
Bash에서 CSV 데이터를 구문 분석하는 방법
게시 됨: 2022-09-16
CSV(쉼표로 구분된 값) 파일은 내보낸 데이터의 가장 일반적인 형식 중 하나입니다. Linux에서는 Bash 명령을 사용하여 CSV 파일을 읽을 수 있습니다. 그러나 그것은 매우 빠르게 매우 복잡해질 수 있습니다. 우리가 도움이 될 것입니다.
CSV 파일이란?
쉼표로 구분된 값 파일은 표 형식의 데이터를 포함하는 텍스트 파일입니다. CSV는 구분된 데이터 유형입니다. 이름에서 알 수 있듯이 쉼표 " , "는 데이터 또는 값 의 각 필드를 인접 필드와 구분하는 데 사용됩니다.
CSV는 어디에나 있습니다. 응용 프로그램에 가져오기 및 내보내기 기능이 있는 경우 거의 항상 CSV를 지원합니다. CSV 파일은 사람이 읽을 수 있습니다. 적은 비용으로 내부를 보고, 모든 텍스트 편집기에서 열고, 프로그램에서 프로그램으로 이동할 수 있습니다. 예를 들어 SQLite 데이터베이스에서 데이터를 내보내 LibreOffice Calc에서 열 수 있습니다.
그러나 CSV도 복잡해질 수 있습니다. 데이터 필드에 쉼표를 사용하시겠습니까? 해당 필드에는 따옴표 " " "가 있어야 합니다. 필드에 따옴표를 포함하려면 각 따옴표를 두 번 입력해야 합니다.
물론 작성한 프로그램이나 스크립트에서 생성된 CSV로 작업하는 경우 CSV 형식이 간단하고 직관적일 가능성이 높습니다. Linux가 Linux인 더 복잡한 CSV 형식으로 작업해야 하는 경우에도 사용할 수 있는 솔루션이 있습니다.
일부 샘플 데이터
Online Data Generator와 같은 사이트를 사용하여 일부 샘플 CSV 데이터를 쉽게 생성할 수 있습니다. 원하는 필드를 정의하고 원하는 데이터 행 수를 선택할 수 있습니다. 데이터는 실제 더미 값을 사용하여 생성되고 컴퓨터에 다운로드됩니다.
50행의 더미 직원 정보가 포함된 파일을 만들었습니다.
- id : 단순하고 고유한 정수 값입니다.
- firstname : 사람의 이름입니다.
- lastname : 사람의 성.
- job-title : 그 사람의 직위.
- email-address : 그 사람의 이메일 주소.
- branch : 근무하는 회사의 지점입니다.
- state : 브랜치가 위치한 state.
일부 CSV 파일에는 필드 이름을 나열하는 헤더 행이 있습니다. 샘플 파일에는 하나가 있습니다. 파일 상단은 다음과 같습니다.
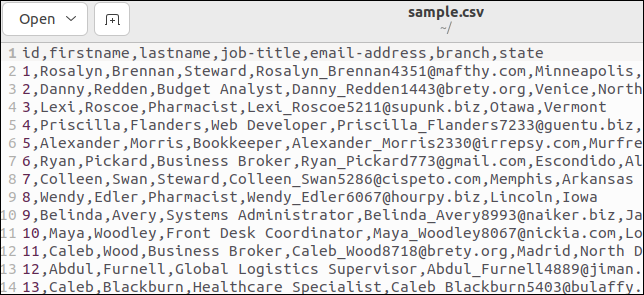
첫 번째 줄은 필드 이름을 쉼표로 구분된 값으로 유지합니다.
CSV 파일 형식의 데이터 구문 분석
CSV 파일을 읽고 각 레코드에서 필드를 추출하는 스크립트를 작성해 보겠습니다. 이 스크립트를 편집기에 복사하고 "field.sh"라는 파일에 저장합니다.
#! /bin/bash IFS="," read -r id 이름 성 직위 이메일 분기 상태 하다 echo "레코드 ID: $id" echo "이름: $이름" echo " 성: $lastname" echo "직위: $jobtitle" echo "이메일 추가: $email" echo " 브랜치: $branch" echo " 상태: $state" 에코 "" 완료 < <(꼬리 -n +2 sample.csv)
우리의 작은 스크립트에 꽤 많은 것이 담겨 있습니다. 분해해 봅시다.

