
GPUs da série RTX 3000 da NVIDIA: aqui está o que há de novo
Publicados: 2022-01-29
Em 1º de setembro de 2020, a NVIDIA revelou sua nova linha de GPUs para jogos: a série RTX 3000, baseada em sua arquitetura Ampere. Discutiremos o que há de novo, o software com inteligência artificial que o acompanha e todos os detalhes que tornam essa geração realmente incrível.
Conheça as GPUs da série RTX 3000

O principal anúncio da NVIDIA foram suas novas GPUs brilhantes, todas construídas em um processo de fabricação personalizado de 8 nm, e todas trazendo grandes acelerações no desempenho de rasterização e rastreamento de raios.
Na extremidade inferior da linha, há o RTX 3070, que custa US $ 499. É um pouco caro para a placa mais barata revelada pela NVIDIA no anúncio inicial, mas é um roubo absoluto quando você descobre que ela supera a RTX 2080 Ti existente, uma placa top de linha que é vendida regularmente por mais de US $ 1400. No entanto, após o anúncio da NVIDIA, o preço de venda de terceiros caiu, com um grande número deles sendo vendidos em pânico no eBay por menos de US $ 600.
Não há benchmarks sólidos no anúncio, então não está claro se a placa é realmente objetivamente “melhor” que uma 2080 Ti, ou se a NVIDIA está distorcendo um pouco o marketing. Os benchmarks que estavam sendo executados estavam em 4K e provavelmente tinham RTX ativado, o que pode fazer a diferença parecer maior do que em jogos puramente rasterizados, já que a série 3000 baseada em Ampere terá desempenho duas vezes melhor em ray tracing do que Turing. Mas, com o ray tracing agora sendo algo que não prejudica muito o desempenho e sendo suportado na última geração de consoles, é um grande ponto de venda tê-lo funcionando tão rápido quanto o carro-chefe da última geração por quase um terço do preço.
Também não está claro se o preço permanecerá assim. Os designs de terceiros adicionam regularmente pelo menos US $ 50 ao preço e, com a alta demanda, não será surpreendente vê-lo sendo vendido por US $ 600 em outubro de 2020.
Logo acima disso está o RTX 3080 por US $ 699, que deve ser duas vezes mais rápido que o RTX 2080 e chegar cerca de 25 a 30% mais rápido que o 3080.
Então, no topo, o novo carro-chefe é o RTX 3090, que é comicamente enorme. A NVIDIA está bem ciente e se referiu a ele como um “BFGPU”, que a empresa diz significa “Big Ferocious GPU”.

A NVIDIA não mostrou nenhuma métrica direta de desempenho, mas a empresa mostrou rodando jogos de 8K a 60 FPS, o que é realmente impressionante. É certo que a NVIDIA está quase certamente usando DLSS para atingir essa marca, mas jogos em 8K são jogos em 8K.
Claro, eventualmente haverá um 3060 e outras variações de cartões mais orientados para o orçamento, mas esses geralmente vêm mais tarde.
Para realmente resfriar as coisas, a NVIDIA precisava de um design de cooler renovado. O 3080 é classificado para 320 watts, o que é bastante alto, então a NVIDIA optou por um design de ventoinha dupla, mas em vez de ambas as ventoinhas vwinf colocadas na parte inferior, a NVIDIA colocou uma ventoinha na extremidade superior, onde a placa traseira geralmente fica. A ventoinha direciona o ar para cima em direção ao cooler do processador e ao topo do gabinete.

A julgar pelo quanto o desempenho pode ser afetado pelo fluxo de ar ruim em um gabinete, isso faz todo o sentido. No entanto, a placa de circuito é muito apertada por causa disso, o que provavelmente afetará os preços de venda de terceiros.
DLSS: uma vantagem de software
O rastreamento de raios não é o único benefício desses novos cartões. Na verdade, é tudo uma espécie de hack - as séries RTX 2000 e 3000 não são muito melhores em fazer ray tracing real, em comparação com as gerações mais antigas de placas. Ray tracing de uma cena completa em software 3D como o Blender geralmente leva alguns segundos ou até minutos por quadro, então forçar a cena em menos de 10 milissegundos está fora de questão.
Claro, há hardware dedicado para executar cálculos de raios, chamados de núcleos RT, mas em grande parte, a NVIDIA optou por uma abordagem diferente. A NVIDIA melhorou os algoritmos de remoção de ruído, que permitem que as GPUs renderizem uma única passagem muito barata que parece terrível e, de alguma forma, por meio da magia da IA, transforma isso em algo que um jogador deseja ver. Quando combinado com técnicas tradicionais baseadas em rasterização, proporciona uma experiência agradável aprimorada por efeitos de raytracing.

