
Cum să utilizați comanda wc în Linux
Publicat: 2022-07-23
Numărarea numărului de linii, cuvinte și octeți dintr-un fișier este utilă, dar flexibilitatea reală a comenzii Linux wc vine din lucrul cu alte comenzi. Hai să aruncăm o privire.
Ce este comanda wc?
Comanda wc este o aplicație mică. Este unul dintre utilitarele Linux de bază, deci nu este nevoie să-l instalați. Va fi deja pe computerul dvs. Linux.
Puteți descrie ceea ce face în câteva cuvinte. Numărează liniile, cuvintele și octeții dintr-un fișier sau o selecție de fișiere și tipărește rezultatul într-o fereastră de terminal. De asemenea, poate prelua intrarea din fluxul STDIN, ceea ce înseamnă că textul pe care doriți să îl proceseze poate fi transmis în el. Aici wc începe cu adevărat să adauge valoare.

Este un exemplu grozav al mantrei Linux de „fă un lucru și fă-l bine”. Deoarece acceptă intrare prin conductă, poate fi folosit în incantații cu mai multe comandă. După cum vom vedea, acest mic utilitar de sine stătător este de fapt un excelent jucător de echipă.
Un mod în care folosesc wc este ca substituent într-o comandă complicată sau un alias pe care îl pregătesc. Dacă comanda finalizată are potențialul de a fi distructivă și de a șterge fișiere, folosesc adesea wc ca substitut pentru comanda reală și periculoasă.
În acest fel, în timpul dezvoltării comenzii primesc feedback vizual că fiecare fișier este procesat așa cum mă așteptam. Nu există nicio șansă să se întâmple ceva rău în timp ce mă lupt cu sintaxa.
Oricât de simplu este wc , există încă câteva mici ciudatenii despre care trebuie să știi.
Noțiuni introductive cu wc
Cel mai simplu mod de a utiliza wc este să treci numele unui fișier text pe linia de comandă.
wc lorem.txt

