
Como o Search Engine funciona e torna sua vida mais fácil?
Publicados: 2015-11-06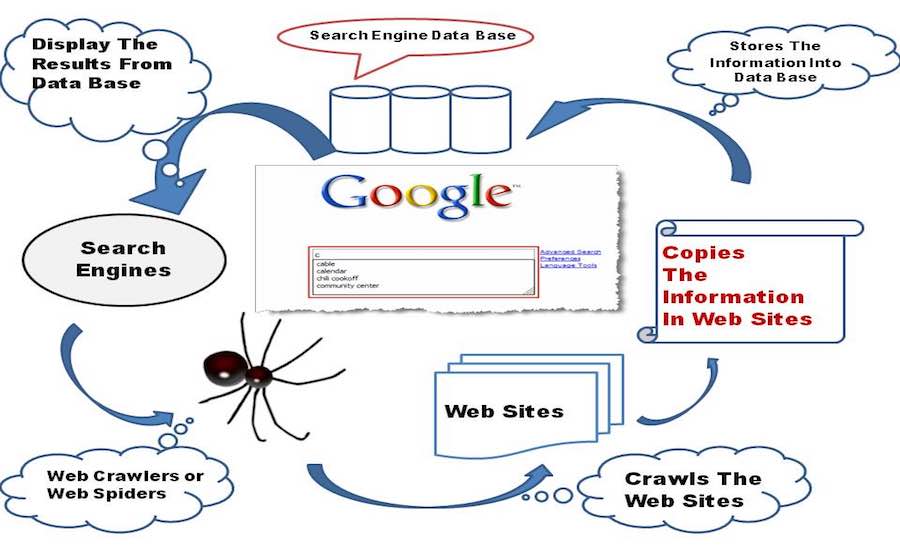 Short Bytes: Search Engine é um software que permite a exibição de resultados relevantes de páginas da web com base na entrada da consulta de pesquisa pelo uso de Web Crawling e Web Indexing, algumas fórmulas gordas e algoritmos inteligentes para coletar os dados apropriados.
Short Bytes: Search Engine é um software que permite a exibição de resultados relevantes de páginas da web com base na entrada da consulta de pesquisa pelo uso de Web Crawling e Web Indexing, algumas fórmulas gordas e algoritmos inteligentes para coletar os dados apropriados.
Como o Google oferece os melhores resultados em um piscar de olhos? Na verdade, não importa até que o Google, o Bing estejam lá. O cenário teria sido muito diferente se não houvesse Google, Bing ou Yahoo. Vamos mergulhar no mundo dos motores de busca e ver como funciona um motor de busca.
Espiando a história
O conto de fadas do mecanismo de busca começou na década de 1990, quando Tim Berners-Lee costumava inscrever todos os novos servidores da Web que ficavam online na lista mantida pelo servidor da Web do CERN. Até setembro de 93, não existiam mecanismos de busca na internet, mas apenas algumas ferramentas capazes de manter um banco de dados de nomes de arquivos. Archie, Veronica, Jughead foram os primeiros participantes nesta categoria.
Oscar Nierstrasz, da Universidade de Genebra, é credenciado pelo primeiro mecanismo de busca que surgiu, chamado W3Catalog. Ele fez alguns scripts Perl sérios e finalmente saiu com o primeiro mecanismo de busca do mundo em 3 de setembro de 1993. Além disso, o ano de 1993 viu o advento de muitos outros mecanismos de busca. JumpStation por Jonathon Fletcher, AliWeb, WWW Worm, etc. Yahoo! foi lançado em 1995 como um diretório web, mas começou a usar o mecanismo de pesquisa do Inktomi a partir de 2000 e depois mudou para o Bing da Microsoft em 2009.
Agora, falar sobre o nome que é o principal sinônimo do termo mecanismo de busca, Google Search, foi um projeto de pesquisa para dois graduados de Stanford, Larry Page e Sergy Brin, tendo suas pegadas iniciais em março de 1995. O trabalho do Google foi inicialmente inspirado pelo método de back-linking de Page, que fazia cálculos com base em quantos backlinks eram originados de uma página da web, para medir a importância dessa página na World Wide Web. “O melhor conselho que já recebi”, disse Page, enquanto lembrava como seu supervisor Terry Winograd apoiou sua ideia. E desde então, o Google nunca olhou para trás.
