
Linux에서 grep 명령을 사용하는 방법
게시 됨: 2022-01-29
Linux grep 명령은 여러 파일에서 일치하는 행을 표시하는 문자열 및 패턴 일치 유틸리티입니다. 다른 명령의 파이프된 출력에서도 작동합니다. 우리는 당신에게 방법을 보여줍니다.
grep 비하인드 스토리
grep 명령은 세 가지 이유로 Linux 및 Unix 서클에서 유명합니다. 첫째, 매우 유용합니다. 둘째, 풍부한 옵션이 압도적일 수 있습니다. 셋째, 특정한 필요를 충족시키기 위해 밤새 썼습니다. 처음 두 개는 계속됩니다. 세 번째는 약간 떨어져 있습니다.
Ken Thompson은 ed 편집기(ee-dee로 발음)에서 정규식 검색 기능을 추출하고 텍스트 파일을 검색하기 위해 자신이 사용할 작은 프로그램을 만들었습니다. Bell Labs의 부서장인 Doug Mcilroy는 Thompson에게 접근하여 동료 중 한 명인 Lee McMahon이 직면한 문제에 대해 설명했습니다.

McMahon은 텍스트 분석을 통해 Federalist 문서의 저자를 식별하려고 했습니다. 그는 텍스트 파일 내에서 구와 문자열을 검색할 수 있는 도구가 필요했습니다. Thompson은 그날 저녁 자신의 도구를 다른 사람들이 사용할 수 있는 일반 유틸리티로 만들고 grep 으로 이름을 변경하는 데 약 1시간을 보냈습니다. 그는 "전역 정규식 검색"으로 번역되는 ed 명령 문자열 g/re/p 에서 이름을 가져왔습니다.
Thompson이 Brian Kernighan에게 grep 의 탄생에 대해 이야기하는 것을 볼 수 있습니다.
grep을 사용한 간단한 검색
파일 내에서 문자열을 검색하려면 명령줄에 검색어와 파일 이름을 전달합니다.

일치하는 선이 표시됩니다. 이 경우 한 줄입니다. 일치하는 텍스트가 강조 표시됩니다. 이는 대부분의 배포판에서 grep 의 별칭이 다음과 같기 때문입니다.
별칭 grep='grep --color=자동'
일치하는 행이 여러 개 있는 결과를 살펴보겠습니다. 응용 프로그램 로그 파일에서 "평균"이라는 단어를 찾습니다. 단어가 로그 파일에서 소문자인지 기억할 수 없기 때문에 -i (대소문자 무시) 옵션을 사용합니다.
grep -i 평균 괴짜-1.log

일치하는 모든 줄이 표시되며 각 줄에서 일치하는 텍스트가 강조 표시됩니다.
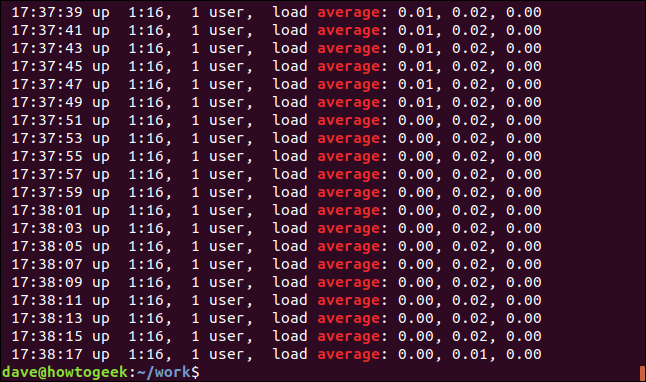
-v(일치 반전) 옵션을 사용하여 일치하지 않는 라인을 표시할 수 있습니다.
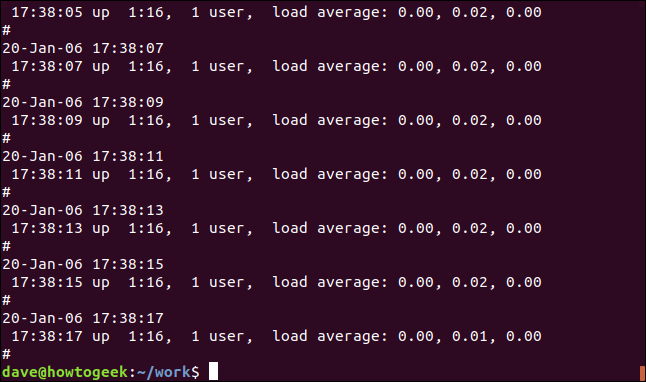
grep -v 메모리 괴짜-1.log