Acest lucru face ca wc să scaneze fișierul și să numere liniile, cuvintele și octeții și să le scrie în fereastra terminalului.
Cuvintele sunt considerate orice delimitat de spații albe. Indiferent dacă sunt cuvinte dintr-o limbă reală sau nu, este irelevant. Dacă un fișier nu conține altceva decât „frd g lkj”, acesta tot contează ca trei cuvinte.
Liniile sunt secvențe de caractere terminate fie printr-un retur de cărucior, fie prin sfârșitul fișierului. Nu contează dacă linia se înfășoară în editorul tău sau în fereastra terminalului, până când wc întâlnește o întoarcere de cărucior sau sfârșitul fișierului, este încă aceeași linie.
Primul nostru exemplu a găsit o linie în întregul fișier. Iată conținutul fișierului „lorem.txt”.
cat lorem.txt
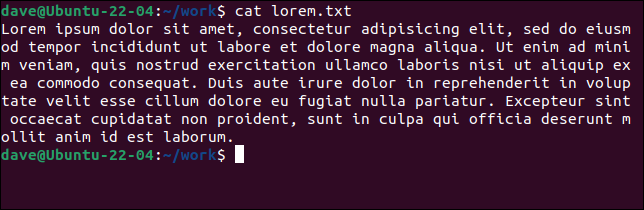
Toate acestea contează ca o singură linie, deoarece nu există retururi de transport. Comparați acest fișier cu un alt fișier, „lorem2.txt”, și modul în care wc îl interpretează.
wc lorem2.txt
cat lorem2.txt
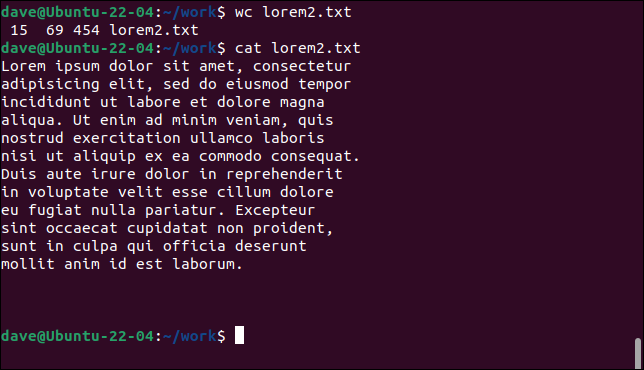
De data aceasta, wc numără 15 linii, deoarece returnările de cărucior au fost inserate în text pentru a începe o nouă linie în anumite puncte. Cu toate acestea, dacă numărați liniile cu text în ele, veți vedea că sunt doar 12.
Celelalte trei linii sunt linii goale la sfârșitul fișierului. Acestea conțin doar returnări de transport. Chiar dacă nu există text în aceste rânduri, a fost începută o nouă linie și astfel wc le numără ca atare.
Putem trece la wc câte fișiere ne dorim.
wc lorem.txt lorem2.txt
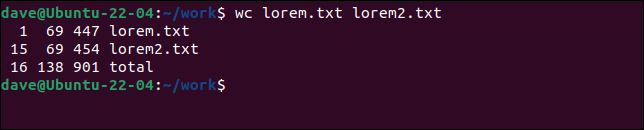
Obținem statisticile pentru fiecare fișier individual și un total pentru toate fișierele.
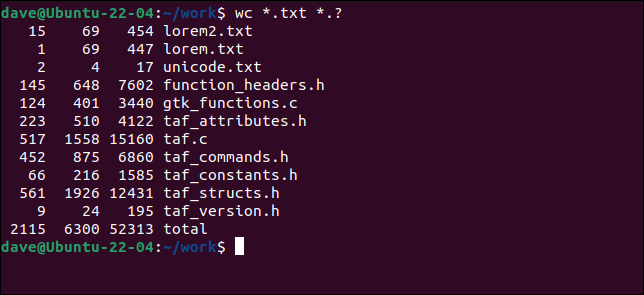
De asemenea, putem folosi metacaractere astfel încât să putem selecta fișiere care se potrivesc în loc de fișiere denumite în mod explicit.
wc *.txt *.?
Opțiunile liniei de comandă
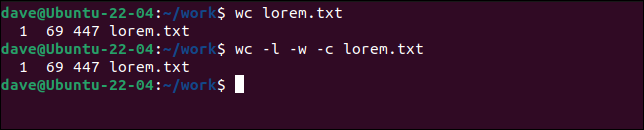
În mod implicit, wc va afișa liniile, cuvintele și octeții din fiecare fișier. Este la fel cu utilizarea opțiunilor -l (linii) -w (cuvinte) și -c (octeți).
wc lorem.txt
wc -l -w -c lorem.txt
Putem specifica ce combinație de figuri dorim să vedem.
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
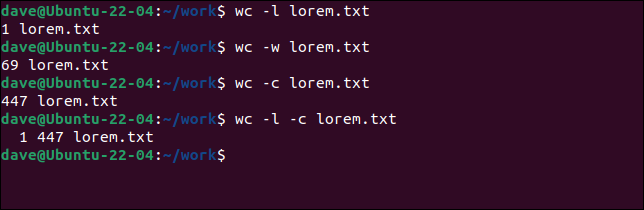
O atenție deosebită trebuie acordată ultimei cifre, generată de opțiunea -c (octeți). Mulți oameni greșesc asta ca numărând personajele. De fapt, numără octeții . Numărul de caractere și numărul de octeți ar putea fi același. Dar nu in totdeauna.
Să ne uităm la conținutul unui fișier numit „unicode.txt”.
cat unicode.txt

Are trei cuvinte și un caracter de alfabet non-latin. Vom lăsa wc să proceseze fișierul cu setarea implicită de octeți și o vom face din nou, dar vom solicita caractere cu opțiunea -m (caractere).
wc unicode.txt
wc -l -w -m unicode.txt
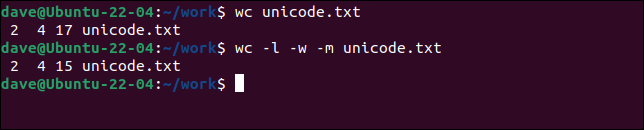
Există mai mulți octeți decât caractere.
Să aruncăm o privire la descărcarea hexagonală a fișierului și să vedem ce se întâmplă. Opțiunea -C (canonică) a comenzii hexdump afișează octeții din fișier în rânduri de 16, cu echivalentul lor simplu ASCII (dacă există unul) afișat la sfârșitul liniei. Dacă nu există niciun caracter ASCII corespunzător, un punct „ . ” este afișat în schimb.

