
Bash で CSV データを解析する方法
公開: 2022-09-16
カンマ区切り値 (CSV) ファイルは、エクスポートされるデータの最も一般的な形式の 1 つです。 Linux では、Bash コマンドを使用して CSV ファイルを読み取ることができます。 しかし、それは非常に複雑になり、非常に速くなる可能性があります。 手を貸しましょう。
CSV ファイルとは
カンマ区切り値ファイルは、表形式のデータを保持するテキスト ファイルです。 CSV は区切りデータの一種です。 名前が示すように、コンマ「 , 」は、データ (または値) の各フィールドを隣接するフィールドから分離するために使用されます。
CSVはどこにでもあります。 アプリケーションにインポートおよびエクスポート機能がある場合、ほとんどの場合、CSV がサポートされます。 CSV ファイルは人間が判読できます。 less でそれらの内部を調べたり、任意のテキスト エディターで開いたり、プログラム間で移動したりできます。 たとえば、SQLite データベースからデータをエクスポートして、LibreOffice Calc で開くことができます。
ただし、CSV でさえ複雑になる可能性があります。 データ フィールドにコンマを入れたいですか? そのフィールドは引用符「 " 」で囲む必要があります。フィールドに引用符を含めるには、各引用符を 2 回入力する必要があります。
もちろん、作成したプログラムまたはスクリプトによって生成された CSV を使用している場合、CSV 形式は単純でわかりやすいものになる可能性があります。 Linux が Linux であるため、より複雑な CSV 形式を使用する必要がある場合は、そのために使用できるソリューションもあります。
サンプルデータ
Online Data Generator などのサイトを使用して、サンプルの CSV データを簡単に生成できます。 必要なフィールドを定義し、必要なデータの行数を選択できます。 データは現実的なダミー値を使用して生成され、コンピューターにダウンロードされます。
50 行のダミー従業員情報を含むファイルを作成しました。
- id : 単純な一意の整数値。
- firstname : 個人の名。
- lastname : 個人の姓。
- job-title : 個人の役職。
- email-address : 個人の電子メール アドレス。
- branch : 彼らが勤務する会社の支店。
- state : ブランチがある州。
一部の CSV ファイルには、フィールド名をリストするヘッダー行があります。 サンプル ファイルには 1 つ含まれています。 ファイルの先頭は次のとおりです。
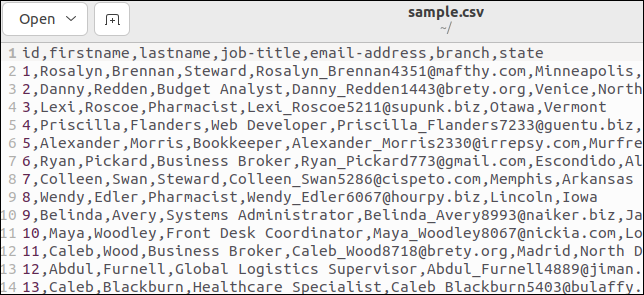
最初の行には、フィールド名がコンマ区切り値として保持されます。
CSV ファイルからのデータの解析
CSV ファイルを読み取り、各レコードからフィールドを抽出するスクリプトを作成しましょう。 このスクリプトをエディターにコピーし、「field.sh」という名前のファイルに保存します。
#! /ビン/バッシュ while IFS="," read -r id firstname lastname jobtitle email branch state 行う echo "レコード ID: $id" echo "名: $firstname" echo "姓: $lastname" echo "役職: $jobtitle" echo "メールアドレス: $email" echo "ブランチ: $branch" echo "状態: $state" エコー "" done < <(tail -n +2 sample.csv)
この小さなスクリプトにはかなりのことが詰め込まれています。 分解してみましょう。

