
Como fazer OCR a partir da linha de comando do Linux usando o Tesseract
Publicados: 2022-01-29
Você pode extrair texto de imagens na linha de comando do Linux usando o mecanismo Tesseract OCR. É rápido, preciso e funciona em cerca de 100 idiomas. Aqui está como usá-lo.
Reconhecimento óptico de caracteres
O reconhecimento óptico de caracteres (OCR) é a capacidade de ver e encontrar palavras em uma imagem e extraí-las como texto editável. Essa tarefa simples para humanos é muito difícil para os computadores. Os primeiros esforços foram desajeitados, para dizer o mínimo. Os computadores muitas vezes ficavam confusos se o tipo de letra ou o tamanho não fossem do agrado do software de OCR.
No entanto, os pioneiros neste campo ainda eram tidos em alta estima. Se você perder a cópia eletrônica de um documento, mas ainda tiver uma versão impressa, o OCR poderá recriar uma versão eletrônica editável. Mesmo que os resultados não fossem 100% precisos, isso ainda economizava muito tempo.
Com alguma arrumação manual, você teria seu documento de volta. As pessoas perdoavam os erros cometidos porque entendiam a complexidade da tarefa de um pacote de OCR. Além disso, era melhor do que redigitar o documento inteiro.
As coisas melhoraram significativamente desde então. O aplicativo Tesseract OCR, escrito pela Hewlett Packard, começou na década de 1980 como um aplicativo comercial. Foi de código aberto em 2005 e agora é suportado pelo Google. Possui recursos multilíngue, é considerado um dos sistemas de OCR mais precisos disponíveis e você pode usá-lo gratuitamente.
Instalando o Tesseract OCR
Para instalar o Tesseract OCR no Ubuntu, use este comando:
sudo apt-get install tesseract-ocr

No Fedora, o comando é:
sudo dnf instalar tesseract

No Manjaro, você precisa digitar:
sudo pacman -Syu tesseract

Usando o Tesseract OCR
Vamos apresentar um conjunto de desafios ao Tesseract OCR. A nossa primeira imagem que contém texto é um extrato do Considerando 63 do Regulamento Geral de Proteção de Dados. Vamos ver se o OCR pode ler isso (e ficar acordado).

É uma imagem complicada porque cada frase começa com um número sobrescrito fraco, o que é típico em documentos legislativos.
Precisamos fornecer ao comando tesseract algumas informações, incluindo:
- O nome do arquivo de imagem que queremos processar.
- O nome do arquivo de texto que será criado para conter o texto extraído. Não precisamos fornecer a extensão do arquivo (sempre será .txt). Se já existir um arquivo com o mesmo nome, ele será sobrescrito.
- Podemos usar a opção
--dpipara informar aotesseractqual é a resolução de pontos por polegada (dpi) da imagem. Se não fornecermos um valor de dpi, otesseracttentará descobrir.
Nosso arquivo de imagem é denominado “recital-63.png” e sua resolução é de 150 dpi. Vamos criar um arquivo de texto a partir dele chamado “recital.txt”.
Nosso comando fica assim:
tesseract considerando-63.png considerando --dpi 150

Os resultados são muito bons. O único problema são os sobrescritos - eles eram muito fracos para serem lidos corretamente. Uma imagem de boa qualidade é vital para obter bons resultados.

tesseract interpretou os números sobrescritos como aspas (“) e símbolos de grau (°), mas o texto real foi extraído perfeitamente (o lado direito da imagem teve que ser cortado para caber aqui).
O caractere final é um byte com o valor hexadecimal de 0x0C, que é um retorno de carro.
Abaixo está outra imagem com texto em tamanhos diferentes, em negrito e itálico.

O nome deste arquivo é “bold-italic.png”. Queremos criar um arquivo de texto chamado “bold.txt”, então nosso comando é:
tesseract bold-italic.png bold --dpi 150

Este não apresentou nenhum problema, e o texto foi extraído perfeitamente.

Usando diferentes idiomas
O Tesseract OCR suporta cerca de 100 idiomas. Para usar um idioma, você deve primeiro instalá-lo. Quando você encontrar o idioma que deseja usar na lista, observe sua abreviação. Vamos instalar suporte para galês. Sua abreviatura é “cym”, que é a abreviação de “Cymru”, que significa galês.
O pacote de instalação é chamado “tesseract-ocr-” com a abreviação do idioma marcada no final. Para instalar o arquivo de idioma galês no Ubuntu, usaremos:
sudo apt-get install tesseract-ocr-cym


A imagem com o texto está abaixo. É o primeiro verso do hino nacional galês.