hexdump -C unicode.txt
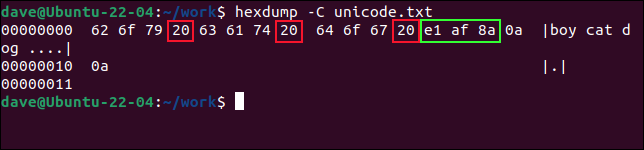
În ASCII, o valoare hexazecimală de 0x20 reprezintă un caracter spațiu. Dacă numărăm trei valori din stânga, vedem că următoarea valoare este un caracter spațiu. Deci primele trei valori 0x62 , 0x6f și 0x79 reprezintă literele din „băiat”.
Trecând peste 0x20 , vedem un alt set de trei valori hexazecimale: 0x63 , 0x61 și 0x74 . Acestea scriu „pisica”. Trecând peste următorul caracter spațiu, vedem încă trei valori pentru literele din „câine”. Acestea sunt 0x64 , 0x5f și 0x67 .
Chiar în spatele cuvântului „câine” putem vedea un caracter de spațiu 0x20 și încă cinci valori hexazecimale. Ultimele două sunt întoarceri de transport, 0x0a .
Ceilalți trei octeți reprezintă caracterul non-latin, pe care l-am sunat în verde. Este un caracter Unicode și este nevoie de trei octeți pentru a-l codifica. Acestea sunt 0xe1 , 0xaf și 0x8a .
Așa că asigurați-vă că știți ce numărați și că octeții și caracterele nu trebuie să fie la fel. De obicei, numărarea octeților este mai utilă, deoarece vă spune ce este de fapt în interiorul fișierului. Numărarea după caractere vă oferă numărul de lucruri reprezentate de conținutul fișierului.
RELATE: Ce sunt codificările de caractere precum ANSI și Unicode și cum diferă?
Preluarea numelor de fișiere dintr-un fișier
Există o altă modalitate de a furniza nume de fișiere pentru wc . Puteți pune numele fișierelor într-un fișier și puteți transmite numele acelui fișier la wc . Deschide fișierul, extrage numele fișierelor și le procesează ca și cum ar fi fost transmise pe linia de comandă. Acest lucru vă permite să stocați o colecție arbitrară de nume de fișiere pentru reutilizare.
Dar există o problemă, și este una mare. Numele de fișiere trebuie să fie terminate nul , nu retur de transport terminat. Adică, după fiecare nume de fișier trebuie să existe un octet nul de 0x00 în loc de octetul obișnuit de returnare a carului 0x0a .
Nu puteți deschide un editor și crea un fișier cu acest format. De obicei, fișierele ca acesta sunt generate de alte programe. Dar, dacă aveți un astfel de fișier, așa l-ați folosi.
Iată fișierul nostru care conține numele fișierelor. Deschiderea în less vă arată caracterele ciudate „ ^@ ” pe care le folosește less pentru a indica octeții nuli.
mai puțin fișiere-sursă-list.txt