Tudo começa com um rastreamento
Um mecanismo de busca de bebês em seu estágio inicial começa a explorar a World Wide Web, com suas pequenas mãos e joelhos, explora todos os outros links que encontra em uma página da Web e os armazena em seu banco de dados.
Agora, vamos nos concentrar em alguns pensamentos técnicos por trás da cena, um mecanismo de pesquisa incorpora um software Web Crawler que é basicamente um bot da Internet com a tarefa de abrir todos os hiperlinks presentes em uma página da Web e criar um banco de dados de texto e metadados de todos os links . Começa com um conjunto inicial de links para visitar, chamado Seeds. Assim que ele continua visitando esses links, adiciona novos links na lista existente de URLs a serem visitados, conhecidos como Crawl Frontier.
À medida que o Crawler percorre os links, ele baixa as informações dessas páginas da Web para serem visualizadas posteriormente na forma de instantâneos, pois o download de toda a página da Web exigiria muitos dados e tem um preço de bolso, pelo menos em países como a Índia. E posso apostar que, se o Google fosse fundado na Índia, todo o dinheiro deles seria usado para pagar as contas da internet. Felizmente, isso não é um tópico de preocupação a partir de agora.
O rastreador da Web explora as páginas da Web com base em algumas políticas:
Política de seleção: O rastreador decide quais páginas ele deve baixar e quais não deve. A política de seleção se concentra no download do conteúdo mais relevante de uma página da Web, em vez de alguns dados sem importância.
Política de re-visita: o Crawler agenda o momento em que deve reabrir as páginas da web e editar as alterações em seu banco de dados, graças à natureza dinâmica da Internet, o que torna muito difícil para os Crawlers se manterem atualizados com as versões mais recentes do as páginas da web.
Política de Paralelização: Os rastreadores usam vários processos ao mesmo tempo para explorar os links conhecidos como Rastreamento distribuído, mas às vezes há chances de que processos diferentes baixem a mesma página da Web, portanto, o rastreador mantém uma coordenação entre todos os processos para eliminar qualquer chance de duplicidade.
Política de polidez: Quando um rastreador atravessa um site, ele simultaneamente baixa páginas da web dele, aumentando assim a carga no servidor que hospeda o site. Assim, um termo “Crawl-Delay” é implementado no qual o rastreador precisa aguardar alguns segundos após baixar alguns dados de um servidor da Web e é regido pela Política de Polidez.
Leia também: Como construir um web crawler básico em Python
Arquitetura de alto nível de um rastreador da Web padrão:
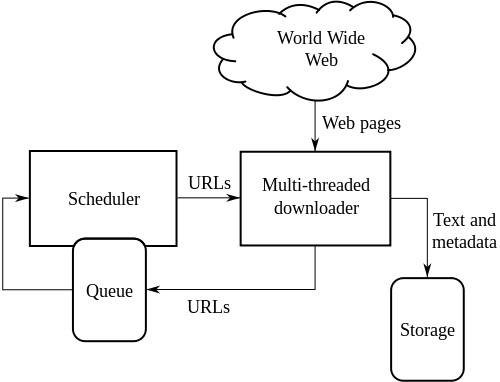
A ilustração acima mostra como um rastreador da Web funciona. Ele abre a lista inicial de links e, em seguida, os links dentro desses links e assim por diante.
A Wikipedia escreve, os pesquisadores de ciência da computação Vladislav Shkapenyuk e Torsten Suel observaram que:
Embora seja bastante fácil construir um rastreador lento que baixe algumas páginas por segundo por um curto período de tempo, construir um sistema de alto desempenho que pode baixar centenas de milhões de páginas ao longo de várias semanas apresenta vários desafios no design do sistema, E/S e eficiência de rede e robustez e capacidade de gerenciamento.
Indexando os rastreamentos
Depois que o mecanismo de busca do bebê rastreia toda a Internet, ele cria um índice de todas as páginas da Web que encontra em seu caminho. Ter um índice é muito melhor do que perder tempo encontrando a consulta de pesquisa em uma pilha de documentos de tamanho grande, pois economizará tempo e recursos.
Existem muitos fatores que contribuem para a criação de um sistema de indexação eficiente para um mecanismo de busca. As técnicas de armazenamento utilizadas pelos indexadores, o tamanho do índice, a capacidade de encontrar rapidamente os documentos que contêm as palavras-chave pesquisadas, etc. são os fatores responsáveis pela eficiência e confiabilidade de um índice.
