
LinuxでSQLite用のDBブラウザを使用する方法
公開: 2022-01-29
DB Browser for SQLiteを使用すると、LinuxでSQLiteデータベースを表示および編集できます。 これらのデータベースファイルを設計、作成、編集したり、他のアプリケーションの内部動作を確認したりできます。 このSQLiteGUIの使用方法は次のとおりです。
SQLiteデータベースプロジェクト
SQLiteデータベースライブラリとツールは、驚異的に成功したオープンソースの構造化クエリ言語(SQL)データベースプロジェクトです。 実際、非常に成功しているため、世界で最も広く展開されているデータベースエンジンと自称することができます。
2000年の最初のリリース以来、SQLiteは絶対に驚異的な普及を遂げてきました。 これは、すべてのiPhoneとAndroidの電話、およびWindows10またはMacコンピューターの内部にあります。 また、Chrome、Firefox、Safari、その他の無数のアプリケーションを含むすべてのインターネットブラウザに搭載されています。
SQLiteデータベースの驚異的な到達範囲は、そのアーキテクチャによるものです。 これは、他のアプリケーションに組み込まれている(または開発者の話ではリンクされている)高速で軽量のライブラリです。 データベースエンジンは、製品の不可欠な部分になります。 これは、MySQL、MariaDB、Microsoft SQLServerなどの外部SQLデータベースサーバーを提供する必要がないことを意味します。
SQLiteにはデータベースを操作するためのコマンドラインツールもありますが、それを成功に導いたのはライブラリです。 有能な自己完結型のデータベースエンジンをアプリケーション内に収納することで、多くの問題を取り除くことができます。 これにより、アプリケーションのインストールルーチンが簡素化され、アプリケーションの最小ハードウェア要件が低くなります。
さらに、SQLiteはデータベーステーブル、インデックス、およびスキーマに単一のクロスプラットフォームファイルを使用するため、データベース全体を別のコンピューターに移動できます。 1つのファイルをコピーすることで、別のオペレーティングシステムを実行しているマシンに移動することもできます。
実際、SQLiteのデータベースファイル形式は非常に高く評価されており、米国議会図書館が長期的なデータストレージとして推奨している数少ないものの1つです。
ただし、SQLiteは開発者向けのライブラリであるため、そのフロントエンドはありません。つまり、グラフィカルユーザーインターフェイスがありません。 ユーザーインターフェイスを提供するのは、ライブラリを使用するアプリケーションです。 コマンドラインユーティリティはインタラクティブモードで実行できますが、それでもGUIではありません。