whileループを使用しています。 whileループの条件が true に解決される限り、 whileループの本体が実行されます。 ループの本体は非常に単純です。 一部の変数の値を端末ウィンドウに出力するために、 echoステートメントのコレクションが使用されます。
whileループの条件は、ループの本体よりも興味深いものです。 IFS=","ステートメントを使用して、コンマを内部フィールド セパレータとして使用するように指定します。 IFS は環境変数です。 readコマンドは、一連のテキストを解析するときにその値を参照します。
readコマンドの-r (バックスラッシュを保持) オプションを使用して、データに含まれるバックスラッシュを無視します。 通常のキャラクターとして扱われます。
readコマンドが解析するテキストは、CSV フィールドにちなんで名付けられた一連の変数に格納されます。 field1, field2, ... field7などと簡単に名前を付けることができますが、意味のある名前を付けると作業が楽になります。
データは、 tailコマンドからの出力として取得されます。 CSV ファイルのヘッダー行をスキップする簡単な方法を提供するため、 tailを使用しています。 -n +2 (行番号) オプションは、2 行目から読み取りを開始するようにtailに指示します。
<(...)コンストラクトは、プロセス置換と呼ばれます。 これにより、Bash はプロセスの出力をあたかもファイル記述子からのものであるかのように受け入れます。 これは、 readコマンドが解析するテキストを提供して、 whileループにリダイレクトされます。
chmodコマンドを使用して、スクリプトを実行可能にします。 この記事からスクリプトをコピーするたびに、これを行う必要があります。 いずれの場合も、適切なスクリプトの名前に置き換えてください。
chmod +x field.sh

スクリプトを実行すると、レコードは構成フィールドに正しく分割され、各フィールドは異なる変数に格納されます。
./field.sh
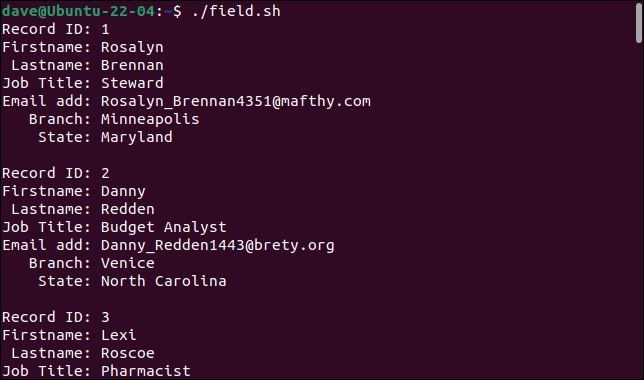
各レコードは一連のフィールドとして出力されます。
フィールドの選択
おそらく、すべてのフィールドを取得したくない、または取得する必要はありません。 cutコマンドを組み込むことで、フィールドの選択を取得できます。
このスクリプトは「select.sh」と呼ばれます。
#!/ビン/バッシュ while IFS="," read -r id jobtitle ブランチの状態 行う echo "レコード ID: $id" echo "役職: $jobtitle" echo "ブランチ: $branch" echo "状態: $state" エコー "" done < <(cut -d "," -f1,4,6,7 sample.csv | テール -n +2)
プロセス置換句にcutコマンドを追加しました。 -d (区切り文字) オプションを使用して、区切り文字としてカンマ「 , 」を使用するようにcutに指示しています。 -f (フィールド) オプションは、 cutにフィールド 1、4、6、および 7 が必要であることを伝えます。 これら 4 つのフィールドは 4 つの変数に読み込まれ、 whileループの本体に出力されます。
これは、スクリプトを実行したときに得られるものです。
./select.sh
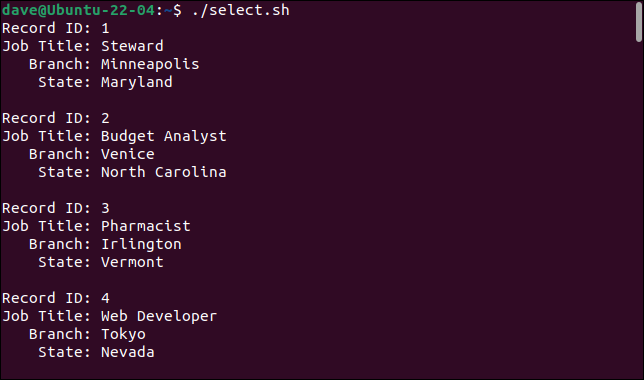
cutコマンドを追加することで、必要なフィールドを選択し、不要なフィールドを無視することができます。
ここまでは順調ですね。 しかし…
扱う CSV がフィールド データにカンマや引用符がなく単純である場合、ここで説明した内容はおそらく CSV 解析のニーズを満たすでしょう。 発生する可能性のある問題を示すために、データの小さなサンプルを次のように変更しました。
id,firstname,lastname,job-title,email-address,branch,state 1、ロザリン、ブレナン、「スチュワード、シニア」、[email protected]、ミネアポリス、メリーランド 2,Danny,Redden,"Analyst ""Budget""",[email protected],Venice,North Carolina 3、レクシー、ロスコー、薬剤師、バーモント州アーリントン
- レコード 1 では、
job-titleフィールドにコンマが含まれているため、フィールドを引用符で囲む必要があります。 - レコード 2 には、
jobs-titleフィールドの 2 組の引用符で囲まれた単語があります。 - レコード 3 には、
email-addressフィールドにデータがありません。
このデータは「sample2.csv」として保存されました。 「field.sh」スクリプトを変更して「sample2.csv」を呼び出し、「field2.sh」として保存します。
#! /ビン/バッシュ while IFS="," read -r id firstname lastname jobtitle email branch state 行う echo "レコード ID: $id" echo "名: $firstname" echo "姓: $lastname" echo "役職: $jobtitle" echo "メールアドレス: $email" echo "ブランチ: $branch" echo "状態: $state" エコー "" done < <(tail -n +2 sample2.csv)
このスクリプトを実行すると、単純な CSV パーサーにクラックが表示されることがわかります。

