
Jak wykonać OCR z wiersza poleceń systemu Linux za pomocą Tesseract
Opublikowany: 2022-01-29
Możesz wyodrębnić tekst z obrazów w wierszu poleceń systemu Linux za pomocą silnika Tesseract OCR. Jest szybki, dokładny i działa w około 100 językach. Oto jak z niego korzystać.
Optyczne rozpoznawanie znaków
Optyczne rozpoznawanie znaków (OCR) to możliwość przeglądania i znajdowania słów na obrazie, a następnie wyodrębniania ich jako edytowalnego tekstu. To proste zadanie dla ludzi jest bardzo trudne do wykonania przez komputery. Wczesne wysiłki były co najmniej niezgrabne. Komputery często były zdezorientowane, jeśli krój pisma lub rozmiar nie odpowiadały gustowi oprogramowania OCR.
Mimo to pionierów w tej dziedzinie nadal szanowano. Jeśli zgubiłeś elektroniczną kopię dokumentu, ale nadal miałeś wersję drukowaną, OCR może odtworzyć elektroniczną, edytowalną wersję. Nawet jeśli wyniki nie były w 100 procentach dokładne, nadal była to świetna oszczędność czasu.
Po pewnym ręcznym uporządkowaniu będziesz miał z powrotem swój dokument. Ludzie wybaczali popełnione błędy, ponieważ rozumieli złożoność zadania stojącego przed pakietem OCR. Poza tym było to lepsze niż przepisywanie całego dokumentu.
Od tego czasu sytuacja znacznie się poprawiła. Aplikacja Tesseract OCR, napisana przez Hewlett Packard, powstała w latach 80. jako aplikacja komercyjna. Został otwarty w 2005 roku i jest teraz obsługiwany przez Google. Obsługuje wiele języków, jest uważany za jeden z najdokładniejszych dostępnych systemów OCR i można z niego korzystać za darmo.
Instalowanie Tesseract OCR
Aby zainstalować Tesseract OCR na Ubuntu, użyj tego polecenia:
sudo apt-get zainstaluj tesseract-ocr

W Fedorze polecenie to:
sudo dnf zainstaluj tesseract

Na Manjaro musisz wpisać:
sudo pacman -Syu tesseract

Korzystanie z Tesseract OCR
Zamierzamy postawić zestaw wyzwań przed Tesseract OCR. Nasz pierwszy obraz zawierający tekst to fragment motywu 63 ogólnych przepisów o ochronie danych. Zobaczmy, czy OCR może to przeczytać (i nie zasnąć).

To trudny obraz, ponieważ każde zdanie zaczyna się słabą liczbą w indeksie górnym, co jest typowe w dokumentach legislacyjnych.
Musimy podać poleceniu tesseract kilka informacji, w tym:
- Nazwa pliku obrazu, który chcemy przetworzyć.
- Nazwa pliku tekstowego, który utworzy do przechowywania wyodrębnionego tekstu. Nie musimy podawać rozszerzenia pliku (zawsze będzie to .txt). Jeśli plik o tej samej nazwie już istnieje, zostanie nadpisany.
- Możemy użyć opcji
--dpi, aby powiedziećtesseract, jaka jest rozdzielczość obrazu w punktach na cal (dpi). Jeśli nie podamy wartości dpi,tesseractspróbuje to rozgryźć.
Nasz plik obrazu nosi nazwę „recital-63.png”, a jego rozdzielczość to 150 dpi. Utworzymy z niego plik tekstowy o nazwie „recital.txt”.
Nasze polecenie wygląda tak:
motyw tesseract-63.png motyw --dpi 150

Wyniki są bardzo dobre. Jedynym problemem są indeksy górne — były zbyt słabe, aby można je było poprawnie odczytać. Dobra jakość obrazu jest niezbędna do uzyskania dobrych wyników.

tesseract zinterpretował liczby w indeksie górnym jako cudzysłowy („) i symbole stopni (°), ale rzeczywisty tekst został idealnie wyodrębniony (prawa strona obrazu musiała zostać przycięta, aby pasowała tutaj).
Ostatni znak to bajt o wartości szesnastkowej 0x0C, który jest znakiem powrotu karetki.
Poniżej znajduje się kolejny obraz z tekstem w różnych rozmiarach, pogrubionym i kursywą.

Nazwa tego pliku to „bold-italic.png”. Chcemy stworzyć plik tekstowy o nazwie „bold.txt”, więc nasze polecenie to:
tesseract bold-italic.png bold --dpi 150

Ten nie sprawiał żadnych problemów, a tekst został wydobyty perfekcyjnie.

Korzystanie z różnych języków
Tesseract OCR obsługuje około 100 języków. Aby używać języka, musisz go najpierw zainstalować. Gdy znajdziesz na liście język, którego chcesz użyć, zanotuj jego skrót. Zamierzamy zainstalować obsługę języka walijskiego. Jego skrót to „cym”, co jest skrótem od „Cymru”, co oznacza walijski.
Pakiet instalacyjny nazywa się „tesseract-ocr-” ze skrótem języka oznaczonym na końcu. Aby zainstalować plik języka walijskiego w Ubuntu, użyjemy:
sudo apt-get zainstaluj tesseract-ocr-cym


Obrazek z tekstem znajduje się poniżej. To pierwszy wers walijskiego hymnu narodowego.