우리는 while 루프를 사용하고 있습니다. while 루프 조건 이 true로 확인되는 한 while 루프의 본문이 실행됩니다. 루프의 본체는 매우 간단합니다. echo 문 모음은 일부 변수의 값을 터미널 창에 인쇄하는 데 사용됩니다.
while 루프 조건은 루프 본문보다 더 흥미롭습니다. IFS="," 문과 함께 쉼표를 내부 필드 구분 기호로 사용하도록 지정합니다. IFS는 환경 변수입니다. read 명령은 텍스트 시퀀스를 구문 분석할 때 해당 값을 참조합니다.
데이터에 있을 수 있는 모든 백슬래시를 무시하기 위해 read 명령의 -r (백슬래시 유지) 옵션을 사용하고 있습니다. 그들은 일반 문자로 취급됩니다.
read 명령이 구문 분석하는 텍스트는 CSV 필드의 이름을 따서 명명된 변수 세트에 저장됩니다. field1, field2, ... field7 이라는 이름을 쉽게 지정할 수 있지만 의미 있는 이름은 삶을 더 쉽게 만듭니다.
데이터는 tail 명령의 출력으로 얻습니다. tail 를 사용하는 이유는 CSV 파일의 헤더 행을 건너뛸 수 있는 간단한 방법을 제공하기 때문입니다. -n +2 (줄 번호) 옵션은 tail 에게 두 번째 줄에서 읽기를 시작하도록 지시합니다.
<(...) 구문을 프로세스 대체라고 합니다. 이것은 Bash가 프로세스의 출력을 파일 설명자에서 온 것처럼 받아들이게 합니다. 그런 다음 이는 while 루프로 리디렉션되어 read 명령이 구문 분석할 텍스트를 제공합니다.
chmod 명령을 사용하여 스크립트를 실행 가능하게 만드십시오. 이 문서에서 스크립트를 복사할 때마다 이 작업을 수행해야 합니다. 각 경우에 적절한 스크립트의 이름을 대체하십시오.
chmod +x 필드.sh

스크립트를 실행할 때 레코드는 구성 필드로 올바르게 분할되며 각 필드는 다른 변수에 저장됩니다.
./필드.sh
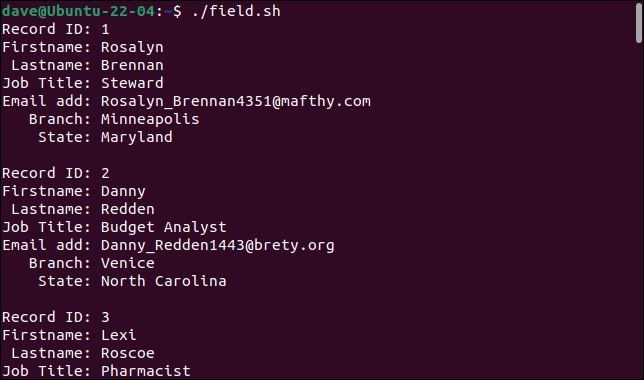
각 레코드는 필드 세트로 인쇄됩니다.
필드 선택
아마도 우리는 모든 필드를 검색하고 싶지 않거나 검색할 필요가 없습니다. cut 명령을 통합하여 필드를 선택할 수 있습니다.
이 스크립트를 "select.sh"라고 합니다.
#!/bin/bash IFS="," read -r id jobtitle 분기 상태 하다 echo "레코드 ID: $id" echo "직위: $jobtitle" echo " 브랜치: $branch" echo " 상태: $state" 에코 "" 완료 < <(자르기 -d "," -f1,4,6,7 sample.csv | 꼬리 -n +2)
프로세스 대체 절에 cut 명령을 추가했습니다. -d (구분자) 옵션을 사용하여 cut 이 구분 기호로 쉼표 " , "를 사용하도록 지시합니다. -f (필드) 옵션은 cut 에 필드 1, 4, 6, 7을 원한다고 알려줍니다. 이 4개의 필드는 4개의 변수로 읽혀서 while 루프의 본문에 인쇄됩니다.
이것은 우리가 스크립트를 실행할 때 얻는 것입니다.
./select.sh
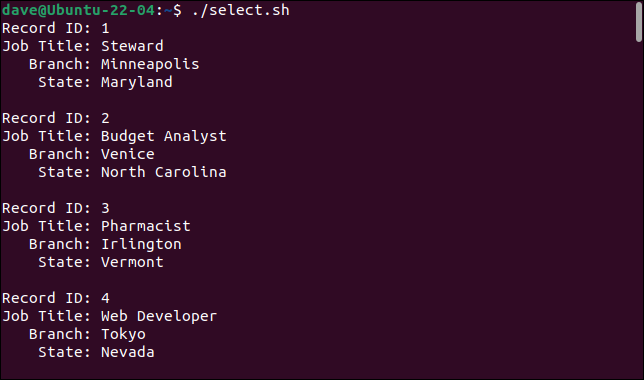
cut 명령을 추가하여 원하는 필드를 선택하고 원하지 않는 필드는 무시할 수 있습니다.
여태까지는 그런대로 잘됐다. 하지만…
다루는 CSV가 필드 데이터에 쉼표나 따옴표 없이 복잡하지 않은 경우 우리가 다룬 내용이 CSV 구문 분석 요구 사항을 충족할 수 있습니다. 발생할 수 있는 문제를 보여주기 위해 데이터의 작은 샘플을 다음과 같이 수정했습니다.
아이디,이름,성,직위,이메일주소,지점,주 1,Rosalyn,Brennan,"스튜어드, 시니어",[email protected],미니애폴리스,메릴랜드 2,Danny,Redden,"분석가 ""예산""",[email protected],Venice,North Carolina 3,Lexi,Roscoe,약사,Irlington,버몬트
- 첫 번째 레코드는
job-title필드에 쉼표가 있으므로 필드를 따옴표로 묶어야 합니다. - 두 번째 레코드에는
jobs-title필드에 두 세트의 따옴표로 묶인 단어가 있습니다. - 레코드 3에는
email-address필드에 데이터가 없습니다.
이 데이터는 "sample2.csv"로 저장되었습니다. "field.sh" 스크립트를 수정하여 "sample2.csv"를 호출하고 "field2.sh"로 저장합니다.
#! /bin/bash IFS="," read -r id 이름 성 직위 이메일 분기 상태 하다 echo "레코드 ID: $id" echo "이름: $이름" echo " 성: $lastname" echo "직위: $jobtitle" echo "이메일 추가: $email" echo " 브랜치: $branch" echo " 상태: $state" 에코 "" 완료 < <(꼬리 -n +2 sample2.csv)
이 스크립트를 실행하면 간단한 CSV 파서에 균열이 나타나는 것을 볼 수 있습니다.

