в указанной функции. Здесь метод regex search() ищет ключ rx в имени файла и возвращает ключ и совпадение первого подходящего регулярного выражения. Любая проблема с шагом может привести к ошибке при синтаксическом анализе текста x.
- Следующим шагом является написание анализатора файлов с использованием функции анализатора файлов, которая называется def_parse_file(filepath) . Пустой список создается для сбора данных кода, как data = [] , совпадение проверяется в каждой строке с помощью match = _parse_line(line) , и возвращаются точные данные значения в зависимости от типа данных.
- Чтобы извлечь число и значение для таблицы, используется команда line.strip().split(',') . Команда row{} используется для создания словаря со строкой данных. Команда data.append(row) используется для понимания данных и их анализа в табличном формате.
Команда data = pd.DataFrame(data) используется для создания pandas DataFrame из значений dict. В качестве альтернативы вы можете использовать следующие команды для соответствующих целей, как указано ниже.
- data.set_index(['string', 'integer'], inplace=True) , чтобы установить индекс таблицы.
- data = data.groupby(level=data.index.names).first() для консолидации и удаления nans.
- data = data.apply(pd.to_numeric, errors='ignore') для повышения оценки с плавающей до целочисленной.
Последний шаг, чтобы узнать, как анализировать текст, — это протестировать анализатор с помощью оператора if , присвоив значения переменной data и распечатав их с помощью команды print(data) .
Пример кода для пояснения выше приведен здесь.
с open('file.txt') в качестве образца:
sample_contents = образец.чтение()
печать (sample_contents)
импортировать повторно
импортировать панд как pd
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line (строка):
для ключа, rx в rx_filename.items():
совпадение = rx.search(строка)
если совпадают:
ключ возврата, совпадение
возврат Нет, Нет
def parse_file (путь к файлу):
данные = []
с открытым (путь к файлу, 'r') как файл_объект:
строка = файл_объект.readline()
