
Jak analizować dane CSV w Bash
Opublikowany: 2022-09-16
Pliki z wartościami oddzielonymi przecinkami (CSV) są jednym z najpopularniejszych formatów eksportowanych danych. W systemie Linux możemy odczytywać pliki CSV za pomocą poleceń Bash. Ale może się to bardzo skomplikować, bardzo szybko. Pomożemy.
Co to jest plik CSV?
Plik wartości oddzielonych przecinkami to plik tekstowy, który zawiera dane tabelaryczne. CSV to rodzaj danych rozdzielanych. Jak sama nazwa wskazuje, przecinek „ , ” służy do oddzielenia każdego pola danych – lub wartości – od jego sąsiadów.
CSV jest wszędzie. Jeśli aplikacja ma funkcje importu i eksportu, prawie zawsze będzie obsługiwać CSV. Pliki CSV są czytelne dla człowieka. Możesz zajrzeć do nich mniej, otwierać je w dowolnym edytorze tekstu i przenosić z programu do programu. Na przykład możesz wyeksportować dane z bazy danych SQLite i otworzyć je w LibreOffice Calc.
Jednak nawet CSV może się skomplikować. Chcesz mieć przecinek w polu danych? To pole musi być otoczone cudzysłowami „ " ”. Aby umieścić cudzysłowy w polu, każdy cudzysłów należy wpisać dwukrotnie.
Oczywiście, jeśli pracujesz z CSV wygenerowanym przez program lub skrypt, który napisałeś, format CSV prawdopodobnie będzie prosty i bezpośredni. Jeśli jesteś zmuszony do pracy z bardziej złożonymi formatami CSV, a Linux jest Linuksem, istnieją rozwiązania, których możemy użyć również do tego celu.
Niektóre przykładowe dane
Możesz łatwo wygenerować przykładowe dane CSV, korzystając z witryn takich jak Generator danych online. Możesz zdefiniować żądane pola i wybrać liczbę wierszy danych. Twoje dane są generowane przy użyciu realistycznych wartości fikcyjnych i pobierane na Twój komputer.
Stworzyliśmy plik zawierający 50 wierszy fikcyjnych informacji o pracownikach:
- id : Prosta unikalna wartość całkowita.
- imię : imię osoby.
- nazwisko : Nazwisko osoby.
- job-title : Tytuł zawodowy danej osoby.
- adres e-mail : adres e-mail osoby.
- oddział : Oddział firmy, w której pracują.
- state : stan, w którym znajduje się oddział.
Niektóre pliki CSV mają wiersz nagłówka z listą nazw pól. Nasz przykładowy plik ma jeden. Oto początek naszego pliku:
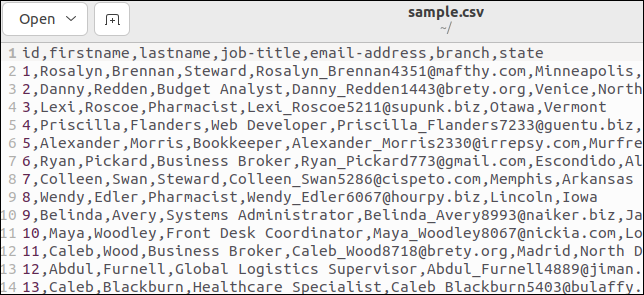
Pierwszy wiersz zawiera nazwy pól jako wartości oddzielone przecinkami.
Parsowanie danych z pliku CSV
Napiszmy skrypt, który odczyta plik CSV i wyodrębni pola z każdego rekordu. Skopiuj ten skrypt do edytora i zapisz go w pliku o nazwie „field.sh”.
#! /bin/bash podczas gdy IFS=”, czytaj -r id imię nazwisko stanowisko e-mail stan oddziału robić echo "Identyfikator rekordu: $id" echo "Imię: $Imię" echo " Nazwisko: $nazwisko" echo "Tytuł pracy: $jobtitle" echo "Dodaj e-mail: $email" echo " Gałąź: $gałąź" echo " Stan: $stan" Echo "" gotowe < <(tail -n +2 sample.csv)
W naszym małym skrypcie jest całkiem sporo. Rozbijmy to.

