
Jak porównywać pliki binarne w systemie Linux
Opublikowany: 2022-08-20
Jak sprawdzić, czy dwa binaria Linuksa są takie same? Jeśli są to pliki wykonywalne, wszelkie różnice mogą oznaczać niepożądane lub złośliwe zachowanie. Oto najprostszy sposób sprawdzenia, czy się różnią.
Porównywanie plików binarnych
Linux jest bogaty w sposoby porównywania i analizowania plików tekstowych. Polecenie diff porówna dla Ciebie dwa pliki i podkreśli różnice. Może nawet zapewnić kilka linii po obu stronach zmian, aby zapewnić pewien kontekst wokół zmienionych linii. A polecenie colordiff dodaje kolor, aby wizualna analiza różnic była jeszcze łatwiejsza.
Deweloperzy i autorzy używają diff do podkreślenia różnic między różnymi wersjami plików kodu źródłowego programów lub szkiców tekstów. Jest to szybkie i łatwe, a do zobaczenia różnic między ciągami tekstu nie potrzebujesz żadnych umiejętności technicznych.
W świecie plików binarnych sprawy nie są takie proste. Pliki binarne nie składają się ze zwykłego tekstu. Składają się z wielu bajtów zawierających wartości liczbowe. Jeśli jest to plik skompresowany, taki jak archiwum TAR lub plik ZIP, te wartości reprezentują skompresowane pliki, które są przechowywane w pliku archiwum, wraz z tabelami symboli wymaganych do dekompresji i wyodrębniania plików.

Jeśli plik binarny jest plikiem wykonywalnym, wartości liczbowe bajtów pliku są interpretowane jako takie rzeczy, jak instrukcje kodu maszynowego dla procesora, metadane, etykiety lub zakodowane dane. Zmiany w pliku binarnym lub pliku biblioteki mogą prowadzić do różnic w zachowaniu, gdy plik binarny jest wykonywany lub jest używany przez inną aplikację.
Łatwo jest sfałszować datę i godzinę utworzenia lub modyfikacji pliku. Oznacza to, że mogą istnieć dwie wersje pliku, które mają tę samą nazwę, rozmiar pliku — jeśli zmiany zastąpią istniejącą zawartość bajt na bajt — i znaczniki daty. A jednak jeden z plików mógł zostać zmieniony.
Bezpieczne algorytmy skrótu
Bezpieczny algorytm mieszający to algorytm oparty na matematyce. Tworzy wartość 64-bitową, skanując wszystkie bajty w pliku i stosując do nich matematyczną transformację w celu wygenerowania wartości skrótu. Każdego dnia ten sam plik zawsze wygeneruje ten sam skrót. Nawet jednobajtowa różnica spowoduje radykalnie inny skrót.
Często zobaczysz skrót pliku wyświetlany na jego stronie pobierania. Po pobraniu pliku należy wygenerować skrót. Jeśli różni się od skrótu wyświetlanego na stronie, wiesz, że plik jest zagrożony. Albo został naruszony i zastąpiony oryginalnym plikiem — aby ludzie pobrali skażony plik — albo został uszkodzony podczas przesyłania.
Na naszym komputerze testowym mamy dwie kopie tego samego pliku, wspólną bibliotekę. Zmieniono nazwy plików, aby mogły znajdować się w tym samym katalogu. Teoretycznie te pliki powinny być takie same. W końcu mają być tą samą wersją biblioteki współdzielonej.
ls -l *.so

