
검색 엔진은 어떻게 작동하고 삶을 더 쉽게 만들어 줍니까?
게시 됨: 2015-11-06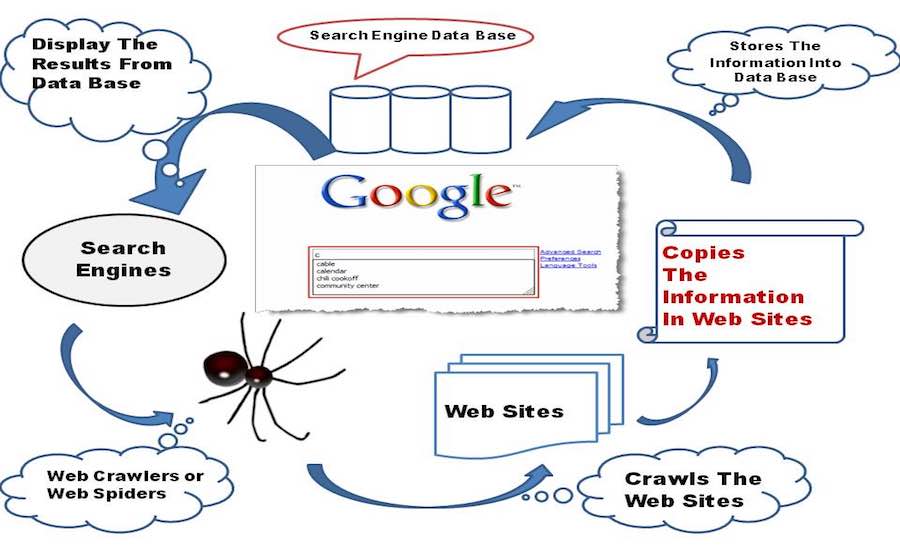 Short Bytes: 검색 엔진은 적절한 데이터를 수집하기 위해 웹 크롤링 및 웹 인덱싱, 일부 뚱뚱한 공식 및 지능형 알고리즘을 사용하여 검색 쿼리 입력을 기반으로 관련 웹 페이지 결과를 표시할 수 있는 소프트웨어입니다.
Short Bytes: 검색 엔진은 적절한 데이터를 수집하기 위해 웹 크롤링 및 웹 인덱싱, 일부 뚱뚱한 공식 및 지능형 알고리즘을 사용하여 검색 쿼리 입력을 기반으로 관련 웹 페이지 결과를 표시할 수 있는 소프트웨어입니다.
Google이 눈 깜짝할 사이에 최상의 결과를 제공하는 방법은 무엇입니까? 사실, 구글, 빙이 있기 전까지는 중요하지 않습니다. Google, Bing 또는 Yahoo가 없었다면 시나리오가 매우 달라졌을 것입니다. 검색 엔진의 세계로 뛰어들어 검색 엔진이 어떻게 작동하는지 살펴보겠습니다.
역사를 엿보다
검색 엔진 동화는 1990년대에 Tim Berners-Lee가 온라인에 연결된 모든 새로운 웹 서버를 CERN 웹 서버가 관리하는 목록에 등록했을 때 시작되었습니다. 93년 9월까지 인터넷에는 검색 엔진이 없었고 파일 이름 데이터베이스를 유지할 수 있는 몇 가지 도구만 있었습니다. Archie, Veronica, Jughead가 이 카테고리의 첫 번째 참가자였습니다.
Geneva 대학의 Oscar Nierstrasz는 W3Catalog라는 이름의 최초 검색 엔진으로 인정받았습니다. 그는 진지한 Perl 스크립트를 작성했고 마침내 1993년 9월 3일에 세계 최초의 검색 엔진을 내놓았습니다. 게다가 1993년에는 다른 많은 검색 엔진이 등장했습니다. Jonathon Fletcher, AliWeb, WWW Worm 등의 JumpStation 야후! 1995년 웹디렉토리로 출시되었으나 2000년부터 잉크토미의 엔진검색을 이용하기 시작하여 2009년 마이크로소프트의 빙으로 옮겨갔다.
