
Linux에서 wc 명령을 사용하는 방법
게시 됨: 2022-07-23
파일의 줄, 단어 및 바이트 수를 계산하는 것은 유용하지만 Linux wc 명령의 진정한 유연성은 다른 명령과 함께 작업할 때 나옵니다. 한 번 보자.
wc 명령이란 무엇입니까?
wc 명령은 작은 응용 프로그램입니다. 핵심 Linux 유틸리티 중 하나이므로 설치할 필요가 없습니다. 이미 Linux 컴퓨터에 있을 것입니다.
아주 짧은 단어로 그것이 하는 일을 설명할 수 있습니다. 파일 또는 파일 선택의 행, 단어 및 바이트 수를 계산하고 결과를 터미널 창에 인쇄합니다. 또한 STDIN 스트림에서 입력을 받을 수 있습니다. 즉, 처리하려는 텍스트를 파이프로 연결할 수 있습니다. 이것은 wc 가 실제로 가치를 추가하기 시작하는 곳입니다.

이것은 "한 가지만 하고 잘 하라"는 Linux 만트라의 좋은 예입니다. 파이프 입력을 허용하기 때문에 다중 명령 주문에 사용할 수 있습니다. 앞으로 살펴보겠지만 이 작은 독립 실행형 유틸리티는 실제로 훌륭한 팀 플레이어입니다.
내가 wc 를 사용하는 한 가지 방법은 내가 요리하고 있는 복잡한 명령이나 별칭에서 자리 표시자로 사용하는 것입니다. 완성된 명령이 파일을 파괴하고 삭제할 가능성이 있는 경우, 저는 종종 wc 를 실제 위험한 명령의 대명사로 사용합니다.
그렇게 하면 명령을 개발하는 동안 각 파일이 예상대로 처리되고 있다는 시각적 피드백을 받습니다. 구문과 씨름하는 동안 나쁜 일이 발생할 가능성은 없습니다.
wc 은 간단하지만 알아야 할 몇 가지 작은 단점이 있습니다.
화장실 시작하기
wc 를 사용하는 가장 간단한 방법은 명령줄에 텍스트 파일의 이름을 전달하는 것입니다.
화장실 lorem.txt