SQLite用のDBブラウザ(DB4S)は、この法案にうまく適合します。 これは、GUI内からSQLiteデータベースを作成および操作できるようにするために、別のオープンソースプロジェクトによって開発されたビジュアルツールです。
SQLite用のDBブラウザ
DB Browser for SQLiteは、2003年から登場しており、いくつかの名前が変更されています。 以前はSQLiteブラウザと呼ばれていましたが、混乱を招きました。 人々はそれがSQLiteチームによって書かれたと思っていたので、DB4Sに関する機能リクエストとサポートクエリをSQLiteに転送していました。
そのため、SQLiteBrowserはSQLiteのDBBrowserに名前が変更されました。 あなたはまだあちこちで古い名前への参照を見るでしょう。 実際、プロジェクトのWebサイトでは、ドメインとして「sqlitebrowser」が引き続き使用されており、DB4Sのインストール時に古い名前も使用されます。
DB4Sを使用すると、次のことができます。
- データベースを作成します。
- データベーススキーマ、テーブル、およびデータをSQL形式でインポートおよびエクスポートします。
- テーブルとデータをCSV形式でインポートおよびエクスポートします。
- テーブルとインデックスを作成、編集、および削除します。
- レコードを追加、編集、および削除します。
- データベースレコードを参照および検索します。
- SQLコマンドを編集して実行します。 SQLをアプリケーションにハードコーディングする前に、コマンドが意図したとおりに動作することを確認できます。
SQLite用のDBブラウザのインストール
UbuntuにDB4Sをインストールするには、次のコマンドを使用します(ここでも、インストールでは古い名前が使用されていることに注意してください)。
sudo apt-get install sqlitebrowser

Fedoraでは、次のように入力します。
sudo dnf install sqlitebrowser

Manjaroでは、 pacmanを使用しています:
sudo pacman -Sy sqlitebrowser

SQLファイルからのデータベースのインポート
DB4Sの起動時には、データベースがロードされていません。 データとデータベーステーブルの両方の定義をインポートする2つの方法と、独自のデータベースを作成する方法について説明します。
場合によっては、SQL形式のデータベースダンプファイルが提供または送信されることがあります。 これには、データベースを再作成し、そのデータをデータベースに挿入するために必要な手順が含まれています。