Używamy pętli while . Dopóki warunek pętli while zostanie spełniony, while pętli zostanie wykonana. Treść pętli jest dość prosta. Zbiór instrukcji echo jest używany do drukowania wartości niektórych zmiennych w oknie terminala.
Warunek while pętli jest bardziej interesujący niż treść pętli. Określamy, że przecinek powinien być używany jako wewnętrzny separator pól, z instrukcją IFS="," . IFS jest zmienną środowiskową. Polecenie read odnosi się do jego wartości podczas analizowania sekwencji tekstu.
Używamy opcji -r polecenia read (zachowaj ukośniki odwrotne), aby zignorować wszelkie ukośniki odwrotne, które mogą znajdować się w danych. Będą traktowane jak zwykłe postacie.
Tekst analizowany przez polecenie read jest przechowywany w zestawie zmiennych nazwanych po polach CSV. Równie dobrze można je nazwać field1, field1, field2, ... field7 , ale znaczące nazwy ułatwiają życie.
Dane są uzyskiwane jako dane wyjściowe z polecenia tail . Używamy tail , ponieważ pozwala nam to w prosty sposób pominąć linię nagłówka pliku CSV. Opcja -n +2 (numer wiersza) nakazuje tail rozpoczęcie czytania od wiersza numer dwa.
Konstrukcja <(...) nazywana jest substytucją procesu. Powoduje, że Bash akceptuje dane wyjściowe procesu tak, jakby pochodziły z deskryptora pliku. Jest to następnie przekierowywane do pętli while , dostarczając tekst, który przeanalizuje polecenie read .
Uczyń skrypt wykonywalnym za pomocą polecenia chmod . Musisz to zrobić za każdym razem, gdy kopiujesz skrypt z tego artykułu. W każdym przypadku zastąp nazwę odpowiedniego skryptu.
chmod +x pole.sh

Kiedy uruchamiamy skrypt, rekordy są poprawnie dzielone na ich pola składowe, przy czym każde pole jest przechowywane w innej zmiennej.
./pole.sh
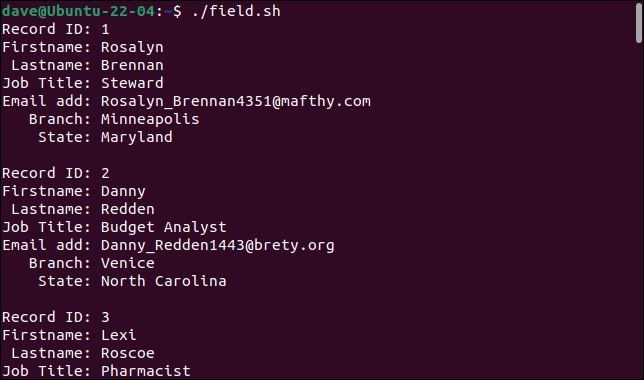
Każdy rekord jest drukowany jako zestaw pól.
Wybieranie pól
Być może nie chcemy lub nie musimy pobierać każdego pola. Możemy uzyskać wybór pól, włączając polecenie cut .
Ten skrypt nazywa się „select.sh”.
#!/kosz/bash podczas gdy IFS="," read -r id nazwa stanowiska pracy stan gałęzi robić echo "Identyfikator rekordu: $id" echo "Tytuł pracy: $jobtitle" echo " Gałąź: $gałąź" echo " Stan: $stan" Echo "" gotowe < <(cut -d "," -f1,4,6,7 sample.csv | ogon -n +2)
Dodaliśmy polecenie cut do klauzuli zastępowania procesu. Używamy opcji -d (ogranicznik), aby powiedzieć cut , aby używał przecinków „ , ” jako ogranicznika. Opcja -f (pole) mówi cut , że potrzebujemy pól jeden, cztery, sześć i siedem. Te cztery pola są wczytywane do czterech zmiennych, które są drukowane w treści pętli while .
Oto, co otrzymujemy, gdy uruchamiamy skrypt.
./wybierz.sh
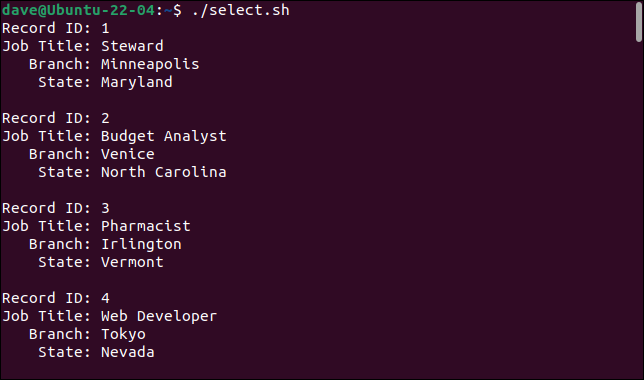
Dodając polecenie cut , jesteśmy w stanie wybrać pola, które chcemy i zignorować te, których nie mamy.
Na razie w porządku. Ale…
Jeśli plik CSV, z którym masz do czynienia, jest nieskomplikowany, bez przecinków i cudzysłowów w danych pola, to, co omówiliśmy, prawdopodobnie spełni Twoje potrzeby w zakresie analizowania pliku CSV. Aby pokazać problemy, które możemy napotkać, zmodyfikowaliśmy małą próbkę danych, aby wyglądała tak.
identyfikator, imię, nazwisko, stanowisko, adres e-mail, oddział, stan 1, Rosalyn, Brennan, "Steward, Senior", [email protected], Minneapolis, Maryland 2,Danny,Redden,„Analityk „„Budżet”””,[email protected],Wenecja,Karolina Północna 3, Lexi, Roscoe, farmaceuta, Irlington, Vermont;
- Rekord jeden zawiera przecinek w polu
job-title, więc pole musi być ujęte w cudzysłów. - Rekord drugi zawiera słowo ujęte w dwa zestawy cudzysłowów w polu
jobs-title. - Rekord trzeci nie zawiera danych w polu
email-address.
Te dane zostały zapisane jako „sample2.csv”. Zmodyfikuj skrypt „field.sh”, aby wywołać „sample2.csv” i zapisz go jako „field2.sh”.
#! /bin/bash podczas gdy IFS=”, czytaj -r id imię nazwisko stanowisko e-mail stan oddziału robić echo "Identyfikator rekordu: $id" echo "Imię: $Imię" echo " Nazwisko: $nazwisko" echo "Tytuł pracy: $jobtitle" echo "Dodaj e-mail: $email" echo " Gałąź: $gałąź" echo " Stan: $stan" Echo "" gotowe < <(ogon -n +2 próbka2.csv)
Kiedy uruchamiamy ten skrypt, widzimy pęknięcia pojawiające się w naszych prostych parserach CSV.