пока строка:
ключ, совпадение = _parse_line (строка)
если ключ == 'строка1':
строка = match.group('string1')
целое число = целое (строка1)
value_type = match.group('string1')
строка = файл_объект.readline()
в то время как line.strip():
число, значение = line.strip().split(',')
значение = значение.strip()
строка = {
'Данные1': строка1,
«Данные2»: число,
тип_значения: значение
}
data.append(строка)
строка = файл_объект.readline()
строка = файл_объект.readline()
данные = pd.DataFrame(данные)
возвращаемые данные
если _ _name_ _ = = '_ _main_ _':
путь к файлу = 'sample.txt'
данные = разбор (путь к файлу)
печать (данные) 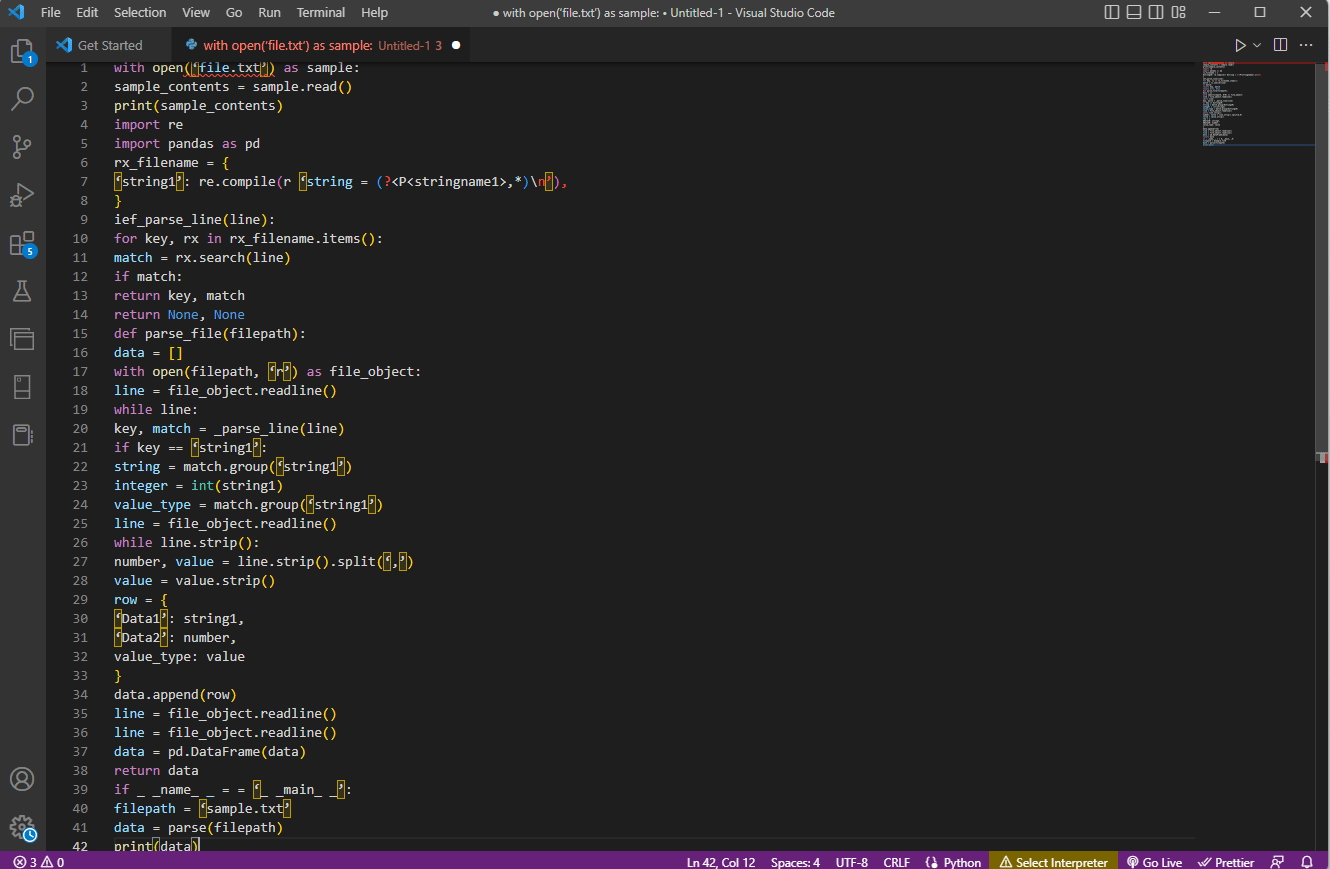
Способ 2: через токенизацию Word
Процесс преобразования текста или корпуса в токены или более мелкие фрагменты на основе определенных правил называется токенизацией. Чтобы узнать, как исправить ошибку синтаксического анализа, важно проанализировать команды токенизации слов в коде. Подобно регулярному выражению, в этом методе можно создавать собственные правила, и это помогает в задачах предварительной обработки текста, таких как сопоставление частей речи. Кроме того, в этом методе выполняются такие действия, как поиск и сопоставление общих слов, очистка текста и подготовка данных для расширенных методов анализа текста, таких как анализ тональности. Если токенизация неправильная, может возникнуть ошибка в тексте синтаксического анализа x.
Библиотека NTL
В этом процессе используется популярная библиотека языковых инструментов под названием nltk, которая имеет богатый набор функций для выполнения многих задач НЛП. Их можно загрузить через пакеты Pip или Pip Installs. Чтобы узнать, как анализировать текст, вы можете использовать базовый пакет дистрибутива Anaconda, который по умолчанию включает библиотеку.
Формы токенизации
Распространенными формами этого метода являются токенизация слов и токенизация предложений. Из-за маркера уровня слова первый печатает одно слово только один раз, а второй печатает слово на уровне предложения.