Zobaczmy, czy Tesseract OCR sprosta wyzwaniu. Użyjemy opcji -l (język), aby poinformować tesseract , w jakim języku chcemy pracować:
tesseract hen-wlad-fy-nhadau.png hymn -l cym --dpi 150

tesseract radzi sobie doskonale, jak widać w wyodrębnionym tekście poniżej. Da awn , Tesserakt OCR.

Jeśli twój dokument zawiera co najmniej dwa języki (na przykład słownik walijski na angielski), możesz użyć znaku plus ( + ), aby powiedzieć tesseract , że ma dodać inny język, na przykład:
tesseract image.png plik tekstowy -l eng+cym+fra
Korzystanie z Tesseract OCR z plikami PDF
Polecenie tesseract jest przeznaczone do pracy z plikami graficznymi, ale nie umożliwia odczytywania plików PDF. Jeśli jednak chcesz wyodrębnić tekst z pliku PDF, możesz najpierw użyć innego narzędzia do wygenerowania zestawu obrazów. Pojedynczy obraz będzie reprezentował pojedynczą stronę pliku PDF.
Potrzebne narzędzie pdftppm powinno być już zainstalowane na komputerze z systemem Linux. Plik PDF, którego użyjemy w naszym przykładzie, jest kopią przełomowego artykułu Alana Turinga na temat sztucznej inteligencji „Maszyny komputerowe i inteligencja”.

Używamy opcji -png , aby określić, że chcemy tworzyć pliki PNG. Nazwa pliku naszego pliku PDF to „turing.pdf”. Nasze pliki obrazów będziemy nazywać „turing-01.png”, „turing-02.png” i tak dalej:
pdftoppm -png turing.pdf turing

Aby uruchomić tesseract na każdym pliku obrazu za pomocą pojedynczego polecenia, musimy użyć pętli for. Dla każdego z naszych plików „turing- nn .png” uruchamiamy tesseract i tworzymy plik tekstowy o nazwie „text-” plus „turing- nn ” jako część nazwy pliku obrazu:
dla mnie w turing-??.png; wykonaj tesseract "$i" "text-$i" -l pol; Gotowe;

Aby połączyć wszystkie pliki tekstowe w jeden, możemy użyć cat :
kot tekst-turing* > kompletny.txt

Więc jak to się stało? Bardzo dobrze, jak widać poniżej. Pierwsza strona wygląda jednak na dość trudne. Ma różne style i rozmiary tekstu oraz dekoracje. Na prawej krawędzi strony znajduje się również pionowy „znak wodny”.
Jednak wydruk jest zbliżony do oryginału. Oczywiście formatowanie zostało utracone, ale tekst jest poprawny.
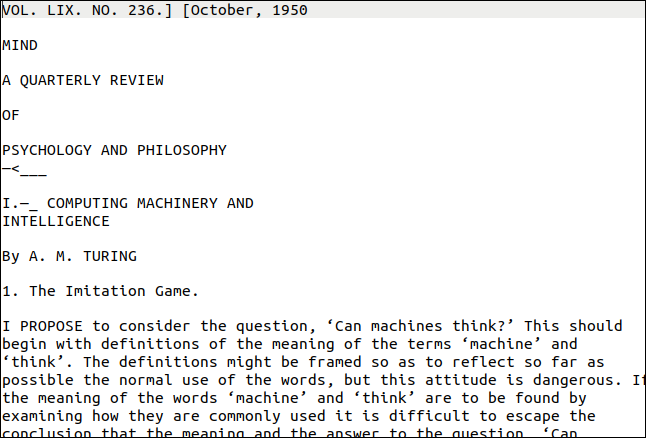
Pionowy znak wodny został przepisany jako bełkot na dole strony. Tekst był zbyt mały, aby mógł być dokładnie odczytany przez tesseract , ale łatwo byłoby go znaleźć i usunąć. Najgorszym wynikiem byłyby zbłąkane znaki na końcu każdej linii.
Co ciekawe, pojedyncze litery na początku listy pytań i odpowiedzi na stronie drugiej zostały zignorowane. Sekcja z pliku PDF jest pokazana poniżej.

Jak widać poniżej, pytania pozostają, ale „Q” i „A” na początku każdej linii zostały utracone.

Diagramy również nie zostaną poprawnie przepisane. Przyjrzyjmy się, co się dzieje, gdy próbujemy wyodrębnić ten pokazany poniżej z pliku Turing PDF.

Jak widać w naszym wyniku poniżej, znaki zostały odczytane, ale format diagramu został utracony.

Ponownie tesseract zmagał się z małym rozmiarem indeksów dolnych i były one nieprawidłowo renderowane.
Szczerze mówiąc, nadal był to dobry wynik. Nie byliśmy w stanie wyodrębnić prostego tekstu, ale ten przykład został wybrany celowo, ponieważ stanowił wyzwanie.
Dobre rozwiązanie, gdy go potrzebujesz
OCR nie jest czymś, czego będziesz potrzebować codziennie. Jednak gdy zajdzie taka potrzeba, dobrze wiedzieć, że masz do dyspozycji jeden z najlepszych silników OCR.