
検索エンジンはどのように機能し、あなたの生活を楽にしますか?
公開: 2015-11-06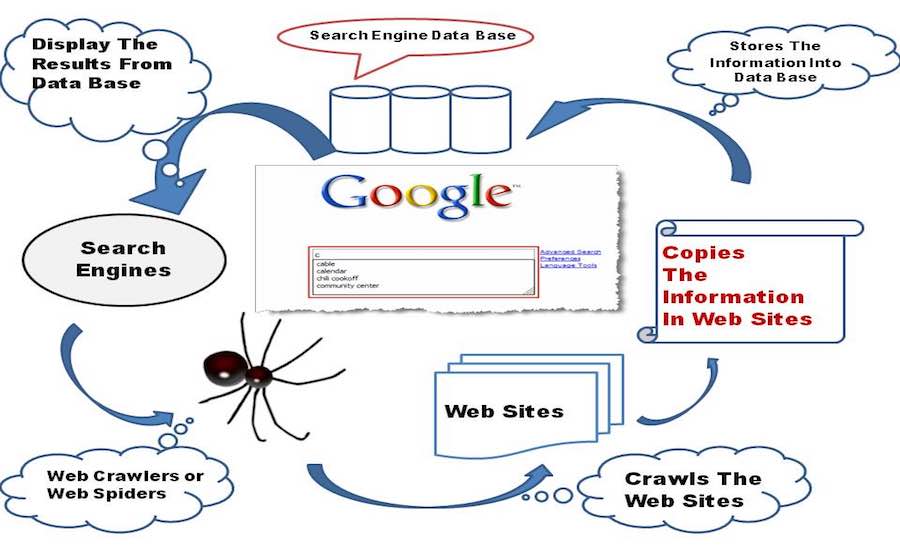 ショートバイト:検索エンジンは、適切なデータを収集するために、WebクロールとWebインデックス、いくつかのファットフォーミュラ、インテリジェントアルゴリズムを使用して、入力された検索クエリに基づいて関連するWebページの結果を表示できるソフトウェアです。
ショートバイト:検索エンジンは、適切なデータを収集するために、WebクロールとWebインデックス、いくつかのファットフォーミュラ、インテリジェントアルゴリズムを使用して、入力された検索クエリに基づいて関連するWebページの結果を表示できるソフトウェアです。
グーグルは瞬く間に最高の結果をどのように提供しますか? 実際、Google、Bingがそこにいるまでは問題ではありません。 Google、Bing、またはYahooがなかった場合、シナリオは大きく異なります。 検索エンジンの世界に飛び込んで、検索エンジンがどのように機能するかを見てみましょう。
歴史をのぞく
検索エンジンのおとぎ話は、ティムバーナーズリーがオンラインになったすべての新しいウェブサーバーをCERNウェブサーバーによって維持されているリストに登録していた1990年代に始まりました。 93年9月まで、インターネット上には検索エンジンは存在しませんでしたが、ファイル名のデータベースを維持できるツールはごくわずかでした。 Archie、Veronica、Jugheadは、このカテゴリーの最初の参入者でした。
ジュネーブ大学のOscarNierstraszは、W3Catalogという名前の最初の検索エンジンが誕生したことで認定されています。 彼はいくつかの本格的なPerlスクリプトを作成し、1993年9月3日にようやく世界初の検索エンジンを発表しました。さらに、1993年には、他の多くの検索エンジンが登場しました。 Jonathon Fletcher、AliWeb、WWWWormなどによるJumpStation。Yahoo! 1995年にウェブディレクトリとして立ち上げられましたが、2000年からInktomiのエンジン検索を使い始め、2009年にMicrosoftのBingに移行しました。
さて、検索エンジンという用語の主要な同義語である名前について話すと、Google Searchは、1995年3月に最初の足跡を残した、スタンフォード大学の2人の卒業生であるLarryPageとSergyBrinの研究プロジェクトでした。ワールドワイドウェブにおけるそのページの重要性を測定するために、ウェブページから発生したバックリンクの数に基づいて計算を行ったページのバックリンク方法による。 「私が今までに得た最高のアドバイス」とページは思い出しながら、上司のテリー・ウィノグラードが彼のアイデアをどのように支持したかを語りました。 そしてそれ以来、Googleは決して振り返りませんでした。
それはすべてクロールから始まります
初期段階の赤ちゃん検索エンジンは、ワールドワイドウェブの探索を開始します。小さな手と膝で、ウェブページで見つけた他のすべてのリンクを探索し、データベースに保存します。
ここで、舞台裏の技術的思考に焦点を当てましょう。検索エンジンにはWeb Crawlerソフトウェアが組み込まれています。これは基本的に、Webページに存在するすべてのハイパーリンクを開き、すべてのリンクからテキストとメタデータのデータベースを作成するタスクを割り当てられたインターネットボットです。 。 それは、シードと呼ばれる、訪問する最初のリンクのセットから始まります。 これらのリンクへのアクセスが進むとすぐに、アクセスするURLの既存のリストに新しいリンクを追加します。これはクロールフロンティアと呼ばれます。