이제 검색 엔진이라는 용어의 주요 동의어인 이름에 대해 이야기하면 Google Search는 1995년 3월에 첫 발자국을 남긴 두 명의 Stanford 졸업생 Larry Page와 Sergy Brin의 연구 프로젝트였습니다. Google의 작업은 처음에 영감을 받았습니다. World Wide Web에서 해당 페이지의 중요성을 측정하기 위해 웹 페이지에서 시작된 백링크 수를 기반으로 계산을 수행한 Page의 백 링크 방법에 의해. 페이지는 “내가 받은 최고의 조언”이라고 회상하면서 그의 상사인 테리 위노그라드가 그의 아이디어를 지원한 방법을 회상했습니다. 그리고 그 이후로 Google은 결코 뒤돌아보지 않았습니다.
모든 것은 크롤링으로 시작됩니다
초기 단계의 아기 검색 엔진은 작은 손과 무릎으로 World Wide Web 탐색을 시작하고 웹 페이지에서 찾은 다른 모든 링크를 탐색하고 데이터베이스에 저장합니다.
이제 이면의 기술적인 생각에 집중해 보겠습니다. 검색 엔진은 기본적으로 웹 페이지에 있는 모든 하이퍼링크를 열고 모든 링크에서 텍스트 및 메타데이터 데이터베이스를 생성하는 작업을 할당받은 인터넷 봇인 Web Crawler 소프트웨어를 통합합니다. . Seeds라고 하는 방문할 초기 링크 세트로 시작합니다. 해당 링크를 방문하는 즉시 크롤링 프론티어라고 하는 방문할 URL의 기존 목록에 새 링크를 추가합니다.
Crawler는 링크를 통과할 때 해당 웹 페이지에서 정보를 다운로드하여 나중에 스냅샷 형태로 볼 수 있습니다. 전체 웹 페이지를 다운로드하려면 엄청난 양의 데이터가 필요하고 적어도 2000년에는 적은 비용으로 제공되기 때문입니다. 인도 같은 나라. 그리고 만약 구글이 인도에서 설립된다면 그들의 모든 돈은 인터넷 요금을 지불하는 데 사용될 것이라고 장담할 수 있습니다. 바라건대, 그것은 현재로서는 걱정할 주제가 아닙니다.
웹 크롤러는 일부 정책을 기반으로 웹 페이지를 탐색합니다.
선택 정책: 크롤러는 다운로드해야 할 페이지와 다운로드하지 말아야 할 페이지를 결정합니다. 선택 정책은 중요하지 않은 데이터보다 웹 페이지에서 가장 관련성이 높은 콘텐츠를 다운로드하는 데 중점을 둡니다.
재방문 정책: Crawler는 웹 페이지를 다시 열고 데이터베이스의 변경 사항을 편집해야 하는 시간을 예약합니다. 인터넷의 동적 특성으로 인해 Crawler가 최신 버전의 업데이트를 유지하기가 매우 어렵기 때문입니다. 웹페이지.
병렬화 정책: 크롤러는 분산 크롤링으로 알려진 링크를 탐색하기 위해 한 번에 여러 프로세스를 사용하지만 때로는 다른 프로세스가 동일한 웹 페이지를 다운로드할 가능성이 있으므로 크롤러는 모든 프로세스 간의 조정을 유지하여 이중성.
정중함 정책: 크롤러가 웹 사이트를 탐색할 때 동시에 웹 페이지를 다운로드하므로 웹 사이트를 호스팅하는 웹 서버의 로드가 증가합니다. 따라서 크롤러가 웹 서버에서 일부 데이터를 다운로드한 후 몇 초 동안 기다려야 하는 "Crawl-Delay"라는 용어가 구현되며 정중함 정책이 적용됩니다.
