
Cum să analizați datele CSV în Bash
Publicat: 2022-09-16
Fișierele cu valori separate prin virgulă (CSV) sunt unul dintre cele mai comune formate pentru datele exportate. Pe Linux, putem citi fișiere CSV folosind comenzile Bash. Dar poate deveni foarte complicat, foarte repede. Vom da o mână de ajutor.
Ce este un fișier CSV?
Un fișier cu valori separate prin virgulă este un fișier text care conține date tabulate. CSV este un tip de date delimitate. După cum sugerează și numele, o virgulă „ , ” este folosită pentru a separa fiecare câmp de date – sau valoare – de vecinii săi.
CSV este peste tot. Dacă o aplicație are funcții de import și export, aproape întotdeauna va accepta CSV. Fișierele CSV pot fi citite de om. Puteți să vă uitați în interiorul lor cu mai puțin, să le deschideți în orice editor de text și să le mutați de la program la program. De exemplu, puteți exporta datele dintr-o bază de date SQLite și le puteți deschide în LibreOffice Calc.
Cu toate acestea, chiar și CSV poate deveni complicat. Doriți să aveți o virgulă într-un câmp de date? Câmpul respectiv trebuie să aibă ghilimele „ " ” înconjurate. Pentru a include ghilimele într-un câmp, fiecare ghilimele trebuie introdus de două ori.
Desigur, dacă lucrați cu CSV generat de un program sau script pe care l-ați scris, este probabil ca formatul CSV să fie simplu și direct. Dacă ești forțat să lucrezi cu formate CSV mai complexe, Linux fiind Linux, există soluții pe care le putem folosi și pentru asta.
Câteva date eșantion
Puteți genera cu ușurință câteva exemple de date CSV, folosind site-uri precum Generatorul de date online. Puteți defini câmpurile dorite și alegeți câte rânduri de date doriți. Datele dvs. sunt generate folosind valori fictive realiste și descărcate pe computer.
Am creat un fișier care conține 50 de rânduri de informații false ale angajaților:
- id : O valoare întreagă unică simplă.
- prenume : prenumele persoanei.
- lastname : Numele de familie al persoanei.
- job-title : titlul postului persoanei.
- email-address : adresa de e-mail a persoanei.
- ramură : filiala companiei în care lucrează.
- stare : statul în care se află sucursala.
Unele fișiere CSV au o linie de antet care listează numele câmpurilor. Fișierul nostru exemplu are unul. Iată partea de sus a fișierului nostru:
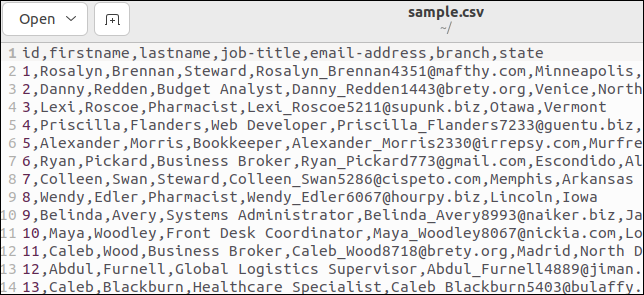
Prima linie conține numele câmpurilor ca valori separate prin virgulă.
Analizarea datelor din fișierul CSV
Să scriem un script care va citi fișierul CSV și va extrage câmpurile din fiecare înregistrare. Copiați acest script într-un editor și salvați-l într-un fișier numit „field.sh”.
#! /bin/bash în timp ce IFS="," citește -r id prenume prenume titlu job e-mail stare ramură do echo „ID înregistrare: $id” echo "Prenumele: $prenume" echo " Nume: $nume" echo „Titlul postului: $jobtitle” echo "Adăugați e-mail: $email" echo " Ramura: $ramură" echo " Stare: $state" ecou "" terminat < <(coada -n +2 sample.csv)
Există destul de mult în micul nostru scenariu. Să-l descompunem.