Pliki mają ten sam rozmiar, te same znaczniki daty i te same znaczniki czasu. Przypadkowemu obserwatorowi wydadzą się takie same. Użyjmy polecenia sha256sum i wygenerujmy skrót dla każdego pliku.
sha256sum plik_binarny1.so
sha256sum plik_binarny2.so
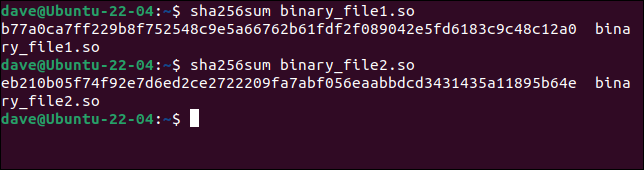
Skróty są zupełnie inne, co wyraźnie wskazuje na różnice między tymi dwoma plikami. Jeśli witryna pokazuje skrót oryginalnego pliku, możesz odrzucić plik, który nie pasuje.
Znajdowanie różnic
Jeśli chcesz przyjrzeć się zmianom, są na to również sposoby. Nie musisz być w stanie dekompilować pliku, ani rozumieć asemblera lub kodu maszynowego tylko po to, aby zobaczyć modyfikacje. Zrozumienie, co oznaczają te zmiany i jaki jest ich cel, wymagałoby oczywiście głębszej wiedzy technicznej. Ale sama wiedza o tym, jak istotne są zmiany, może wskazywać na to, co stało się z plikiem.
Jeśli użyjemy diff na dwóch plikach binarnych, otrzymamy odpowiedź, która będzie trochę rozczarowująca.
diff plik_binarny1.so plik_binarny2.so

Wiedzieliśmy już, że akta są inne. Spróbujmy cmp .
cmp plik_binarny1.so plik_binarny2.so

To mówi nam trochę więcej. Pierwszym bajtem, który różni się między tymi dwoma plikami, jest bajt numer 13451. Oznacza to, że bajt 13451 liczony od początku pliku binarnego jest inny w obu plikach binarnych. Więc 13451 to przesunięcie pierwszej różnicy, od początku pliku.
Przypadkiem w całym pliku będą bajty zawierające szesnastkową wartość 0x10. Jest to wartość, której Linux używa w plikach tekstowych jako znaku końca wiersza. Polecenie cmp napotkało 131 bajtów z tą wartością między początkiem pliku binarnego a lokalizacją pierwszej różnicy. Więc myśli, że jest w linii 132. To naprawdę nic nie znaczy w tym kontekście.
Jeśli dodamy opcję -l (pełny), zaczniemy uzyskiwać przydatne informacje.
cmp -l plik_binarny1.so plik_binarny2.so
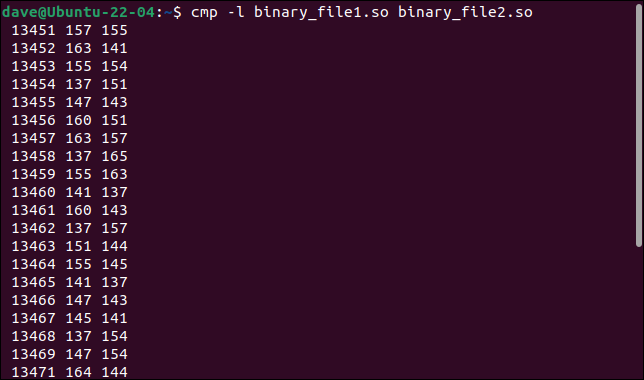