テーブル定義とデータのインポートに使用されるもう1つの一般的な形式は、コンマ区切り値(CSV)形式です。 データベーステストデータなどのデータ生成サイトを使用して、練習用のダミーデータを生成できます。 その後、データをSQLまたはCSVとしてエクスポートできます。
以下は、そのサイトで作成したSQLファイルです。 エクスポート後、編集してファイルの先頭に行を追加しました。これはSQLiteに必要です。
トランザクションの開始;
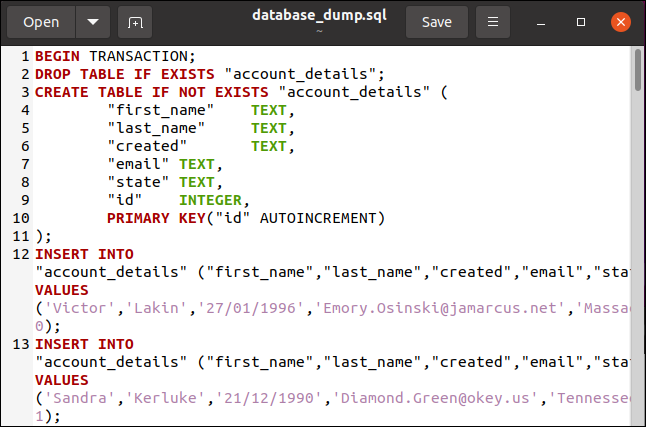
次に、ファイルを保存しました。 DB4Sでは、[ファイル]> [インポート]> [SQLファイルからのデータベース]をクリックします。
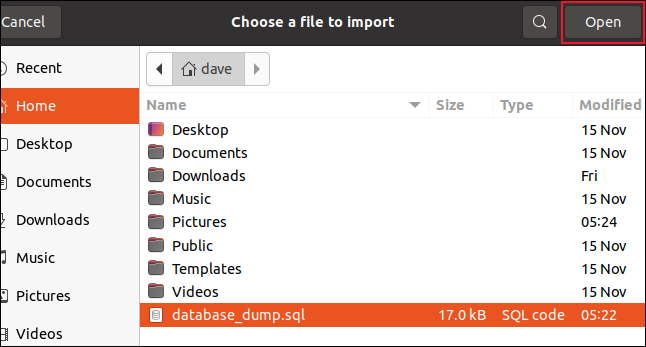
ファイル選択ダイアログが開き、SQLファイルを選択できます。 この例では、「database_dump.sql」と呼ばれ、ホームディレクトリのルートにあります。
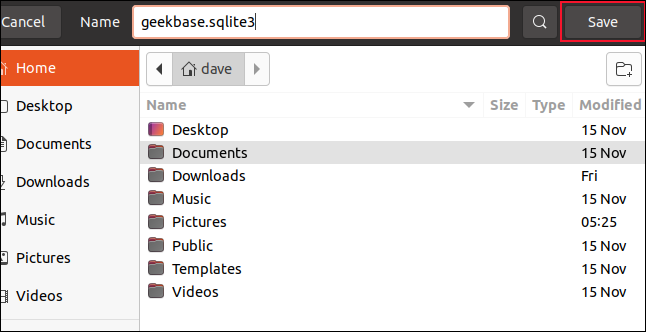
ファイルを選択した状態で「開く」をクリックすると、ファイル保存ダイアログが開きます。 ここで、新しいデータベースに名前を付けて、保存する場所を決定する必要があります。 これを「geekbase.sqlite3」と呼び、ホームディレクトリに保存しています。
続行する準備ができたら、[保存]をクリックします。 ソースSQLファイルを特定し、新しいデータベースに名前を付けたので、インポートプロセスを開始できます。 完了すると、以下の通知ダイアログが表示されます。
データベースにテーブルとデータを追加したので、それらの変更を保存するように求められます。そのため、[保存]をクリックして保存します。
メインのDB4Sウィンドウに、データベースの構造が表示されます。
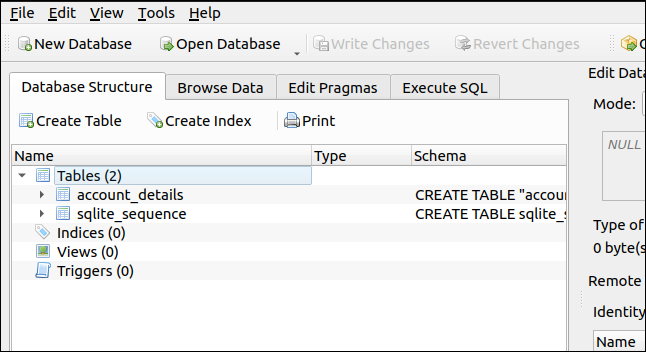
SQLファイルには1つの定義しかありませんでしたが、2つのテーブルが作成されました。 これは、「id」フィールドが自動インクリメントフィールドとして定義されているためです。 新しいレコードがデータベースに追加されるたびに、自動的に追加されます。 SQLiteは、自動インクリメントフィールドを追跡するためのテーブルを作成します。
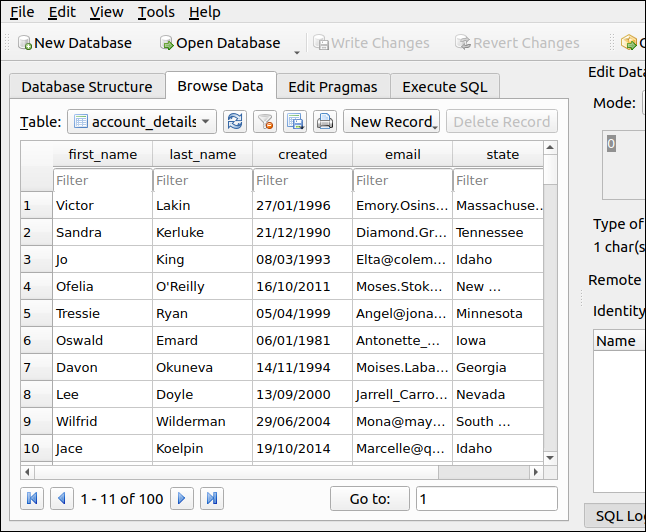
「データの参照」タブをクリックして、新しく追加されたレコードを表示します。
もちろん、データベースの力は、レコードを検索して抽出する機能にあります。 SQL対応のデータベースでは、SQL言語を使用してこれを行います。 開始するには、「SQLの実行」タブ。
![SQLite用DBブラウザの[SQLの実行]タブ](/uploads/article/3060/6h6Jj4i030QdpMua.png)
次のSQLコマンドを追加しました。
SELECT * FROM account_details WHERE last_name LIKE "%ll%" ORDERBY状態