이로 인해 wc 는 파일을 스캔하고 행, 단어 및 바이트 수를 세어 터미널 창에 기록합니다.
단어는 공백으로 묶인 모든 것으로 간주됩니다. 실제 언어에서 나온 단어인지 아닌지는 중요하지 않습니다. 파일에 "frd g lkj"만 포함되어 있어도 여전히 세 단어로 계산됩니다.
줄은 캐리지 리턴이나 파일 끝으로 끝나는 일련의 문자입니다. 편집기나 터미널 창에서 줄이 줄 바꿈되는지 여부는 중요하지 않습니다. wc 가 캐리지 리턴이나 파일의 끝을 만나기 전까지는 여전히 같은 줄입니다.
첫 번째 예에서는 전체 파일에서 한 줄을 찾았습니다. 다음은 "lorem.txt" 파일의 내용입니다.
고양이 lorem.txt
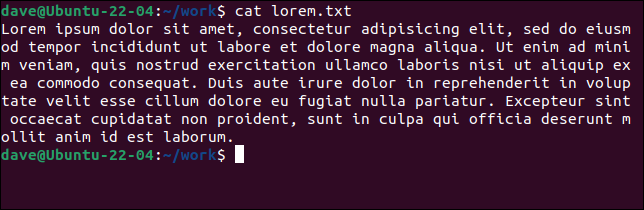
캐리지 리턴이 없기 때문에 이 모든 것이 한 줄로 계산됩니다. 이것을 다른 파일인 "lorem2.txt"와 wc 가 해석하는 방법을 비교하십시오.
화장실 lorem2.txt
고양이 lorem2.txt
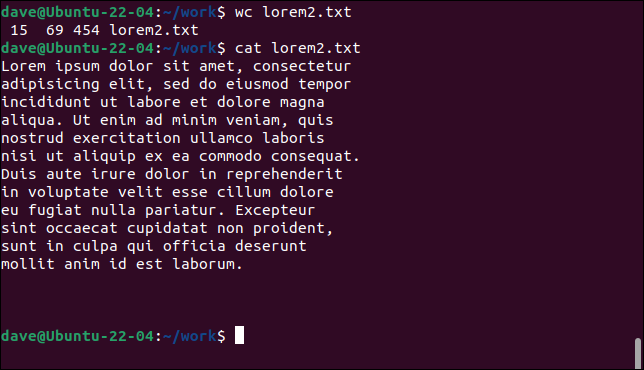
이번에는 특정 지점에서 새 줄을 시작하기 위해 텍스트에 캐리지 리턴이 삽입되었기 때문에 wc 는 15줄을 계산합니다. 그러나 텍스트가 있는 줄을 세어 보면 12개만 있는 것을 알 수 있습니다.
나머지 세 줄은 파일 끝에 있는 빈 줄입니다. 여기에는 캐리지 리턴만 포함됩니다. 이 줄에 텍스트가 없더라도 새 줄이 시작되었으므로 wc 는 이러한 줄로 계산합니다.
우리는 원하는 만큼 많은 파일을 wc 에 전달할 수 있습니다.
화장실 lorem.txt lorem2.txt
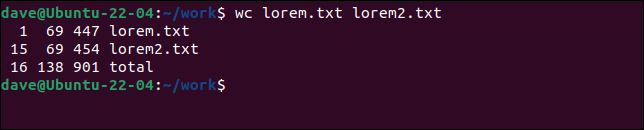
각 개별 파일에 대한 통계와 모든 파일에 대한 합계를 얻습니다.
명시적으로 명명된 파일 대신 일치하는 파일을 선택할 수 있도록 와일드카드를 사용할 수도 있습니다.
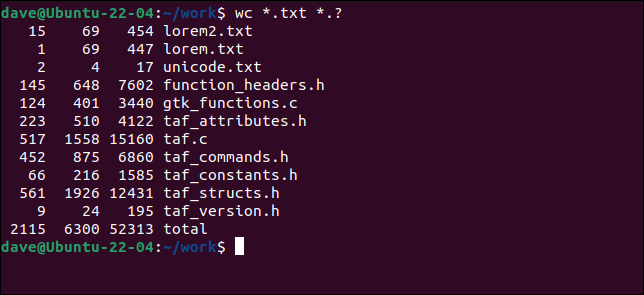
화장실 *.txt *.?
명령줄 옵션
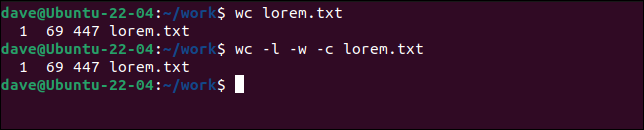
기본적으로 wc 는 각 파일의 행, 단어 및 바이트를 표시합니다. -l (줄) -w (단어) 및 -c (바이트) 옵션을 사용하는 것과 같습니다.
화장실 lorem.txt
화장실 -l -w -c lorem.txt
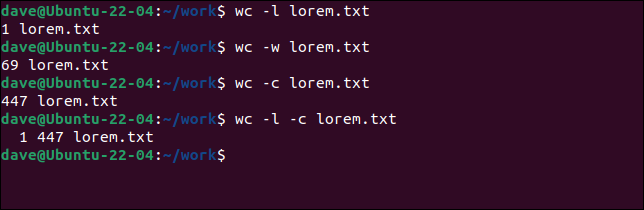
보고 싶은 그림의 조합을 지정할 수 있습니다.
화장실 -l lorem.txt 화장실 -w lorem.txt 화장실 -c lorem.txt 화장실 -l -c lorem.txt
-c (bytes) 옵션에 의해 생성된 마지막 숫자에 특별한 주의를 기울여야 합니다. 많은 사람들이 이것을 문자 수를 세는 것으로 착각합니다. 실제로 바이트 수를 계산합니다. 문자 수와 바이트 수는 동일할 수 있습니다. 하지만 항상 그런 것은 아닙니다.
"unicode.txt"라는 파일의 내용을 살펴보겠습니다.
고양이 unicode.txt

세 단어와 비 라틴 알파벳 문자가 있습니다. wc 가 기본 설정인 bytes 로 파일을 처리하도록 하고 다시 수행하지만 -m (characters) 옵션을 사용하여 문자 를 요청합니다.
화장실 유니코드.txt
화장실 -l -w -m 유니코드.txt
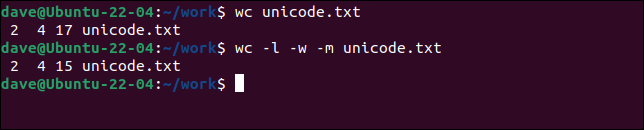
문자보다 바이트가 더 많습니다.
파일의 16진 덤프를 살펴보고 무슨 일이 일어나는지 봅시다. hexdump 명령의 -C (표준) 옵션은 파일의 바이트를 16행으로 표시하고 해당 일반 ASCII(있는 경우)가 행 끝에 표시됩니다. 해당 ASCII 문자가 없으면 마침표 " . "가 대신 표시됩니다.

