
Linux에서 바이너리 파일을 비교하는 방법
게시 됨: 2022-08-20
두 개의 Linux 바이너리가 동일한지 어떻게 확인할 수 있습니까? 실행 파일인 경우 차이점이 있으면 원치 않거나 악의적인 동작을 의미할 수 있습니다. 다른지 확인하는 가장 쉬운 방법은 다음과 같습니다.
바이너리 파일 비교
Linux는 텍스트 파일을 비교하고 분석하는 방법이 풍부합니다. diff 명령은 두 파일을 비교하고 차이점을 강조 표시합니다. 변경된 줄 주위에 약간의 컨텍스트를 제공하기 위해 변경 사항의 양쪽에 몇 줄을 제공할 수도 있습니다. 그리고 colordiff 명령은 색상을 추가하여 시각적으로 차이점을 더 쉽게 구문 분석할 수 있도록 합니다.
개발자와 작성자는 diff 를 사용하여 서로 다른 버전의 프로그램 소스 코드 파일 또는 초안 텍스트 간의 차이점을 강조합니다. 빠르고 쉬우며 텍스트 문자열 간의 차이점을 확인하는 데 기술적인 기술이 필요하지 않습니다.
바이너리 파일의 세계에서는 상황이 그렇게 간단하지 않습니다. 바이너리 파일은 일반 텍스트로 구성되지 않습니다. 숫자 값을 포함하는 많은 바이트로 구성됩니다. TAR 아카이브 또는 ZIP 파일과 같은 압축 파일인 경우 해당 값은 파일의 압축 해제 및 추출에 필요한 기호 테이블과 함께 아카이브 파일 내부에 저장된 압축 파일을 나타냅니다.

이진 파일이 실행 파일인 경우 파일 바이트의 숫자 값은 CPU, 메타데이터, 레이블 또는 인코딩된 데이터에 대한 기계어 코드 명령과 같은 것으로 해석됩니다. 바이너리 파일이나 라이브러리 파일을 변경하면 바이너리가 실행되거나 다른 응용 프로그램에서 사용될 때 동작이 달라질 수 있습니다.
파일의 생성 또는 수정 날짜와 시간을 스푸핑하기 쉽습니다. 즉, 동일한 이름, 파일 크기(변경 사항이 기존 콘텐츠 바이트를 바이트로 대체하는 경우) 및 날짜 스탬프를 가진 두 가지 버전의 파일이 있을 수 있습니다. 그러나 파일 중 하나가 변경되었을 수 있습니다.
보안 해시 알고리즘
보안 해시 알고리즘은 수학 기반 알고리즘입니다. 파일의 모든 바이트를 스캔하고 수학적 변환을 적용하여 해시 값을 생성하여 64비트 값을 생성합니다. 어느 날이든 동일한 파일은 항상 동일한 해시를 생성합니다. 1바이트 차이라도 근본적으로 다른 해시를 생성합니다.
다운로드 페이지에 표시된 파일의 해시를 종종 볼 수 있습니다. 파일을 다운로드한 후에는 파일에 대한 해시를 생성해야 합니다. 웹페이지에 표시된 해시와 다르면 파일이 손상된 것입니다. 사람들이 오염된 파일을 다운로드하도록 하기 위해 변조되어 정품 파일로 대체되었거나 전송 중에 손상되었습니다.
테스트 컴퓨터에는 공유 라이브러리라는 동일한 파일의 복사본이 두 개 있습니다. 동일한 디렉토리에 있을 수 있도록 파일 이름이 변경되었습니다. 이론적으로 이러한 파일은 동일해야 합니다. 결국, 그들은 공유 라이브러리의 동일한 버전이어야 합니다.
ls -l *.so