더 읽어보기: Python에서 기본 웹 크롤러를 빌드하는 방법
표준 웹 크롤러의 고급 아키텍처:
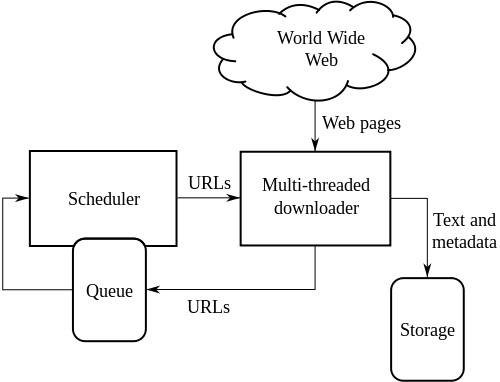
위의 그림은 웹 크롤러의 작동 방식을 보여줍니다. 링크의 초기 목록을 연 다음 해당 링크 내부의 링크 등을 엽니다.
Wikipedia에서는 컴퓨터 과학 연구원인 Vladislav Shkapenyuk와 Torsten Suel이 다음과 같이 언급했습니다.
짧은 시간 동안 초당 몇 페이지를 다운로드하는 느린 크롤러를 구축하는 것은 상당히 쉽지만, 몇 주에 걸쳐 수억 페이지를 다운로드할 수 있는 고성능 시스템을 구축하는 것은 시스템 설계에 여러 가지 문제를 제시합니다. I/O 및 네트워크 효율성, 견고성 및 관리 용이성.
크롤링 인덱싱
아기 검색 엔진이 인터넷 전체를 크롤링한 후 방해가 되는 모든 웹 페이지의 색인을 생성합니다. 인덱스를 갖는 것이 큰 크기의 문서 더미에서 검색 쿼리를 찾는 데 시간을 낭비하는 것보다 훨씬 낫습니다. 시간과 리소스를 모두 절약할 수 있습니다.
검색 엔진을 위한 효율적인 인덱싱 시스템을 만드는 데 기여하는 많은 요소가 있습니다. 인덱서가 사용하는 저장 기술, 인덱스의 크기, 검색된 키워드가 포함된 문서를 빠르게 찾는 기능 등은 인덱스의 효율성과 신뢰성을 결정하는 요소입니다.
성공적인 웹 인덱스를 만드는 데 있어 가장 큰 장애물 중 하나는 두 프로세스 간의 충돌입니다. 한 프로세스가 문서를 검색하려고 하고 동시에 다른 프로세스가 색인에 문서를 추가하려고 하면 두 프로세스 간에 일종의 충돌이 발생합니다. 더 많은 데이터를 처리하기 위해 검색 엔진에서 분산 컴퓨팅을 구현하면 문제가 더욱 악화됩니다.
인덱스 유형
앞으로: 이러한 유형의 인덱스에서는 문서에 있는 모든 키워드가 목록에 저장됩니다. 정방향 인덱스는 비동기식 인덱서가 서로 협업할 수 있도록 하므로 인덱싱 시작 단계에서 쉽게 만들 수 있습니다.
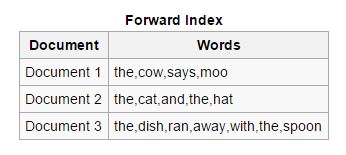

역방향: 정방향 인덱스가 정렬되어 역방향 인덱스로 변환됩니다. 여기서 특정 키워드를 포함하는 각 문서는 해당 키워드를 포함하는 다른 문서와 함께 배치됩니다. 역 인덱스는 정방향 인덱스의 경우가 아닌 주어진 검색 쿼리에 대한 관련 문서를 찾는 프로세스를 용이하게 합니다.
또한 읽기: DNS(도메인 이름 시스템)란 무엇이며 어떻게 작동합니까?
