
cURL vs. wget w Linuksie: jaka jest różnica?
Opublikowany: 2022-07-13
Jeśli zapytasz grupę użytkowników Linuksa, z czym pobierają pliki, niektórzy powiedzą wget , a inni cURL . Jaka jest różnica i czy jedno jest lepsze od drugiego?
Zaczęło się od łączności
Naukowcy rządowi zaczęli łączyć ze sobą różne sieci już w latach 60. XX wieku, dając początek połączonym sieciom. Ale narodziny Internetu, jaki znamy, miały miejsce 1 stycznia 1983 roku, kiedy został zaimplementowany protokół TCP/IP. To było brakujące ogniwo. Umożliwiło to różnym komputerom i sieciom komunikowanie się przy użyciu wspólnego standardu.
W 1991 r. CERN wydał oprogramowanie World Wide Web, którego używali wewnętrznie od kilku lat. Zainteresowanie tą nakładką wizualną do Internetu było natychmiastowe i powszechne. Pod koniec 1994 roku istniało 10 000 serwerów internetowych i 10 milionów użytkowników.

Te dwa kamienie milowe — internet i sieć — reprezentują bardzo różne oblicza łączności. Ale mają też wiele takich samych funkcji.
Łączność oznacza właśnie to. Łączysz się z jakimś zdalnym urządzeniem, takim jak serwer. I łączysz się z nim, ponieważ jest na nim coś, czego potrzebujesz lub chcesz. Ale jak pobrać zdalnie hostowany zasób na lokalny komputer z wiersza poleceń systemu Linux?
W 1996 roku narodziły się dwa narzędzia, które umożliwiają pobieranie zdalnie hostowanych zasobów. Są to wget , który został wydany w styczniu i cURL , który został wydany w grudniu. Oba działają w wierszu poleceń Linuksa. Obaj łączą się ze zdalnymi serwerami i oboje pobierają dla Ciebie rzeczy.
Ale to nie jest zwykły przypadek Linuksa dostarczającego dwa lub więcej narzędzi do wykonania tej samej pracy. Te narzędzia mają różne cele i różne specjalizacje. Problem polega na tym, że są na tyle podobne, że powodują zamieszanie co do tego, którego użyć i kiedy.
Rozważ dwóch chirurgów. Prawdopodobnie nie chcesz, aby chirurg okulista wykonał operację pomostowania aortalno-wieńcowego, ani nie chcesz, aby chirurg serca wykonał operację zaćmy. Tak, obaj są wysoko wykwalifikowanymi lekarzami, ale to nie znaczy, że zastępują siebie nawzajem.
To samo dotyczy wget i cURL .
Różne cele, różne funkcje, niektóre nakładają się
„w” w poleceniu wget jest wskaźnikiem jego zamierzonego celu. Jego głównym celem jest pobieranie stron internetowych, a nawet całych witryn. Jego strona podręcznika opisuje man jako narzędzie do pobierania plików z sieci przy użyciu protokołów HTTP, HTTPS i FTP.
Natomiast cURL działa z 26 protokołami, w tym SCP, SFTP i SMSB oraz HTTPS. Jego strona man mówi, że jest to narzędzie do przesyłania danych do lub z serwera. W szczególności nie jest przystosowany do pracy z witrynami internetowymi. Jest przeznaczony do interakcji ze zdalnymi serwerami przy użyciu dowolnego z wielu obsługiwanych protokołów internetowych.
Tak więc wget jest głównie zorientowany na stronę internetową, podczas gdy cURL jest czymś, co działa na głębszym poziomie, na zwykłym, waniliowym poziomie Internetu.
wget jest w stanie pobierać strony internetowe i może rekursywnie nawigować po całej strukturze katalogów na serwerach internetowych w celu pobrania całych witryn internetowych. Jest również w stanie dostosować łącza na pobranych stronach tak, aby poprawnie wskazywały strony internetowe na komputerze lokalnym, a nie ich odpowiedniki na zdalnym serwerze internetowym.
cURL pozwala na interakcję ze zdalnym serwerem. Może przesyłać pliki, a także je pobierać. cURL współpracuje z serwerami proxy SOCKS4 i SOCKS5 oraz HTTPS z serwerem proxy. Obsługuje automatyczną dekompresję skompresowanych plików w formatach GZIP, BROTLI i ZSTD. cURL umożliwia także równoległe pobieranie wielu transferów.
Ich nakładanie polega na tym, że zarówno wget , jak i cURL umożliwiają pobieranie stron internetowych i korzystanie z serwerów FTP.
To tylko przybliżona metryka, ale możesz poznać względne zestawy funkcji tych dwóch narzędzi, patrząc na długość ich stron man . Na naszej maszynie testowej strona podręcznika dla wget ma 1433 wierszy. Strona man dla cURL ma aż 5296 linijek.