일치하지 않는 라인이기 때문에 강조 표시가 없습니다.
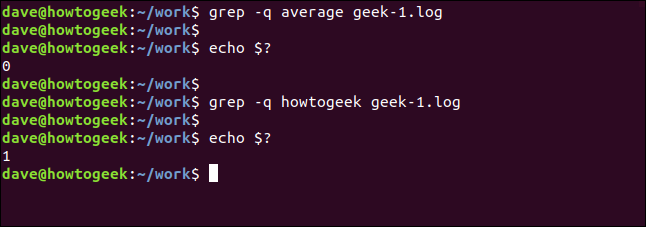
grep 이 완전히 침묵하도록 할 수 있습니다. 결과는 grep 의 반환 값으로 셸에 전달됩니다. 0의 결과는 문자열 이 발견되었음을 의미하고 1의 결과는 발견 되지 않았음을 의미합니다. $? 를 사용하여 리턴 코드를 확인할 수 있습니다. 특수 매개변수:
grep -q 평균 괴짜-1.log
에코 $?
grep -q howtogeek geek-1.log
에코 $?
grep을 사용한 재귀 검색
중첩된 디렉터리 및 하위 디렉터리를 검색하려면 -r(재귀) 옵션을 사용합니다. 명령줄에 파일 이름을 제공하지 않고 경로를 제공해야 합니다. 여기에서 현재 디렉토리 "."를 검색하고 있습니다. 및 모든 하위 디렉토리:
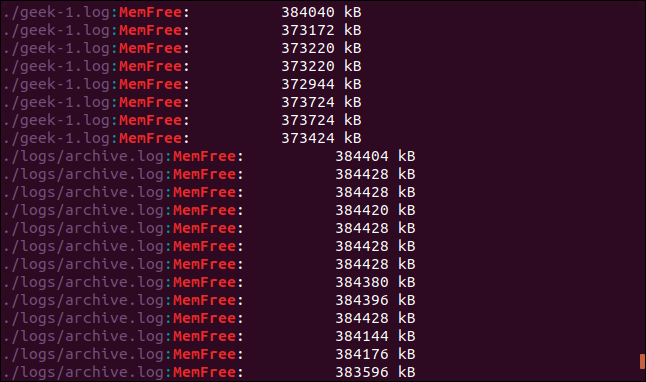
grep -r -i memfree .

출력에는 일치하는 각 줄의 디렉토리와 파일 이름이 포함됩니다.
-R (재귀적 역참조) 옵션을 사용하여 grep 이 심볼릭 링크를 따르도록 할 수 있습니다. 이 디렉토리에 logs-folder 라는 심볼릭 링크가 있습니다. /home/dave/logs 를 가리킵니다.
ls -l 로그 폴더

-R (재귀적 역참조) 옵션을 사용하여 마지막 검색을 반복해 보겠습니다.
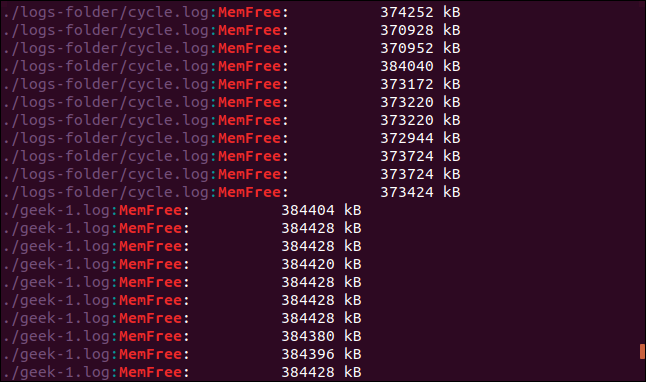
grep -R -i memfree .