No entanto, para fazer isso rapidamente, a NVIDIA adicionou núcleos de processamento específicos de IA chamados núcleos Tensor. Eles processam toda a matemática necessária para executar modelos de aprendizado de máquina e fazem isso muito rapidamente. Eles são um divisor de águas para a IA no espaço do servidor em nuvem, pois a IA é amplamente usada por muitas empresas.
Além do denoising, o principal uso dos núcleos Tensor para jogadores é chamado de DLSS, ou deep learning super sampling. Ele recebe um quadro de baixa qualidade e o aprimora para qualidade nativa total. Isso significa essencialmente que você pode jogar com taxas de quadros de nível 1080p, enquanto observa uma imagem 4K.

Isso também ajuda bastante no desempenho do ray-tracing - os benchmarks do PCMag mostram um RTX 2080 Super running Control com qualidade ultra, com todas as configurações de ray-tracing no máximo. Em 4K, ele luta com apenas 19 FPS, mas com DLSS ativado, obtém 54 FPS muito melhores. DLSS é desempenho gratuito para NVIDIA, possibilitado pelos núcleos Tensor em Turing e Ampere. Qualquer jogo que o suporte e seja limitado por GPU pode ver grandes acelerações apenas com o software.
O DLSS não é novo e foi anunciado como um recurso quando a série RTX 2000 foi lançada há dois anos. Na época, era suportado por muito poucos jogos, pois exigia que a NVIDIA treinasse e ajustasse um modelo de aprendizado de máquina para cada jogo individual.
No entanto, nesse período, a NVIDIA o reescreveu completamente, chamando a nova versão de DLSS 2.0. É uma API de uso geral, o que significa que qualquer desenvolvedor pode implementá-la e já está sendo escolhida pela maioria dos principais lançamentos. Em vez de trabalhar em um quadro, ele recebe dados vetoriais de movimento do quadro anterior, de forma semelhante ao TAA. O resultado é muito mais nítido do que o DLSS 1.0 e, em alguns casos, parece melhor e mais nítido do que a resolução nativa, então não há muitos motivos para não ativá-lo.
Há um problema - ao alternar completamente as cenas, como nas cutscenes, o DLSS 2.0 deve renderizar o primeiro quadro com 50% de qualidade enquanto aguarda os dados do vetor de movimento. Isso pode resultar em uma pequena queda na qualidade por alguns milissegundos. Mas, 99% de tudo que você vê será renderizado corretamente, e a maioria das pessoas não percebe isso na prática.
RELACIONADO: O que é o NVIDIA DLSS e como ele tornará o Ray Tracing mais rápido?
Arquitetura Ampere: Construída para IA
Ampère é rápido. Muito rápido, especialmente em cálculos de IA. O núcleo RT é 1,7x mais rápido que Turing, e o novo núcleo Tensor é 2,7x mais rápido que Turing. A combinação dos dois é um verdadeiro salto geracional no desempenho do raytracing.

