
Linuxでディレクトリツリーをトラバースする方法
公開: 2022-07-21
Linuxのディレクトリを使用すると、ファイルを個別の個別のコレクションにグループ化できます。 欠点は、反復的なタスクを実行するためにディレクトリ間を移動するのが面倒になることです。 これを自動化する方法は次のとおりです。
ディレクトリのすべて
Linuxを紹介したときに最初に学ぶコマンドは、おそらくlsですが、 cdはそれほど遅れることはありません。 ディレクトリとその移動方法、特にネストされたサブディレクトリを理解することは、Linuxがそれ自体を編成する方法、および自分の作業をファイル、ディレクトリ、およびサブディレクトリに編成する方法を理解するための基本的な部分です。
ディレクトリツリーの概念と、それらの間を移動する方法を把握することは、Linuxの状況に慣れるために通過する多くの小さなマイルストーンの1つです。 パスを指定してcdを使用すると、そのディレクトリに移動します。 cd cd ~ようなショートカットは、それ自体でホームディレクトリに戻り、 cd ..はディレクトリツリーの1つ上のレベルに移動します。 単純。
ただし、ディレクトリツリーのすべてのディレクトリでコマンドを実行する同じように簡単な方法はありません。 その機能を実現する方法はいくつかありますが、その目的専用の標準的なLinuxコマンドはありません。
lsなどの一部のコマンドには、再帰的に動作するように強制するコマンドラインオプションがあります。つまり、1つのディレクトリから開始し、そのディレクトリの下のディレクトリツリー全体を系統的に処理します。 lsの場合、これは-R (再帰的)オプションです。
再帰をサポートしないコマンドを使用する必要がある場合は、再帰機能を自分で提供する必要があります。 その方法は次のとおりです。
関連:知っておくべき37の重要なLinuxコマンド
ツリーコマンド
treeコマンドは、当面のタスクには役立ちませんが、ディレクトリツリーの構造を簡単に確認できます。 ターミナルウィンドウにツリーを描画して、ディレクトリツリーを構成するディレクトリとサブディレクトリ、およびツリー内でのそれらの相対的な位置の概要を即座に取得できるようにします。
treeをインストールする必要があります。
Ubuntuでは、次のように入力する必要があります。
sudoaptインストールツリー