クローラーがリンクをトラバースすると、それらのWebページから情報をダウンロードして、後でスナップショットの形式で表示します。これは、Webページ全体をダウンロードするには大量のデータが必要であり、少なくともインドのような国。 そして、もしグーグルがインドで設立されたとしたら、彼らのお金はすべてインターネット代の支払いに使われるだろうと私は確信している。 うまくいけば、それは今のところ懸念事項ではありません。
Webクローラーは、いくつかのポリシーに基づいてWebページを探索します。
選択ポリシー:クローラーは、ダウンロードするページとダウンロードしないページを決定します。 選択ポリシーは、重要でないデータではなく、Webページの最も関連性の高いコンテンツのダウンロードに重点を置いています。
再訪問ポリシー:クローラーは、インターネットの動的な性質により、クローラーが最新バージョンの更新を維持することが非常に困難であるため、Webページを再度開いてデータベースの変更を編集する時間をスケジュールします。ウェブページ。
並列化ポリシー:クローラーは一度に複数のプロセスを使用して分散クロールと呼ばれるリンクを探索しますが、異なるプロセスが同じWebページをダウンロードする可能性があるため、クローラーはすべてのプロセス間の調整を維持して、二枚舌。
ポライトネスポリシー:クローラーがWebサイトをトラバースすると、同時にWebページがダウンロードされるため、WebサイトをホストしているWebサーバーの負荷が増加します。 したがって、「クロール遅延」という用語が実装され、クローラーはWebサーバーからデータをダウンロードした後、数秒間待機する必要があり、ポライトネスポリシーが適用されます。
また読む: Pythonで基本的なWebクローラーを構築する方法
標準のWebクローラーの高レベルのアーキテクチャ:
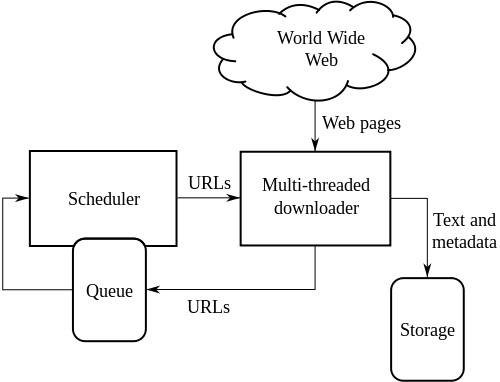
上の図は、Webクローラーがどのように機能するかを示しています。 リンクの最初のリストを開き、次にそれらのリンク内のリンクなどを開きます。
ウィキペディアは、コンピューターサイエンスの研究者であるVladislavShkapenyukとTorstenSuelが次のように述べています。
毎秒数ページを短時間ダウンロードする低速クローラーを構築するのはかなり簡単ですが、数週間にわたって数億ページをダウンロードできる高性能システムを構築することは、システム設計に多くの課題をもたらします。 I / Oとネットワークの効率、および堅牢性と管理性。
クロールのインデックス作成
赤ちゃんの検索エンジンはインターネット全体をクロールした後、途中で見つけたすべてのWebページのインデックスを作成します。 インデックスを作成することは、大きなサイズのドキュメントのヒープから検索クエリを見つけるのに時間を浪費するよりもはるかに優れており、時間とリソースの両方を節約できます。
検索エンジンのための効率的な索引付けシステムの作成に寄与する多くの要因があります。 インデクサーが使用するストレージ技術、インデックスのサイズ、検索されたキーワードを含むドキュメントをすばやく見つける機能などは、インデックスの効率と信頼性に影響を与える要因です。
Webインデックスを成功させるための主要な障害の1つは、2つのプロセス間の衝突です。 あるプロセスがドキュメントを検索し、同時に別のプロセスがドキュメントをインデックスに追加したいとすると、2つのプロセス間に競合が発生します。 より多くのデータを処理するために検索エンジンによる分散コンピューティングを実装すると、問題はさらに悪化します。