Um dos principais obstáculos no caminho para a criação de índices web bem-sucedidos é a colisão entre dois processos. Digamos que um processo queira pesquisar um documento e ao mesmo tempo outro processo queira adicionar um documento no índice, meio que cria conflito entre os dois processos. O problema é agravado pela implementação da computação distribuída pelos motores de busca para lidar com mais dados.
Tipos de Índice
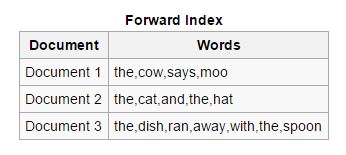
Encaminhar: Nesse tipo de índice, todas as palavras-chave presentes em um documento são armazenadas em uma lista. O índice de encaminhamento é fácil de criar na fase inicial da indexação, pois permite que os indexadores assíncronos colaborem entre si.
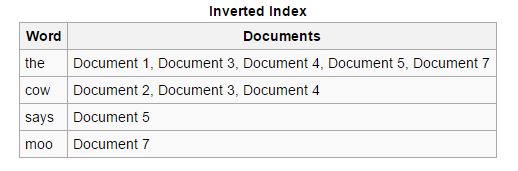
Reverse: Os índices forward são ordenados e convertidos em índices reversos, nos quais cada documento contendo uma palavra-chave específica é colocado junto com outros documentos contendo essa palavra-chave. Os índices reversos facilitam o processo de localização de documentos relevantes para uma determinada consulta de pesquisa, o que não é o caso dos índices de encaminhamento.

Leia também: O que é DNS (Sistema de Nomes de Domínio) e como funciona?
Análise de documentos
Também chamada de Tokenização, refere-se à quebra de componentes de um documento como palavras-chave (chamadas tokens), imagens e outras mídias, para que possam ser inseridas em índices posteriormente. O método basicamente se concentra em entender o idioma nativo e prever as palavras-chave que um usuário pode pesquisar, que servem como base para a criação de um sistema de indexação web eficaz.
Os principais desafios incluem encontrar os limites das palavras-chave a serem extraídas, pois podemos ver que idiomas como chinês e japonês geralmente não têm espaços em branco em seus scripts de idioma. Compreender a ambiguidade de uma língua também é um ponto de preocupação, pois algumas línguas começam a diferir ligeiramente ou mesmo consideravelmente com as mudanças geográficas. Além disso, a ineficiência de algumas páginas da web em não mencionar claramente a linguagem utilizada também é motivo de preocupação e aumenta a carga de trabalho dos indexadores.
Os mecanismos de pesquisa têm a capacidade de reconhecer vários formatos de arquivo e extrair dados deles com sucesso, e é necessário que se tome o máximo cuidado nesses casos.
Meta Tags também são muito úteis na criação de índices muito rapidamente, reduzem os esforços do indexador da web e facilitam a necessidade de analisar completamente todo o documento. Você encontrará Meta Tags anexadas na parte inferior deste artigo.
Pesquisando o índice
Agora, o mecanismo de busca de bebês não é mais um bebê, ele aprendeu a engatinhar e a pegar as coisas de maneira rápida e eficiente, e como organizar suas coisas sistematicamente. Suponha que seu amigo lhe peça para encontrar algo de seu arranjo, o que ele fará? Existem quatro tipos de consultas de pesquisa em uso, embora não sejam formalmente derivadas, mas evoluíram ao longo do tempo e foram consideradas válidas em termos de consultas da vida real feitas por usuários.
Navegacional: Este termo é utilizado para aquelas consultas em que o usuário deseja acessar uma determinada página ou site existente na internet. Por exemplo, quando você pesquisa fossBytes no Google, está iniciando uma consulta de navegação.
Informacional: Esse tipo de consulta tem milhares de resultados e abrange tópicos gerais que aprimoram o conhecimento do usuário. Por exemplo, ao pesquisar, digamos, Steve Jobs, você verá todos os links relevantes para Steve Jobs.
Transacional: As consultas com foco na intenção do usuário de realizar uma determinada ação podem envolver um conjunto predefinido de instruções. Por exemplo, como encontrar seu laptop perdido/roubado?