Fedoraでは、以下を使用します。
sudodnfインストールツリー

Manjaroでは、コマンドは次のとおりです。
sudo pacman -Sy tree

パラメータなしでtreeを使用すると、現在のディレクトリの下にツリーが描画されます。
木
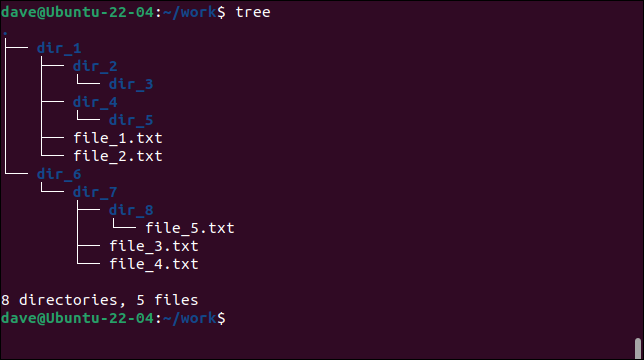
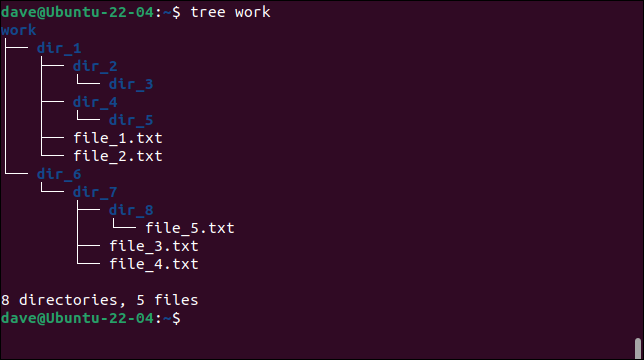
コマンドラインでtreeへのパスを渡すことができます。
木の仕事
-d (ディレクトリ)オプションはファイルを除外し、ディレクトリのみを表示します。
ツリー-d作業
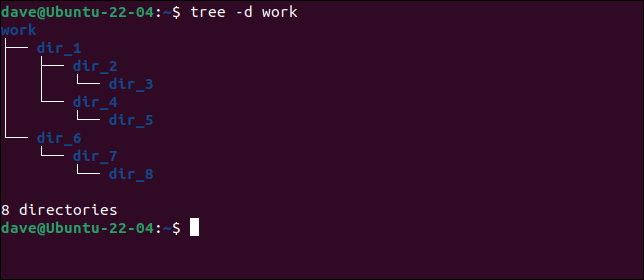
これは、ディレクトリツリーの構造を明確に把握するための最も便利な方法です。 ここに示されているディレクトリツリーは、次の例で使用されているものです。 5つのテキストファイルと8つのディレクトリがあります。
lsからトラバースディレクトリへの出力を解析しないでください
最初に考えたのは、 lsがディレクトリツリーを再帰的にトラバースできる場合、 lsを使用してそれを実行し、ディレクトリを解析してアクションを実行する他のコマンドに出力をパイプするのはなぜですか?
lsの出力を解析することは悪い習慣と見なされます。 Linuxでは、あらゆる種類の奇妙な文字を含むファイル名とディレクトリ名を作成できるため、一般的で普遍的に正しいパーサーを作成することは非常に困難になります。
これほど馬鹿げたディレクトリ名を故意に作成することは決してないかもしれませんが、スクリプトやアプリケーションの間違いはそうかもしれません。
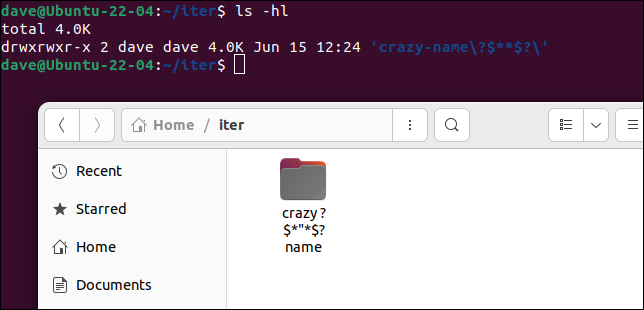
正当であるが十分に考慮されていないファイル名とディレクトリ名を解析すると、エラーが発生しやすくなります。 lsの出力の解釈に依存するよりも安全で、はるかに堅牢な、使用できる方法は他にもあります。
findコマンドの使用
findコマンドには再帰機能が組み込まれており、コマンドを実行する機能もあります。 これにより、強力なワンライナーを構築できます。 将来使用する可能性が高いものである場合は、ワンライナーをエイリアスまたはシェル関数に変えることができます。
このコマンドは、ディレクトリツリーを再帰的にループし、ディレクトリを探します。 ディレクトリが見つかるたびに、ディレクトリの名前が出力され、そのディレクトリ内で検索が繰り返されます。 1つのディレクトリの検索が完了すると、そのディレクトリを終了し、親ディレクトリで検索を再開します。
find work -type d -execdir echo "In:" {} \; 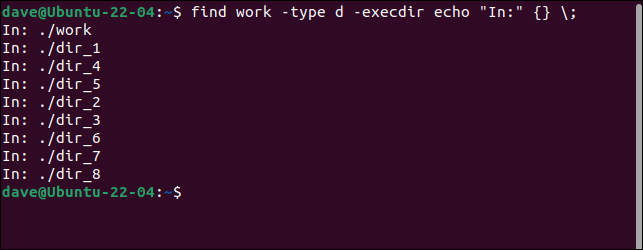
ディレクトリがリストされている順序、ツリー内での検索の進行状況を確認できます。 treeコマンドの出力をfind -linerの出力と比較すると、サブディレクトリのないディレクトリに到達するまで、findが各ディレクトリとサブディレクトリを順番に検索する方法findます。 次に、レベルを上げて、そのレベルで検索を再開します。
コマンドの構成は次のとおりです。
- find :
findコマンド。 - work :検索を開始するディレクトリ。これはパスにすることができます。
- -type d :ディレクトリを探しています。
- -execdir :見つかった各ディレクトリでコマンドを実行します。
- echo“ In:” {} :これはコマンドです。ディレクトリの名前をターミナルウィンドウにエコーしているだけです。 「{}」は、現在のディレクトリの名前を保持します。
- \; :これは、コマンドを終了するために使用されるセミコロンです。 Bashが直接解釈しないように、バックスラッシュでエスケープする必要があります。
わずかな変更を加えるだけで、検索の手がかりに一致するファイルをfindコマンドで返すことができます。 -nameオプションと検索の手がかりを含める必要があります。 この例では、「*。txt」に一致するテキストファイルを探し、その名前をターミナルウィンドウにエコーします。

