
Jak korzystać z polecenia wc w systemie Linux?
Opublikowany: 2022-07-23
Liczenie liczby wierszy, słów i bajtów w pliku jest przydatne, ale prawdziwa elastyczność polecenia wc w Linuksie wynika z pracy z innymi poleceniami. Spójrzmy.
Co to jest polecenie wc?
Polecenie wc to mała aplikacja. Jest to jedno z podstawowych narzędzi Linuksa, więc nie ma potrzeby instalowania go. Będzie już na twoim komputerze z systemem Linux.
Możesz w kilku słowach opisać, co robi. Liczy wiersze, słowa i bajty w pliku lub wybranych plikach i wyświetla wynik w oknie terminala. Może również pobierać dane wejściowe ze strumienia STDIN, co oznacza, że tekst, który chcesz przetworzyć, może zostać do niego dołączony. W tym miejscu wc naprawdę zaczyna przynosić wartość dodaną.

Jest to świetny przykład mantry Linuksa „zrób jedną rzecz i rób to dobrze”. Ponieważ akceptuje wejście potokowe, może być używany w zaklęciach wielopoleceniowych. Jak zobaczymy, to małe samodzielne narzędzie jest w rzeczywistości świetnym graczem zespołowym.
Jednym ze sposobów, w jaki używam wc , jest zastępowanie go w skomplikowanym poleceniu lub aliasie, który przygotowuję. Jeśli gotowe polecenie może być destrukcyjne i usuwać pliki, często używam wc jako zastępstwa dla prawdziwego, niebezpiecznego polecenia.
W ten sposób podczas tworzenia polecenia otrzymuję wizualną informację zwrotną, że każdy plik jest przetwarzany zgodnie z oczekiwaniami. Nie ma szans, żeby coś złego się wydarzyło, kiedy zmagam się ze składnią.
Tak proste, jak wc , jest jeszcze kilka małych dziwactw, o których musisz wiedzieć.
Pierwsze kroki z wc
Najprostszym sposobem użycia wc jest przekazanie nazwy pliku tekstowego w wierszu poleceń.
wc lorem.txt