./field2.sh

最初のレコードは、役職フィールドを 2 つのフィールドに分割し、2 番目の部分を電子メール アドレスとして扱います。 これ以降のすべてのフィールドは、1 つ右にシフトされます。 最後のフィールドには、 branchとstate値の両方が含まれています。
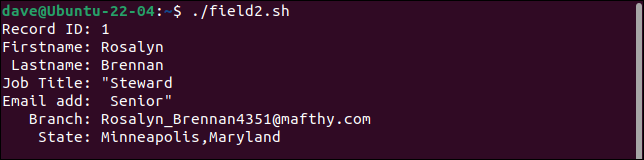
2 番目のレコードはすべての引用符を保持します。 「Budget」という単語を 1 組の引用符で囲む必要があります。
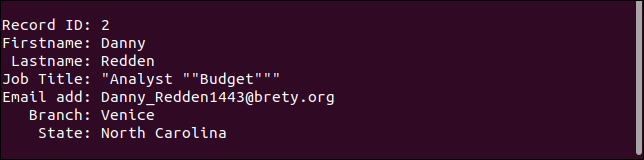
3 番目のレコードは、不足しているフィールドを適切に処理します。 メールアドレスがありませんが、それ以外は問題ありません。

直観に反して、単純なデータ形式の場合、堅牢な汎用 CSV パーサーを作成することは非常に困難です。 awkのようなツールを使用すると、近づくことができますが、すり抜けてしまう特殊なケースや例外が常に存在します。