Folosim o buclă while . Atâta timp cât condiția buclei while se rezolvă la adevărat, corpul buclei while va fi executat. Corpul buclei este destul de simplu. O colecție de instrucțiuni echo sunt folosite pentru a imprima valorile unor variabile în fereastra terminalului.
Condiția buclei while este mai interesantă decât corpul buclei. Precizăm că trebuie folosită o virgulă ca separator de câmp intern, cu instrucțiunea IFS="," . IFS este o variabilă de mediu. Comanda de read se referă la valoarea sa atunci când parsează secvențe de text.
Folosim opțiunea -r (reține barele oblice inverse) a comenzii de read pentru a ignora orice bare oblice inverse care ar putea fi în date. Vor fi tratați ca personaje obișnuite.
Textul pe care îl parsează comanda de read este stocat într-un set de variabile numite după câmpurile CSV. La fel de ușor ar fi putut fi numite câmp1, field1, field2, ... field7 , dar numele semnificative fac viața mai ușoară.
Datele sunt obținute ca rezultat din comanda tail . Folosim tail deoarece ne oferă o modalitate simplă de a sări peste linia antetului fișierului CSV. Opțiunea -n +2 (numărul liniei) îi spune lui tail să înceapă să citească la rândul numărul doi.
Construcția <(...) se numește substituție de proces. Determină Bash să accepte rezultatul unui proces ca și cum ar proveni dintr-un descriptor de fișier. Acesta este apoi redirecționat în bucla while , furnizând textul pe care comanda de read îl va analiza.
Faceți scriptul executabil folosind comanda chmod . Va trebui să faceți acest lucru de fiecare dată când copiați un script din acest articol. Înlocuiți numele scriptului corespunzător în fiecare caz.
chmod +x field.sh

Când rulăm scriptul, înregistrările sunt împărțite corect în câmpurile lor constitutive, fiecare câmp stocat într-o variabilă diferită.
./câmp.sh
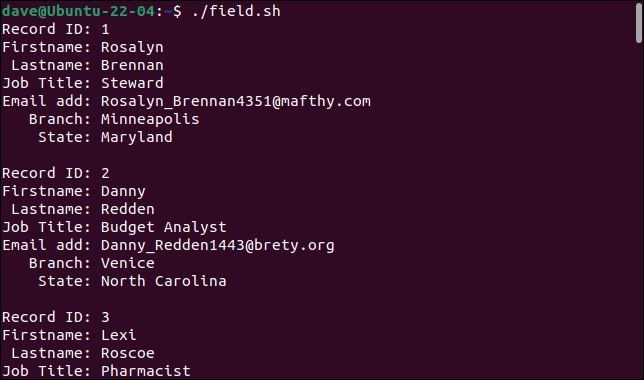
Fiecare înregistrare este tipărită ca un set de câmpuri.
Selectarea Câmpurilor
Poate că nu vrem sau nu trebuie să recuperăm fiecare câmp. Putem obține o selecție de câmpuri prin încorporarea comenzii cut .
Acest script se numește „select.sh”.
#!/bin/bash în timp ce IFS="," citește -r id jobtitle stare de ramură do echo „ID înregistrare: $id” echo „Titlul postului: $jobtitle” echo " Ramura: $ramură" echo " Stare: $state" ecou "" terminat < <(cut -d "," -f1,4,6,7 sample.csv | coada -n +2)
Am adăugat comanda cut în clauza de înlocuire a procesului. Folosim opțiunea -d (delimitator) pentru a spune cut să folosească virgulele „ , ” ca delimitator. Opțiunea -f (câmp) spune cut că vrem câmpurile unu, patru, șase și șapte. Aceste patru câmpuri sunt citite în patru variabile, care sunt imprimate în corpul buclei while .
Aceasta este ceea ce obținem când rulăm scriptul.
./select.sh
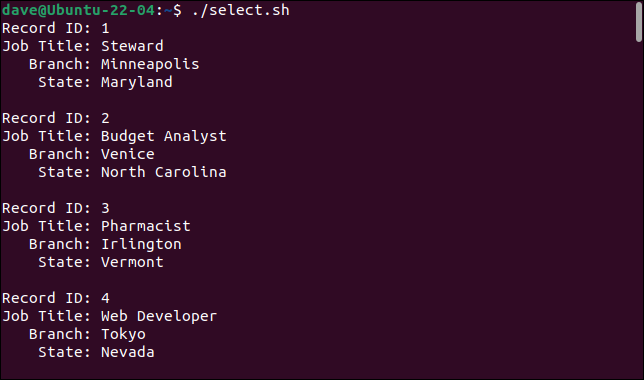
Adăugând comanda cut , putem să selectăm câmpurile pe care le dorim și să le ignorăm pe cele pe care nu le facem.
Până acum, bine. Dar…
Dacă CSV-ul cu care vă ocupați este simplu, fără virgule sau ghilimele în datele de câmp, ceea ce am acoperit probabil va satisface nevoile dvs. de analiză CSV. Pentru a arăta problemele pe care le putem întâlni, am modificat un mic eșantion de date pentru a arăta astfel.
id, prenume, prenume, titlul postului, adresă de e-mail, sucursală, stat 1, Rosalyn, Brennan, „Steward, Senior”, [email protected], Minneapolis, Maryland 2,Danny,Redden,"Analist ""Buget""",[email protected], Venice, Carolina de Nord 3, Lexi, Roscoe, Farmacist, Irlington, Vermont
- Înregistrarea unu are o virgulă în câmpul
job-title, așa că câmpul trebuie să fie împachetat între ghilimele. - Înregistrarea doi are un cuvânt înfășurat în două seturi de ghilimele în câmpul
jobs-titlepostului. - Înregistrarea trei nu are date în câmpul
email-address.
Aceste date au fost salvate ca „sample2.csv”. Modificați scriptul „field.sh” pentru a apela „sample2.csv” și salvați-l ca „field2.sh”.

