
Cum se face OCR din linia de comandă Linux folosind Tesseract
Publicat: 2022-01-29
Puteți extrage text din imagini pe linia de comandă Linux folosind motorul Tesseract OCR. Este rapid, precis și funcționează în aproximativ 100 de limbi. Iată cum să-l folosești.
Recunoaștere optică a caracterelor
Recunoașterea optică a caracterelor (OCR) este capacitatea de a privi și de a găsi cuvinte într-o imagine, apoi de a le extrage ca text editabil. Această sarcină simplă pentru oameni este foarte dificil de realizat pentru computere. Eforturile timpurii au fost greoaie, ca să spunem cel puțin. Calculatoarele erau adesea confundate dacă fontul sau dimensiunea nu erau pe placul software-ului OCR.
Cu toate acestea, pionierii în acest domeniu erau încă ținuți la mare stimă. Dacă ai pierdut copia electronică a unui document, dar ai încă o versiune tipărită, OCR ar putea recrea o versiune electronică, editabilă. Chiar dacă rezultatele nu au fost 100 la sută exacte, aceasta a fost totuși o economie excelentă de timp.
Cu niște remedieri manuale, ați avea documentul înapoi. Oamenii au fost iertați cu privire la greșelile pe care le-a făcut, deoarece au înțeles complexitatea sarcinii cu care se confruntă un pachet OCR. În plus, a fost mai bine decât să tastezi întregul document.
Lucrurile s-au îmbunătățit semnificativ de atunci. Aplicația Tesseract OCR, scrisă de Hewlett Packard, a început în anii 1980 ca o aplicație comercială. A fost open-source în 2005 și acum este susținut de Google. Are capabilități în mai multe limbi, este considerat unul dintre cele mai precise sisteme OCR disponibile și îl puteți folosi gratuit.
Instalarea Tesseract OCR
Pentru a instala Tesseract OCR pe Ubuntu, utilizați această comandă:
sudo apt-get install tesseract-ocr

Pe Fedora, comanda este:
sudo dnf install tesseract

Pe Manjaro, trebuie să tastați:
sudo pacman -Syu tesseract

Folosind Tesseract OCR
Vom pune un set de provocări pentru Tesseract OCR. Prima noastră imagine care conține text este un extras din Considerentul 63 din Regulamentul General de Protecție a Datelor. Să vedem dacă OCR poate citi asta (și rămâne treaz).

Este o imagine dificilă, deoarece fiecare propoziție începe cu un număr superscript slab, care este tipic în documentele legislative.
Trebuie să oferim comenzii tesseract câteva informații, inclusiv:
- Numele fișierului imagine pe care dorim să îl proceseze.
- Numele fișierului text pe care îl va crea pentru a reține textul extras. Nu trebuie să furnizăm extensia fișierului (va fi întotdeauna .txt). Dacă există deja un fișier cu același nume, acesta va fi suprascris.
- Putem folosi opțiunea
--dpipentru a spunetesseractcare este rezoluția puncte pe inch (dpi) a imaginii. Dacă nu furnizăm o valoare dpi,tesseractva încerca să o descopere.
Fișierul nostru imagine se numește „recital-63.png” și rezoluția sa este de 150 dpi. Vom crea un fișier text din acesta numit „recital.txt”.
Comanda noastră arată astfel:
tesseract recital-63.png recital --dpi 150

Rezultatele sunt foarte bune. Singura problemă sunt superscriptele - erau prea slabe pentru a fi citite corect. O imagine de bună calitate este vitală pentru a obține rezultate bune.

tesseract a interpretat numerele superscripte ca ghilimele (“) și simboluri de grade (°), dar textul real a fost extras perfect (partea dreaptă a imaginii a trebuit să fie tăiată pentru a se potrivi aici).
Caracterul final este un octet cu valoarea hexazecimală 0x0C, care este o întoarcere de transport.
Mai jos este o altă imagine cu text în diferite dimensiuni și atât aldine, cât și italice.

Numele acestui fișier este „bold-italic.png”. Dorim să creăm un fișier text numit „bold.txt”, așa că comanda noastră este:
tesseract bold-italic.png bold --dpi 150

Acesta nu a pus probleme, iar textul a fost extras perfect.

Utilizarea diferitelor limbi
Tesseract OCR acceptă aproximativ 100 de limbi. Pentru a utiliza o limbă, trebuie mai întâi să o instalați. Când găsiți limba pe care doriți să o utilizați în listă, notați abrevierea acesteia. Vom instala suport pentru Welsh. Abrevierea sa este „cym”, care este prescurtare pentru „Cymru”, care înseamnă galeză.
Pachetul de instalare se numește „tesseract-ocr-” cu abrevierea limbii etichetată la sfârșit. Pentru a instala fișierul în limba galeză în Ubuntu, vom folosi:
sudo apt-get install tesseract-ocr-cym


Imaginea cu textul este mai jos. Este primul vers al imnului național al Galilor.