これにより、姓に二重の「l」が含まれる人が検索され、結果は州ごとに並べ替えられます。 青い矢印(「再生」ボタンのように見えます)をクリックして、SQLコマンドを実行します。 結果は下のペインに表示されます。
姓に二重の「l」が含まれる4つのレコードがあり、アリゾナからウィスコンシンまで、州ごとにアルファベット順に並べ替えられています。
CSVファイルからのデータベーステーブルのインポート
適切なCSVファイルからテーブルをインポートすることもできます。 これを行う最も便利な方法は、CSVファイルのテーブルフィールド名をテキストの最初の行にすることです。 以下は、CSVファイルの短いセクションです。
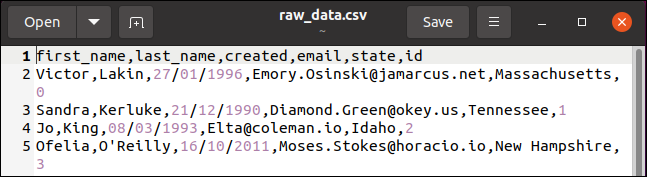
最初の行には、フィールド名(first_name、last_name、created、email、state、およびID)が含まれています。 他の行は、テーブルに追加される各レコードのデータ値を保持します。 これは以前と同じデータです。 ファイル形式のみが変更されました。
CSVデータをインポートするときは、空のデータベースを作成して、インポート先のデータベースを作成する必要があります。 これを行うには、ツールバーの「新しいデータベース」をクリックします。

ファイル保存ダイアログが開きます。 新しいデータベースに名前を付けて、保存する場所を決定します。 これを「howtogeek.sqlite3」と呼び、ホームディレクトリに保存します。
「テーブル定義の編集」ダイアログが表示されたら、「キャンセル」をクリックします。 DB4Sのメインウィンドウに戻り、[ファイル]> [インポート]> [CSVファイルからのテーブル]をクリックします。 CSVファイルを選択できるファイル選択ダイアログが開きます。
この例では、「users.csv」と呼ばれ、ホームディレクトリのルートにあります。 [開く]をクリックすると、プレビューダイアログが表示され、DB4SがCSVデータをどのように解釈するかが示されます。
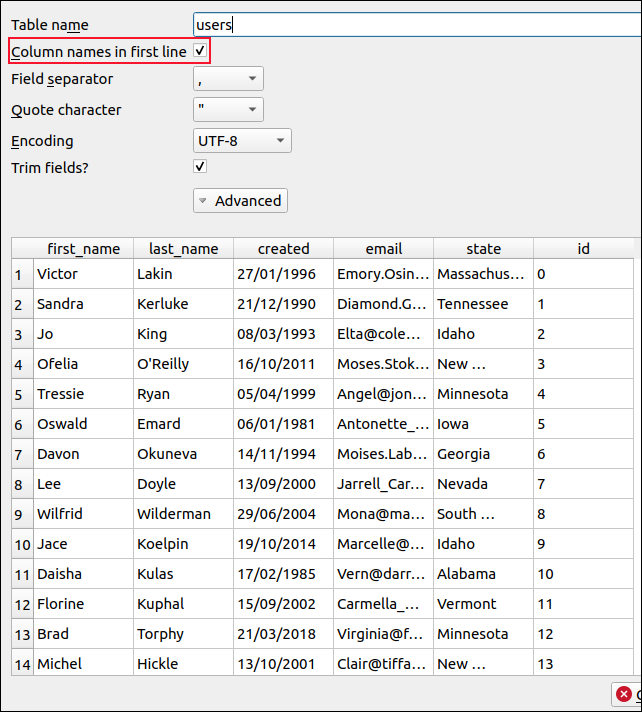
ファイルの名前は、テーブルの名前として使用されます。 必要に応じてこれを編集できます。必ず「最初の行の列名」の横にあるチェックボックスを選択してください。
「OK」をクリックします(上の画像では画面外です)。 データがインポートされ、問題がなければ「インポートが完了しました」ダイアログが表示されます。 「OK」をクリックします。
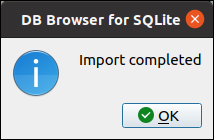
「データの参照」をクリックすると、インポートされたデータが表示されます。
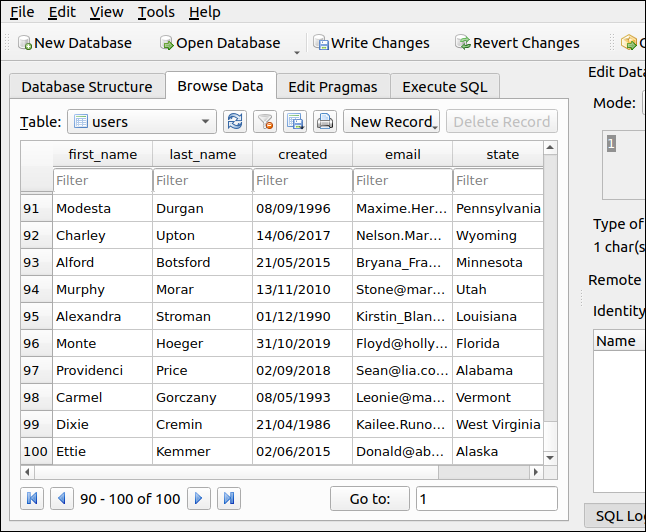
