
AI アート ジェネレーターから画像を保護する方法
公開: 2023-03-24
- HaveIBeenTrained.com などのツールを使用して、トレーニング データセットをオプトアウトします。
- 「robots.txt」ファイルを使用して、Web クローラーを回避します。その多くは、最初にデータセットを作成するために使用されます。
- アートワークの著作権を取得し、法廷でこれらのツールの開発者に異議を唱えます (または、既存の集団訴訟に参加してください)。
- 積極的に透かしを入れた画像のみをアップロードしてください。
- そもそもアートをインターネットに掲載することは避けてください。
AI アート ジェネレーターは、人間の創造性を真似することはできないかもしれませんが、確実にあなたをだますことができます。 これは、アーティストにとっても AI の乗っ取りを恐れる人々にとっても心配なことですが、すべてが失われるわけではありません。
著作権で保護されたアートを AI から保護する方法
AI アート ジェネレーターは、トレーニングされたデータセットなしでは何もありません。 これには、既存のアートワークの膨大なサンプルを取得し、人間が自然言語プロンプトを使用して同様のアートワークを作成できるように文脈化することが含まれます。 OpenAI の DALL-E 2 や Midjourney などのジェネレーティブ アート アプリを使用して、自分で試すことができます。
DALL-E 2 に「パブロ ピカソ スタイルのセサミ ストリートのエルモの写真」を作成するように依頼したところ、得られたものは次のとおりです (はい、これが最高の写真でした)。

死んだアーティストのスタイルでアートワークを作成できることは、特に非常に認識可能なスタイルでは、それほど多くの警告ベルを鳴らさないかもしれません. しかし、ArtStation、DeviantArt、Behance、個人の Web サイト、Instagram や Facebook などのソーシャル メディア ページで自分の作品を共有している現代のアーティストにとっては、はるかに心配なことです。
では、自分よりもはるかに速く創作物を吐き出す AI の訓練に自分の創作物が使用されないようにするには、どうすればよいでしょうか?
トレーニング データセットのオプトアウト
HaveIBeenTrained.com を使用して、インターネット上で最大のオープンな画像トレーニング データセットの 2 つ、LAION-400M と LAION-5B をオプトアウトすることを選択できます。 これらのデータセットは、Stable Diffusion や Google Imagen など、ウェブ上で最大の画像ジェネレーターによって使用されています。 それらは真にオープンであるため、他の多くのジェネレーティブ AI ツールでも使用されています。
残念ながら、これを行うプロセスは遅くて退屈です。 最初にアカウントにサインアップしてから、画像を検索またはアップロードして、データセット内で一致するものを見つける必要があります。 次に、デスクトップ Web ブラウザーで画像を右クリックし、[マイ オプトアウトに追加] オプションを選択します。 または、代わりに [マイ オプトインに追加] をクリックして、データセットに画像を使用する明示的な許可を与えることができます。
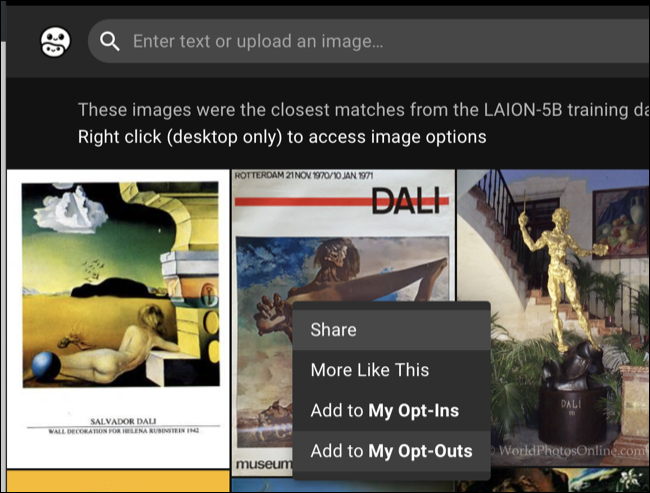
見つけた画像ごとにこれを行う必要があるため、大量の作品を扱うアーティストの場合、骨の折れるプロセスになる可能性があります。 現実的にどれくらいの時間がかかるかは、最終的にあなたの仕事をどれだけ簡単に除外できるかによって異なります。これは、ユニークな名前やプロジェクト、オンラインでの大規模なフォロワーなどに関連する仕事がある場合は簡単かもしれません.