파일의 크기, 날짜 스탬프 및 타임 스탬프가 동일합니다. 우연한 관찰자에게는 그것들이 동일하게 보일 것입니다. sha256sum 명령을 사용하여 각 파일에 대한 해시를 생성해 보겠습니다.
sha256sum binary_file1.so
sha256sum binary_file2.so
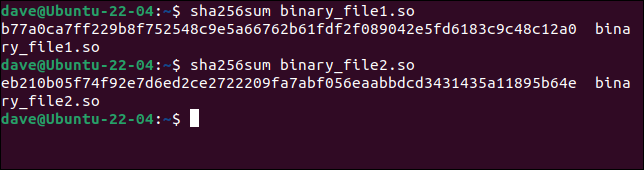
해시는 완전히 다르며 두 파일 간에 차이가 있음을 분명히 나타냅니다. 웹사이트에 정품 파일의 해시가 표시되면 일치하지 않는 파일을 삭제할 수 있습니다.
차이점 찾기
변경 사항을 보고 싶다면 그렇게 하는 방법도 있습니다. 수정 사항을 보기 위해 파일을 디컴파일할 필요도 없고 어셈블리나 기계어 코드를 이해할 필요도 없습니다. 물론 이러한 변경 사항이 의미 하는 바와 목적이 무엇인지 이해하려면 더 깊은 기술 지식이 필요합니다. 그러나 변경 사항이 얼마나 중요한지 아는 것만으로도 파일에 무슨 일이 일어났는지 알 수 있습니다.
두 바이너리 파일에 diff 를 사용하면 다소 실망스러운 응답을 얻을 수 있습니다.
diff 바이너리_파일1.so 바이너리_파일2.so

우리는 이미 파일이 다르다는 것을 알고 있었습니다. cmp 를 시도해보자.
cmp 바이너리_파일1.so 바이너리_파일2.so

이것은 우리에게 조금 더 알려줍니다. 두 파일 사이에 다른 첫 번째 바이트는 바이트 번호 13451입니다. 즉, 바이너리 파일의 시작 부분부터 계산하면 두 바이너리 파일에서 바이트 13451이 다릅니다. 따라서 13451은 파일 시작 부분에서 첫 번째 차이의 오프셋입니다.
우연히 파일 전체에 0x10의 16진수 값을 포함하는 바이트가 있을 것입니다. 이것은 Linux가 텍스트 파일에서 줄 끝 문자로 사용하는 값입니다. cmp 명령은 이진 파일의 시작과 첫 번째 차이의 위치 사이에 이 값과 함께 131바이트를 발견했습니다. 그래서 그것은 132번째 줄에 있다고 생각합니다. 이 문맥에서 그것은 정말로 아무 의미가 없습니다.
-l (verbose) 옵션을 추가하면 유용한 정보를 얻을 수 있습니다.
cmp -l 바이너리_파일1.so 바이너리_파일2.so
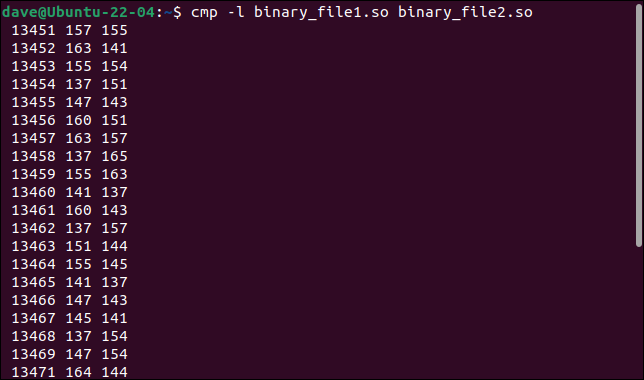
다른 모든 바이트가 나열됩니다. 바이트 번호 또는 오프셋, 첫 번째 파일의 값, 두 번째 파일의 값이 출력 행당 1바이트로 표시됩니다.
바이트 값은 바이너리 파일에 사용되는 일반적인 16진수 형식 대신 8진수로 표시됩니다. 그럼에도 불구하고 우리는 다른 것을 배웠습니다. 변경된 모든 바이트는 하나의 연속 시퀀스에 있습니다. 오프셋은 각 바이트에 대해 1씩 증가합니다.