ただし、まだ微調整が必要です。 「データベース構造」タブをクリックし、テーブルの名前を選択してから、ツールバーの「テーブルの変更」をクリックします。
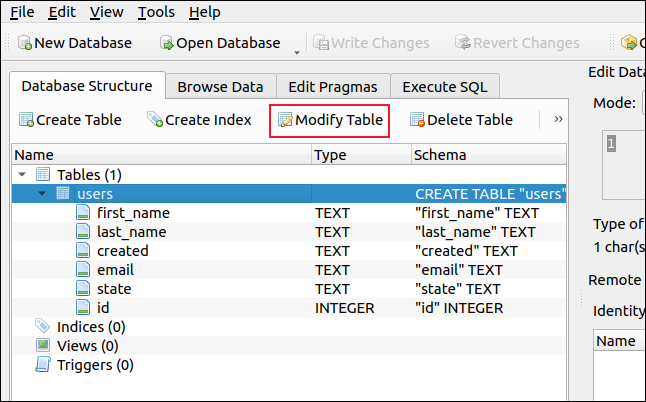
「テーブル定義の編集」ダイアログで、「id」フィールドの「AI」(自動インクリメント)チェックボックスを選択します。
![SQLite用のDBブラウザの[テーブル定義の編集]ダイアログ](/uploads/article/3060/vcJa7GvhPyPmhp3z.png)
「PK」(主キー)チェックボックスが自動的に選択されます。 「OK」をクリックします。 これにより、「id」フィールドが自動インクリメントされるように設定されます。 これで、データベースに新しいレコードを追加して、データベースが機能していることを確認できます。
[SQLの実行]タブをクリックし、上部ペインに次のSQLを入力します(「id」を除くすべてのフィールドに値を指定していることに注意してください)。
INSERT INTO "users" ( "first_name"、 "last_name"、 "created"、 "email"、 "state") 値(「Dave」、「McKay」、「12/08/2020」、「[email protected]」、「Idaho」);
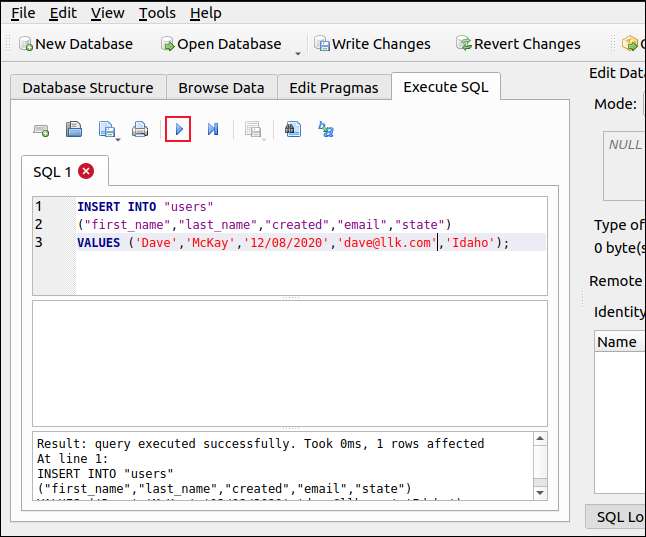
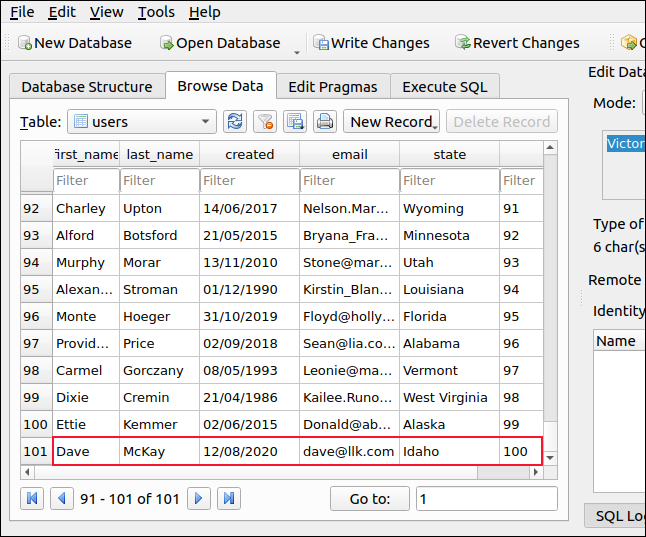
青い矢印([再生]ボタンのように見えます)をクリックして、SQLコマンドを実行します。 「データの参照」をクリックして、一番下までスクロールします。 以前の最高の「id」値よりも1つ高い値を保持する、自動的に提供された「id」フィールドを含む、新しく追加されたレコードが表示されます。
データベースを手動で作成する
インポートするSQLまたはCVSファイルがない場合は、データベースを手動で作成する必要があります。 開始するには、「新しいデータベース」をクリックすると、ファイル保存ダイアログが表示されます。 新しいデータベースの名前と保存する場所を入力します。
「geeksrock.sqlite3」という名前を付けて、「Documents」ディレクトリに保存しています。 データベースに名前を付けて保存する場所に移動したら、[保存]をクリックします。
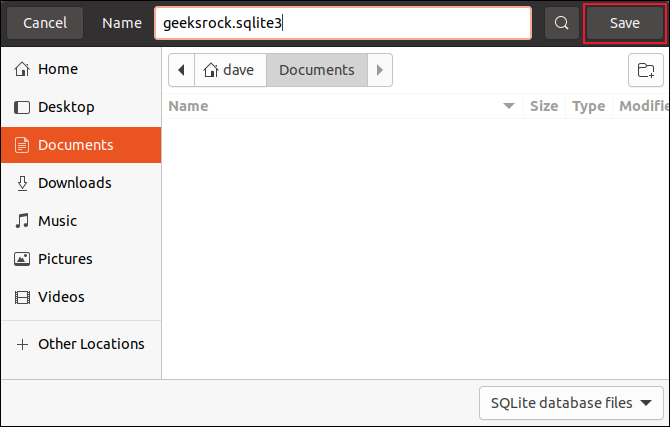
選択内容の確認を求められたら、もう一度「保存」をクリックします。
![SQLite用のDBブラウザの[確認の保存]ダイアログ](/uploads/article/3060/JYpd9ub0IZ7Cc2fq.png)