これら 2 つの大規模なデータセットは出発点として最適ですが、使用されているのはこれらだけではありません。 個人は独自のデータセットを作成でき、特定のアーティストやアート スタイルを再現するために作成する人もいます。 OpenAI のような一部の企業は、自社のツールがどのデータセットを使用しているかをまったく開示していないため、これらに対抗する方法はありません。
Robots.txt を使用してクローラーを追い払う
robots.txt ファイルは、Web クローラーに移動を許可または禁止する場所を伝えるために、Web サイトのルート ディレクトリに配置される小さなテキスト ドキュメントです。 Google は「これは Web ページを Google から除外するためのメカニズムではありません」と明示的に述べていますが、自分の Web サイトでホストしている場合は、アートワークから Web クローラーを遠ざけるために使用することをお勧めします。
名前が示すように、Web クローラーはインデックス作成用のコンテンツを探して Web をクロールします。 クローラーは検索エンジンだけではありません。クローラーは、前述の LAION-400M および LAION-5B データセットのようなデータセットの作成にも使用されます。 robots.txt の主な問題は、リクエストを尊重する Web クローラーに依存していることです。
最大のデータセットの 1 つは Common Crawl であり、そのデータは LAION のデータセットの構築に使用されています。 Web をクロールするプロセスは進行中です。LAION は、現在 (執筆時点) の LAION-400M データセットが「2014 年から 2021 年の間にクロールされたランダムな Web ページから」作成されたと述べています。
Common Crawl は、コンテンツのブロックとクロールの遅延 (帯域幅を節約するため) の両方に関して、robots.txt と Robots Exclusion Protocol を尊重すると述べています。 これを行うには、Robots.txt ファイルで「CCBot」ユーザー エージェントのルールを作成します。 もちろん、アートワークを自己ホストしていない場合、これは役に立ちません。
Google 検索セントラルには、robots.txt ファイルを作成するための便利なガイドがあります。または、Ryte の Robots.txt Generator などの Web サイトを使用して作成することもできます。 特定のディレクトリからの特定のユーザー エージェントを許可または無効にするか、ワイルドカード (*) を使用してすべてをブロックすることができます。 たとえば、/images/ ディレクトリ内のすべてのファイルを Common Crawl からブロックする一方で、他のクローラーが Web サイトをインデックスに登録できるようにする robots.txt ファイルは、次のようになります。
ユーザーエージェント: CCbot 許可しない: /images/ ユーザーエージェント: * 許可する: / サイトマップ: https://www.example.com/sitemap.xml
これにより、既に Web サイトにアクセスしたクローラーが無効になることはありませんが、今後、Common Crawl が /images/ フォルダー (および最後のクロール以降の新しいアップロード) にインデックスを作成するのを防ぐ必要があります。
アートワークの著作権
著作権はあなたが作成した作品に暗示されていますが、あなたの作品を著作権で保護するために努力することも、努力する価値があるかもしれません. 米国では、作品を Copyright.gov に登録することでこれを行うことができます。 1回の応募で未発表作品10点まで応募できますが、作品の処理には時間がかかる場合があります(現時点では約1年)。
自分の作品の著作権を登録すると、法廷が関係する問題でより多くの立場を確立できます。 これが、Stability AI (Stable Diffusion および DreamStudio の開発者であり、LAION の資金提供者)、DeviantArt (アーティストのためのプラットフォームであり、DreamUp の開発者)、および影響を受けたアーティストに代わってジェネレーティブ アート アプリである Midjourney に対して提起された集団訴訟の背後にある考えです。 .