Процесс разбора текста
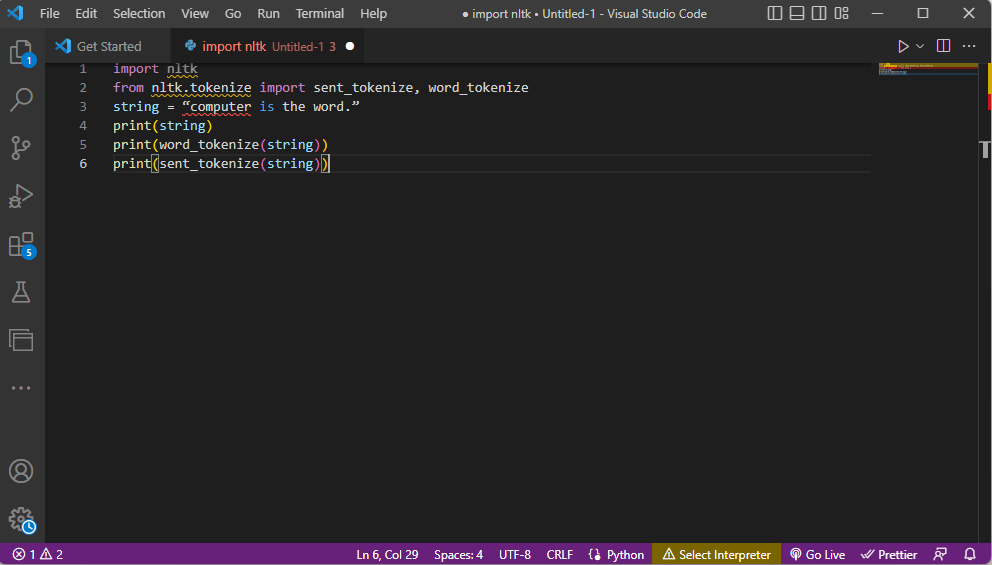
- Библиотека инструментов ntlk импортируется, а формы токенизации импортируются из библиотеки.
- Дана строка и даны команды для выполнения токенизации.
- Пока строка печатается, выводом будет компьютер — это слово.
- В случае токенизации слов или word_tokenize() каждое слово в предложении печатается отдельно внутри '' и отделяется запятой . Результатом команды будет «компьютер», «есть», «тот», «слово», «.».
- В случае токенизации предложения или sent_tokenize() отдельные предложения помещаются в '' и допускается повторение слова. Результатом команды будет «компьютер — это слово».
Код, объясняющий шаги для токенизации выше, приведен здесь.
импортировать нлтк из nltk.tokenize импортировать send_tokenize, word_tokenize string = «компьютер — это слово». печать (строка) печать (word_tokenize (строка)) печать (sent_tokenize (строка))
Читайте также: Как исправить ошибку javascript:void(0)
Способ 3: через класс DocParser
Подобно классу DataFrame, класс DocParser можно использовать для анализа текста в коде. Класс позволяет вам вызывать функцию синтаксического анализа с путем к файлу.
Процесс разбора текста
Чтобы узнать, как анализировать текст с помощью класса DocParser, следуйте приведенным ниже инструкциям.
- Функция get_format(filename) используется для извлечения расширения файла, возврата его в установленную переменную для функции и передачи его следующей функции. Например, p1 = get_format(filename) извлечет расширение файла filename , установит его в переменную p1 и передаст следующей функции.
- Логическая структура с другими функциями создается с помощью операторов и функций if-elif-else .
- Если расширение файла допустимо и структура логична, функция get_parser используется для анализа данных в пути к файлу и возврата пользователю строкового объекта.
Примечание. Чтобы знать, как исправить ошибку синтаксического анализа, эта функция должна быть реализована правильно.
- Анализ значений данных выполняется с расширением файла. Конкретная реализация класса parse_txt или parse_docx используется для генерации строковых объектов из частей данного типа файла.
- Анализ может быть выполнен для файлов с другими читаемыми расширениями, такими как parse_pdf , parse_html и parse_pptx .
- Значения данных и интерфейс можно импортировать в приложения с помощью операторов импорта и создать экземпляр объекта DocParser. Это можно сделать путем разбора файлов на языке Python, таких как parse_file.py . Эту операцию следует выполнять осторожно, чтобы избежать ошибки при разборе текста x.
Способ 4: с помощью инструмента «Синтаксический анализ текста»
Инструмент Parse text используется для извлечения определенных данных из переменных и сопоставления их с другими переменными. Это не зависит от каких-либо других инструментов, используемых в задаче, и инструмент платформы BPA используется для потребления и вывода переменных. Используйте приведенную здесь ссылку, чтобы получить доступ к онлайн-инструменту «Синтаксический анализ текста» и использовать приведенные ранее ответы о том, как анализировать текст.
Способ 5: через TextFieldParser (Visual Basic)
TextFieldParser использовал объекты для анализа и обработки очень больших файлов, которые структурированы и разделены. В этом методе можно использовать ширину и столбец текста, например файлы журнала или информацию из устаревшей базы данных. Метод синтаксического анализа аналогичен повторению кода в текстовом файле и в основном используется для извлечения полей текста, аналогичных методам манипулирования строками. Это делается для токенизации строк с разделителями и полей различной ширины с использованием определенного разделителя, такого как запятая или табуляция.