Pentru a folosi fișierul cu wc , trebuie să folosim --files0-from (citește intrarea de la) și să trecem numele fișierului care conține numele fișierelor.
wc ---files0-from=source-files-list.txt
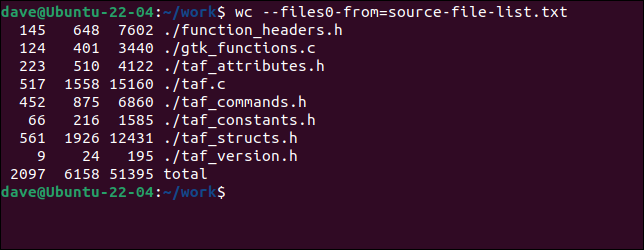
Fișierele sunt procesate exact ca și cum ar fi furnizate pe linia de comandă.
Conducte de intrare la wc
O modalitate mult mai comună, mai flexibilă și mai productivă de a trimite intrare la wc este de a direcționa ieșirea de la alte comenzi în wc . Putem demonstra acest lucru cu comanda echo .
echo „Numără asta pentru mine” | toaleta
echo -e „Numără asta\npentru mine” | toaleta
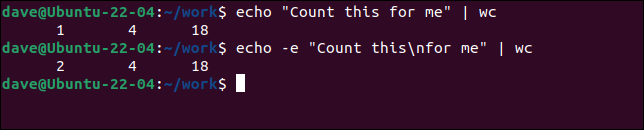
Cea de-a doua comandă echo folosește opțiunea -e (caractere escape) pentru a permite secvențe escape, cum ar fi codul de formatare newline „ \n ”. Aceasta injectează o nouă linie, determinând wc să vadă intrarea ca două linii.
Iată o cascadă de comenzi care își alimentează intrarea de la una la alta.
găsi ./* -tip f | rev | cut -d'.' -f1 | rev | sortare | unic
- find caută fișiere (
type -f) recursiv, începând din directorul curent.revinversează numele fișierelor. - cut extrage primul câmp (
-f1) prin definirea delimitatorului câmpului ca punct „.” și citirea din „fața” a numelui de fișier inversat până la prima perioadă pe care o găsește. Acum am extras extensia fișierului. - rev inversează primul câmp extras.
- sortează le sortează în ordine alfabetică crescătoare.
- uniq listează intrări unice în fereastra terminalului.
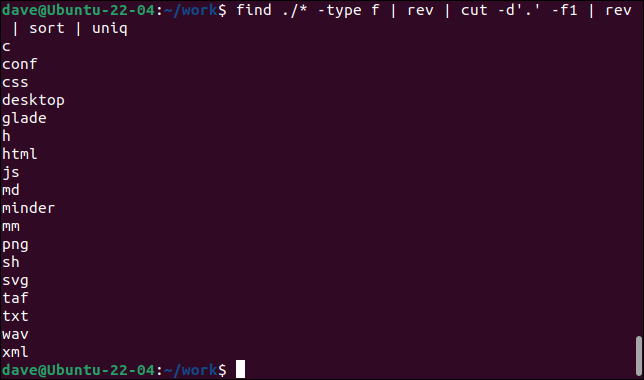
Această comandă listează toate extensiile de fișiere unice din directorul curent și orice subdirectoare.
Dacă am adăugat opțiunea -c (numărare) la comanda uniq , aceasta ar număra aparițiile fiecărui tip de extensie. Dar dacă vrem să știm câte extensii de fișiere diferite și unice există, putem să aruncăm wc ca ultima comandă de pe linie și să folosim opțiunea -l (linii).
găsi ./* -tip f | rev | cut -d'.' -f1 | rev | sortare | unic | wc -l

LEGATE: Cum să utilizați comanda Linux cut
Și, în sfârșit
Iată un ultim truc pe care wc îl poate face pentru tine. Vă va spune lungimea celei mai lungi linii dintr-un fișier. Din păcate, nu vă spune despre ce linie este. Îți dă doar lungimea.
wc -L taf.c

Atenție totuși, că filele sunt numărate ca opt spații. Vizualizate în editorul meu, există trei file cu două spații la începutul acelei linii. Lungimea sa reală este de 124 de caractere. Deci cifra raportată este extinsă artificial.
Aș trata această funcție cu un praf mare de sare. Și prin asta vreau să spun să nu-l folosești. Rezultatul său este înșelător.
În ciuda particularităților sale, wc este un instrument grozav pentru a introduce comenzile introduse atunci când trebuie să numărați tot felul de valori, nu doar cuvintele dintr-un fișier.
RELATE: 37 de comenzi Linux importante pe care ar trebui să le cunoașteți