StableDiffusionLitigation.com で訴訟のすべてを読むことができます。あなたの作品がこれらのジェネレーターのトレーニングに使用されていると思われる場合は、法務チームに連絡して集団訴訟に参加する根拠があるかもしれません. このルートをたどりたい場合は、アートを米国著作権局に登録するために申請することが重要な最初のステップです。
著作権侵害、脱獄、ファイル共有など、過去に弁護士を惹きつけた他の慣行と同様に、訴訟によってこの慣行が完全に停止されることはまずありません。 弁護側は、これらのツールが一般向けの Web サイトから収集された「フェアユース」の資料に基づいて訓練されていると主張する可能性があります。 このような訴訟があった場合、どのような影響があるかを見極める必要があります。
積極的な透かし
積極的または境界的な自己破壊的な透かしが存在するアートワークのみをアップロードした場合、データセットに含まれるアートワークにはこれが反映されます。 最終的に、これはアートワークが最初にアップロードされた理由に大きく依存します。 インターネットを楽しむために非営利でアートワークを作成している場合、これは最終的に自滅的なように思えます。

ただし、実際の絵画を販売していて、販売前にオンラインで展示する手段が必要な場合は、多少役立つ場合があります. それは確かに完成したアートワークを損なうことになるので、それはあなた自身で検討しなければならないものです.
アートをインターネットにアップロードしないでください
これはばかげているように聞こえるかもしれませんが (実際にそうです)、アートワークが最初からインターネットにアップロードされていなければ、ネットでキャッチされて AI のトレーニングに使用される可能性はありません。 もちろん、インターネットを使用してアートワークを共有せずにアーティストとして生計を立てることは、ほぼ不可能かもしれません (特にデジタル メディアで作業している場合)。
音楽に取り組むアーティストにとって、これは不可能なことです。 油彩や水彩画などの従来の素材を使用したとしても、誰かが完成した作品の写真を撮ってアップロードするかどうかはわかりません。
AIアートは著作権で保護されますか?
ジェネレーティブ AI の出力が著作権で保護されるかどうかという問題は複雑です。 一般的に受け入れられていることの 1 つは、アートを生成するために使用される AI ツールが出力に対する権利を持っていることはめったにないということです。
これは、Stable Diffusion を含むほとんどのツールのサービス条件に明確に記載されています。
ここに記載されている場合を除き、ライセンサーは、お客様がモデルを使用して生成した出力に対していかなる権利も主張しません。 あなたは、生成したアウトプットとその後の使用について責任を負います。 出力の使用は、ライセンスに記載されている規定に違反することはできません。
このライセンスは、著作権法を含む「該当する国、連邦、州、地方、または国際法または規制に違反する」使用を禁止しています。
途中:
あなたは、現在の法律の下で可能な範囲で、サービスを使用して作成したすべての資産を所有します。 これにより、元のアセット作成者が引き続き所有する他の画像のアップスケーリングは除外されます。
そして OpenAI (DALL-E 2):
当事者間で、適用法で許可される範囲で、お客様はすべてのインプットを所有し、お客様が本規約を遵守することを条件として、OpenAI はここに、アウトプットに対するすべての権利、権原、利益をお客様に譲渡します。
このようなツールで作成したすべての著作権に関して、米国著作権局は、著作権は人間が作成したアートにのみ適用されると述べています (独創性などの他の要件と共に)。
人間以外の著作者であると主張された場合、控訴裁判所は、著作権が主張された作品を保護しないことを発見しました。
法律は常に進化しているため、これは将来的に首尾よく挑戦される可能性があります。 また、AI ジェネレーターの製品ではない最終製品の要素 (プロットやダイアログなど) は、他の要素 (アートワークや音楽など) が著作権で保護されていなくても、著作権で保護される可能性があることにも注意してください。
AI Art Generator は私の著作権で保護されたアートを使用できますか?