Vamos ver se o Tesseract OCR está à altura do desafio. Usaremos a opção -l (idioma) para permitir que o tesseract saiba o idioma no qual queremos trabalhar:
tesseract hen-wlad-fy-nhadau.png hino -l cym --dpi 150

tesseract lida perfeitamente, conforme mostrado no texto extraído abaixo. Da iawn , Tesseract OCR.

Se o seu documento contém dois ou mais idiomas (como um dicionário de galês para inglês, por exemplo), você pode usar um sinal de mais ( + ) para dizer ao tesseract para adicionar outro idioma, assim:
tesseract image.png arquivo de texto -l eng+cym+fra
Usando o Tesseract OCR com PDFs
O comando tesseract foi projetado para funcionar com arquivos de imagem, mas não consegue ler PDFs. No entanto, se você precisar extrair texto de um PDF, poderá usar outro utilitário primeiro para gerar um conjunto de imagens. Uma única imagem representará uma única página do PDF.
O utilitário pdftppm que você precisa já deve estar instalado em seu computador Linux. O PDF que usaremos para nosso exemplo é uma cópia do artigo seminal de Alan Turing sobre inteligência artificial, “Computing Machinery and Intelligence”.

Usamos a opção -png para especificar que queremos criar arquivos PNG. O nome do arquivo do nosso PDF é “turing.pdf”. Chamaremos nossos arquivos de imagem “turing-01.png”, “turing-02.png” e assim por diante:
pdftoppm -png turing.pdf turing

Para executar o tesseract em cada arquivo de imagem usando um único comando, precisamos usar um loop for. Para cada um dos nossos arquivos “turing- nn.png ”, executamos o tesseract e criamos um arquivo de texto chamado “text-” mais “turing- nn ” como parte do nome do arquivo de imagem:
para i em turing-??.png; faça tesseract "$i" "text-$i" -l eng; feito;

Para combinar todos os arquivos de texto em um, podemos usar cat :
cat text-turing* > complete.txt

Então, como foi? Muito bem, como você pode ver abaixo. A primeira página parece bastante desafiadora, no entanto. Tem diferentes estilos e tamanhos de texto e decoração. Há também uma “marca d'água” vertical na borda direita da página.
No entanto, a saída está próxima do original. Obviamente, a formatação foi perdida, mas o texto está correto.
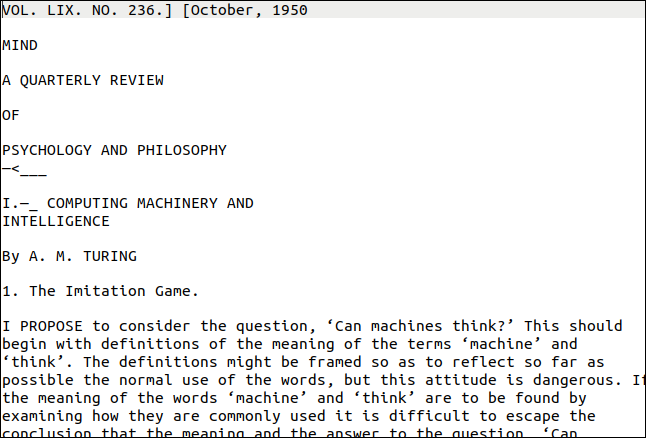
A marca d'água vertical foi transcrita como uma linha de rabiscos na parte inferior da página. O texto era muito pequeno para ser lido pelo tesseract com precisão, mas seria fácil encontrá-lo e excluí-lo. O pior resultado teria sido caracteres perdidos no final de cada linha.
Curiosamente, as letras soltas no início da lista de perguntas e respostas na página dois foram ignoradas. A seção do PDF é mostrada abaixo.

Como você pode ver abaixo, as perguntas permanecem, mas o “Q” e o “A” no início de cada linha foram perdidos.

Os diagramas também não serão transcritos corretamente. Vejamos o que acontece quando tentamos extrair o mostrado abaixo do Turing PDF.

Como você pode ver em nosso resultado abaixo, os caracteres foram lidos, mas o formato do diagrama foi perdido.

Novamente, o tesseract teve problemas com o tamanho pequeno dos subscritos, e eles foram renderizados incorretamente.
Para ser justo, porém, ainda era um bom resultado. Não conseguimos extrair texto direto, mas esse exemplo foi escolhido deliberadamente porque apresentava um desafio.
Uma boa solução quando você precisa
OCR não é algo que você precisará usar diariamente. No entanto, quando surgir a necessidade, é bom saber que você tem um dos melhores mecanismos de OCR à sua disposição.