./필드2.sh

첫 번째 레코드는 직위 필드를 두 개의 필드로 분할하고 두 번째 부분을 이메일 주소로 처리합니다. 이후의 모든 필드는 오른쪽으로 한 칸 이동합니다. 마지막 필드에는 branch 값과 state 값이 모두 포함됩니다.
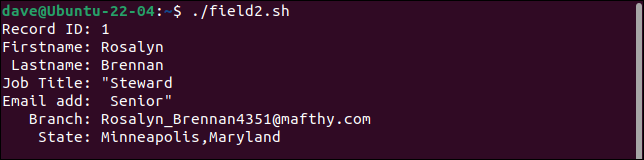
두 번째 레코드는 모든 따옴표를 유지합니다. "예산"이라는 단어 주위에는 한 쌍의 따옴표만 있어야 합니다.
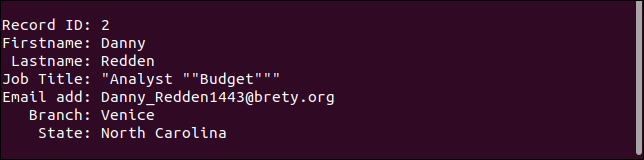
세 번째 레코드는 실제로 누락된 필드를 원래대로 처리합니다. 이메일 주소가 누락되었지만 다른 모든 것은 원래대로입니다.

반직관적으로 간단한 데이터 형식의 경우 강력한 일반 사례 CSV 파서를 작성하는 것은 매우 어렵습니다. awk 와 같은 도구를 사용하면 가까이 갈 수 있지만 항상 예외적인 경우와 예외가 있습니다.