#! /bin/bash în timp ce IFS="," citește -r id prenume prenume titlu job e-mail stare ramură do echo „ID înregistrare: $id” echo "Prenumele: $prenume" echo " Nume: $nume" echo „Titlul postului: $jobtitle” echo "Adăugați e-mail: $email" echo " Ramura: $ramură" echo " Stare: $state" ecou "" terminat < <(coada -n +2 sample2.csv)
Când rulăm acest script, putem vedea fisuri care apar în analizatorii CSV simpli.
./field2.sh

Prima înregistrare împarte câmpul cu titlul postului în două câmpuri, tratând a doua parte drept adresa de e-mail. Fiecare câmp după aceasta este mutat cu un loc la dreapta. Ultimul câmp conține atât valorile de branch , cât și de state .
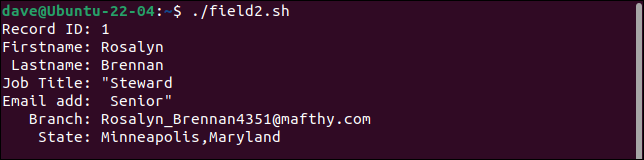
A doua înregistrare păstrează toate ghilimelele. Ar trebui să aibă doar o singură pereche de ghilimele în jurul cuvântului „Buget”.
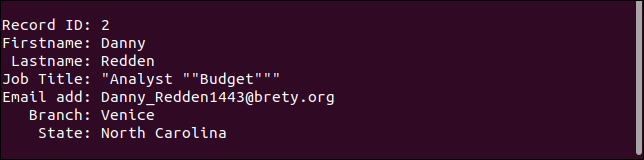
A treia înregistrare tratează de fapt câmpul lipsă așa cum ar trebui. Adresa de e-mail lipsește, dar totul este așa cum ar trebui.

În mod contraintuitiv, pentru un format de date simplu, este foarte dificil să scrieți un parser CSV general robust. Instrumente precum awk vă vor permite să vă apropiați, dar există întotdeauna cazuri marginale și excepții care se strecoară.