Conectividade: Esses tipos de consultas não são usados com frequência, eles se concentram em quão conectado é o índice criado a partir de um site. Por exemplo, se você pesquisar, quantas páginas existem na Wikipedia?
O Google e o Bing criaram alguns algoritmos sérios que são capazes o suficiente para determinar os resultados mais relevantes para sua consulta. O Google afirma calcular seus resultados de pesquisa com base em mais de 200 fatores, como qualidade do conteúdo, novo ou antigo, segurança da página da Web e muito mais. Eles têm as maiores mentes do mundo nomeadas em seus laboratórios de Pesquisa, que fazem cálculos difíceis e lidam com fórmulas alucinantes, apenas para tornar a Pesquisa mais simples e rápida para você.
Outros recursos notáveis *
Pesquisa de imagens: você ficará surpreso ao conhecer a inspiração do Google por trás de sua famosa ferramenta de pesquisa de imagens. J.Lo, sim, você ouviu direito, J.Lo e seu vestido verde Versace (ver-sah-chay) no Grammy Awards de 2000, foram a verdadeira razão pela qual o Google saiu com sua busca de imagens, já que as pessoas estavam ocupadas pesquisando sobre ela.
Disse Eric Schmidt em seu texto intitulado “O Aprendiz do Tinkerer”, publicado em 19 de janeiro de 2015.
Pesquisa por voz: o Google foi o primeiro a introduzir a pesquisa por voz em seu mecanismo de pesquisa após muito trabalho e, posteriormente, outros mecanismos de pesquisa também a implementaram.
Spam Fighting: Os mecanismos de pesquisa implantam alguns algoritmos sérios, para que possam protegê-lo contra ataques de spam . Um spam é basicamente uma mensagem ou um arquivo que se espalha por toda a internet, talvez para propaganda ou para transmissão de vírus. Nesta questão também, os caras do Google informam manualmente que o site que encontram é responsável por espalhar mensagens de spam na internet.
Otimização de Localização: Os motores de busca agora são capazes de exibir resultados com base na localização do usuário. Se pesquisar, Qual é o clima em Bengaluru, as estatísticas meteorológicas serão em referência a Bengaluru.
Entende você melhor: os mecanismos de pesquisa modernos são capazes de entender o significado da consulta do usuário em vez de encontrar as palavras-chave inseridas pelo usuário.
Preenchimento automático : a capacidade de prever sua consulta de pesquisa à medida que você digita com base em suas pesquisas anteriores e pesquisas feitas por outros usuários.
Gráfico de conhecimento: esse recurso, fornecido pela Pesquisa do Google, mostra sua capacidade de fornecer resultados de pesquisa com base em pessoas, lugares e eventos da vida real.
Controle dos pais: os mecanismos de pesquisa permitem que pais de pequeno porte controlem o que seus filhos estão fazendo na Internet.
* É difícil cobrir a vasta lista de recursos fornecidos por esses poderosos mecanismos de pesquisa.
Encerramento
Os motores de busca têm contribuído para tornar a nossa vida mais simples e o trabalho árduo que têm vindo a fazer para aproveitar toda a informação na internet não tem preço. Mas essa exploração levou à exibição de nosso espaço pessoal em uma plataforma pública, e devo dizer que já é hora de nos agitarmos com o caminho que percorremos há tanto tempo, a menos que seja tarde demais para retrospectar nossas ações e nossa vida seja apenas uma bienal de constrangimentos. Não podemos negar o fato de que os mecanismos de busca são agora uma parte vital de nossa personalidade dividida digital. Nós só precisamos fazer uso da tecnologia que nos foi dada, não permitir que ela nos escravize nas cadeias de nossos próprios crimes.
Ok, chega de conversas emocionais, apenas adore a fofura e os talentos daquele buscador de bebês que agora virou adolescente, e te entende muito melhor. O Google está lá para pesquisar tudo para nós, é a internet para muitos de nós, e devemos valorizar as boas experiências que conquistamos ao usar a Pesquisa do Google. Oh! Esqueci de mencionar Bing, você também é incrível. Fique alerta, fique seguro e pesquise no Google.
Assista a este vídeo e saiba mais sobre os mecanismos de busca:
Você já clicou no botão Estou com sorte na Pesquisa do Google. Abra-o e diga-nos qual doodle você mais gostou na seção de comentários abaixo.