
Cum funcționează motorul de căutare și cum îți face viața mai ușoară?
Publicat: 2015-11-06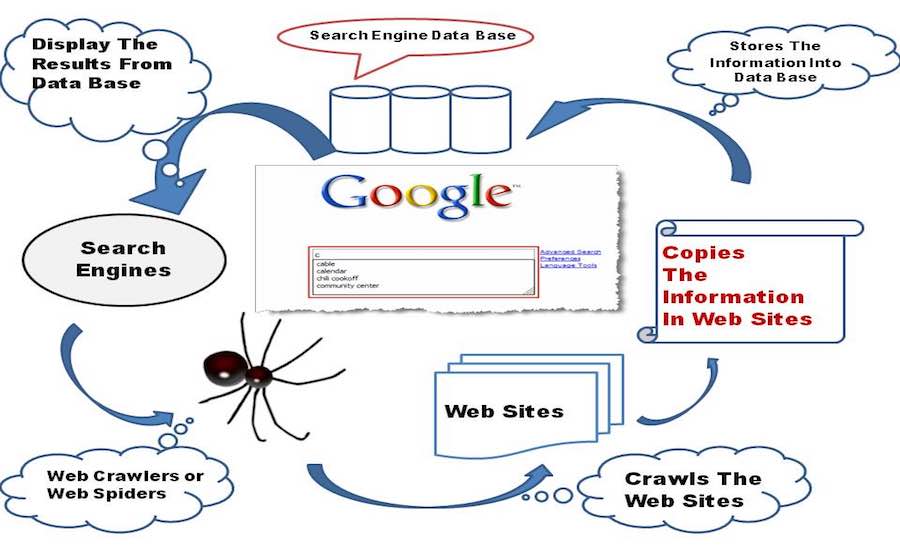 Short Bytes: Motorul de căutare este un software care permite afișarea rezultatelor relevante ale paginii web pe baza interogării de căutare introduse prin utilizarea crawling-ului web și a indexării web, a unor formule grase și a algoritmilor inteligenți pentru a aduna datele corespunzătoare.
Short Bytes: Motorul de căutare este un software care permite afișarea rezultatelor relevante ale paginii web pe baza interogării de căutare introduse prin utilizarea crawling-ului web și a indexării web, a unor formule grase și a algoritmilor inteligenți pentru a aduna datele corespunzătoare.
Cum vă oferă Google cele mai bune rezultate dintr-o clipă? De fapt, nu contează până când Google, Bing sunt acolo. Scenariul ar fi fost foarte diferit dacă nu ar exista Google, Bing sau Yahoo. Să ne scufundăm în lumea motoarelor de căutare și să vedem cum funcționează un motor de căutare.
Privind în istorie
Basmul motorului de căutare a început în anii 1990, când Tim Berners-Lee obișnuia să înroleze fiecare nou server web care intra online, pe lista ținută de serverul web CERN. Până în septembrie 93, nu existau motoare de căutare pe internet, ci doar câteva instrumente capabile să mențină o bază de date cu nume de fișiere. Archie, Veronica, Jughead au fost primii participanți la această categorie.
Oscar Nierstrasz de la Universitatea din Geneva este acreditat pentru primul motor de căutare care a apărut, numit W3Catalog. A făcut niște scripturi Perl serioase și, în cele din urmă, a lansat primul motor de căutare din lume pe 3 septembrie 1993. În plus, anul 1993 a văzut apariția multor alte motoare de căutare. JumpStation de Jonathon Fletcher, AliWeb, WWW Worm etc. Yahoo! a fost lansat în 1995 ca director web, dar a început să folosească motorul de căutare Inktomi din 2000 și apoi a trecut la Bing de la Microsoft în 2009.
Acum, vorbind despre numele care este sinonimul principal pentru termenul motor de căutare, Google Search, a fost un proiect de cercetare pentru doi absolvenți de la Stanford, Larry Page și Sergy Brin, care a avut amprentele inițiale în martie 1995. Lucrarea Google a fost inițial inspirată. prin metoda de back-link a paginii, care făcea calcule bazate pe câte backlink-uri provin dintr-o pagină web, pentru a măsura importanța acelei pagini în World Wide Web. „Cel mai bun sfat pe care l-am primit vreodată”, a spus Page, în timp ce își amintea, modul în care supervizorul său Terry Winograd i-a susținut ideea. Și de atunci, Google nu s-a uitat niciodată înapoi.