./field2.sh

Pierwszy rekord dzieli pole stanowiska pracy na dwa pola, traktując drugą część jako adres e-mail. Każde pole po tym jest przesunięte o jedno miejsce w prawo. Ostatnie pole zawiera zarówno branch , jak i wartości state .
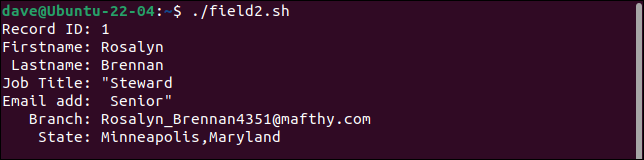
Drugi rekord zachowuje wszystkie cudzysłowy. Powinna mieć tylko jedną parę cudzysłowów wokół słowa „Budżet”.
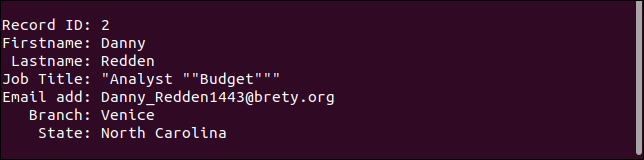
Trzeci rekord faktycznie obsługuje brakujące pole tak, jak powinien. Brakuje adresu e-mail, ale wszystko inne jest tak, jak powinno.

Wbrew intuicji, w przypadku prostego formatu danych, bardzo trudno jest napisać solidny parser CSV z ogólnymi przypadkami. Narzędzia takie jak awk pozwolą ci się zbliżyć, ale zawsze zdarzają się przypadki skrajne i wyjątki, które się prześlizgną.