hexdump -C unicode.txt
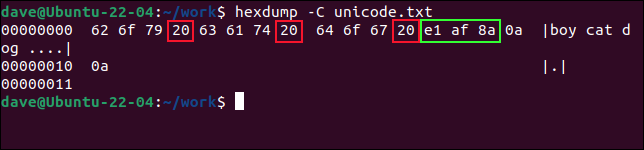
ASCII에서 0x20 의 16진수 값은 공백 문자를 나타냅니다. 왼쪽에서 세 개의 값을 계산하면 다음 값이 공백 문자임을 알 수 있습니다. 따라서 처음 세 값 0x62 , 0x6f 및 0x79 는 "boy"의 문자를 나타냅니다.
0x20 을 0x63 , 0x61 및 0x74 의 세 가지 16진수 값의 또 다른 집합이 표시됩니다. 이 철자는 "고양이"입니다. 다음 공백 문자 위로 이동하면 "dog"의 문자에 대한 세 가지 값이 더 표시됩니다. 0x64 , 0x5f 및 0x67 입니다.
"dog"이라는 단어 바로 뒤에 공백 문자 0x20 과 5개의 16진수 값이 더 있습니다. 마지막 두 개는 캐리지 리턴, 0x0a 입니다.
다른 세 바이트는 비라틴 문자를 나타내며 녹색으로 표시됩니다. 유니코드 문자이며 인코딩하는 데 3바이트가 필요합니다. 0xe1 , 0xaf 및 0x8a 입니다.
따라서 무엇을 계산하고 있는지 확인하고 바이트와 문자가 같을 필요는 없습니다. 일반적으로 바이트 수를 계산하는 것은 파일 내부 에 실제로 무엇이 있는지 알려 주기 때문에 더 유용합니다. 문자로 계산하면 파일의 내용이 나타내는 항목의 수를 알 수 있습니다.
관련: ANSI 및 유니코드와 같은 문자 인코딩은 무엇이며 어떻게 다릅니까?
파일에서 파일 이름 가져오기
wc 에 파일 이름을 제공하는 또 다른 방법이 있습니다. 파일 이름을 파일에 넣고 해당 파일의 이름을 wc 에 전달할 수 있습니다. 파일을 열고 파일 이름을 추출한 다음 명령줄에서 전달된 것처럼 처리합니다. 이를 통해 재사용을 위해 임의의 파일 이름 컬렉션을 저장할 수 있습니다.
하지만 문제가 있고 큰 문제입니다. 파일 이름은 캐리지 리턴으로 끝나는 것이 아니라 null 로 끝나야 합니다. 즉, 각 파일 이름 뒤에 일반적인 캐리지 리턴 바이트 0x0a 대신 null 바이트 0x00 이 있어야 합니다.
이 형식으로 편집기를 열고 파일을 만들 수 없습니다. 일반적으로 이와 같은 파일은 다른 프로그램에서 생성됩니다. 그러나 이러한 파일이 있는 경우 이 방법을 사용합니다.
여기에 파일 이름이 포함된 파일이 있습니다. less 에서 열면 null 바이트를 나타내기 위해 less 를 사용하는 이상한 " ^@ " 문자가 표시됩니다.
적은 소스 파일 목록.txt