No início de maio, a NVIDIA lançou a GPU Ampere A100, uma GPU de data center projetada para executar IA. Com ele, eles detalharam muito o que torna o Ampere muito mais rápido. Para cargas de trabalho de data center e computação de alto desempenho, o Ampere é, em geral, cerca de 1,7x mais rápido que o Turing. Para treinamento de IA, é até 6 vezes mais rápido.
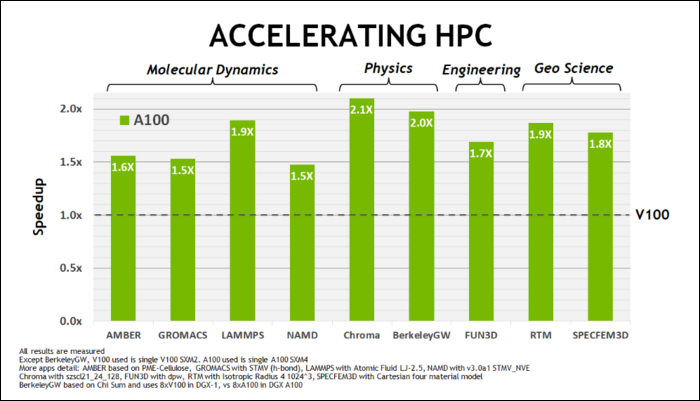
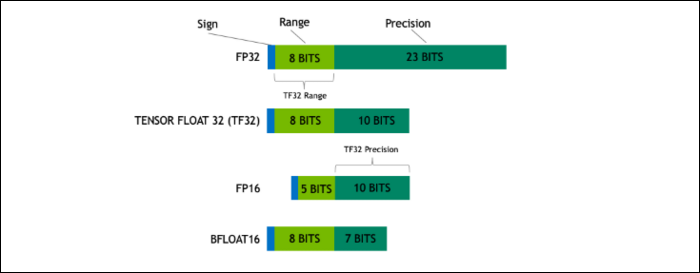
Com o Ampere, a NVIDIA está usando um novo formato numérico projetado para substituir o padrão do setor “Floating-Point 32”, ou FP32, em algumas cargas de trabalho. Sob o capô, cada número que seu computador processa ocupa um número predefinido de bits na memória, seja 8 bits, 16 bits, 32, 64 ou até maior. Números maiores são mais difíceis de processar, portanto, se você puder usar um tamanho menor, terá menos coisas para processar.
O FP32 armazena um número decimal de 32 bits e usa 8 bits para o intervalo do número (o quão grande ou pequeno ele pode ser) e 23 bits para a precisão. A alegação da NVIDIA é que esses 23 bits de precisão não são totalmente necessários para muitas cargas de trabalho de IA, e você pode obter resultados semelhantes e desempenho muito melhor com apenas 10 deles. Reduzir o tamanho para apenas 19 bits, em vez de 32, faz uma grande diferença em muitos cálculos.
Este novo formato é chamado Tensor Float 32, e os Tensor Cores no A100 são otimizados para lidar com o formato de tamanho estranho. Isto é, além do encolhimento de matrizes e do aumento da contagem de núcleos, como eles estão obtendo a enorme aceleração de 6x no treinamento de IA.
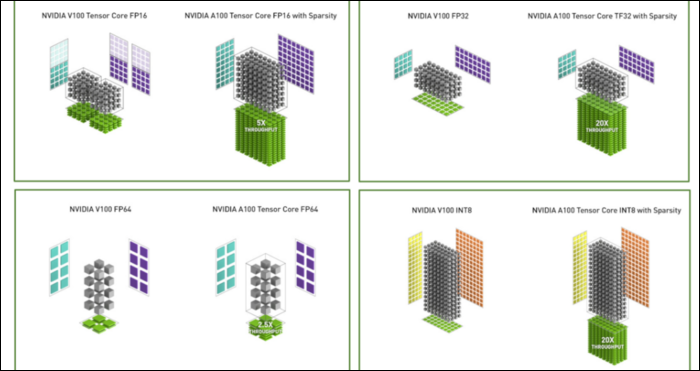
Além do novo formato numérico, a Ampere está vendo grandes aumentos de desempenho em cálculos específicos, como FP32 e FP64. Isso não se traduz diretamente em mais FPS para o leigo, mas são parte do que o torna quase três vezes mais rápido no geral nas operações do Tensor.
Então, para acelerar ainda mais os cálculos, eles introduziram o conceito de esparsidade estruturada refinada, que é uma palavra muito chique para um conceito bastante simples. As redes neurais trabalham com grandes listas de números, chamadas de pesos, que afetam a saída final. Quanto mais números para triturar, mais lento será.
No entanto, nem todos esses números são realmente úteis. Alguns deles são literalmente zero e basicamente podem ser descartados, o que leva a enormes acelerações quando você pode processar mais números ao mesmo tempo. A esparsidade essencialmente comprime os números, o que exige menos esforço para fazer cálculos. O novo “Sparse Tensor Core” foi desenvolvido para operar em dados compactados.
Apesar das mudanças, a NVIDIA diz que isso não deve afetar visivelmente a precisão dos modelos treinados.
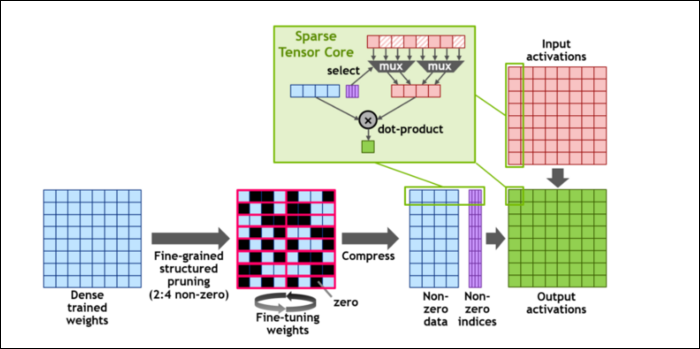
Para cálculos do Sparse INT8, um dos menores formatos numéricos, o desempenho máximo de uma única GPU A100 é superior a 1,25 PetaFLOPs, um número incrivelmente alto. Claro, isso é apenas ao processar um tipo específico de número, mas é impressionante mesmo assim.