間違いのない CSV パーサーを作成しようとすることは、おそらく最善の方法ではありません。 別のアプローチ (特に何らかの締め切りに向けて作業している場合) は、2 つの異なる戦略を使用します。
1 つは、目的に合わせて設計されたツールを使用して、データを操作および抽出することです。 2 つ目は、データをサニタイズし、埋め込まれたコンマや引用符などの問題シナリオを置き換えることです。 単純な Bash パーサーは、Bash に適した CSV に対応できます。
csvkit ツールキット
CSV ツールキットcsvkitは、CSV ファイルの操作を支援するために特別に作成されたユーティリティのコレクションです。 コンピューターにインストールする必要があります。
Ubuntu にインストールするには、次のコマンドを使用します。
須藤 apt インストール csvkit

Fedora にインストールするには、次のように入力する必要があります。
sudo dnf install python3-csvkit

Manjaro では、コマンドは次のとおりです。
sudo pacman -S csvkit

CSV ファイルの名前を渡すと、 csvlookユーティリティは各フィールドの内容を示すテーブルを表示します。 フィールドの内容は、CSV ファイルに保存されているためではなく、フィールドの内容が何を表しているかを示すために表示されます。
問題のある「sample2.csv」ファイルでcsvlookを試してみましょう。
csvlook sample2.csv
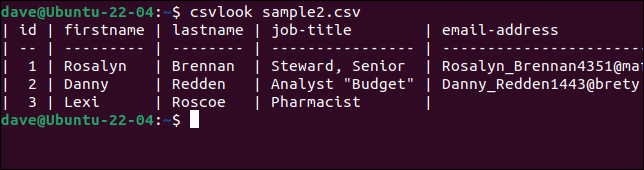
すべてのフィールドが正しく表示されます。 これは、問題が CSV ではないことを証明しています。 問題は、スクリプトが単純すぎて CSV を正しく解釈できないことです。
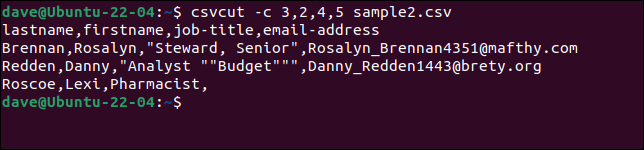
特定の列を選択するには、 csvcutコマンドを使用します。 -c (列) オプションは、フィールド名または列番号、あるいはその両方を組み合わせて使用できます。
各レコードから姓名、役職、電子メール アドレスを抽出する必要があるが、名前の順序を「姓、名」にしたいとします。 必要なのは、フィールド名または番号を必要な順序で配置することだけです。
これら 3 つのコマンドはすべて同等です。
csvcut -c 姓、名、役職、メールアドレス sample2.csv
csvcut -c 姓,名,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
csvsortコマンドを追加して、出力をフィールドでソートできます。 -c (列) オプションを使用して並べ替える列を指定し、 -r (逆) オプションを使用して降順で並べ替えます。
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
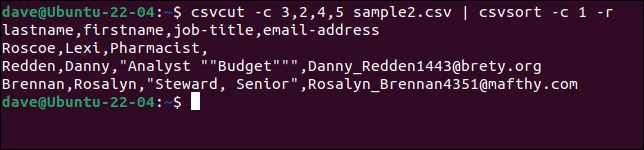
出力をよりきれいにするために、 csvlookを介してフィードできます。
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
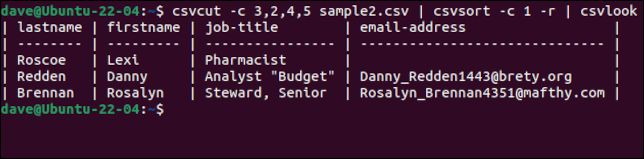
レコードがソートされていても、フィールド名を含むヘッダー行が最初の行として保持されるのは、ちょっとした工夫です。 希望どおりのデータが得られたら、コマンド チェーンからcsvlookを削除し、出力をファイルにリダイレクトして新しい CSV ファイルを作成します。
「sample2.file」にデータを追加し、 csvsortコマンドを削除して、「sample3.csv」という新しいファイルを作成しました。
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