심볼릭 링크가 뒤따르고 그것이 가리키는 디렉토리도 grep 에 의해 검색됩니다.
전체 단어 검색
기본적으로 grep 은 검색 대상이 다른 문자열 내부를 포함하여 해당 줄의 아무 곳에나 나타나면 해당 줄과 일치합니다. 이 예를 보십시오. 우리는 "무료"라는 단어를 검색할 것입니다.
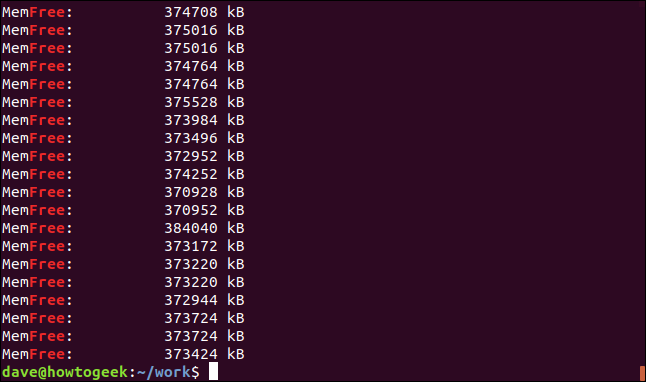
grep -i 무료 괴짜-1.log

결과는 "free" 문자열이 포함된 행이지만 별도의 단어는 아닙니다. "MemFree" 문자열의 일부입니다.
grep 이 별도의 "단어"와만 일치하도록 하려면 -w (단어 regexp) 옵션을 사용하십시오.
grep -w -i 무료 괴짜-1.log
에코 $?
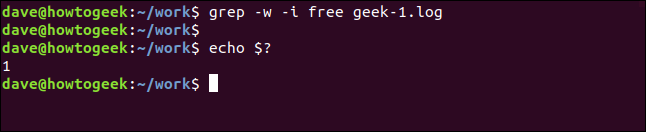
이번에는 "무료"라는 검색어가 파일에 별도의 단어로 나타나지 않기 때문에 결과가 없습니다.
여러 검색어 사용
-E (extended regexp) 옵션을 사용하면 여러 단어를 검색할 수 있습니다. ( -E 옵션은 더 이상 사용되지 않는 egrep 버전의 grep 을 대체합니다.)
이 명령은 "average"와 "memfree"라는 두 가지 검색어를 검색합니다.
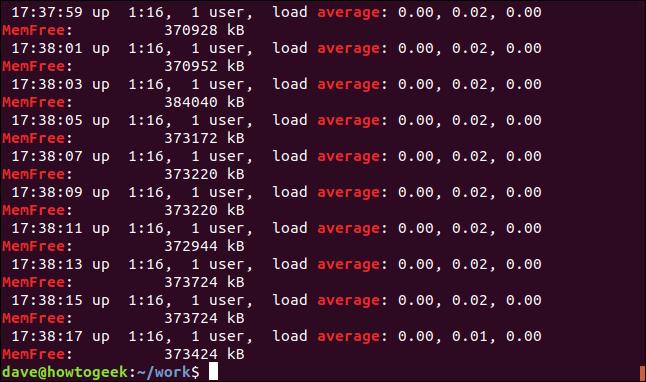
grep -E -w -i "평균|memfree" geek-1.log

각 검색어에 대해 일치하는 모든 줄이 표시됩니다.
전체 단어일 필요는 없지만 전체 단어일 수도 있는 여러 용어를 검색할 수도 있습니다.
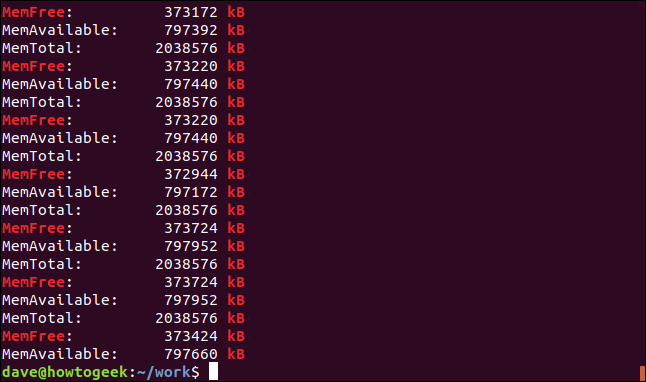
-e (패턴) 옵션을 사용하면 명령줄에서 여러 검색어를 사용할 수 있습니다. 정규식 대괄호 기능을 사용하여 검색 패턴을 만들고 있습니다. 대괄호 "[]"에 포함된 문자 중 하나와 일치하도록 grep 에 지시합니다. 이것은 grep 이 검색할 때 "kB" 또는 "KB"와 일치함을 의미합니다.