wc 와 함께 파일을 사용하려면 --files0-from (입력 읽기) 옵션을 사용하고 파일 이름이 포함된 파일 이름을 전달해야 합니다.
화장실 ---files0-from=source-files-list.txt
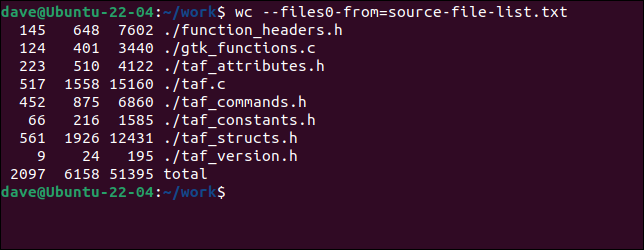
파일은 명령줄에 제공된 것처럼 정확하게 처리됩니다.
화장실에 배관 입력
wc 에 입력을 보내는 훨씬 더 일반적이고 유연하며 생산적인 방법은 다른 명령의 출력을 wc 로 파이프하는 것입니다. echo 명령으로 이것을 증명할 수 있습니다.
echo "나를 위해 이것을 세어라" | 화장실
echo - "나를 위해\n계산" | 화장실
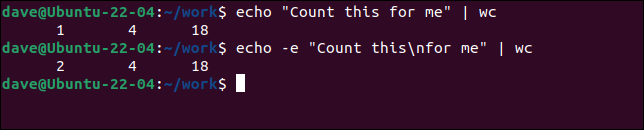
두 번째 echo 명령은 -e (이스케이프된 문자) 옵션을 사용하여 " \n " 개행 형식 코드와 같은 이스케이프 시퀀스를 허용합니다. 이것은 새 줄을 주입하여 wc 가 입력을 두 줄로 보게 합니다.
다음은 입력을 서로 공급하는 일련의 명령입니다.
찾기 ./* -유형 f | 레브 | 컷 -d'.' -f1 | 레브 | 정렬 | 유니크
- find 는 현재 디렉토리에서 시작하여 재귀적으로 파일(
type -f)을 찾습니다.rev는 파일 이름을 뒤집습니다. - cut 은 필드 구분 기호를 마침표로 정의하여 첫 번째 필드(
-f1)를 추출합니다." 그리고 반전된 파일 이름의 "앞"에서 찾은 첫 번째 마침표까지 읽습니다. 이제 파일 확장자를 추출했습니다. - rev 는 추출된 첫 번째 필드를 반전시킵니다.
- sort 는 알파벳 오름차순으로 정렬합니다.
- uniq 는 터미널 창에 고유한 항목을 나열합니다.
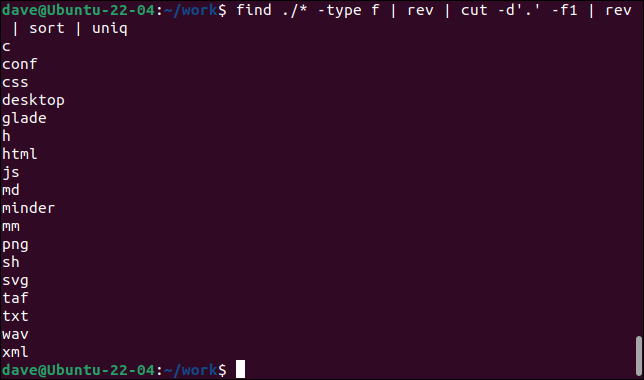
이 명령은 현재 디렉토리와 모든 하위 디렉토리에 있는 고유한 파일 확장자를 모두 나열합니다.
uniq 명령에 -c (count) 옵션을 추가하면 각 확장 유형의 발생 횟수를 계산합니다. 그러나 얼마나 많은 다른 고유한 파일 확장자가 있는지 알고 싶다면 줄의 마지막 명령으로 wc 를 삭제하고 -l (줄) 옵션을 사용할 수 있습니다.
찾기 ./* -유형 f | 레브 | 컷 -d'.' -f1 | 레브 | 정렬 | 유니크 | 화장실 -l

관련: Linux cut 명령을 사용하는 방법
그리고 마지막으로
여기 wc 가 당신을 위해 할 수 있는 마지막 트릭이 있습니다. 파일에서 가장 긴 줄의 길이를 알려줍니다. 슬프게도, 어떤 라인인지 알려주지 않습니다. 그것은 단지 당신에게 길이를 제공합니다.
화장실 -L taf.c

그러나 탭은 8개의 공백으로 계산됩니다. 내 편집기에서 보면 해당 줄의 시작 부분에 세 개의 공백 탭이 있습니다. 실제 길이는 124자입니다. 따라서 보고된 수치는 인위적으로 확장된 것입니다.
나는 이 기능을 약간의 소금으로 처리할 것입니다. 그리고 사용하지 말라는 뜻입니다. 그 출력은 오해의 소지가 있습니다.
특이한 점에도 불구하고 wc 는 파일에 있는 단어뿐만 아니라 모든 종류의 값을 계산해야 할 때 파이프된 명령을 사용할 수 있는 훌륭한 도구입니다.
관련: 알아야 할 37가지 중요한 Linux 명령