hexdump 도구는 바이너리 파일을 터미널 창에 덤프합니다. -C (표준) 옵션을 사용하면 출력은 오프셋, 해당 오프셋의 16바이트 값 및 바이트 값의 ASCII 표현(있는 경우)을 각 줄에 나열합니다.
hexdump -C binary_file1.so
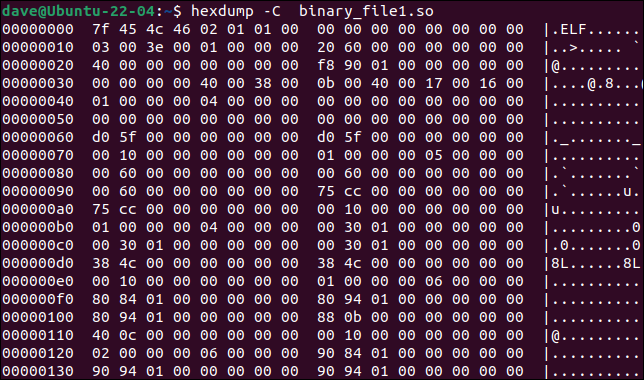
hexdump 의 출력을 diff 에 대한 입력으로 사용할 수 있으므로 diff 가 두 개의 텍스트 파일을 읽는 것처럼 작동하도록 할 수 있습니다.
diff <(hexdump binary_file1.so) <(hexdump binary_file2.so)
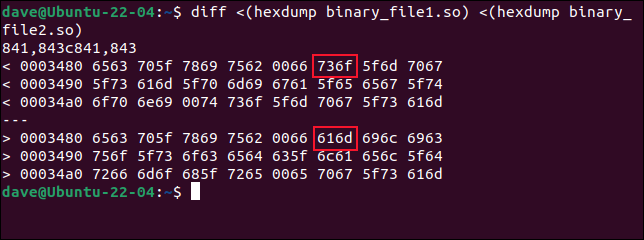
diff 는 다른 행을 찾고 첫 번째 파일의 16진수 바이트 값을 두 번째 파일의 값 위에 표시합니다. 첫 번째 줄의 오프셋은 0x3480 또는 십진수로 13440입니다. 이전에 cmp 는 0x348B인 바이트 13451에서 첫 번째 변경이 발생했다고 말했습니다. 이것은 실제로 우리가 여기서 보는 것과 일치합니다.
diff 의 출력은 2바이트 블록에 있습니다. 첫 번째 바이트 쌍은 0x3480의 오프셋에서 바이트 0과 1이고, 두 번째 블록은 오프셋에서 바이트 2와 3을 보유합니다. 블록 6은 바이트 0xA 및 0xB 또는 십진수로 10 및 11을 보유합니다. 그것들은 바이트 13450과 13451입니다. 그리고 우리는 그들이 다른 첫 번째 바이트임을 알 수 있습니다. 처음 5개의 바이트 쌍은 두 파일에서 동일합니다.
그러나 diff 는 기본 0부터 계산하기 때문에 cmp 가 13451이라고 부르는 것은 diff 에 대한 바이트 13540이 됩니다. 그리고 문제를 더욱 혼란스럽게 하기 위해 각 2바이트 블록의 바이트 순서는 diff 로 반전됩니다. 바이트는 실제로 1과 0, 3과 2, 5와 4, 7과 6 등의 순서로 나열됩니다.
이 명령은 특히 diff 중인 파일이 큰 경우 계산 비용이 많이 hexdumps .
그러나 hexdump -C 가 바이너리 파일의 ASCII 버전을 터미널 창으로 보낼 수 있다면 출력을 텍스트 파일로 리디렉션한 다음 이 두 텍스트 파일을 diff 로 비교하지 않겠습니까?
hexdump -C binary_file1.so > binary1.txt
hexdump -C binary_file2.so > binary2.txt
diff 바이너리1.txt 바이너리2.txt
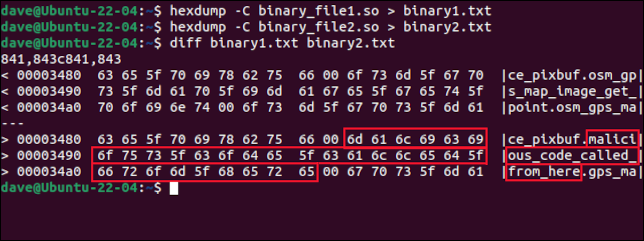
두 파일의 차이점은 두 개의 짧은 추출로 표시됩니다. 그들 옆에는 ASCII 표현이 있습니다. 파일 간의 각 차이에 대한 추출 쌍이 있습니다. 이 예에서는 한 가지 차이점만 있습니다.
그것은 모두 아주 좋은 일이지만, 당신에게 이 모든 것을 할 수 있는 무언가가 있다면 좋지 않을까요?
VBinDiff
VBinDiff 프로그램은 모든 주요 배포판에 대한 일반적인 저장소에서 설치할 수 있습니다. Ubuntu에 설치하려면 다음 명령을 사용하십시오.
sudo apt 설치 vbindiff