두 문자열이 모두 일치하며 실제로 일부 행에는 두 문자열이 모두 포함되어 있습니다.
라인을 정확히 일치시키기
-x (정규식 줄)는 전체 줄 이 검색어와 일치하는 줄만 찾습니다. 로그 파일에 한 번만 나타나는 날짜 및 시간 스탬프를 검색해 보겠습니다.
grep -x "20-1월--06 15:24:35" geek-1.log

일치하는 단일 행을 찾아서 표시합니다.
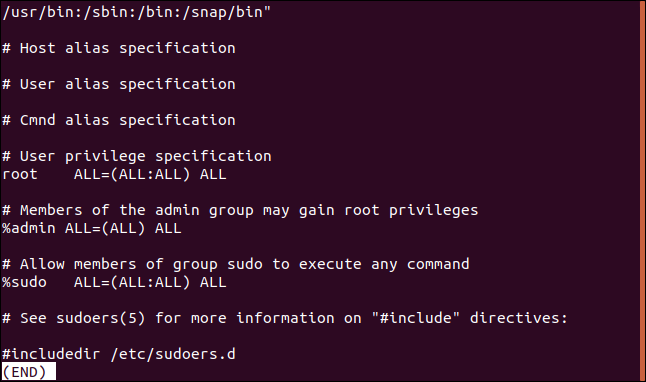
그 반대는 일치 하지 않는 행만 표시하는 것입니다. 이것은 구성 파일을 볼 때 유용할 수 있습니다. 댓글은 훌륭하지만 때로는 전체 중에서 실제 설정을 찾기가 어렵습니다. 다음은 /etc/sudoers 파일입니다.
다음과 같이 주석 줄을 효과적으로 필터링할 수 있습니다.
sudo grep -v "#" /etc/sudoers
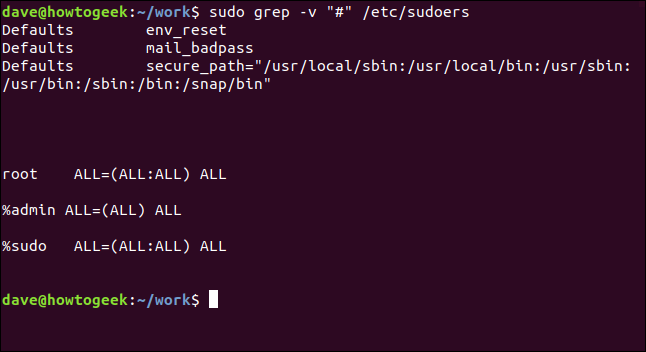
구문 분석이 훨씬 쉽습니다.
일치하는 텍스트만 표시
일치하는 줄 전체를 보고 싶지 않고 일치하는 텍스트만 보고 싶은 경우가 있을 수 있습니다. -o (일치하는 경우에만) 옵션이 바로 이 작업을 수행합니다.
grep -o MemFree geek-1.log

일치하는 줄 전체가 아닌 검색어와 일치하는 텍스트만 표시하도록 표시가 축소됩니다.

grep으로 계산하기
grep 은 텍스트에 관한 것이 아니라 숫자 정보도 제공할 수 있습니다. 우리는 다른 방법으로 grep count를 만들 수 있습니다. 검색어가 파일에 몇 번 나타나는지 알고 싶다면 -c (count) 옵션을 사용할 수 있습니다.
grep -c 평균 괴짜-1.log

grep 은 검색어가 이 파일에 240번 나타난다고 보고합니다.