Próba napisania niezawodnego parsera CSV prawdopodobnie nie jest najlepszym rozwiązaniem. Alternatywne podejście — zwłaszcza jeśli pracujesz do pewnego rodzaju terminu — wykorzystuje dwie różne strategie.
Jednym z nich jest użycie specjalnie zaprojektowanego narzędzia do manipulowania i wyodrębniania danych. Drugim jest oczyszczenie danych i zastąpienie scenariuszy problemów, takich jak osadzone przecinki i cudzysłowy. Twoje proste parsery Bash mogą następnie poradzić sobie z przyjaznym dla Bash plikiem CSV.
Zestaw narzędzi csvkit
Zestaw narzędzi CSV csvkit to zbiór narzędzi stworzonych specjalnie do pomocy w pracy z plikami CSV. Musisz go zainstalować na swoim komputerze.
Aby zainstalować go na Ubuntu, użyj tego polecenia:
sudo apt install csvkit

Aby zainstalować go w Fedorze, musisz wpisać:
sudo dnf zainstaluj python3-csvkit

Na Manjaro polecenie to:
sudo pacman -S csvkit

Jeśli przekażemy do niego nazwę pliku CSV, narzędzie csvlook wyświetli tabelę pokazującą zawartość każdego pola. Zawartość pola jest wyświetlana, aby pokazać, co reprezentuje zawartość pola, a nie jak są przechowywane w pliku CSV.
Wypróbujmy csvlook z naszym problematycznym plikiem „sample2.csv”.
csvlook sample2.csv
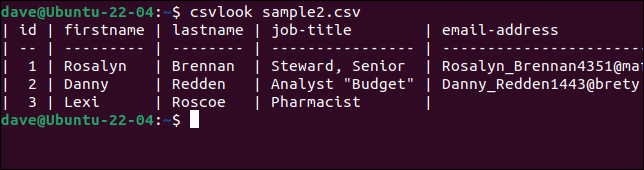
Wszystkie pola są poprawnie wyświetlane. To dowodzi, że problemem nie jest plik CSV. Problem polega na tym, że nasze skrypty są zbyt uproszczone, aby poprawnie zinterpretować plik CSV.
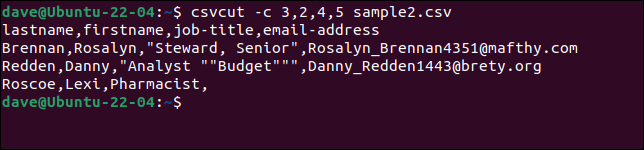
Aby wybrać określone kolumny, użyj polecenia csvcut . Opcji -c (kolumna) można używać z nazwami pól lub numerami kolumn, albo z kombinacją obu.
Załóżmy, że musimy wyodrębnić imiona i nazwiska, stanowiska i adresy e-mail z każdego rekordu, ale chcemy, aby kolejność imion była „nazwisko, imię”. Wszystko, co musimy zrobić, to umieścić nazwy pól lub numery w żądanej przez nas kolejności.
Wszystkie te trzy polecenia są równoważne.
csvcut -c nazwisko, imię, stanowisko, przykładowy adres e-mail2.csv
csvcut -c nazwisko,imię,4,5 próbka2.csv
csvcut -c 3,2,4,5 sample2.csv
Możemy dodać polecenie csvsort , aby posortować dane wyjściowe według pola. Używamy opcji -c (kolumna), aby określić kolumnę, według której ma odbywać się sortowanie, oraz opcji -r (odwrotnej), aby sortować w kolejności malejącej.
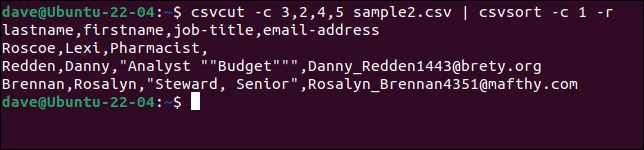
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
Aby upiększyć dane wyjściowe, możemy je przesłać przez csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
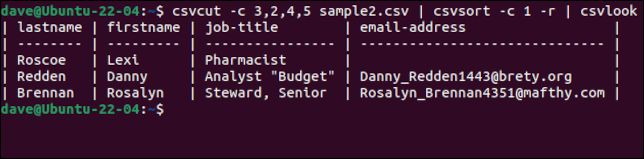
Zgrabnym akcentem jest to, że nawet jeśli rekordy są posortowane, wiersz nagłówka z nazwami pól jest utrzymywany jako pierwszy wiersz. Gdy jesteśmy zadowoleni, że mamy dane w pożądany sposób, możemy usunąć csvlook z łańcucha poleceń i utworzyć nowy plik CSV, przekierowując dane wyjściowe do pliku.
Dodaliśmy więcej danych do „sample2.file”, usunęliśmy polecenie csvsort i utworzyliśmy nowy plik o nazwie „sample3.csv”.
csvcut -c 3,2,4,5 próbka2.csv > próbka3.csv