Fedora에서는 다음을 입력해야 합니다.
sudo dnf 설치 vbindiff

Manjaro 사용자는 pacman 을 사용해야 합니다.
sudo pacman -Sy vbindiff

프로그램을 사용하려면 명령줄에 두 개의 이진 파일 이름을 전달합니다.
vbindiff binary_file1.so binary_file2.so

터미널 기반 응용 프로그램이 열리고 스크롤 보기에 두 파일이 모두 표시됩니다.
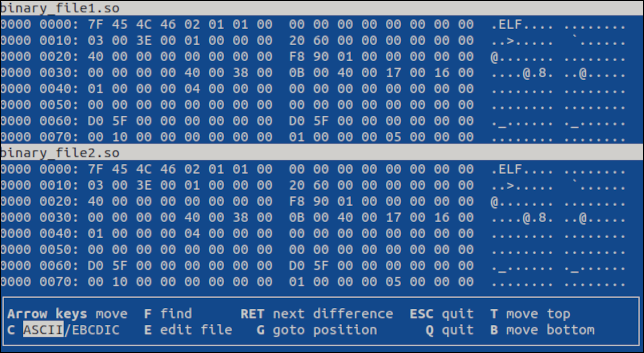
마우스 스크롤 휠 또는 "UpArrow", "DownArrow", "Home", "End", "PageUp" 및 "PageDown" 키를 사용하여 파일을 이동할 수 있습니다. 두 파일 모두 스크롤됩니다.
첫 번째 차이점으로 이동하려면 "Enter" 키를 누르십시오. 차이점은 두 파일 모두에서 강조 표시됩니다.
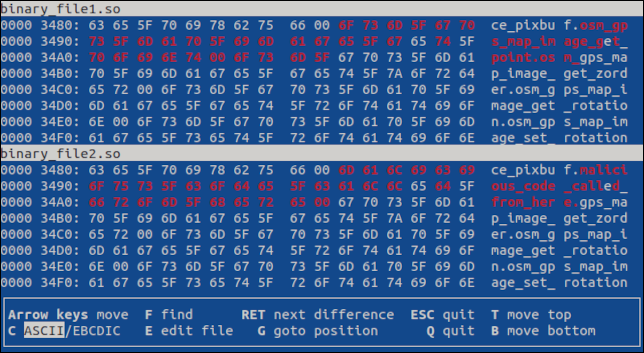
더 많은 차이가 있는 경우 "Enter"를 누르면 다음 차이가 표시됩니다. "q" 또는 "Esc"를 누르면 프로그램이 종료됩니다.
차이점이 뭐야?
다른 사람이 소유한 컴퓨터에서 작업 중이고 패키지를 설치할 수 없는 경우 cmp , diff 및 hexdump 를 사용할 수 있습니다. 추가 처리를 위해 출력을 캡처해야 하는 경우에도 사용할 수 있는 도구입니다.
그러나 패키지 설치가 허용된 경우 VBinDiff는 워크플로를 더 쉽고 빠르게 만듭니다. 사실, 단일 바이너리 파일과 함께 VBinDiff를 사용하는 것은 바이너리 파일을 탐색하는 쉽고 편리한 방법이며 이는 좋은 보너스입니다.
관련: Linux 명령줄에서 바이너리 파일 내부를 엿보는 방법