インデックスの種類
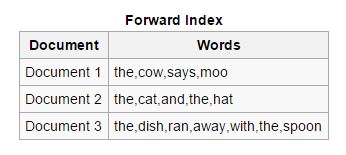
転送:これらのタイプのインデックスでは、ドキュメントに存在するすべてのキーワードがリストに保存されます。 フォワードインデックスは、非同期インデクサーが相互に連携できるため、インデックス作成の開始フェーズで簡単に作成できます。

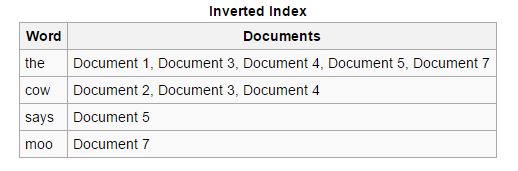
リバース:フォワードインデックスは並べ替えられ、リバースインデックスに変換されます。この場合、特定のキーワードを含む各ドキュメントは、そのキーワードを含む他のドキュメントと一緒にまとめられます。 逆インデックスは、順インデックスの場合とは異なり、特定の検索クエリに関連するドキュメントを見つけるプロセスを容易にします。
また読む:DNS(ドメインネームシステム)とは何ですか?それはどのように機能しますか?
ドキュメントの解析
トークン化とも呼ばれ、キーワード(トークンと呼ばれる)、画像、その他のメディアなどのドキュメントのコンポーネントの内訳を指し、後でインデックスに挿入できるようにします。 この方法は基本的に、母国語を理解し、ユーザーが検索する可能性のあるキーワードを予測することに重点を置いています。これは、効果的なWebインデックスシステムを作成するための基盤として機能します。
主な課題には、抽出するキーワードの単語境界を見つけることが含まれます。中国語や日本語などの言語では、通常、言語スクリプトに空白がないことがわかります。 一部の言語は地理的な変化に伴ってわずかに、または大幅に異なるようになるため、言語が持つあいまいさを理解することも懸念事項です。 また、使用されている言語を明確に言及していない一部のWebページの非効率性も懸念事項であり、インデクサーの作業負荷が増加します。
検索エンジンにはさまざまなファイル形式を認識し、それらからデータを正常に抽出する機能があります。このような場合は、細心の注意を払う必要があります。
メタタグは、インデックスを非常に迅速に作成するのにも非常に役立ちます。メタタグは、Webインデクサーの労力を軽減し、ドキュメント全体を完全に解析する必要性を軽減します。 この記事の下部にメタタグが添付されています。
インデックスの検索
今、赤ちゃんの検索エンジンはもう赤ちゃんではありません。彼は、クロールする方法と物事をすばやく効率的につかむ方法、そして物事を体系的に整理する方法を学びました。 彼の友人が彼に彼の取り決めから何かを見つけるように頼んだとしたら、彼は何をしますか? 正式に派生したものではありませんが、使用されている検索クエリには4つのタイプがありますが、時間の経過とともに進化し、ユーザーによる実際のクエリの観点から有効であることがわかっています。
ナビゲーション:この用語は、ユーザーがインターネット上に存在する特定のWebページまたはWebサイトにアクセスしたいクエリに使用されます。 たとえば、GoogleでfossBytesを検索すると、ナビゲーションクエリが開始されます。
情報:このタイプのクエリには数千の結果があり、ユーザーの知識を高める一般的なトピックをカバーしています。 たとえば、たとえばSteve Jobsを検索すると、SteveJobsに関連するすべてのリンクが表示されます。
トランザクション:特定のアクションを実行するユーザーの意図に焦点を当てたクエリには、事前定義された一連の指示が含まれる場合があります。 たとえば、紛失/盗難にあったノートパソコンを見つける方法は?