Wymienione są wszystkie różniące się bajty. Wyświetlany jest numer lub przesunięcie bajtu, wartość z pierwszego pliku i wartość z drugiego pliku, z jednym bajtem na wiersz wyjścia.
Wartości bajtów są wyświetlane ósemkowo, zamiast zwykłego formatu szesnastkowego używanego w plikach binarnych. Niemniej jednak nauczyliśmy się czegoś innego. Wszystkie zmienione bajty znajdują się w jednej ciągłej sekwencji. Ich przesunięcia są zwiększane o jeden na każdy bajt.
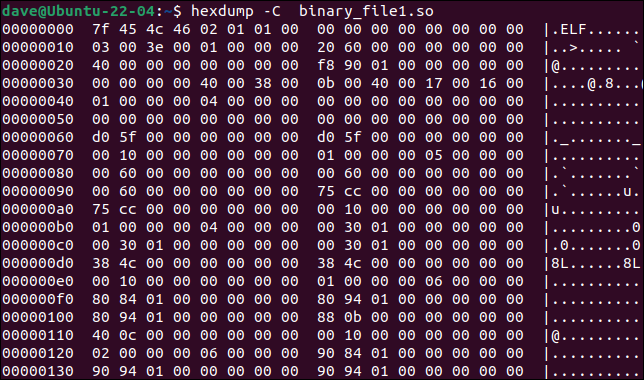
Narzędzie hexdump zrzuci plik binarny do okna terminala. Jeśli użyjemy opcji -C (canonical), dane wyjściowe wypiszą w każdym wierszu przesunięcie, wartości 16 bajtów przy tym przesunięciu i — jeśli takowa istnieje — reprezentację ASCII wartości bajtów.
hexdump -C plik_binarny1.so
Możemy użyć danych wyjściowych z hexdump jako danych wejściowych do diff , pozwalając diff działać tak, jakby odczytywał dwa pliki tekstowe.
diff <(zrzut_szesnastkowy plik_binarny1.so) <(zrzut_szesnastkowy plik_dwójkowy2.so)
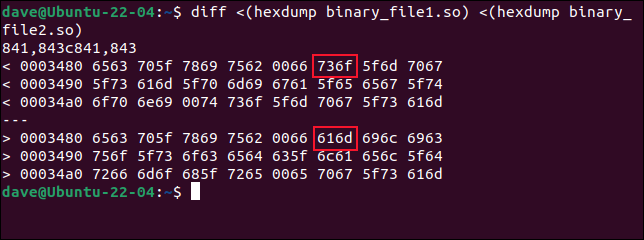
diff znajduje linie, które są różne i pokazuje szesnastkowe wartości bajtów z pierwszego pliku ponad wartościami z drugiego pliku. Przesunięcie pierwszego wiersza to 0x3480 lub 13440 dziesiętnie. Wcześniej cmp powiedział nam, że pierwsza zmiana nastąpiła w bajcie 13451, czyli 0x348B. To właściwie pasuje do tego, co tutaj widzimy.
Dane wyjściowe z diff są w dwubajtowych blokach. Pierwsza para bajtów to bajty 0 i 1 z przesunięcia 0x3480, drugi blok zawiera bajty 2 i 3 z przesunięcia. Blok 6 będzie zawierał bajty 0xA i 0xB lub 10 i 11 dziesiętnie. Są to bajty 13450 i 13451. Widzimy, że są to pierwsze bajty, które się różnią. Pierwsze pięć par bajtów jest takich samych w obu plikach.
Jednakże, ponieważ diff liczy od podstawy zero, to co cmp wywołuje 13451 będzie bajtem 13540 do diff . Aby sprawa była jeszcze bardziej zagmatwana, kolejność bajtów w każdym dwubajtowym bloku jest odwracana przez diff . Bajty są w rzeczywistości wymienione w tej kolejności: 1 i 0, 3 i 2, 5 i 4, 7 i 6 i tak dalej.
Polecenie jest również kosztowne obliczeniowo — dwa hexdumps i diff naraz — zwłaszcza jeśli porównywane pliki są duże.
Ale jeśli hexdump -C może wysłać wersję ASCII pliku binarnego do okna terminala, dlaczego nie przekierujemy wyjścia do plików tekstowych, a następnie nie porównamy tych dwóch plików tekstowych z diff ?
hexdump -C plik_binarny1.so > plik_binarny1.txt
hexdump -C plik_binarny2.so > plik_binarny2.txt
diff binarny1.txt binarny2.txt
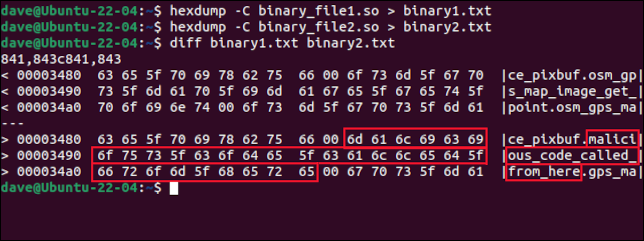
Różnica między tymi dwoma plikami jest pokazana w dwóch krótkich fragmentach. Obok nich jest reprezentacja ASCII. Dla każdej różnicy między plikami będzie para fragmentów. W tym przykładzie jest tylko jedna różnica.
To wszystko bardzo dobrze, ale czy nie byłoby wspaniale, gdyby było coś, co zrobiło to wszystko dla ciebie?
VBinDiff
Program VBinDiff można zainstalować ze zwykłych repozytoriów dla wszystkich głównych dystrybucji. Aby zainstalować go na Ubuntu, użyj tego polecenia:
sudo apt zainstaluj vbindiff