문서 파싱
토큰화라고도 하며, 나중에 인덱스에 삽입할 수 있도록 키워드(토큰이라고 함), 이미지 및 기타 미디어와 같은 문서 구성 요소를 분해하는 것을 말합니다. 이 방법은 기본적으로 모국어를 이해하고 사용자가 검색할 수 있는 키워드를 예측하는 데 중점을 두고 있으며 이는 효과적인 웹 인덱싱 시스템을 만들기 위한 기반이 됩니다.
주요 과제는 추출할 키워드의 단어 경계를 찾는 것입니다. 중국어 및 일본어와 같은 언어는 일반적으로 언어 스크립트에 공백이 없음을 알 수 있습니다. 일부 언어는 지리적 변화에 따라 약간 또는 상당히 달라지기 시작하기 때문에 언어가 지닌 모호성을 이해하는 것도 문제입니다. 또한 사용된 언어를 명확하게 언급하지 않는 일부 웹 페이지의 비효율성도 문제이며 인덱서의 작업량을 증가시킵니다.
검색 엔진은 다양한 파일 형식을 인식하고 성공적으로 데이터를 추출할 수 있는 기능을 가지고 있으며 이러한 경우 각별한 주의가 필요합니다.
메타 태그는 인덱스를 매우 빠르게 생성하는 데에도 매우 유용하며 웹 인덱서의 노력을 줄이고 전체 문서를 완전히 구문 분석할 필요성을 줄여줍니다. 이 기사의 하단에 첨부된 메타 태그를 찾을 수 있습니다.
색인 검색
이제 아기 검색 엔진은 더 이상 아기가 아닙니다. 그는 기어가는 방법과 물건을 빠르고 효율적으로 잡는 방법, 물건을 체계적으로 정리하는 방법을 배웠습니다. 그의 친구가 그에게 그의 마련에서 무엇인가를 찾아달라고 요청한다고 가정해 봅시다. 그는 무엇을 할 것입니까? 공식적으로 파생된 것은 아니지만 사용 중인 검색어에는 4가지 유형이 있지만 시간이 지남에 따라 진화 했으며 사용자가 수행한 실제 검색어 측면에서 유효한 것으로 확인되었습니다.
탐색: 이 용어는 사용자가 인터넷에 존재하는 특정 웹페이지 또는 웹사이트로 이동하기를 원하는 쿼리에 사용됩니다. 예를 들어 Google에서 fossBytes 를 검색하면 탐색 쿼리가 시작됩니다.
정보: 이 유형의 쿼리는 수천 개의 결과를 가지고 있으며 사용자의 지식을 향상시키는 일반적인 주제를 다룹니다. 예를 들어, Steve Jobs를 검색하면 Steve Jobs와 관련된 모든 링크가 표시됩니다.
트랜잭션: 특정 작업을 수행하려는 사용자의 의도에 초점을 맞춘 쿼리는 미리 정의된 명령 집합을 포함할 수 있습니다. 예를 들어, 분실/도난 노트북을 찾는 방법은 무엇입니까?
연결성: 이러한 유형의 쿼리는 자주 사용되지 않으며 웹 사이트에서 생성된 인덱스가 어떻게 연결되어 있는지에 중점을 둡니다. 예를 들어 Wikipedia에 몇 페이지가 있습니까?
Google과 Bing은 쿼리와 가장 관련성이 높은 결과를 결정할 수 있는 몇 가지 중요한 알고리즘을 만들었습니다. Google은 콘텐츠 품질, 새롭거나 오래된 것, 웹페이지의 안전성 등과 같은 200가지 이상의 요소를 기반으로 검색 결과를 계산한다고 주장합니다. 그들은 검색 연구소에 세계에서 가장 뛰어난 사람을 임명하여 어려운 계산을 하고 놀라운 공식을 다루지만 검색을 보다 간단하고 빠르게 만들어 줍니다.