find work -name "* .txt" -type f -execdir echo "Found:" {} \; 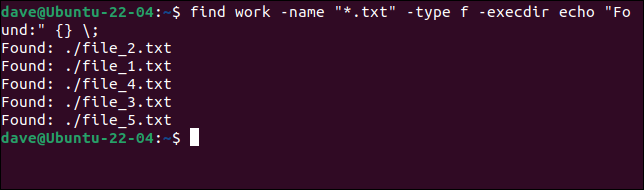
ファイルとディレクトリのどちらを検索するかは、何を達成したいかによって異なります。 各ディレクトリ内でコマンドを実行するには、 -type dを使用します。 一致する各ファイルに対してコマンドを実行するには、 -type fを使用します。
このコマンドは、開始ディレクトリとサブディレクトリ内のすべてのテキストファイルの行をカウントします。
作業を検索-name"*.txt" -type f -execdir wc -l {} \; 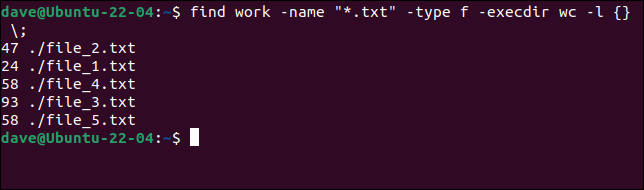
関連: Linuxでfindコマンドを使用する方法
スクリプトを使用したディレクトリツリーのトラバース
スクリプト内のディレクトリをトラバースする必要がある場合は、スクリプト内でfindコマンドを使用できます。 自分で再帰検索を実行する必要がある場合、または実行したい場合は、それも実行できます。
#!/ bin / bash
shopt -s dotglob nullglob
関数再帰{
ローカルcurrent_dirdir_or_file
$1のcurrent_dirの場合; 行う
echo "次のディレクトリコマンド:" $ current_dir
"$ current_dir"/*のdir_or_fileの場合; 行う
if [[-d $ dir_or_file]]; それから
再帰的な「$dir_or_file」
そうしないと
wc $ dir_or_file
fi
終わり
終わり
}
再帰的な「$1」 テキストをエディターにコピーして「recurse.sh」として保存し、 chmodコマンドを使用して実行可能にします。
chmod + x recurse.sh

スクリプトは、 dotglobとnullglobの2つのシェルオプションを設定します。
dotglob設定は、ピリオド「。」で始まるファイル名とディレクトリ名を意味します. ワイルドカード検索用語が展開されると、」が返されます。 これは事実上、検索結果に隠しファイルと隠しディレクトリを含めることを意味します。
nullglob設定は、結果が見つからない検索パターンが空またはnull文字列として扱われることを意味します。 デフォルトでは検索語自体にはなりません。 つまり、アスタリスクのワイルドカード「 * 」を使用してディレクトリ内のすべてを検索しているが、結果がない場合、アスタリスクを含む文字列の代わりにnull文字列を受け取ります。 これにより、スクリプトが誤って「*」というディレクトリを開こうとしたり、「*」をファイル名として扱ったりするのを防ぐことができます。
次に、 recursiveと呼ばれる関数を定義します。 ここで面白いことが起こります。
current_dirおよびdir_or_fileと呼ばれる2つの変数が宣言されています。 これらはローカル変数であり、関数内でのみ参照できます。
$1と呼ばれる変数も関数内で使用されます。 これは、関数が呼び出されたときに関数に渡される最初の(そして唯一の)パラメーターです。