오류가 없는 CSV 파서를 작성하는 것은 아마도 최선의 방법이 아닐 것입니다. 다른 접근 방식(특히 어떤 종류의 마감일까지 작업하는 경우)은 두 가지 다른 전략을 사용합니다.
하나는 목적에 맞게 설계된 도구를 사용하여 데이터를 조작하고 추출하는 것입니다. 두 번째는 데이터를 삭제하고 포함된 쉼표 및 따옴표와 같은 문제 시나리오를 교체하는 것입니다. 그러면 간단한 Bash 파서가 Bash 친화적 CSV에 대처할 수 있습니다.
csvkit 툴킷
CSV 툴킷 csvkit 은 CSV 파일 작업을 돕기 위해 명시적으로 생성된 유틸리티 모음입니다. 컴퓨터에 설치해야 합니다.
Ubuntu에 설치하려면 다음 명령을 사용하십시오.
sudo apt 설치 csvkit

Fedora에 설치하려면 다음을 입력해야 합니다.
sudo dnf 설치 python3-csvkit

Manjaro에서 명령은 다음과 같습니다.
sudo 팩맨 -S csvkit

CSV 파일 이름을 전달하면 csvlook 유틸리티는 각 필드의 내용을 보여주는 테이블을 표시합니다. 필드 내용은 CSV 파일에 저장된 것이 아니라 필드 내용이 나타내는 것을 표시하기 위해 표시됩니다.
문제가 있는 "sample2.csv" 파일로 csvlook 을 사용해 보겠습니다.
csvlook 샘플2.csv
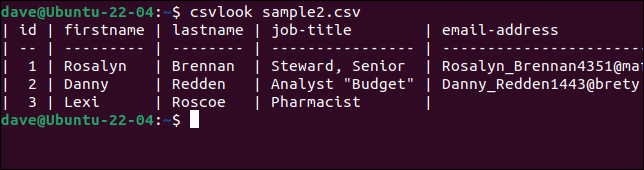
모든 필드가 올바르게 표시됩니다. 이것은 문제가 CSV가 아님을 증명합니다. 문제는 스크립트가 CSV를 올바르게 해석하기에는 너무 단순하다는 것입니다.
특정 열을 선택하려면 csvcut 명령을 사용하십시오. -c (열) 옵션은 필드 이름이나 열 번호 또는 이 둘을 혼합하여 사용할 수 있습니다.
각 레코드에서 이름과 성, 직함, 이메일 주소를 추출해야 하지만 이름 순서를 "성, 이름"으로 지정하려고 한다고 가정합니다. 우리가 해야 할 일은 필드 이름이나 숫자를 원하는 순서대로 넣는 것입니다.
이 세 가지 명령은 모두 동일합니다.
csvcut -c 성, 이름, 직위, 이메일 주소 sample2.csv
csvcut -c 성, 이름, 4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
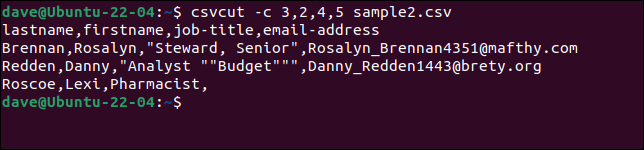
csvsort 명령을 추가하여 필드별로 출력을 정렬할 수 있습니다. -c (열) 옵션을 사용하여 정렬 기준으로 사용할 열을 지정하고 -r (역) 옵션을 사용하여 내림차순으로 정렬합니다.
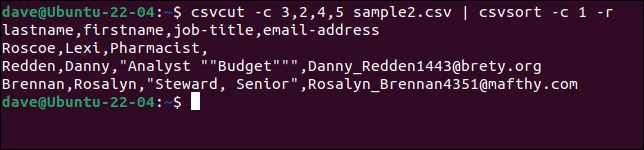
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
출력을 더 예쁘게 만들기 위해 csvlook 을 통해 공급할 수 있습니다.
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
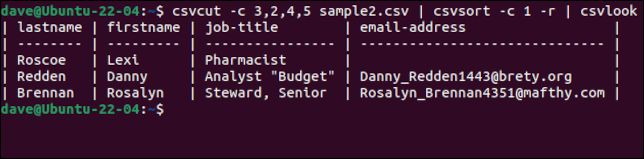
깔끔한 터치는 레코드가 정렬되더라도 필드 이름이 있는 헤더 행이 첫 번째 행으로 유지된다는 것입니다. 원하는 방식으로 데이터가 확보되면 명령 체인에서 csvlook 을 제거하고 출력을 파일로 리디렉션하여 새 CSV 파일을 만들 수 있습니다.
"sample2.file"에 더 많은 데이터를 추가하고 csvsort 명령을 제거하고 "sample3.csv"라는 새 파일을 만들었습니다.
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