Bezpieczny sposób na oczyszczenie danych CSV
Jeśli otworzysz plik CSV w LibreOffice Calc, każde pole zostanie umieszczone w komórce. Możesz użyć funkcji Znajdź i zamień, aby wyszukać przecinki. Możesz je zastąpić słowem „nic”, aby zniknęły, lub znakiem, który nie wpłynie na parsowanie CSV, np. średnikiem „ ; " na przykład.
Nie zobaczysz cudzysłowów wokół cytowanych pól. Jedyne cudzysłowy, które zobaczysz, to osadzone cudzysłowy w danych pola. Są one pokazane jako pojedyncze cudzysłowy. Znalezienie i zastąpienie ich pojedynczym apostrofem „ ' ” zastąpi podwójne cudzysłowy w pliku CSV.
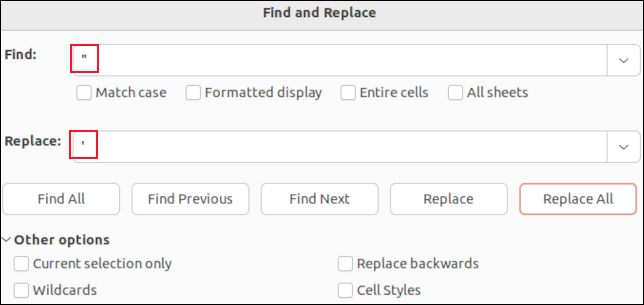
Wykonanie wyszukiwania i zamiany w aplikacji takiej jak LibreOffice Calc oznacza, że nie można przypadkowo usunąć żadnego z przecinków separatora pól ani usunąć cudzysłowów wokół cytowanych pól. Zmienisz tylko wartości danych pól.
Zmieniliśmy wszystkie przecinki w polach ze średnikami i wszystkie osadzone cudzysłowy z apostrofami i zapisaliśmy nasze zmiany.
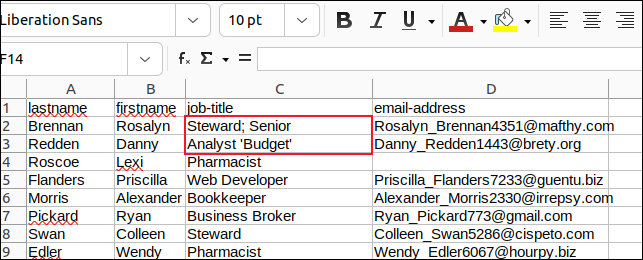
Następnie stworzyliśmy skrypt o nazwie „field3.sh”, który analizuje plik „sample3.csv”.
#! /bin/bash podczas gdy IFS=”, czytaj -r nazwisko imię stanowisko e-mail robić echo " Nazwisko: $nazwisko" echo "Imię: $Imię" echo "Tytuł pracy: $jobtitle" echo "Dodaj e-mail: $email" Echo "" gotowe < <(tail -n +2 sample3.csv)
Zobaczmy, co otrzymamy, gdy go uruchomimy.
./field3.sh
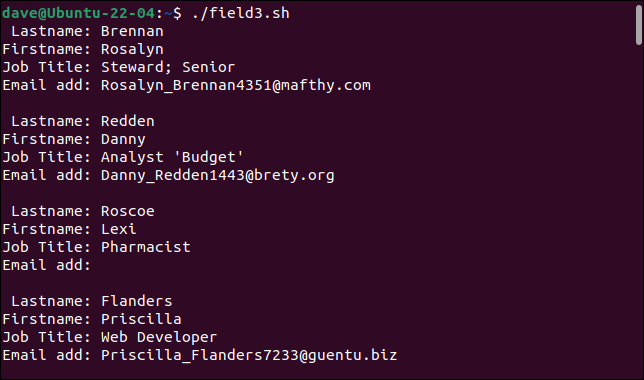
Nasz prosty parser może teraz obsłużyć nasze wcześniej problematyczne rekordy.
Zobaczysz dużo CSV
CSV jest prawdopodobnie najbardziej zbliżony do wspólnego języka dla danych aplikacji. Większość aplikacji obsługujących jakąś formę danych obsługuje importowanie i eksportowanie plików CSV. Wiedza o tym, jak radzić sobie z CSV – w realistyczny i praktyczny sposób – zapewni Ci dobrą pozycję.
POWIĄZANE: 9 przykładów skryptów Bash, które pomogą Ci zacząć w systemie Linux