問題は、AI ジェネレーターがあなたの著作権で保護されたアートを必ずしも「使用できる」ということではなく、あなたの著作権で保護されたアートを既に「使用しているか」ということです。 多くのアーティストが発見したように、その質問に対する答えは圧倒的にイエスです。 上記で、データセットをオプトアウトし、クローラーがコンテンツのインデックスを作成しないようにするいくつかの方法について説明しましたが、最終的にこれらの手法は、あなたの好みを尊重するかどうかにかかっています。
あなたのアートが、HaveIBeenTrained.com を使用して、最大の公開画像データセットに含まれているかどうかを確認できます。 有名なアートワークをアップロードするか、名前、アートワークのタイトル、ウェブコミック、またはその他の作品を検索して見てください。 アートワークが Web サイトに表示されている場合、アートワークは Stable Diffusion などで使用されているデータセットに含まれています。
どのデータセットが使用されているかを明らかにしない他のジェネレーティブ アート アプリケーション (OpenAI の DALL-E など) は言うまでもありません。 「あなたの名前のスタイルのアートワーク」などのプロンプトをいつでも試して、おなじみのものが表示されるかどうかを確認できます.
今後のツールは、AI アート ジェネレーターを打ち負かすのに役立つ可能性があります
ジェネレーティブ AI がデータセット内の画像に基づいてアートワークを再現することを困難にするツールの形で登場するアーティストには、いくらかの希望があるかもしれません。 残念ながら、これらのソリューションはまだ (執筆時点では) 登場しておらず、長期的にどの程度効果があるかはわかりません。 AI ツールは急速に進化するため、このような保護手段を回避するように進化する可能性があります。
1 つ目は Glaze です。これはシカゴ大学のプロジェクトで、アップロードする前にアートワークに「非常に小さな変更を加える」ものです。 開発者はこれらの変更を「スタイル クローク」と呼び、アートワークが人間の目にはオリジナルとほぼ同じように見える一方で、AI がスタイルを別のスタイルと誤解する原因になっていると指摘しています。
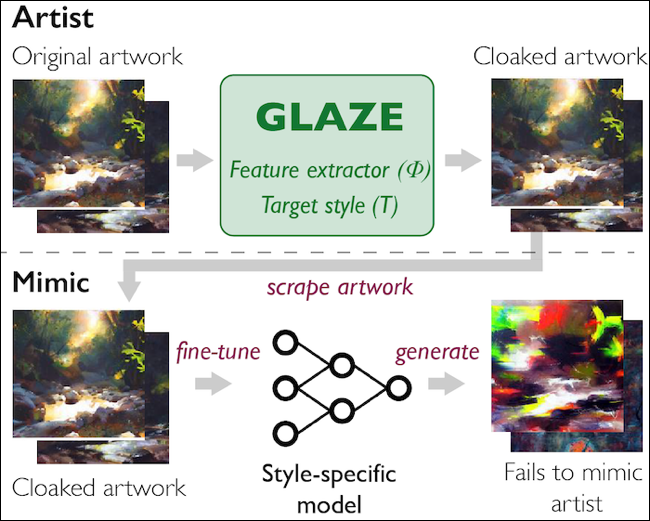
Glaze は Mac および Windows 用のアプリケーションとしてリリースされるため、アーティストのコンピューターから離れずにアートワークを「隠す」ことができます。 開発者は、このツールを商品化する予定はないと述べているため、誰でも無料で使用できます。 Glaze プロジェクトは、このツールを「AI の模倣に対抗するためのアーティスト中心の保護ツールに向けた必要な第一歩」と見なしています。
メルボルン大学の Pursuit ブログで概説されている別の手法では、「画像内のピクセルを変更して AI を混乱させ、それを「学習不可能な」画像に変える」ノイズの巧妙な使用について説明しています。 この機関は、モデルの弱点を悪用する手法を思いついたと主張しており、Stable Diffusion のようなツールを「怠惰な学習者」と表現するところまで行っています。
この手法には、視覚的なアートワークだけでなく、個人を特定する音声や写真など、幅広い潜在的な用途があります。 これらの手法はまだ開発の初期段階にあることを認識しておくことが重要です。そのため、実際に何ができるかを確認する必要があります。
ロボットの台頭
ジェネレーティブ アート アプリはアートワークを短時間で作成できますが、人間と同じように真に創造的ではありません。 ChatGPT で履歴書を作成できる場合もありますが、チャットボットは自信を持って間違っていることが多いため、慎重に校正する必要があります。
要するに、現在の AI ソリューションは有用かもしれませんが、脆弱でもあるということです。