Să vedem dacă Tesseract OCR face față provocării. Vom folosi opțiunea -l (limbă) pentru a-i permite lui tesseract să cunoască limba în care dorim să lucrăm:
tesseract hen-wlad-fy-nhadau.png imn -l cym --dpi 150

tesseract se descurcă perfect, așa cum se arată în textul extras de mai jos. Da iawn , Tesseract OCR.

Dacă documentul dvs. conține două sau mai multe limbi (cum ar fi un dicționar din galeză în engleză, de exemplu), puteți utiliza semnul plus ( + ) pentru a spune tesseract să adauge o altă limbă, astfel:
tesseract image.png textfile -l eng+cym+fra
Utilizarea Tesseract OCR cu PDF-uri
Comanda tesseract este proiectată să funcționeze cu fișiere imagine, dar nu poate citi PDF-uri. Cu toate acestea, dacă trebuie să extrageți text dintr-un PDF, puteți utiliza mai întâi un alt utilitar pentru a genera un set de imagini. O singură imagine va reprezenta o singură pagină a PDF-ului.
Utilitarul pdftppm de care aveți nevoie ar trebui să fie deja instalat pe computerul dvs. Linux. PDF-ul pe care îl vom folosi pentru exemplul nostru este o copie a lucrării fundamentale a lui Alan Turing despre inteligența artificială, „Computing Machinery and Intelligence”.

Folosim opțiunea -png pentru a specifica că dorim să creăm fișiere PNG. Numele fișierului PDF-ului nostru este „turing.pdf”. Vom numi fișierele noastre de imagine „turing-01.png”, „turing-02.png” și așa mai departe:
pdftoppm -png turing.pdf turing

Pentru a rula tesseract pe fiecare fișier imagine folosind o singură comandă, trebuie să folosim o buclă for. Pentru fiecare dintre fișierele noastre „turing- nn .png”, rulăm tesseract și creăm un fișier text numit „text-” plus „turing- nn ” ca parte a numelui fișierului imagine:
pentru i in turing-??.png; do tesseract "$i" "text-$i" -l eng; Terminat;

Pentru a combina toate fișierele text într-unul singur, putem folosi cat :
cat text-turing* > complete.txt

Deci, cum a făcut? Foarte bine, după cum puteți vedea mai jos. Prima pagină pare destul de provocatoare, totuși. Are diferite stiluri și dimensiuni de text și decorațiuni. Există, de asemenea, un „filigran” vertical pe marginea dreaptă a paginii.
Cu toate acestea, ieșirea este aproape de cea originală. Evident, s-a pierdut formatarea, dar textul este corect.
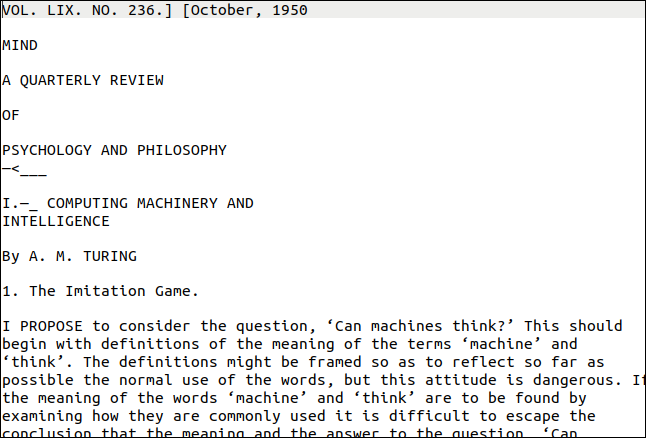
Filigranul vertical a fost transcris ca o linie de farfurie în partea de jos a paginii. Textul era prea mic pentru a fi citit de tesseract cu acuratețe, dar ar fi destul de ușor să îl găsiți și să îl ștergeți. Cel mai rău rezultat ar fi fost caracterele rătăcite la sfârșitul fiecărei rânduri.
În mod curios, literele unice de la începutul listei de întrebări și răspunsuri de pe pagina a doua au fost ignorate. Secțiunea din PDF este afișată mai jos.

După cum puteți vedea mai jos, întrebările rămân, dar „Q” și „A” de la începutul fiecărei linii au fost pierdute.

De asemenea, diagramele nu vor fi transcrise corect. Să ne uităm la ce se întâmplă atunci când încercăm să-l extragem pe cel afișat mai jos din PDF-ul Turing.

După cum puteți vedea în rezultatul nostru de mai jos, caracterele au fost citite, dar formatul diagramei a fost pierdut.

Din nou, tesseract s-a luptat cu dimensiunea mică a subscriptelor și au fost redate incorect.
Pentru dreptate, totuși, a fost încă un rezultat bun. Nu am reușit să extragem text simplu, dar apoi, acest exemplu a fost ales în mod deliberat pentru că prezenta o provocare.
O soluție bună când aveți nevoie de ea
OCR nu este ceva pe care trebuie să-l utilizați zilnic. Cu toate acestea, atunci când este nevoie, este bine să știți că aveți unul dintre cele mai bune motoare OCR la dispoziție.