-n (줄 번호) 옵션을 사용하여 grep 이 일치하는 각 줄에 대한 줄 번호를 표시하도록 할 수 있습니다.
grep -n Jan geek-1.log

각 일치하는 줄의 줄 번호는 줄의 시작 부분에 표시됩니다.
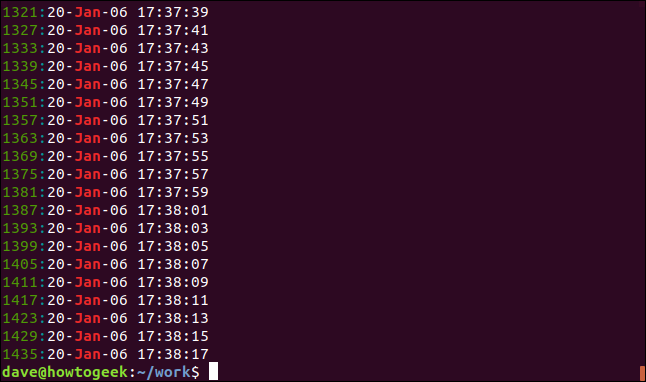
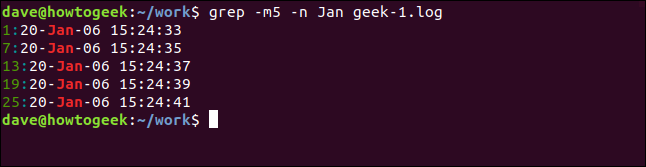
표시되는 결과 수를 줄이려면 -m (최대 개수) 옵션을 사용합니다. 출력을 5개의 일치하는 줄로 제한할 것입니다.
grep -m5 -n Jan geek-1.log
컨텍스트 추가
각 일치하는 선에 대해 일부 추가 선(일치하지 않는 선)을 볼 수 있는 것이 종종 유용합니다. 일치하는 행 중 관심 있는 행을 구별하는 데 도움이 될 수 있습니다.
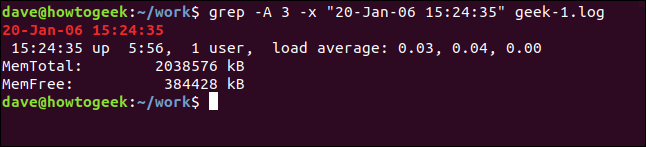
일치하는 줄 뒤에 일부 줄을 표시하려면 -A(컨텍스트 이후) 옵션을 사용합니다. 이 예에서는 세 줄을 요구합니다.
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
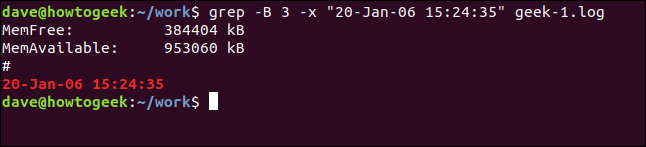
일치하는 줄 이전의 일부 줄을 보려면 -B (context before) 옵션을 사용하십시오.
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
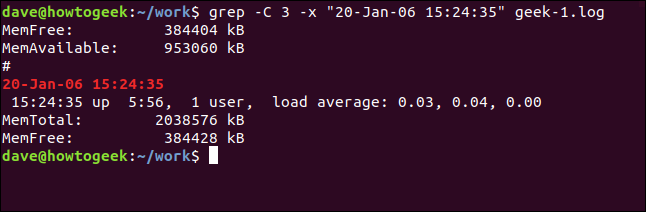
그리고 일치하는 줄 전후의 줄을 포함하려면 -C (context) 옵션을 사용하십시오.
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
일치하는 파일 표시
검색어가 포함된 파일의 이름을 보려면 -l (일치하는 파일) 옵션을 사용하십시오. sl.h 헤더 파일에 대한 참조가 포함된 C 소스 코드 파일을 찾으려면 다음 명령을 사용하십시오.
grep -l "sl.h" *.c

일치하는 줄이 아니라 파일 이름이 나열됩니다.
물론 검색어가 포함되지 않은 파일을 찾을 수도 있습니다. -L (일치하지 않는 파일) 옵션이 바로 이 작업을 수행합니다.
grep -L "sl.h" *.c

라인의 시작과 끝
grep 이 줄의 시작이나 끝에 있는 일치 항목만 표시하도록 강제할 수 있습니다. "^" 정규식 연산자는 줄의 시작과 일치합니다. 실제로 로그 파일 내의 모든 줄에는 공백이 포함되지만 첫 번째 문자로 공백이 있는 줄을 검색할 것입니다.
grep "^ " 괴짜-1.log

첫 번째 문자로 공백이 있는 줄(줄 시작 부분)이 표시됩니다.
줄의 끝을 일치시키려면 "$" 정규식 연산자를 사용하십시오. "00"으로 끝나는 줄을 검색할 것입니다.
grep "00$" geek-1.log