Powoduje to, że wc skanuje plik i liczy wiersze, słowa i bajty i zapisuje je w oknie terminala.
Za słowa uznaje się wszystko, co jest ograniczone białymi znakami. To, czy są to słowa z prawdziwego języka, czy nie, nie ma znaczenia. Jeśli plik zawiera tylko „frd g lkj”, nadal liczy się jako trzy słowa.
Wiersze to sekwencje znaków zakończone znakiem powrotu karetki lub końcem pliku. Nie ma znaczenia, czy wiersz zawija się w edytorze, czy w oknie terminala, dopóki wc nie napotka znaku powrotu karetki lub końca pliku, nadal jest to ten sam wiersz.
Nasz pierwszy przykład znalazł jedną linię w całym pliku. Oto zawartość pliku „lorem.txt”.
kot lorem.txt
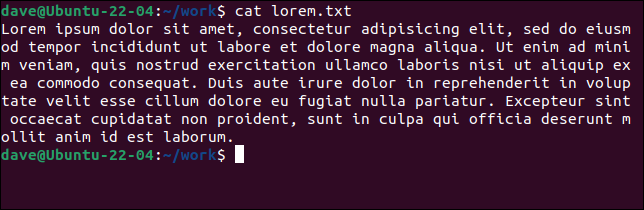
Wszystko to liczy się jako jeden wiersz, ponieważ nie ma powrotu karetki. Porównaj to z innym plikiem „lorem2.txt” i tym, jak wc go interpretuje.
wc lorem2.txt
kot lorem2.txt
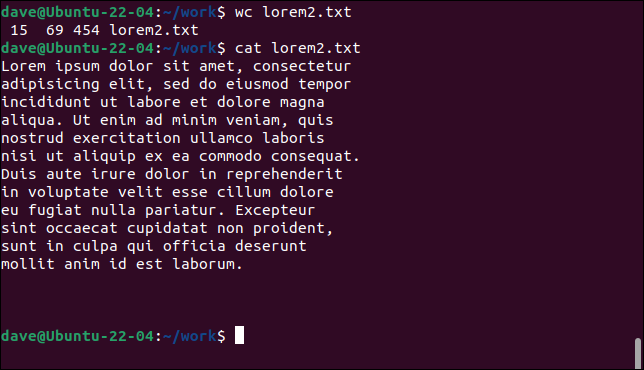
Tym razem wc liczy 15 wierszy, ponieważ do tekstu wstawiono znaki powrotu karetki, aby rozpocząć nowy wiersz w określonych punktach. Jeśli jednak policzysz wiersze z tekstem, zobaczysz, że jest ich tylko 12.
Pozostałe trzy wiersze to puste wiersze na końcu pliku. Zawierają one tylko zwroty karetki. Mimo że w tych wierszach nie ma tekstu, nowy wiersz został rozpoczęty, więc wc liczy je jako takie.
Do wc możemy przekazać dowolną liczbę plików.
wc lorem.txt lorem2.txt
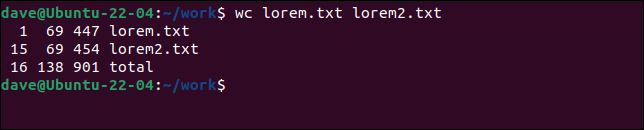
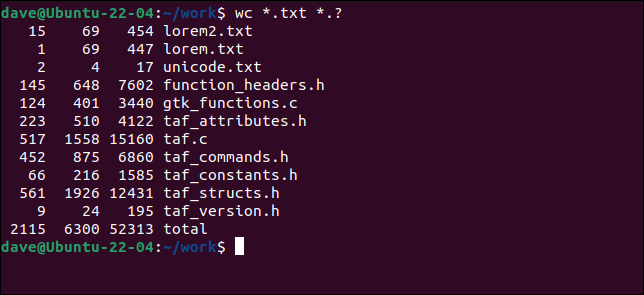
Otrzymujemy statystyki dla każdego pojedynczego pliku i sumę dla wszystkich plików.
Możemy również użyć symboli wieloznacznych, aby wybrać pasujące pliki zamiast jawnie nazwanych plików.
wc *.txt *.?
Opcje wiersza poleceń
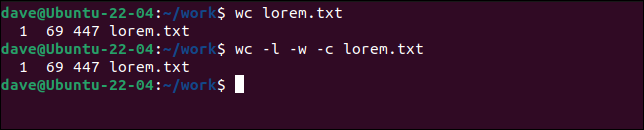
Domyślnie wc wyświetla wiersze, słowa i bajty w każdym pliku. Działa to tak samo, jak użycie opcji -l (linie) -w (słowa) i -c (bajty).
wc lorem.txt
wc -l -w -c lorem.txt
Możemy określić, jaką kombinację cyfr chcemy zobaczyć.
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
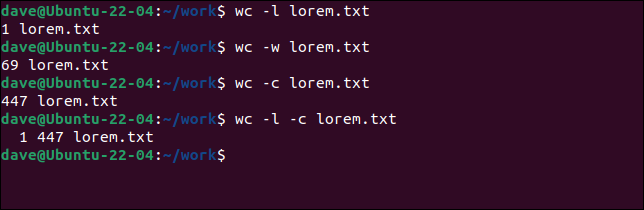
Szczególną uwagę należy zwrócić na ostatnią cyfrę, wygenerowaną przez opcję -c (bajty). Wiele osób myli to jako liczenie postaci. W rzeczywistości liczy bajty . Liczba znaków i liczba bajtów mogą być takie same. Ale nie zawsze.
Przyjrzyjmy się zawartości pliku o nazwie „unicode.txt”.
kot unicode.txt

Składa się z trzech słów i znaku alfabetu innego niż łaciński. Pozwolimy wc przetworzyć plik z domyślnym ustawieniem bytes , i zrobimy to ponownie, ale zażądamy znaków z opcją -m (znaki).
wc unicode.txt
wc -l -w -m unicode.txt
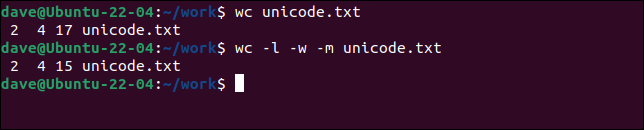
Jest więcej bajtów niż znaków.
Przyjrzyjmy się zrzutowi szesnastkowemu pliku i zobaczmy, co się dzieje. Opcja polecenia hexdump -C (canonical) wyświetla bajty w pliku w wierszach po 16, z ich zwykłym odpowiednikiem ASCII (jeśli taki istnieje) pokazanym na końcu wiersza. Jeśli nie ma odpowiadającego znaku ASCII, kropka „ . zamiast tego wyświetlany jest symbol ”.