Totul începe cu un târâș
Un motor de căutare pentru copii aflat în stadiu incipient începe să exploreze World Wide Web, cu mâinile și genunchii săi mici, explorează orice link pe care îl găsește pe o pagină web și le stochează în baza de date.
Acum, să ne concentrăm asupra unor gânduri tehnice din spatele scenei, un motor de căutare încorporează un software Web Crawler care este practic un bot de internet căruia i-a fost atribuit sarcina de a deschide toate hyperlinkurile prezente pe o pagină web și de a crea o bază de date de text și metadate din toate linkurile. . Începe cu un set inițial de link-uri de vizitat, numite Semințe. De îndată ce continuă cu accesarea acestor linkuri, adaugă linkuri noi în lista existentă de adrese URL de vizitat, cunoscută sub numele de Crawl Frontier.
Pe măsură ce crawler-ul traversează link-urile, descarcă informațiile din acele pagini web pentru a fi vizualizate ulterior sub formă de instantanee, deoarece descărcarea întregii pagini web ar necesita o mulțime de date și are un preț de buzunar, cel puțin în țări precum India. Și pot paria, dacă Google ar fi fondat în India, toți banii lor ar fi folosiți pentru a plăti facturile de internet. Sper că nu este un subiect de îngrijorare deocamdată.
Crawler-ul web explorează paginile web pe baza unor politici:
Politica de selecție: crawler-ul decide ce pagini ar trebui să descarce și care nu. Politica de selecție se concentrează pe descărcarea celui mai relevant conținut al unei pagini web, mai degrabă decât pe unele date neimportante.
Politica de re-vizitare: Crawler programează ora la care ar trebui să redeschidă paginile web și să editeze modificările din baza sa de date, datorită naturii dinamice a internetului, care face foarte greu ca Crawler-ul să rămână actualizat cu cele mai recente versiuni de paginile web.
Politica de paralelizare: crawlerele folosesc mai multe procese simultan pentru a explora legăturile cunoscute sub numele de crawling distribuit, dar uneori există șanse ca diferite procese să descarce aceeași pagină web, astfel încât crawler-ul menține o coordonare între toate procesele pentru a elimina orice șansă de duplicitate.
Politica de politețe: Când un crawler traversează un site web, descarcă simultan pagini web de pe acesta, crescând astfel încărcătura serverului web care găzduiește site-ul web. Prin urmare, este implementat un termen „Crawler-Delay” în care crawler-ul trebuie să aștepte câteva secunde după ce descarcă unele date de pe un server web și este guvernat de Politeness Policy.
Citiți și: Cum să construiți un crawler web de bază în Python
Arhitectura de nivel înalt a unui crawler web standard:
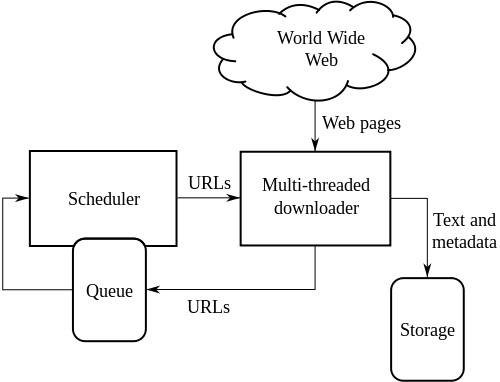
Ilustrația de mai sus ilustrează cum funcționează un crawler web. Deschide lista inițială de link-uri și apoi link-uri în interiorul acelor link-uri și așa mai departe.
Wikipedia scrie, cercetătorii în informatică Vladislav Shkapenyuk și Torsten Suel au remarcat că:
Deși este destul de ușor să construiți un crawler lent care descarcă câteva pagini pe secundă pentru o perioadă scurtă de timp, construirea unui sistem de înaltă performanță care poate descărca sute de milioane de pagini în câteva săptămâni prezintă o serie de provocări în proiectarea sistemului, Eficiența I/O și a rețelei, și robustețe și manevrabilitate.
Indexarea crawlerilor
După ce motorul de căutare pentru copii se târăște pe tot internetul, creează un index al tuturor paginilor web pe care le găsește în cale. A avea un index este mult mai bine decât a pierde timpul găsind interogarea de căutare dintr-o grămadă de documente de dimensiuni mari, aceasta va economisi atât timp, cât și resurse.
Există mulți factori care contribuie la crearea unui sistem de indexare eficient pentru un motor de căutare. Tehnicile de stocare utilizate de indexatori, dimensiunea indexului, capacitatea de a găsi rapid documentele care conțin cuvintele cheie căutate etc. sunt factorii responsabili pentru eficiența și fiabilitatea unui index.