Функции для анализа текста
Следующие функции могут использоваться для анализа текста в этом методе.
- Для определения разделителя используется SetDelimiters . Например, команда testReader.SetDelimiters (vbTab) используется для установки табуляции в качестве разделителя.
- Чтобы установить ширину поля на положительное целое значение для фиксированной ширины поля текстовых файлов, вы можете использовать команду testReader.SetFieldWidths (integer) .
- Чтобы проверить тип поля текста, вы можете использовать следующую команду testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth .
Методы поиска MatchObject
Существует два основных метода поиска MatchObject в коде или проанализированном тексте.
- Первый метод заключается в определении формата и циклическом просмотре файла с помощью метода ReadFields . Этот метод поможет в обработке каждой строки кода.
- Метод PeekChars используется для проверки каждого поля по отдельности перед его чтением, определения нескольких форматов и реагирования.
В любом случае, если поле не соответствует указанному формату при выполнении синтаксического анализа или поиске способа анализа текста, возвращается исключение MalformedLineException .
Совет для профессионалов: как анализировать текст в MS Excel
В качестве окончательного и простого метода анализа текста вы можете использовать приложение MS Excel в качестве анализатора для создания файлов с разделителями табуляции и запятыми. Это поможет перепроверить ваш проанализированный результат и поможет найти, как исправить ошибку синтаксического анализа.
1. Выберите значения данных в исходном файле и нажмите одновременно клавиши Ctrl + C , чтобы скопировать файл.
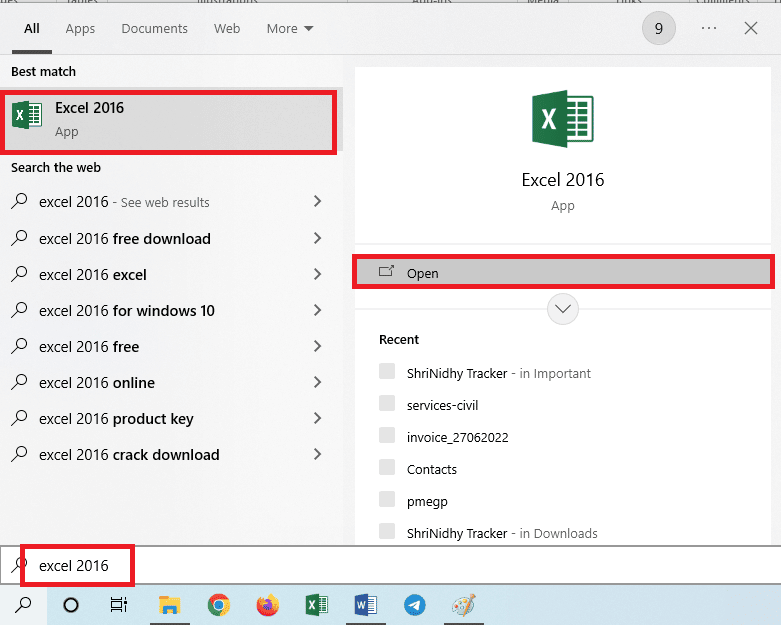
2. Откройте приложение Excel с помощью панели поиска Windows.
3. Щелкните ячейку A1 и одновременно нажмите клавиши Ctrl + V , чтобы вставить скопированный текст.