接続性:これらのタイプのクエリは頻繁には使用されません。Webサイトから作成されたインデックスがどのように接続されているかに焦点を当てています。 たとえば、検索すると、ウィキペディアには何ページありますか?
GoogleとBingは、クエリに最も関連性の高い結果を決定するのに十分な機能を備えたいくつかの本格的なアルゴリズムを作成しました。 Googleは、コンテンツの品質、新旧、ウェブページの安全性など、200を超える要素に基づいて検索結果を計算すると主張しています。 彼らは検索ラボに任命された世界最高の頭脳を持っています。彼らは難しい計算を行い、驚異的な数式を処理しますが、検索をより簡単かつ迅速にするためだけです。
その他の注目すべき機能*
画像検索:有名な画像検索ツールの背後にあるGoogleのインスピレーションを知って驚かれることでしょう。 J.Lo、そうですね、2000年のグラミー賞でのJ.Loと彼女の緑色のVersace(ver-sah-chay)ガウンは、人々がグーグルで忙しくしていたため、Googleが画像検索を発表した本当の理由でした。彼女。
エリック・シュミットは、2015年1月19日に発行された「TheTinkerer'sApprentice」というタイトルの執筆で述べています。
音声検索: Googleは、多大な労力を費やした後、最初に検索エンジンに音声検索を導入し、その後、他の検索エンジンでも音声検索が実装されました。
スパム対策:検索エンジンはいくつかの深刻なアルゴリズムを展開しているため、スパム攻撃からユーザーを守ることができます。 スパムとは、基本的には、広告やウイルスの送信など、インターネット全体に拡散するメッセージまたはファイルです。 この問題でも、Googleの担当者は、インターネット上でスパムメッセージを拡散する責任があると判断したWebサイトに手動で通知します。
場所の最適化:検索エンジンは、ユーザーの場所に基づいて結果を表示できるようになりました。 「バンガロールの天気はどうですか」を検索すると、天気の統計はバンガロールを参照します。
あなたをよりよく理解する:現代の検索エンジンは、ユーザーが入力したキーワードを見つけるのではなく、ユーザークエリの意味を理解することができます。
オートコンプリート:以前の検索と他のユーザーによる検索に基づいて、入力時に検索クエリを予測する機能。
知識グラフ: Google検索によって提供されるこの機能は、実際の人、場所、およびイベントに基づいて検索結果を提供する機能を示しています。
ペアレンタルコントロール:検索エンジンを使用すると、小さな種類の親がインターネット上で子供が何をしているかを制御できます。
*これらの強力な検索エンジンによって提供される機能の膨大なリストをカバーするのは難しいです。
終わらせている
検索エンジンは私たちの生活をよりシンプルにすることに貢献しており、インターネット上のすべての情報を活用するために検索エンジンが行ってきた努力は貴重です。 しかし、この探検は私たちの個人的なスペースを公共の場で展示することにつながりました。私たちの行動を振り返るのに遅すぎる場合を除いて、私たちがこれまでずっと横断してきた道について慌てなければならない時が来たと言わなければなりません。そして私たちの人生は恥ずかしさのビエンナーレにすぎません。 検索エンジンが今や私たちのデジタルスプリットパーソナリティの重要な部分であるという事実を否定することはできません。 私たちは与えられた技術を利用するだけでよく、それが私たち自身の悪行の連鎖に私たちを奴隷にすることを許しません。
さて、これ以上の感情的な話はありません。今やティーンエイジャーになったその赤ちゃんの検索エンジンのかわいらしさと才能を崇拝し、あなたをはるかによく理解しています。 グーグルは私たちのためにすべてを検索するためにそこにいました、それは私たちの多くにとってインターネットです、そして私たちはグーグル検索を使用している間に私たちが得たそれらの良い経験を大切にしなければなりません。 おー! Bingについて言及するのを忘れました、あなたも素晴らしいです。 警戒を怠らず、安全を確保し、グーグルで検索してください。
このビデオを見て、検索エンジンについてもっと知ってください:
Google検索で[ラッキーだと思っています]ボタンをクリックしたことがありますか。 それを開いて、下のコメントセクションであなたが一番好きなDoodleを教えてください。