Unul dintre obstacolele majore în calea spre realizarea de indici web de succes este coliziunea dintre două procese. Să presupunem că un proces dorește să caute un document și, în același timp, un alt proces dorește să adauge un document în index, creează un fel de conflict între cele două procese. Problema este mai agravată de implementarea calculului distribuit de către motoarele de căutare pentru a gestiona mai multe date.
Tipuri de index
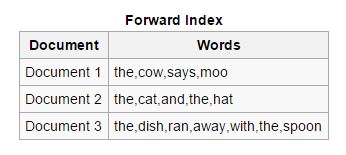
Forward: În acest tip de indici, toate cuvintele cheie prezente într-un document sunt stocate într-o listă. Indexul direct este ușor de creat în faza de început a indexării, deoarece permite indexatorilor asincroni să colaboreze între ei.
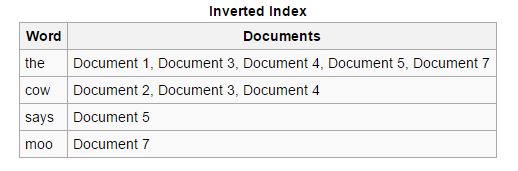
Reverse: indicii forward sunt sortați și convertiți în indici inversați, în care fiecare document care conține un anumit cuvânt cheie este pus împreună cu alte documente care conțin acel cuvânt cheie. Indicii inversi ușurează procesul de găsire a documentelor relevante pentru o anumită interogare de căutare, ceea ce nu este cazul indicilor forward.

Citește și: Ce este DNS (Domain Name System) și cum funcționează?
Analiza documentelor
Denumită și tokenizare, se referă la defalcarea componentelor unui document, cum ar fi cuvinte cheie (numite tokens), imagini și alte medii, astfel încât acestea să poată fi inserate în indici ulterior. Metoda se concentrează, practic, pe înțelegerea limbii native și pe prezicerea cuvintelor cheie pe care le-ar putea căuta un utilizator, care servesc drept bază pentru crearea unui sistem eficient de indexare web.
Principalele provocări includ găsirea limitelor de cuvinte ale cuvintelor cheie care urmează să fie extrase, deoarece putem vedea limbi precum chineza și japoneză, în general, nu au spații albe în scripturile lor de limbă. Înțelegerea ambiguității pe care o posedă o limbă este, de asemenea, un punct de îngrijorare, deoarece unele limbi încep să difere ușor sau chiar considerabil în funcție de schimbările geografice. De asemenea, ineficiența unor pagini web de a nu menționa în mod clar limbajul folosit este, de asemenea, un motiv de îngrijorare și crește volumul de lucru pe indexare.
Motoarele de căutare au capacitatea de a recunoaște diferite formate de fișiere și de a extrage cu succes date din ele și este necesar să se acorde o atenție deosebită în aceste cazuri.
Meta tag-urile sunt, de asemenea, foarte utile în crearea indicilor foarte rapid, reduc eforturile indexatorului web și ușurează necesitatea de a analiza complet întregul document. Veți găsi etichete meta atașate în partea de jos a acestui articol.
Căutarea indexului
Acum, motorul de căutare pentru bebeluși nu mai este un bebeluș, el a învățat cum să se târască și să apuce lucrurile rapid și eficient și cum să-și aranjeze lucrurile sistematic. Să presupunem că prietenul lui îi cere să găsească ceva din aranjamentul lui, ce va face? Există patru tipuri de interogări de căutare utilizate, deși nu sunt derivate în mod formal, dar au evoluat de-a lungul timpului și s-au dovedit a fi valabile în ceea ce privește interogările din viața reală făcute de utilizatori.
Navigație: Acest termen este folosit pentru acele interogări în care utilizatorul dorește să acceseze o anumită pagină web sau site web existent pe internet. De exemplu, când căutați fossBytes pe Google, atunci inițiați o interogare de navigare.
Informațional: Acest tip de interogări au mii de rezultate și acoperă subiecte generale care îmbunătățesc cunoștințele utilizatorului. De exemplu, când căutați, să spunem Steve Jobs, vi se vor prezenta toate linkurile relevante pentru Steve Jobs.
Tranzacțional: Interogările care se concentrează pe intenția utilizatorului de a efectua o anumită acțiune pot implica un set predefinit de instrucțiuni. De exemplu, Cum să-ți găsești laptopul pierdut/furat?