「テーブル定義の編集」ダイアログが表示されます。 新しいテーブルに名前を付け(これを「イーグル」と呼びます)、[フィールドの追加]をクリックします。 これで、フィールドの名前を入力し、「タイプ」ドロップダウンメニューからフィールドに含まれる情報のタイプを選択できます。
![[テーブル定義の編集]ダイアログDBBrowser for SQLite](/uploads/article/3060/m1cIHe2wIz0pbEjf.png)
ワシの名前を保持するためのテキストフィールドと、翼幅を保持するための実際の(浮動小数点)数値フィールドを追加しました。
![SQLite用の新しいテーブルDBブラウザに2つのフィールドが追加された[テーブル定義の編集]ダイアログ](/uploads/article/3060/hivmgvLaddyDUg1r.png)
各フィールドの横にあるチェックボックスとその他のオプションを使用すると、次の動作を追加できます。
- NN(Null以外):このオプションが設定されている場合、フィールドを空のままにすることはできません。 このフィールドに値を指定せずにレコードを追加しようとすると、拒否されます。
- PK (主キー):テーブル内のレコードに一意の識別子を提供するフィールド(またはフィールドのグループ)。 これは、上記で説明した自動インクリメント整数フィールドのような単純な数値である可能性があります。 ただし、ユーザーアカウントのテーブルでは、ユーザー名である可能性があります。 テーブルには主キーを1つだけ含めることができます。
- AI (自動インクリメント):数値フィールドに、次に高い未使用の値を自動的に入力できます。 上記の例の「id」フィールドでこれを使用しました。
- U(一意):各レコードのこのフィールドは一意の値を保持する必要があります。つまり、テーブルのこのフィールドに重複はありません。
- デフォルト:このフィールドに値がないレコードが追加された場合、デフォルト値が提供されます。
- チェック:レコードが追加されたときに、フィールドでチェックを実行できます。 たとえば、電話番号フィールドの値が10文字以上であることを確認できます。
- 照合: Sqliteは文字列比較のさまざまな方法を使用できます。 デフォルトは
BINARYです。 他のオプションは、大文字と小文字を区別しないNOCASE、および末尾の空白を無視するRTRIMです。 ほとんどの場合、これはデフォルト値のままにしておくことができます。 - 外部キー:別のテーブルのキーと一致する必要があるレコード内のフィールドまたはフィールドのグループ。 たとえば、ワークショップツールのデータベースに、個々のツールのテーブルとツールカテゴリの別のテーブルがあるとします。 ツールカテゴリが「ハンマー」、「スパナ」、「ドライバー」の場合、「チゼル」タイプのレコードを追加することはできません。
必要なフィールドを追加したら、「OK」をクリックします。 データベースが作成され、最初のテーブルが追加されたら、いくつかのレコードを追加できます。