W Fedorze musisz wpisać:
sudo dnf zainstaluj vbindiff

Użytkownicy Manjaro muszą używać pacman .
sudo pacman -Sy vbindiff

Aby użyć programu, przekaż nazwę dwóch plików binarnych w wierszu poleceń.
vbindiff plik_binarny1.so plik_binarny2.so

Otworzy się aplikacja terminalowa, pokazując oba pliki w widoku przewijania.
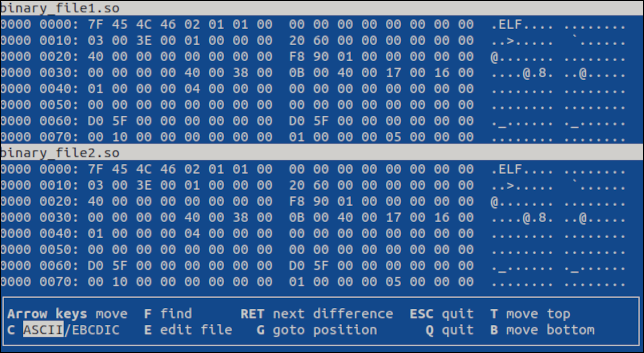
Do poruszania się po plikach można używać kółka myszy lub klawiszy „UpArrow”, „DownArrow”, „Home”, „End”, „PageUp” i „PageDown”. Oba pliki zostaną przewinięte.
Naciśnij klawisz „Enter”, aby przejść do pierwszej różnicy. Różnica jest podkreślona w obu plikach.
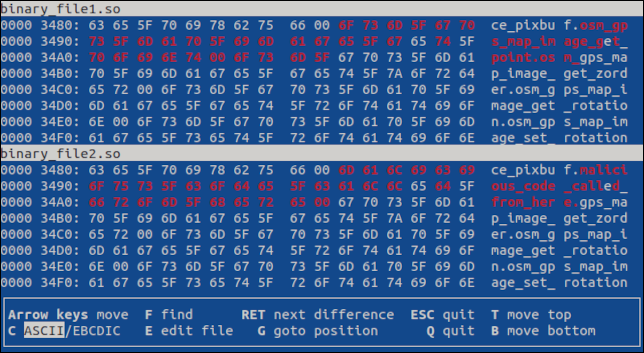
Gdyby było więcej różnic, naciśnięcie „Enter” wyświetli następną różnicę. Naciśnięcie „q” lub „Esc” spowoduje wyjście z programu.
Co za różnica?
Jeśli pracujesz na komputerze należącym do kogoś innego i nie możesz instalować żadnych pakietów, możesz użyć poleceń cmp , diff i hexdump . Jeśli chcesz przechwycić dane wyjściowe do dalszego przetwarzania, są to również narzędzia, których możesz użyć.
Ale jeśli masz pozwolenie na instalowanie pakietów, VBinDiff ułatwia i przyspiesza pracę. W rzeczywistości używanie VBinDiff z pojedynczym plikiem binarnym jest łatwym i wygodnym sposobem przeglądania plików binarnych, co jest miłym dodatkiem.
POWIĄZANE: Jak zajrzeć do plików binarnych z wiersza poleceń systemu Linux