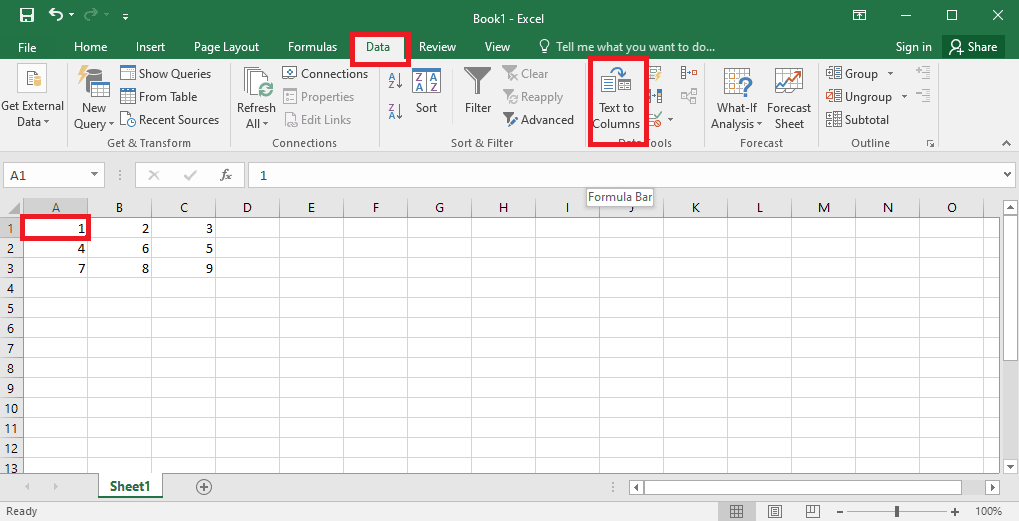
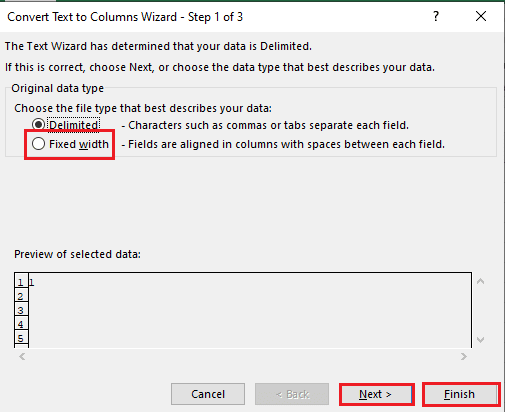
4. Выберите ячейку A1 , перейдите на вкладку « Данные » и щелкните параметр « Текст в столбцы » в разделе « Инструменты данных ».
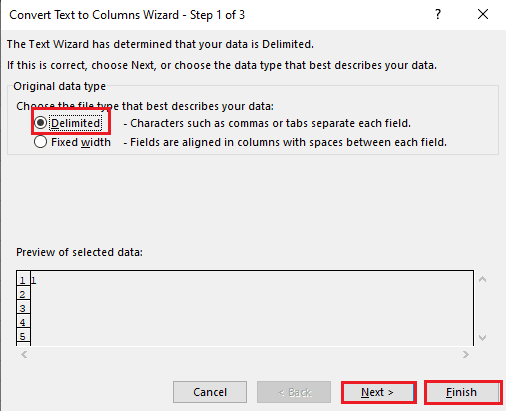
5А. Выберите параметр « С разделителями », если в качестве разделителя используется запятая или табуляция , и нажмите кнопки « Далее » и « Готово ».
5Б. Выберите параметр « Фиксированная ширина », задайте значение разделителя и нажмите кнопки « Далее » и « Готово ».
Читайте также: Как исправить ошибку перемещения столбца Excel
Как исправить ошибку синтаксического анализа
На устройствах Android может возникнуть ошибка в тексте синтаксического анализа x: Ошибка синтаксического анализа: возникла проблема при синтаксическом анализе пакета. Обычно это происходит, когда приложение не удается установить из магазина Google Play или при запуске стороннего приложения.
Текст ошибки x может возникнуть, если список векторов символов зациклен, а другие функции формируют линейную модель для вычисления значений данных. Сообщение об ошибке: Error in parse(text = x, keep.source = FALSE):<text>:2.0:неожиданный конец ввода 1:OffenceAgainst ~ ^.
Вы можете прочитать статью о том, как исправить ошибку синтаксического анализа на Android, чтобы узнать причины и способы исправления ошибки.
Помимо решений в руководстве, вы можете попробовать следующие исправления.
- Повторная загрузка файла .apk или восстановление имени файла.
- Восстановление изменений в файле Androidmanifest.xml , если у вас есть навыки программирования на уровне эксперта.
Рекомендуемые:
- Как удалить чужую учетную запись Facebook
- 10 главных навыков, необходимых для того, чтобы стать этичным хакером
- 21 лучшая альтернатива Pastebin для обмена кодом и текстом
- Исправить ошибку команды с кодом ошибки 1 Информация о яйце Python
Статья помогает научить анализировать текст и узнать, как исправить ошибку синтаксического анализа. Сообщите нам, какой метод помог исправить ошибку в разборе текста x и какой метод анализа предпочтительнее. Пожалуйста, поделитесь своими предложениями и вопросами в разделе комментариев ниже.