[SQLの実行]タブでは、SQL INSERTステートメントを数回使用して、テーブルにいくつかのレコードを追加しました。
![DB Browser forSQLiteの[ExecuteSQL]タブにあるINSERTSQLステートメント](/uploads/article/3060/YCkwmTSmwosOQZkn.png)
[データの参照]タブを使用して、新しいレコードを表示することもできます。
![新しいレコードがリストされた[データの参照]タブDBBrowser for SQLite](/uploads/article/3060/NSp93KfMEdd8flQo.png)
ユーザーインターフェイスから新しいレコードを追加する場合は、ツールバーの[新しいレコード]をクリックします。 その後、SQLを理解していなくても、新しいレコードの値を入力できます。
他のアプリケーションのデータベース
DB4Sを使用して、他のアプリケーションに属するSQLiteデータベースを表示することもできます。 他のデータベースの構造や内容を調べることは、有益である(または単に興味深い)場合があります。 ただし、他のアプリケーションが所有するデータベースに変更を加えないことが重要です。変更を加えると、そのアプリケーションの動作に悪影響を与える可能性があります。
Firefoxが作成および維持しているSQLiteデータベースの1つを見てみましょう。 ツールバーの「データベースを開く」をクリックすると、ファイルを開くダイアログが表示されます。 Firefoxは、ホームディレクトリにある「.mozilla」という隠しディレクトリ内にある「firefox」というディレクトリにファイルを保持します。
テストマシンでは、FirefoxSQLiteデータベースが次の場所にあります。「home / dave / .mozilla / firefox /vpvuy438.default-release」; あなたも同様の場所にいます。
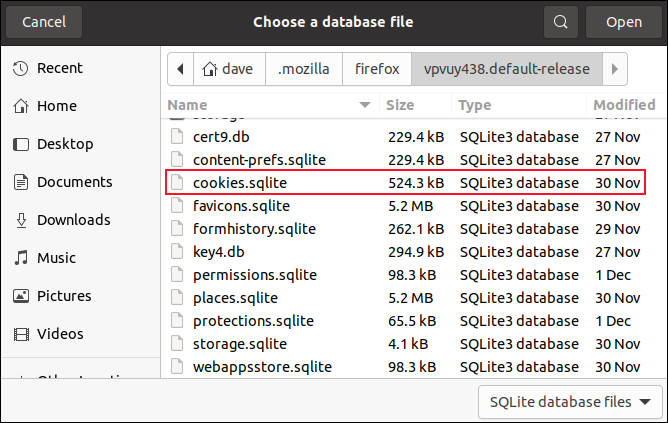
「cookies.sqlite」データベースを開くので、ファイルを強調表示して、「開く」をクリックします。 データベースを開くと、そのテーブル構造、フィールド定義、およびデータを調べることができます。
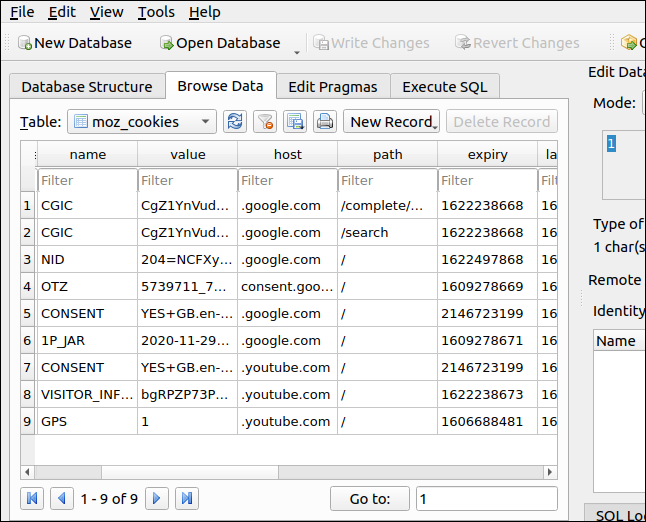
ここでは、さまざまなGoogleおよびYouTubeのCookieを確認できます。
エクスポートは洞察を提供します
データベースのエクスポート([ファイル]> [エクスポート]> [SQLファイルへのデータベース]をクリックして)も役立ちます。 データベースのSQLダンプを見ると、SQLステートメントでレンダリングされたデータベースのスキーマ全体を確認できます。