Încercarea de a scrie un parser CSV infailibil nu este probabil cea mai bună cale de urmat. O abordare alternativă – mai ales dacă lucrați la un anumit termen limită – folosește două strategii diferite.
Una este să utilizați un instrument conceput special pentru a vă manipula și extrage datele. Al doilea este să vă igienizați datele și să înlocuiți scenariile cu probleme, cum ar fi virgulele încorporate și ghilimelele. Parserii dvs. simpli Bash pot face față apoi CSV-ului prietenos cu Bash.
Setul de instrumente csvkit
Setul de instrumente CSV csvkit este o colecție de utilitare creată în mod expres pentru a ajuta la lucrul cu fișierele CSV. Va trebui să îl instalați pe computer.
Pentru a-l instala pe Ubuntu, utilizați această comandă:
sudo apt install csvkit

Pentru a-l instala pe Fedora, trebuie să tastați:
sudo dnf install python3-csvkit

Pe Manjaro comanda este:
sudo pacman -S csvkit

Dacă îi transmitem numele unui fișier CSV, utilitarul csvlook afișează un tabel care arată conținutul fiecărui câmp. Conținutul câmpului este afișat pentru a arăta ce reprezintă conținutul câmpului, nu așa cum este stocat în fișierul CSV.
Să încercăm csvlook cu fișierul nostru problematic „sample2.csv”.
csvlook sample2.csv
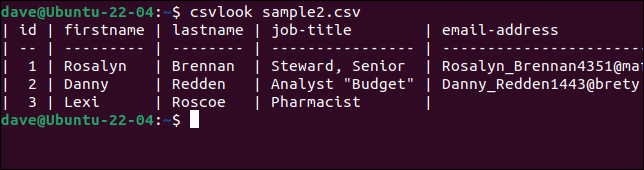
Toate câmpurile sunt afișate corect. Acest lucru demonstrează că problema nu este CSV. Problema este că scripturile noastre sunt prea simpliste pentru a interpreta CSV-ul corect.
Pentru a selecta anumite coloane, utilizați comanda csvcut . Opțiunea -c (coloană) poate fi utilizată cu nume de câmpuri sau numere de coloane sau o combinație a ambelor.
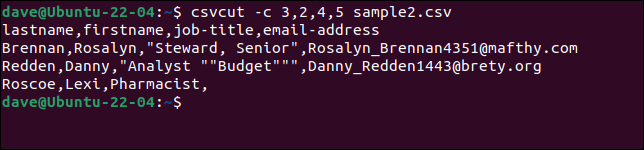
Să presupunem că trebuie să extragem numele și prenumele, titlurile postului și adresele de e-mail din fiecare înregistrare, dar dorim să avem ordinea numelui ca „nume, prenume”. Tot ce trebuie să facem este să punem numele câmpurilor sau numerele în ordinea dorită.
Aceste trei comenzi sunt toate echivalente.
csvcut -c nume, prenume, titlul postului, adresa de e-mail sample2.csv
csvcut -c nume, prenume,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
Putem adăuga comanda csvsort pentru a sorta rezultatul după un câmp. Folosim opțiunea -c (coloană) pentru a specifica coloana după care să sortăm și opțiunea -r (invers) pentru a sorta în ordine descrescătoare.
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
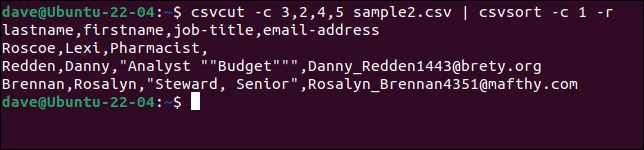
Pentru a face ieșirea mai frumoasă, o putem alimenta prin csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
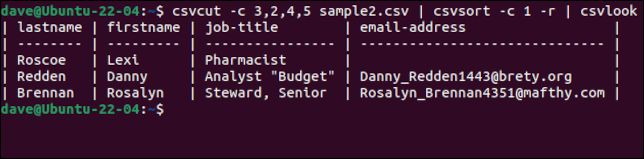
O notă bună este că, deși înregistrările sunt sortate, linia antetului cu numele câmpurilor este păstrată ca primă linie. Odată ce suntem fericiți că avem datele așa cum le dorim, putem elimina csvlook din lanțul de comandă și putem crea un nou fișier CSV redirecționând rezultatul într-un fișier.
Am adăugat mai multe date la „sample2.file”, am eliminat comanda csvsort și am creat un nou fișier numit „sample3.csv”.
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