기타 주목할만한 기능*
이미지 검색: 유명한 이미지 검색 도구 뒤에 숨겨진 Google의 영감을 알게 되면 놀랄 것입니다. J.Lo, 맞아요, 2000년 그래미 시상식에서 J.Lo와 그녀의 초록색 Versace(ver-sah-chay) 가운이 사람들이 구글링하느라 바빴을 때 Google이 이미지 검색을 시작한 진짜 이유였습니다. 그녀의.
Eric Schmidt는 2015년 1월 19일에 출판된 "The Tinkerer's Apprentice"라는 제목의 글에서 말했습니다.
음성 검색: Google은 많은 노력 끝에 검색 엔진에 음성 검색을 처음 도입했으며 이후 다른 검색 엔진에서도 이를 구현했습니다.
스팸 방지: 검색 엔진 은 스팸 공격으로부터 사용자를 보호할 수 있도록 몇 가지 심각한 알고리즘을 배포합니다. 스팸은 기본적으로 광고나 바이러스 전송을 위해 인터넷 전체에 퍼진 메시지 또는 파일입니다. 이 문제에서 Google 직원은 웹사이트가 인터넷에 스팸 메시지를 퍼뜨릴 책임이 있음을 수동으로 알립니다.
위치 최적화: 이제 검색 엔진이 사용자의 위치를 기반으로 결과를 표시할 수 있습니다. 검색하면 벵갈루루의 날씨는 어떻습니까? 날씨 통계는 벵갈루루를 기준으로 합니다.
당신을 더 잘 이해함: 최신 검색 엔진은 사용자가 입력한 키워드를 찾는 것보다 사용자 쿼리의 의미를 이해할 수 있습니다.
자동 완성 : 이전 검색 및 다른 사용자의 검색을 기반으로 입력할 때 검색어를 예측하는 기능입니다.
지식 정보: Google 검색에서 제공하는 이 기능은 실제 사람, 장소 및 이벤트를 기반으로 검색 결과를 제공하는 기능을 보여줍니다.
자녀 보호: 검색 엔진을 사용하면 작은 종류의 부모가 자녀가 인터넷에서 무엇을 했는지 제어할 수 있습니다.
* 이 강력한 검색 엔진이 제공하는 방대한 기능 목록을 다루기는 어렵습니다.
감기
검색 엔진은 우리의 삶을 더 단순하게 만드는 데 기여했으며 인터넷의 모든 정보를 활용하기 위해 해온 노력은 값을 매길 수 없습니다. 그러나 이 탐색은 공개 플랫폼에서 우리의 개인 공간을 전시하게 했으며, 우리가 우리의 행동을 회고하기에 너무 늦지 않는 한 우리가 지금까지 걸어온 길에 대해 당황해야 할 때가 되었습니다. 그리고 우리의 삶은 부끄러움의 비엔날레일 뿐입니다. 검색 엔진이 이제 디지털 분할 성격의 중요한 부분이라는 사실을 부인할 수 없습니다. 우리는 우리에게 주어진 기술을 활용하기만 하면 되며, 우리 자신의 악행의 사슬에 우리를 노예로 만들지 않아야 합니다.
좋아, 더 이상 감정적인 대화는 하지 말고 이제 십대가 되어 당신을 훨씬 더 잘 이해하는 아기 검색 엔진의 귀여움과 재능에 감탄하십시오. Google은 우리를 위해 모든 것을 검색하기 위해 존재했으며, 우리 중 많은 사람들에게 인터넷은 Google 검색을 사용하는 동안 얻은 좋은 경험을 소중히 여겨야 합니다. 오! Bing을 언급하는 것을 잊었습니다. 당신도 대단합니다. 경계를 늦추지 않고 안전을 유지하고 Google에서 확인하세요.
이 비디오를 시청하고 검색 엔진에 대해 자세히 알아보십시오.
Google 검색에서 I'm Feeling Lucky 버튼 을 클릭한 적이 있습니까? 파일을 열고 아래 댓글 섹션에서 어떤 기념일 로고가 가장 마음에 들었는지 알려주세요.