Szybki podgląd wget
Ponieważ wget jest częścią projektu GNU, powinieneś znaleźć go preinstalowany we wszystkich dystrybucjach Linuksa. Korzystanie z niego jest proste, szczególnie w przypadku jego najczęstszych zastosowań: pobierania stron internetowych lub plików.
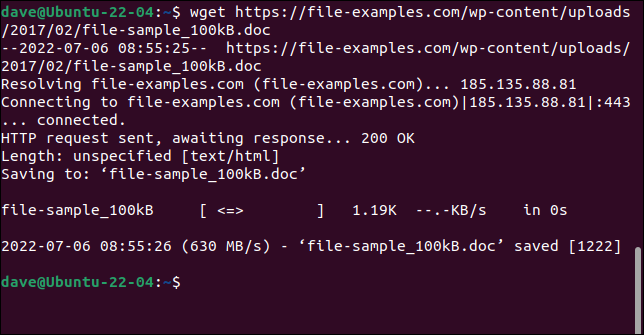
Wystarczy użyć polecenia wget z adresem URL strony internetowej lub pliku zdalnego.
wget https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

Plik jest pobierany i zapisywany na komputerze pod oryginalną nazwą.
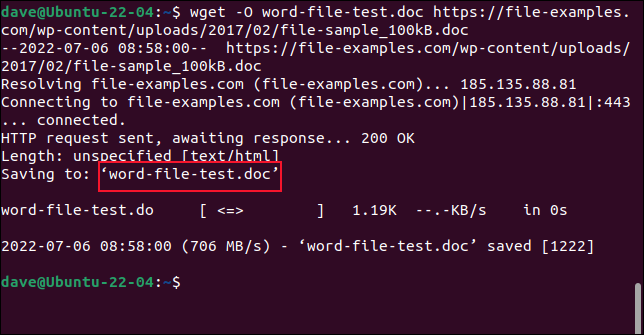
Aby plik został zapisany pod nową nazwą, użyj opcji -O (dokument wyjściowy).
wget -O test-pliku-slowa.doc https://przyklady-pliku.com/wp-content/uploads/2017/02/przyklad-pliku_100kB.doc

Pobrany plik jest zapisywany pod wybraną przez nas nazwą.
Nie używaj opcji -O podczas pobierania stron internetowych. Jeśli to zrobisz, wszystkie pobrane pliki zostaną dołączone do jednego.
Aby pobrać całą witrynę, użyj opcji -m (mirror) i adresu URL strony głównej witryny. Warto również użyć --page-requisites aby upewnić się, że wszystkie pliki pomocnicze wymagane do prawidłowego renderowania stron internetowych również zostały pobrane. Opcja --convert-links dostosowuje łącza w pobranym pliku tak, aby wskazywały właściwe miejsca docelowe na komputerze lokalnym, a nie zewnętrzne lokalizacje w witrynie.
POWIĄZANE: Jak korzystać z wget, najlepszego narzędzia do pobierania wiersza poleceń
Szybki podgląd na cURL
cURL to niezależny projekt open source. Jest preinstalowany na Manjaro 21 i Fedorze 36, ale musiał być zainstalowany na Ubuntu 21.04.
To jest polecenie instalacji cURL na Ubuntu.
sudo apt zainstaluj curl

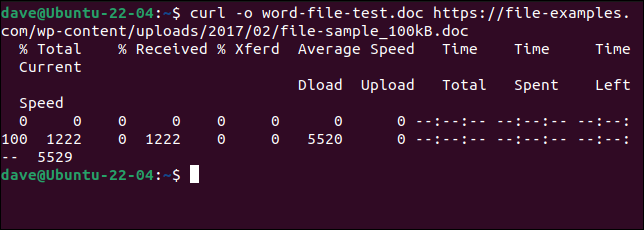
Aby pobrać ten sam plik, co w wget , i zapisać go pod tą samą nazwą, musimy użyć tego polecenia. Zauważ, że opcja -o (wyjście) jest małymi literami z cURL .
curl -o word-file-test.doc https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

Plik jest dla nas pobierany. Podczas pobierania wyświetlany jest pasek postępu ASCII.
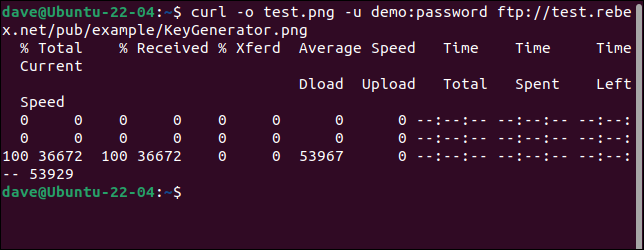
Aby połączyć się z serwerem FTP i pobrać plik, użyj opcji -u (użytkownik) i podaj parę nazwy użytkownika i hasła, w następujący sposób:
curl -o test.png -u demo:hasło ftp://test.rebex.net/pub/example/KeyGenerator.png

Spowoduje to pobranie i zmianę nazwy pliku z testowego serwera FTP.
POWIĄZANE: Jak używać curl do pobierania plików z wiersza poleceń systemu Linux
Nie ma najlepszego
Nie da się odpowiedzieć „Którego powinienem użyć” bez pytania „Co próbujesz zrobić?”
Gdy zrozumiesz, co robią wget i cURL , zdasz sobie sprawę, że nie konkurują ze sobą. Nie spełniają tych samych wymagań i nie starają się zapewnić tej samej funkcjonalności.
Pobieranie stron internetowych i witryn internetowych to wget . Jeśli to właśnie robisz, użyj wget . Do czegokolwiek innego — na przykład przesyłania lub korzystania z wielu innych protokołów — użyj cURL .