CSV 데이터를 삭제하는 안전한 방법
LibreOffice Calc에서 CSV 파일을 열면 각 필드가 셀에 배치됩니다. 찾기 및 바꾸기 기능을 사용하여 쉼표를 검색할 수 있습니다. 사라지도록 "nothing"으로 바꾸거나 세미콜론과 같이 CSV 구문 분석에 영향을 미치지 않는 문자로 바꿀 수 있습니다 ; " 예를 들어.
인용된 필드 주위에 인용 부호가 표시되지 않습니다. 볼 수 있는 유일한 따옴표는 필드 데이터 내부 에 포함된 따옴표입니다. 작은따옴표로 표시됩니다. 이를 찾아 작은 아포스트로피 " ' "로 바꾸면 CSV 파일에서 큰따옴표가 바뀝니다.
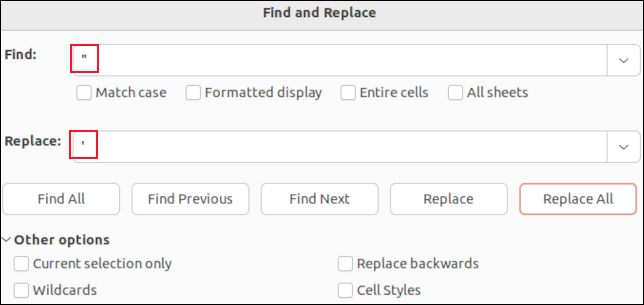
LibreOffice Calc와 같은 응용 프로그램에서 찾기 및 바꾸기를 수행하면 실수로 필드 구분자 쉼표를 삭제하거나 인용된 필드 주위의 따옴표를 삭제할 수 없습니다. 필드의 데이터 값만 변경합니다.
필드의 모든 쉼표는 세미콜론으로, 포함된 따옴표는 모두 아포스트로피로 변경하고 변경 사항을 저장했습니다.
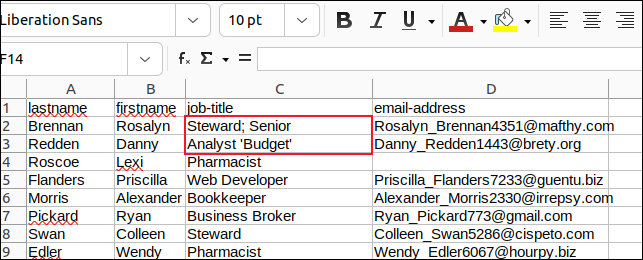
그런 다음 "sample3.csv"를 구문 분석하기 위해 "field3.sh"라는 스크립트를 만들었습니다.
#! /bin/bash IFS="," read -r 성 이름 직함 이메일 하다 echo " 성: $lastname" echo "이름: $이름" echo "직위: $jobtitle" echo "이메일 추가: $email" 에코 "" 완료 < <(꼬리 -n +2 sample3.csv)
실행할 때 무엇을 얻을 수 있는지 봅시다.
./필드3.sh
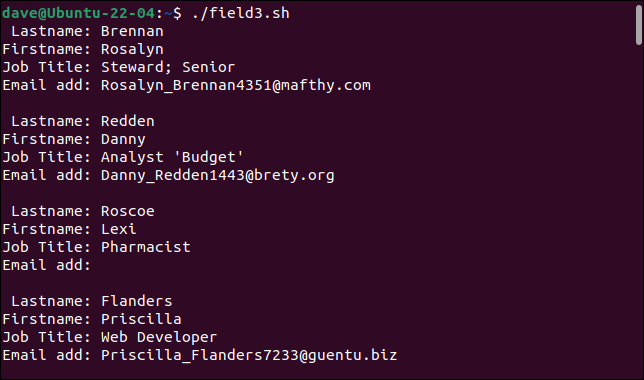
이제 간단한 구문 분석기가 이전에 문제가 있었던 레코드를 처리할 수 있습니다.
많은 CSV를 볼 수 있습니다.
CSV는 틀림없이 애플리케이션 데이터에 대한 공통 언어에 가장 가까운 것입니다. 일부 형식의 데이터를 처리하는 대부분의 응용 프로그램은 CSV 가져오기 및 내보내기를 지원합니다. 현실적이고 실용적인 방법으로 CSV를 처리하는 방법을 알면 오히려 도움이 될 것입니다.
관련: Linux 시작을 위한 9가지 Bash 스크립트 예제