hexdump -C unicode.txt
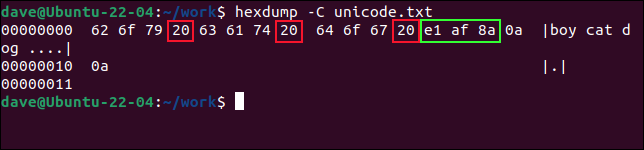
W ASCII wartość szesnastkowa 0x20 reprezentuje znak spacji. Jeśli policzymy trzy wartości od lewej, zobaczymy, że następna wartość to znak spacji. Tak więc te pierwsze trzy wartości 0x62 , 0x6f i 0x79 reprezentują litery w „chłopiec”.
Przeskakując nad 0x20 , widzimy kolejny zestaw trzech wartości szesnastkowych: 0x63 , 0x61 i 0x74 . To znaczy „kot”. Przeskakując następny znak spacji, widzimy jeszcze trzy wartości dla liter w „piesie”. Są to 0x64 , 0x5f i 0x67 .
Tuż za słowem „pies” widzimy spację 0x20 oraz pięć kolejnych wartości szesnastkowych. Ostatnie dwa to powrót karetki, 0x0a .
Pozostałe trzy bajty reprezentują znak spoza alfabetu łacińskiego, który otoczyliśmy zielonym pierścieniem. Jest to znak Unicode, którego zakodowanie zajmuje trzy bajty. Są to 0xe1 , 0xaf i 0x8a .
Upewnij się więc, że wiesz, co liczysz, i że bajty i znaki nie muszą być takie same. Zwykle liczenie bajtów jest bardziej przydatne, ponieważ mówi, co faktycznie znajduje się w pliku. Liczenie według znaków daje liczbę rzeczy reprezentowanych przez zawartość pliku.
POWIĄZANE: Czym są kodowania znaków, takie jak ANSI i Unicode, i czym się różnią?
Pobieranie nazw plików z pliku
Jest inny sposób dostarczania nazw plików do wc . Możesz umieścić nazwy plików w pliku i przekazać nazwę tego pliku do wc . Otwiera plik, wyodrębnia nazwy plików i przetwarza je tak, jakby zostały przekazane w wierszu poleceń. Pozwala to na przechowywanie dowolnej kolekcji nazw plików do ponownego wykorzystania.
Ale jest wpadka, i to jest duża. Nazwy plików muszą być zakończone znakiem NULL , a nie zakończone znakiem powrotu karetki . Oznacza to, że po każdej nazwie pliku musi znajdować się pusty bajt 0x00 zamiast zwykłego bajtu powrotu karetki 0x0a .
Nie możesz otworzyć edytora i utworzyć pliku w tym formacie. Zazwyczaj takie pliki są generowane przez inne programy. Ale jeśli masz taki plik, tak byś go używał.
Oto nasz plik zawierający nazwy plików. Otwarcie go w less pokazuje dziwne znaki „ ^@ ”, których less używa do wskazania bajtów null.
mniej source-files-list.txt