CSV データを安全にサニタイズする方法
LibreOffice Calc で CSV ファイルを開くと、各フィールドがセルに配置されます。 検索と置換機能を使用してカンマを検索できます。 それらを「無」に置き換えて消えるようにすることも、CSV 解析に影響を与えない文字 (セミコロン「 ; 」など) に置き換えることもできます。 " 例えば。
引用されたフィールドを囲む引用符は表示されません。 表示される唯一の引用符は、フィールド データ内に埋め込まれた引用符です。 これらは一重引用符で示されます。 これらを検索して単一のアポストロフィ「 ' 」に置き換えると、CSV ファイル内の二重引用符が置き換えられます。
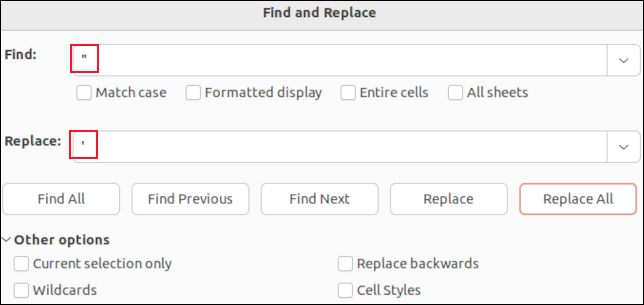
LibreOffice Calc のようなアプリケーションで検索と置換を行うと、誤ってフィールド区切りのカンマを削除したり、引用されたフィールドを囲む引用符を削除したりすることができなくなります。 フィールドのデータ値のみを変更します。
フィールド内のすべてのコンマをセミコロンで変更し、すべての埋め込み引用符をアポストロフィで変更して、変更を保存しました。
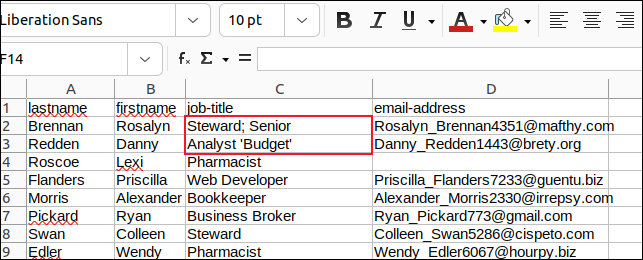
次に、「sample3.csv」を解析する「field3.sh」というスクリプトを作成しました。
#! /ビン/バッシュ while IFS="," read -r lastname firstname jobtitle email 行う echo "姓: $lastname" echo "名: $firstname" echo "役職: $jobtitle" echo "メールアドレス: $email" エコー "" done < <(tail -n +2 sample3.csv)
実行すると何が得られるか見てみましょう。
./field3.sh
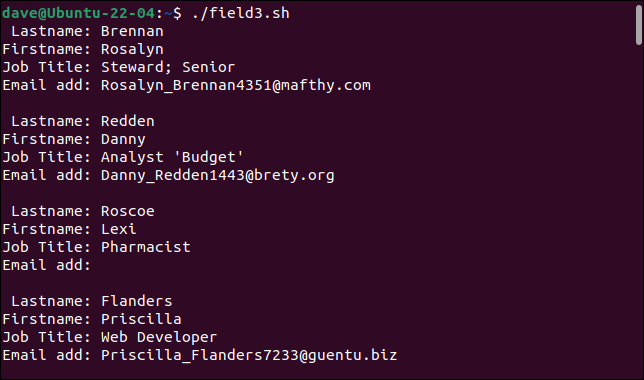
シンプルなパーサーは、これまで問題があったレコードを処理できるようになりました。
多くの CSV が表示されます
CSV は、間違いなく、アプリケーション データの共通言語に最も近いものです。 何らかの形式のデータを処理するほとんどのアプリケーションは、CSV のインポートとエクスポートをサポートしています。 現実的かつ実用的な方法で CSV を処理する方法を知っていれば、役に立ちます。
関連: Linux を使い始めるための 9 つの Bash スクリプトの例