O modalitate sigură de a igieniza datele CSV
Dacă deschideți un fișier CSV în LibreOffice Calc, fiecare câmp va fi plasat într-o celulă. Puteți utiliza funcția de căutare și înlocuire pentru a căuta virgule. Le puteți înlocui cu „nimic”, astfel încât să dispară, sau cu un caracter care să nu afecteze analiza CSV, cum ar fi un punct și virgulă „ ; " de exemplu.
Nu veți vedea ghilimele în jurul câmpurilor citate. Singurele ghilimele pe care le veți vedea sunt ghilimelele încorporate în datele câmpului. Acestea sunt afișate ca ghilimele simple. Găsirea și înlocuirea acestora cu un singur apostrof „ ' ” va înlocui ghilimelele duble din fișierul CSV.
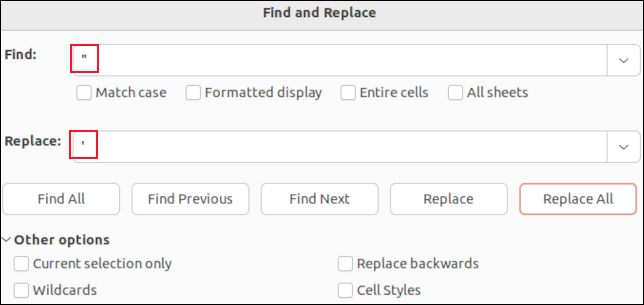
Găsirea și înlocuirea într-o aplicație precum LibreOffice Calc înseamnă că nu puteți șterge accidental niciuna dintre virgulele separatoare de câmpuri și nici nu puteți șterge ghilimelele din jurul câmpurilor citate. Veți modifica doar valorile datelor din câmpuri.
Am schimbat toate virgulele din câmpurile cu punct și virgulă și toate ghilimelele încorporate cu apostrofe și am salvat modificările.
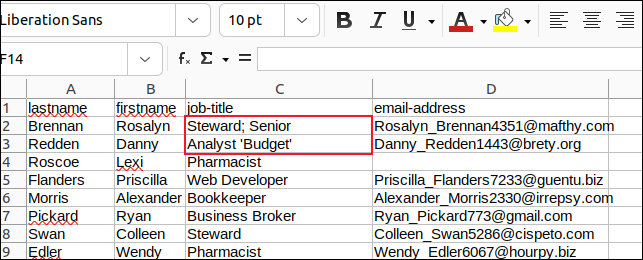
Apoi am creat un script numit „field3.sh” pentru a analiza „sample3.csv”.
#! /bin/bash în timp ce IFS="," citește -r nume prenume titlu job e-mail do echo " Nume: $nume" echo "Prenumele: $prenume" echo „Titlul postului: $jobtitle” echo "Adăugați e-mail: $email" ecou "" terminat < <(coada -n +2 sample3.csv)
Să vedem ce obținem când îl rulăm.
./field3.sh
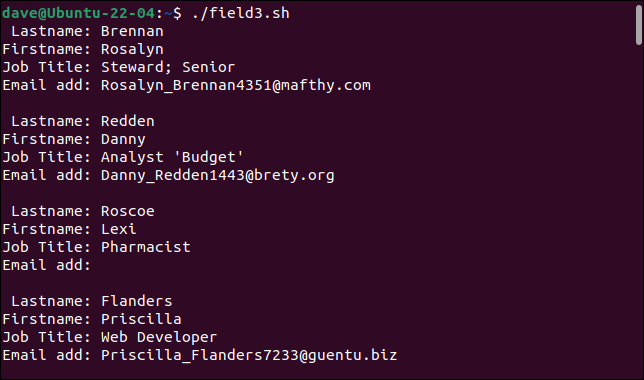
Analizatorul nostru simplu poate gestiona acum înregistrările noastre anterior problematice.
Veți vedea o mulțime de CSV
CSV este, fără îndoială, cel mai apropiat lucru de o limbă comună pentru datele aplicației. Majoritatea aplicațiilor care gestionează o anumită formă de date acceptă importul și exportul CSV. A ști cum să gestionezi CSV-ul într-un mod realist și practic-ți va fi de folos.
LEGATE: 9 exemple de script Bash pentru a începe pe Linux