Aby użyć pliku z wc , musimy użyć --files0-from (odczytaj dane wejściowe z) i przekazać nazwę pliku zawierającego nazwy plików.
wc ---files0-from=source-files-list.txt
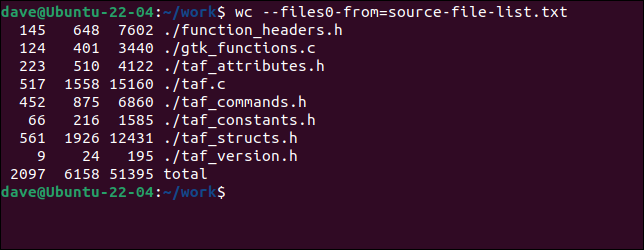
Pliki są przetwarzane dokładnie tak, jakby zostały dostarczone w wierszu poleceń.
Wejście rurowe do wc
O wiele bardziej powszechnym, elastycznym i produktywnym sposobem wysyłania danych wejściowych do wc jest przesyłanie danych wyjściowych z innych poleceń do wc . Możemy to zademonstrować za pomocą polecenia echo .
echo "Policz to dla mnie" | toaleta
echo -e "Policz to\ndla mnie" | toaleta
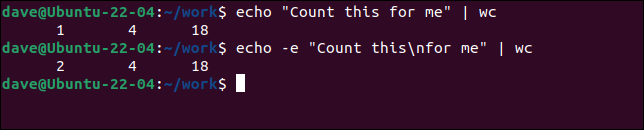
Drugie polecenie echo używa opcji -e (znaki specjalne), aby zezwolić na sekwencje specjalne, takie jak kod formatowania nowej linii „ \n ”. Wstawia to nową linię, powodując, że wc widzi wejście jako dwie linie.
Oto kaskada poleceń przekazujących ich dane wejściowe od jednego do drugiego.
znajdź ./* -typ f | obr | wyciąć -d'. -f1 | obr | sortuj | uniq
- find szuka plików (
type -f) rekurencyjnie, zaczynając od bieżącego katalogu.revodwraca nazwy plików. - cut wyodrębnia pierwsze pole (
-f1), definiując ogranicznik pola jako kropkę „.” i czytanie od „początku” odwróconej nazwy pliku do pierwszego znalezionego okresu. Teraz wyodrębniliśmy rozszerzenie pliku. - rev odwraca wyodrębnione pierwsze pole.
- sort sortuje je w rosnącej kolejności alfabetycznej.
- uniq wyświetla unikalne wpisy w oknie terminala.
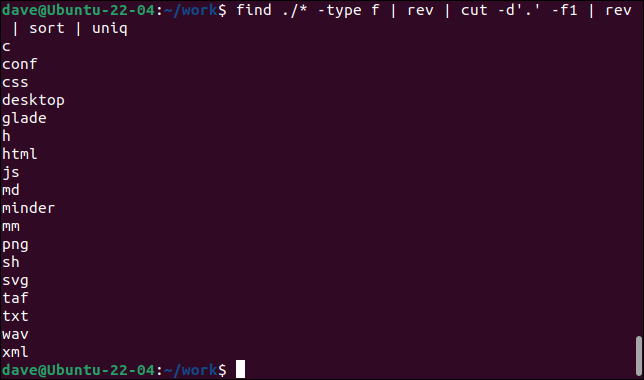
To polecenie wyświetla wszystkie unikalne rozszerzenia plików w bieżącym katalogu i podkatalogach.
Jeśli dodamy opcję -c (liczba) do polecenia uniq , zliczy ona wystąpienia każdego typu rozszerzenia. Ale jeśli chcemy wiedzieć, ile jest różnych, unikalnych rozszerzeń plików, możemy usunąć wc jako ostatnie polecenie w linii i użyć opcji -l (linie).
znajdź ./* -typ f | obr | wyciąć -d'. -f1 | obr | sortuj | unikalny | wc-l

POWIĄZANE: Jak korzystać z polecenia cięcia systemu Linux
I w końcu
Oto ostatnia sztuczka, którą wc może dla Ciebie zrobić. Powie ci długość najdłuższego wiersza w pliku. Niestety nie mówi, która to linia. To po prostu daje długość.
wc -L taf.c

Uważaj jednak, że tabulatory są liczone jako osiem spacji. W moim edytorze na początku tej linii znajdują się trzy zakładki z dwoma spacjami. Jego rzeczywista długość to 124 znaki. Tak więc podana liczba jest sztucznie rozszerzona.
Traktowałbym tę funkcję z dużą przymrużeniem oka. I przez to mam na myśli nie używaj go. Jego wyniki są mylące.
Pomimo swoich dziwactw, wc jest świetnym narzędziem do wpadania do poleceń potoku, gdy musisz policzyć wszelkiego rodzaju wartości, a nie tylko słowa w pliku.
POWIĄZANE: 37 ważnych poleceń systemu Linux, które powinieneś znać