スクリプトは2つforループを使用し、一方は他方の中にネストされています。 最初の(外側の) forループは、2つの目的で使用されます。
1つは、各ディレクトリで実行したいコマンドを実行することです。 ここで行っているのは、ディレクトリの名前をターミナルウィンドウにエコーすることだけです。 もちろん、任意のコマンドまたは一連のコマンドを使用したり、別のスクリプト関数を呼び出したりすることもできます。
外側のforループが行う2番目のことは、検出できるすべてのファイルシステムオブジェクト(ファイルまたはディレクトリ)をチェックすることです。 これが内部forループの目的です。 次に、各ファイルまたはディレクトリ名がdir_or_file変数に渡されます。
次に、 dir_or_file変数がifステートメントでテストされ、ディレクトリであるかどうかが確認されます。
- そうである場合、関数はそれ自体を呼び出し、ディレクトリの名前をパラメータとして渡します。
-
dir_or_file変数がディレクトリでない場合は、ファイルである必要があります。 ファイルに適用したいコマンドは、ifステートメントのelse句から呼び出すことができます。 同じスクリプト内で別の関数を呼び出すこともできます。
スクリプトの最後の行はrecursive関数を呼び出し、最初のコマンドラインパラメーター$1を検索の開始ディレクトリとして渡します。これにより、プロセス全体が開始されます。
スクリプトを実行してみましょう。
./recurse.sh作業

ディレクトリがトラバースされ、各ディレクトリでコマンドが実行されるスクリプト内のポイントは、「Directory commandfor:」行で示されます。 見つかったファイルでは、行、単語、文字をカウントするためにwcコマンドが実行されます。
処理される最初のディレクトリは「作業」であり、その後にツリーのネストされたディレクトリブランチが続きます。
注意すべき興味深い点は、ディレクトリ固有のコマンドを内側のforループの上から下に移動することで、ディレクトリが処理される順序を変更できることです。
「Directorycommandfor:」行を、内側forループのdone後に移動してみましょう。
#!/ bin / bash
shopt -s dotglob nullglob
関数再帰{
ローカルcurrent_dirdir_or_file
$1のcurrent_dirの場合; 行う
"$ current_dir"/*のdir_or_fileの場合; 行う
if [[-d $ dir_or_file]]; それから
再帰的な「$dir_or_file」
そうしないと
wc $ dir_or_file
fi
終わり
echo "次のディレクトリコマンド:" $ current_dir
終わり
}
再帰的な「$1」次に、スクリプトをもう一度実行します。
./recurse.sh作業
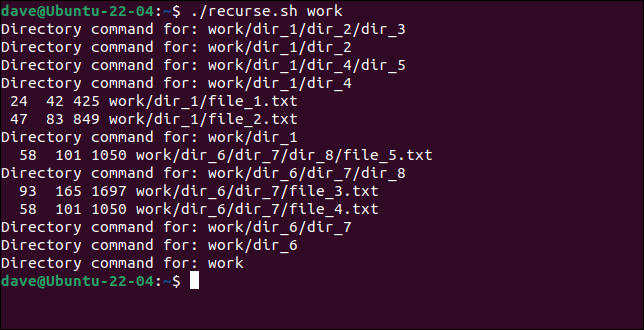
今回は、ディレクトリに最初に最も深いレベルからコマンドが適用され、ツリーのブランチをバックアップします。 スクリプトにパラメータとして渡されたディレクトリは最後に処理されます。
より深いディレクトリを最初に処理することが重要な場合は、これがその方法です。
再帰は奇妙です
これは、自分の電話で自分に電話をかけ、次に会うときに自分に伝えるメッセージを繰り返し残すようなものです。
その利点を理解するまでには多少の努力が必要ですが、理解すると、難しい問題に取り組むためのプログラム的にエレガントな方法であることがわかります。
関連:プログラミングにおける再帰とは何ですか、そしてそれをどのように使用しますか?