Conectivitate: Aceste tipuri de interogări nu sunt utilizate frecvent, ele se concentrează pe cât de conectat este indexul creat de pe un site web. De exemplu, dacă căutați, Câte pagini există pe Wikipedia?
Google și Bing au creat niște algoritmi serioși care sunt suficient de capabili pentru a determina cele mai relevante rezultate pentru interogarea dvs. Google pretinde că calculează rezultatele căutării dvs. pe baza a peste 200 de factori, cum ar fi calitatea conținutului, nou sau vechi, siguranța paginii web și multe altele. Ei au cele mai mari minți din lume numite în laboratoarele lor de căutare, care fac calcule grele și se ocupă de formule uimitoare, doar pentru a face Căutarea mai simplă și mai rapidă pentru tine.
Alte caracteristici notabile*
Căutare de imagini: veți fi surprinși să aflați inspirația Google din spatele celebrului lor instrument de căutare de imagini. J.Lo, da, ai auzit bine, J.Lo și rochia ei verde Versace(ver-sah-chay) la Premiile Grammy, 2000, au fost adevăratul motiv pentru care Google a apărut cu căutarea de imagini, deoarece oamenii erau ocupați să caute pe Google. a ei.
A spus Eric Schmidt în scrierea sa intitulată „The Tinkerer's Apprentice”, publicată pe 19 ianuarie 2015.
Căutare vocală: Google a fost primul care a introdus căutarea vocală în motorul său de căutare după multă muncă grea și, ulterior, și alte motoare de căutare au implementat-o.
Combaterea spamului: motoarele de căutare implementează niște algoritmi serioși, astfel încât să te poată proteja de atacurile de spam . Un spam este practic un mesaj sau un fișier care este răspândit pe tot internetul, poate pentru publicitate sau pentru transmiterea de viruși. De asemenea, în această problemă, băieții Google informează manual site-ul web pe care îl consideră responsabil pentru răspândirea mesajelor spam pe internet.
Optimizarea locației: motoarele de căutare sunt acum capabile să afișeze rezultate în funcție de locația utilizatorului. Dacă căutați, Cum este vremea în Bengaluru, atunci statisticile meteo vor fi în raport cu Bengaluru.
Te înțelege mai bine: motoarele de căutare moderne sunt capabile să înțeleagă semnificația interogării utilizatorului, mai degrabă decât să găsească cuvintele cheie introduse de utilizator.
Completare automată : abilitatea de a prezice interogarea dvs. de căutare pe măsură ce introduceți text, pe baza căutărilor dvs. anterioare și a căutărilor efectuate de alți utilizatori.
Knowledge Graph: Această funcție, oferită de Căutarea Google, arată capacitatea sa de a oferi rezultate de căutare bazate pe oameni, locuri și evenimente din viața reală.
Control parental: Motoarele de căutare le permit părinților de mici dimensiuni să controleze ceea ce a făcut copilul lor pe internet.
* Este greu de acoperit lista vastă de caracteristici oferite de aceste puternice motoare de căutare.
Lichidare
Motoarele de căutare au contribuit la simplificarea vieții noastre, iar munca grea pe care o depun pentru a valorifica toate informațiile de pe internet este neprețuită. Dar această explorare a dus la expunerea spațiului nostru personal pe o platformă publică și trebuie să spun că este timpul să ne frământăm de drumul pe care l-am parcurs atâta timp, cu excepția cazului în care este prea târziu pentru a ne retrospecta acțiunile. iar viața noastră să fie doar o bienală a stânjenilor. Nu putem nega faptul că motoarele de căutare sunt acum o parte vitală a personalității noastre digitale separate. Trebuie doar să folosim tehnologia care ne-a fost dată, nu să-i permitem să ne înrobească în lanțurile propriilor noastre fapte rele.
Bine, gata de discuții emoționante, doar adoră drăgălașul și talentele acelui motor de căutare pentru copii care acum a devenit adolescent și te înțelege mult mai bine. Google a fost acolo pentru a căuta totul pentru noi, este internetul pentru mulți dintre noi și trebuie să prețuim acele experiențe bune pe care le-am câștigat când folosim Căutarea Google. Oh! Am uitat să menționez Bing, și tu ești minunat. Fii atent, fii în siguranță și pe Google.
Urmăriți acest videoclip și aflați mai multe despre motoarele de căutare:
Ați făcut vreodată clic pe butonul Mă simt norocos din Căutarea Google? Deschide-l și spune-ne care doodle ți-a plăcut cel mai mult în secțiunea de comentarii de mai jos.