디스플레이에 "00"이 마지막 문자로 포함된 행이 표시됩니다.
grep과 함께 파이프 사용
물론 입력을 grep 으로 파이프하고 grep 의 출력을 다른 프로그램으로 파이프하며 파이프 체인의 중간에 grep 을 배치할 수 있습니다.
C 소스 코드 파일에서 "ExtractParameters" 문자열의 모든 발생을 보고 싶다고 가정해 보겠습니다. 꽤 많을 것이라는 것을 알고 있으므로 출력을 less 로 파이프합니다.
grep "ExtractParameters" *.c | 더 적은

출력은 less 에 표시됩니다.
이렇게 하면 파일 목록을 통해 페이지를 탐색하고 less's 검색 기능을 사용할 수 있습니다.
grep 의 출력을 wc 로 파이프하고 -l (줄) 옵션을 사용하면 "ExtractParameters"가 포함된 소스 코드 파일의 줄 수를 계산할 수 있습니다. ( grep -c (count) 옵션을 사용하여 이것을 달성할 수 있지만 이것은 grep 에서 파이프를 보여주는 깔끔한 방법입니다.)
grep "ExtractParameters" *.c | 화장실 -l

다음 명령을 사용하여 ls 의 출력을 grep 으로 연결하고 grep 의 출력을 sort 로 연결합니다. 현재 디렉토리에 있는 파일을 나열하고 "Aug" 문자열이 포함된 파일을 선택하고 파일 크기별로 정렬합니다.
ls -l | grep "8월" | 정렬 +4n
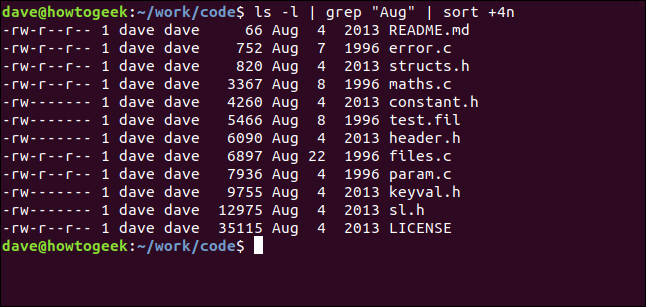
다음과 같이 분해해 보겠습니다.
- ls -l :
ls를 사용하여 긴 형식의 파일 목록을 수행합니다. - grep "Aug" :
ls목록에서 "Aug"가 포함된 행을 선택합니다. 이렇게 하면 이름에 "Aug"가 포함된 파일도 찾을 수 있습니다. - sort +4n : 네 번째 열(파일 크기)에서 grep의 출력을 정렬합니다.
파일 크기의 오름차순으로 8월에 수정된 모든 파일의 정렬된 목록(연도에 관계 없음)을 얻습니다.
관련: Linux에서 파이프를 사용하는 방법
grep: 더 적은 명령, 더 많은 동맹
grep 은 마음대로 사용할 수 있는 훌륭한 도구입니다. 그것은 1974년에 시작되었으며 우리는 그것이 하는 일이 필요하고 더 나은 것은 없기 때문에 여전히 강력하게 진행되고 있습니다.
grep 을 일부 정규식과 결합하면 fu가 실제로 다음 단계로 이동합니다.
관련: 기본 정규식을 사용하여 더 나은 검색 및 시간 절약 방법
| 리눅스 명령어 | ||
| 파일 | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · tail · stat · ls · fstab · echo · less · chgrp · chown · rev · 보기 · 문자열 · 유형 · 이름 바꾸기 · zip · 압축 풀기 · 마운트 · 언마운트 · 설치 · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · 패치 · 변환 · rclone · 파쇄 · srm | |
| 프로세스 | alias · screen · top · nice · renice · progress · strace · systemd · tmux · chsh · history · at · batch · free · which · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · timeout · wall · yes · kill · sleep · sudo · su · time · groupadd · usermod · groups · lshw · 종료 · 재부팅 · 정지 · poweroff · passwd · lscpu · crontab · 날짜 · bg · fg | |
| 네트워킹 | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · dig · finger · nmap · ftp · curl · wget · who · whoami · w · iptables · ssh-keygen · ufw |
관련: 개발자 및 열광자를 위한 최고의 Linux 노트북